elasticsearch架构
1、部署方式:docker compse
2、系统架构:集群模式
3、相关部署文件
compose.yaml文本内容
yaml
services:
setup:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- ./certs:/usr/share/elasticsearch/config/certs
user: "0"
command: >
bash -c '
if [ x${ELASTIC_PASSWORD} == x ]; then
echo "Set the ELASTIC_PASSWORD environment variable in the .env file";
exit 1;
fi;
if [ ! -f config/certs/certs.zip ]; then
echo "Creating certs";
echo -ne \
"instances:\n"\
" - name: $NODE_NAME\n"\
" dns:\n"\
" - $NODE_NAME\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
> config/certs/instances.yml;
bin/elasticsearch-certutil cert --silent --pem -out config/certs/certs.zip --in config/certs/instances.yml --ca-cert config/certs/ca/ca.crt --ca-key config/certs/ca/ca.key;
unzip config/certs/certs.zip -d config/certs;
fi;
echo "Setting file permissions"
chown -R root:root config/certs;
find . -type d -exec chmod 750 \{\} \;;
find . -type f -exec chmod 640 \{\} \;;
'
healthcheck:
test: ["CMD-SHELL", "[ -f config/certs/$NODE_NAME/$NODE_NAME.crt ]"]
interval: 1s
timeout: 5s
retries: 120
es:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
container_name: es
user: "1000:0"
environment:
- node.name=${NODE_NAME}
- cluster.name=${CLUSTER_NAME}
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- discovery.seed_hosts=node-b,node-c
- cluster.initial_master_nodes=node-a,node-b,node-c
- network.publish_host=172.31.121.77
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.license.self_generated.type=${LICENSE}
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.key=certs/$NODE_NAME/$NODE_NAME.key
- xpack.security.transport.ssl.certificate=certs/$NODE_NAME/$NODE_NAME.crt
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.verification_mode=certificate
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.http.ssl.key=certs/$NODE_NAME/$NODE_NAME.key
- xpack.security.http.ssl.certificate=certs/$NODE_NAME/$NODE_NAME.crt
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/esdatadir/:/usr/share/elasticsearch/data
- ./certs:/usr/share/elasticsearch/config/certs
ports:
- ${ES_PORT}:9200
- 9300:9300
extra_hosts:
- "node-a:172.31.107.43"
- "node-b:127.0.0.1"
- "node-c:172.31.139.253"
depends_on:
setup:
condition: service_healthy统计目录下环境变量文件.env
c
NODE_NAME=node-b
# Password for the 'elastic' user (at least 6 characters)
ELASTIC_PASSWORD=xxxx
# Version of Elastic products
STACK_VERSION=7.17.26
# Set the cluster name
CLUSTER_NAME=starboard
# Set to 'basic' or 'trial' to automatically start the 30-day trial
LICENSE=basic
# Port to expose Elasticsearch HTTP API to the host
ES_PORT=9200调用hot_threads查询日志信息
1、调用hot_threads日志命令
bash
curl -k -u elastic:xxxx-X GET "https://172.31.139.253:9200/_nodes/hot_threads?pretty&threads=5&interval=500ms"-k:屏蔽证书
-u:elasticsearc开启的密码登录,所以要添加账号密码
请求方式:elasticsearch开启了xpack安全模式,所以要https请求方式
2、排查操作过程
首要任务是确认是 GC 问题 还是 卡在某些任务上。请按顺序执行以下操作
检查 JVM 内存堆积
查看当前节点的堆内存使用百分比
如果 heap.percent 长期高于 85%-90%,说明内存不够用了
bash
admin@elasticsearch-c:~$ curl -k -u elastic:xxx -X GET "https://localhost:9200/_cat/nodes?v&h=name,ip,heap.percent,ram.percent,cpu"
name ip heap.percent ram.percent cpu
node-a 172.31.107.43 41 95 15
node-c 172.31.139.253 49 98 79
node-b 172.31.121.77 52 94 70查看"热点线程" (最直接的方法)
这个命令会直接展现 CPU 到底在忙什么(是 GC?还是 Lucene 合并?还是网络等待?)
bash
curl -k -u elastic:xxx -X GET "https://172.31.121.77:9200/_nodes/hot_threads?pretty&threads=5&interval=500ms"3、hot_threads日志分析总结
结论:这是典型的"雪崩效应"。根源是 Node C 的磁盘 I/O 几乎完全卡死,导致整个集群的写入队列堵塞,并引发了其他节点的连锁高负载。
4、基于日志的详细证据分析:
1)核心证据:Node C 的磁盘已经"瘫痪"
Node C 的 write 线程日志 :
100.0% [cpu=0.3%, other=99.7%] (500ms out of 500ms) cpu usage by thread 'elasticsearch[node-c][write][T#1]'解读: 这个线程在 500ms 的采样时间内,100% 的时间都在运行,但 CPU 消耗仅为 0.3%,而 99.7% 的时间处于 "other" 状态。
原因: 堆栈跟踪显示它卡在了 sun.nio.ch.FileChannelImpl.force 。
这意味着 Elasticsearch 正在试图将数据(Translog)强制刷入磁盘(fsync),但操作系统迟迟不返回成功信号。这个在 htop 中可以看到相关的 D 状态进程,Node C 的磁盘物理读写能力已经饱和或损坏。
2. Node A 也出现了 I/O 瓶颈
Node A 的情况与 Node C 类似 :
100.0% [cpu=0.0%, other=100.0%] ... cpu usage by thread 'elasticsearch[node-a][write][T#2]'同样卡在 UnixFileDispatcherImpl.force 。这说明由于集群副本同步机制,Node C 的卡顿可能拖累了 Node A,或者这两台机器共享了同一底层存储(如果是虚拟机/云盘),导致 Node A 的 I/O 也被耗尽。
3. 为什么 CPU 会飙高?(Node B 和 Node C 的搜索线程)
即使"没有外部连接",但 Node B 和 Node C 的 CPU 都在疯狂处理 search 类型的任务。
日志证据: 也就是看到的 MultiTermQueryConstantScoreWrapper 和 BooleanWeight.scorer 。
这些通常是复杂的过滤查询(Filter Query)或通配符查询。
如果没有外部用户,这通常来自:
Prometheus Exporter / Monitoring: 在节点中运行着 prometheus-node。监控组件会不断查询集群状态。当磁盘卡死时,简单的元数据读取会变慢,导致查询堆积。
集群自我修复(Rebalancing): 当 Master 发现 Node C 写入不动时,可能会判定其故障,并试图通过查询元数据来重新分配分片。
Kibana/X-Pack 监控: 如果开启了 X-Pack 监控,它会后台运行 Query 统计集群健康。
总结:磁盘 I/O 卡死是因,CPU 飙高是果。因为磁盘写不进去,所有涉及数据一致性的内部查询和监控查询全部阻塞或超时重试,导致 CPU 即使在空转等待中也被计入高负载(Load Average)。
解决思路及操作过程
第一步:立即隔离 Node C
既然 Node C 的磁盘已经无法响应(99.7% 等待时间),让它留在集群里只会拖垮 A 和 B。 在 Node C 的宿主机上直接强制停止容器:
bash
docker compose stop 如果 stop 卡住(因为磁盘 I/O 问题),直接 kill
bash
docker kill es第二步:暂停集群分片分配(止血)
停止 Node C 后,集群通常会疯狂尝试在 A 和 B 之间复制数据来恢复"绿色"状态,这会导致 A 和 B 的 I/O 瞬间再次爆炸。先暂停自动恢复:
在任意存活节点(如 Node A)执行:
(注:如果不加 -k 报错,请加上 -k 忽略证书)
bash
curl -u elastic:xxx -X PUT "https://localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.enable": "none"
}
}'返回
bash
{"acknowledged":true,"persistent":{},"transient":{"cluster":{"routing":{"allocation":{"enable":"none"}}}}}第三步:检查 Node C 硬件
Node C 停掉后,A 和 B 的负载应该会逐渐下降。此时去检查 Node C 的物理磁盘:
如果是云服务器(AWS/Aliyun),检查云盘监控是否达到 IOPS 上限。
如果是物理机,这块硬盘很可能已经坏了。
执行iostat -x 查看 %util 是否持续 100%
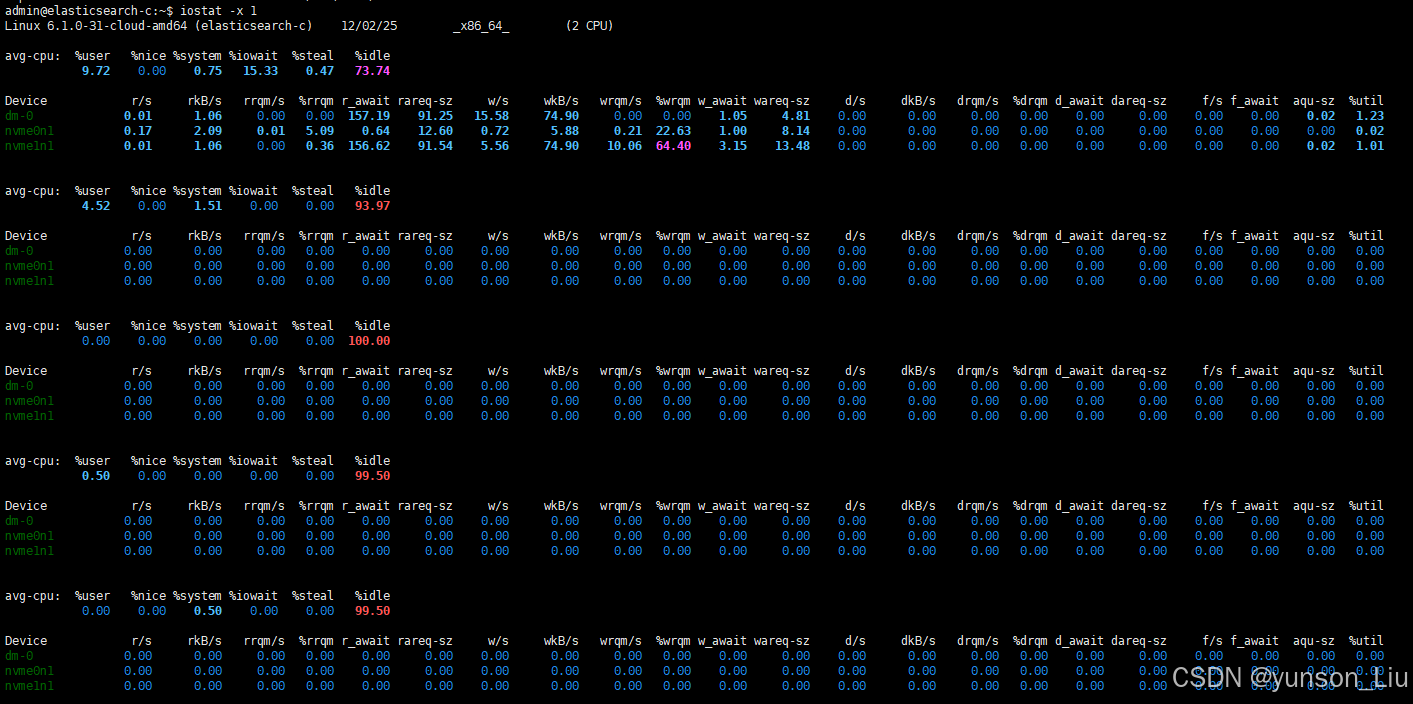
截图显示是 0% (基于上图)
第一部分(历史统计): %iowait 是 15.33,nvme1n1 的 %util 只有 1.01。
后续部分(实时监控): 所有的 nvme 设备 %util 全部变成了 0.00。
CPU 状态: %idle (空闲) 达到了 99.50% - 100.00%。
这说明在您截取这张图的那几秒钟内,没有任何读写请求发送给磁盘。
这通常有三种可能:
已经停止了 ES 容器:由于没有进程在写盘,自然就是 0%。
进程已经彻底卡死:ES 进程(那个处于 D 状态的进程)已经死锁,连"尝试写盘"的动作都做不出来了。
紧接着验证磁盘好坏
直接在 Node C 的宿主机上运行这个命令,测试能不能在磁盘上写文件。这能瞬间判断磁盘是否活着。
bash
# 尝试在当前目录下写入一个 50MB 的测试文件
dd if=/dev/zero of=./testfile bs=1M count=50 oflag=direct判定标准:
正常: 命令瞬间结束,显示写入速度(例如 100 MB/s 或更高)。 -> 磁盘没坏,可能是软件死锁。
卡死/报错: 命令按下去后光标一直闪烁不结束,或者报错 Input/output error。 -> 物理磁盘坏了/掉线了。
建议: 如果 dd 命令卡住,请立即按照之前的建议将 Node C 踢出集群(停掉 Node C 容器),否则它会一直拖累整个集群无法恢复
bash
admin@elasticsearch-c:/data$ sudo dd if=/dev/zero of=./testfile bs=1M count=50 oflag=direct
50+0 records in
50+0 records out
52428800 bytes (52 MB, 50 MiB) copied, 0.0873892 s, 600 MB/s结果显示硬盘属于正常
第四步:启动node-c es
启动日志
bash
{"type": "server", "timestamp": "2025-12-02T03:16:24,191Z", "level": "INFO", "component": "o.e.x.s.s.SecurityStatusChangeListener", "cluster.name": "starboard", "node.name": "node-c", "message": "Active license is now [BASIC]; Security is enabled" }
{"type": "server", "timestamp": "2025-12-02T03:16:24,230Z", "level": "INFO", "component": "o.e.h.AbstractHttpServerTransport", "cluster.name": "starboard", "node.name": "node-c", "message": "publish_address {172.31.139.253:9200}, bound_addresses {[::]:9200}", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:24,231Z", "level": "INFO", "component": "o.e.n.Node", "cluster.name": "starboard", "node.name": "node-c", "message": "started", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:27,249Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "retrieve geoip database [GeoLite2-Country.mmdb] from [.geoip_databases] to [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-Country.mmdb.tmp.gz]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:27,257Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "retrieve geoip database [GeoLite2-City.mmdb] from [.geoip_databases] to [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-City.mmdb.tmp.gz]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:27,258Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "retrieve geoip database [GeoLite2-ASN.mmdb] from [.geoip_databases] to [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-ASN.mmdb.tmp.gz]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:53,503Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "successfully reloaded changed geoip database file [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-Country.mmdb]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:16:55,352Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "successfully reloaded changed geoip database file [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-ASN.mmdb]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "server", "timestamp": "2025-12-02T03:17:22,918Z", "level": "INFO", "component": "o.e.i.g.DatabaseNodeService", "cluster.name": "starboard", "node.name": "node-c", "message": "successfully reloaded changed geoip database file [/tmp/elasticsearch-14189928425167436158/geoip-databases/pMc7EqGnQ8qg-AC6UkvAiA/GeoLite2-City.mmdb]", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" }
{"type": "deprecation.elasticsearch", "timestamp": "2025-12-02T03:17:45,992Z", "level": "CRITICAL", "component": "o.e.d.a.b.BulkRequestParser", "cluster.name": "starboard", "node.name": "node-c", "message": "[types removal] Specifying types in bulk requests is deprecated.", "key": "bulk_with_types", "category": "types", "cluster.uuid": "fpA7Ozk6QTCoU3NCD7DVaA", "node.id": "pMc7EqGnQ8qg-AC6UkvAiA" } 1)核心好消息
节点已启动:
message": "started" 这标志着 Elasticsearch 进程已经完成了初始化,成功绑定了网络端口,并准备好工作了。
没有数据损坏: 日志中没有出现 CorruptIndexException 或 TranslogCorruptedException。这意味着之前的"软件死锁"并没有导致磁盘上的数据文件物理损坏,运气非常好!
2)那个 "CRITICAL" 报错严重吗?
最后一行看到的:
level": "CRITICAL", ... message": "[types removal] Specifying types in bulk requests is deprecated."这不会导致节点崩溃。
含义:这只是一个"弃用警告"。说明现在有业务程序(或监控组件)正在向 node-c 发送写入请求,但请求的格式还在使用旧版本的语法(指定了 _type)。
正面意义:这条报错反而证明了 node-c 已经开始接收并处理写入流量了,它已经活过来了!
把集群状态从"临时止血"切换回"正常运转"
第一步:检查集群是否识别到了 3 个节点
bash
admin@elasticsearch-a:~$ curl -k -u elastic:xxx-X GET "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.31.139.253 21 98 54 1.69 4.22 5.52 cdfhilmrstw * node-c
172.31.107.43 58 93 15 6.57 6.31 6.28 cdfhilmrstw - node-a
172.31.121.77 45 94 73 0.27 1.35 2.14 cdfhilmrstw - node-b显示 node-a, node-b, node-c 三个节点
第二步:恢复数据自动平衡 (之前关掉了)
bash
curl -k -u elastic:xxx-X PUT "https://localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.enable": "all"
}
}'
{"acknowledged":true,"persistent":{},"transient":{"cluster":{"routing":{"allocation":{"enable":"all"}}}}}第三步:检查集群健康度
预期状态:可能是 yellow(正在恢复数据)或 green(完全恢复)。
关键指标:关注 relo (relocating) 和 init (initializing) 这两列的数字,它们应该会动,最终归零。
bash
curl -k -u elastic:xxx-X GET "https://localhost:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1764649507 04:25:07 starboard yellow 3 3 181 114 0 2 38 1 - 81.9%与预期结果相符
第四步:回头看一眼 Node A 和 B 的负载
此时再去 node-b 上运行 htop,它的 CPU 应该会从之前的 196% (爆表) 逐渐下降到正常水平,因为"拖后腿"的 Node C 已经恢复正常工作了。
重启修复node-c后我发现node-b的负载不正常,cpu还是在100%
bash
curl -k -u elastic:xxxxx-X GET "https://172.31.121.77:9200/_nodes/hot_threads?pretty&threads=5&interval=500ms"日志结果可以明确地判断 Node B 并没有坏,也没有发生之前的磁盘死锁(D 状态)。
Node B 目前 CPU 100% 的原因是:它正在承担巨大的计算压力,进行数据的解压和复杂查询运算。
日志证据分析:
- 根本原因:昂贵的"解压"与"搜索"
请查看 Node B 的堆栈跟踪日志:
bash
100.0% [cpu=85.8%, other=14.2%] ... cpu usage by thread 'elasticsearch[node-b][search][T#3]' 状态分析:这个线程 85.8% 的时间都在吃 CPU(计算),只有 14.2% 的时间在等待。这与之前 Node C 99% 等待磁盘(other)的情况截然不同。这是健康的(虽然很忙)CPU 密集型工作。
此时节点node-b主要执行以下工作
解压缩数据:日志中出现了 app//org.apache.lucene.util.compress.LZ4.decompress 。这说明 Node B 正在从磁盘读取压缩的数据块,并消耗大量 CPU 将其解压到内存中。
复杂查询:日志中出现了
MultiTermQueryConstantScoreWrapper。这通常代表通配符查询 (Wildcard)、正则查询 (Regex) 或 范围查询 (Range)。这类查询非常消耗 CPU,因为它们不能直接查倒排索引,往往需要扫描大量的词项(Terms)。缓存操作:日志中还出现了 LRUQueryCache ,说明系统正在试图建立或更新查询缓存。由于 Node C 刚加入,集群拓扑发生变化,旧的缓存可能失效,导致 Node B 需要重新从磁盘加载数据。
- Node B 负载高的原因
Node C 还是空的/冷的:虽然 Node C 启动了,但它的缓存是空的,且可能正在同步数据。因此,大部分查询请求此时都会落在数据最全、状态最"热"的 Node B 身上。
Node A 在等待:看 Node A 的日志,它卡在 fetch_shard_store ,大部分时间是 other=100.0%。这说明 Node A 正在等待其他节点(主要是忙碌的 Node B)告诉它元数据信息。Node B 现在是全村的希望,所以最累。
- 建议的操作
这种情况通常是暂时性的。随着 Node C 数据同步完成以及缓存预热结束,负载会自动平衡。
为了确认具体是哪个查询在消耗 CPU,请执行以下命令抓出"真凶":
第一步:查看正在运行的任务 (Tasks)
这个命令能直接告诉您当前那个消耗 CPU 的 search 任务到底在查什么(是业务查询?还是 Prometheus 监控?)。
bash
admin@elasticsearch-a:~$ curl -k -u elastic:xxx-X GET "https://localhost:9200/_cat/tasks?v&detailed=true&actions=*search*"
action task_id parent_task_id type start_time timestamp running_time ip node description
indices:data/read/search pMc7EqGnQ8qg-AC6UkvAiA:298726 - transport 1764649799970 04:29:59 2.8m 172.31.139.253 node-c indices[data-api], types[], search_type[QUERY_THEN_FETCH], source[{"size":0,"query":{"bool":{"filter":[{"term":{"user_id.keyword":{"value":"OQLamKJow8W3ppZj9E0NpRb8gVMEYe","boost":1.0}}},{"wildcard":{"uri.keyword":{"wildcard":"*","boost":1.0}}},{"range":{"@timestamp":{"from":"now-0d-365d/d","to":"now-0d/d","include_lower":true,"include_upper":false,"boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"track_total_hits":2147483647}]关注 description 列:如果是 indices... 后面跟着复杂的查询语句,您就能看到具体的查询内容。
第二步:查看恢复进度
确认数据是否正在从 B 复制到 C。
bash
admin@elasticsearch-a:~$ curl -k -u elastic:xxx-X GET "https://localhost:9200/_cat/recovery?v&active_only=true"
index shard time type stage source_host source_node target_host target_node repository snapshot files files_recovered files_percent files_total bytes bytes_recovered bytes_percent bytes_total translog_ops translog_ops_recovered translog_ops_percent
.ds-data-api-2025.01.06-000003 0 1.2m peer translog 172.31.121.77 node-b 172.31.107.43 node-a n/a n/a 0 0 0.0% 0 0 0 0.0% 0 0 0 100.0%
.ds-data-api-2025.01.06-000003 1 1.3m peer translog 172.31.139.253 node-c 172.31.107.43 node-a n/a n/a 0 0 0.0% 0 0 0 0.0% 0 0 0 100.0%如果有大量的 shard 正在从 Node B SOURCE 传输到 Node C TARGET,那么 CPU 高就是完全预期的行为(解压数据发送给 C)。
总结
Node B 很安全,它只是在"加班"干活。 之前的 Node C 是硬件/内核层面的"死锁"(由于磁盘不响应),而现在的 Node B 是业务层面的"忙碌"(算力跑满)。请耐心等待 10-20 分钟,待数据平衡完成后,负载就会降下来。
最后在查询下健康状况
bash
admin@elasticsearch-a:~$ curl -k -u elastic:xxx-X GET "https://localhost:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1764651890 05:04:50 starboard green 3 3 221 114 0 0 0 0 - 100.0%状态status 是绿色green
active_shards_percent是100%