前篇我们学习了SLS的核心用途及概念,本篇以将一个linux服务器的json格式日志接入阿里云SLS为例,继续学习SLS接入中的关键设置及注意事项,以及如何将其实现简单自动化快速操作。
一、 SLS 日志接入流程
python
[1] 准备工作(确定日志路径和格式等)
↓
[2] 在 Linux 服务器安装 Logtail 客户端
↓
[3] 创建 SLS Project
[4] 创建 Logstore
↓
[5] 创建机器组
↓
[6] 创建采集配置(Logtail Config 或 Pipeline)
↓
[7] 机器组绑定
↓
[8] 开启索引
↓
[9] 在 SLS 控制台验证日志数据
↓
[10] 授权用户访问/读写
↓
[11] 日志投递/冷热分层(可选)- 其中1和2主要为用户操作,本篇不会涉及,详细可以参考阿里云官方文档
- 后续代码按照流程节点将其拆分出了单独脚本,如有需要完全可以进行合并
二、 创建 SLS Project
这步关键点是名字,project名字创建后不能修改,只能删除重建。如果等一切都接完了发现project名字不合规范,那真是无语了。
另外注意删除project后默认会在回收站放7天,虽说在回收站中,阿里云还是会将其部分设置视为已生效。例如配置了多个project中的logtail接入相同日志文件,即使旧project已经在回收站,也会报配置冲突。
python
from aliyun.log import LogClient
import os
# 本示例从环境变量中获取AccessKey ID和AccessKey Secret。
access_key_id = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID', '')
access_key_secret = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET', '')
# 日志服务的服务接入点
endpoint = "cn-shenzhen.log.aliyuncs.com"
# 创建日志服务Client。
client = LogClient(endpoint, access_key_id, access_key_secret)
# Project名称。
project_name = "slsproject-1"
# Project描述。project_des=""代表描述值为空
project_des = "your describe"
# 调用create_project接口,如果没有抛出异常,则说明执行成功。
def main():
try:
res = client.create_project(project_name, project_des)
res.log_print()
res = client.get_project(project_name)
res.log_print()
except Exception as error:
print(error)
if __name__ == '__main__':
main()三、 创建 Logstore
这步关键点:
- 保留时间 ttl:热日志保留时间,与费用相关。例如设置为15,若不配置日志投递及冷热分层,则15天前的日志将无法从SLS中查询
- webtracking :控制是否允许 通过 HTTP/HTTPS API 直接向 Logstore 写日志 。如果开启,你无需安装 Logtail、Flume、Beats 等采集程序,客户端(例如浏览器 JS、手机 App、小程序、第三方后端)就可以 直接调用 SLS API 发送日志数据到这个 Logstore
看起来 webtracking 似乎更简单,为什么阿里云不将其作为默认方式?

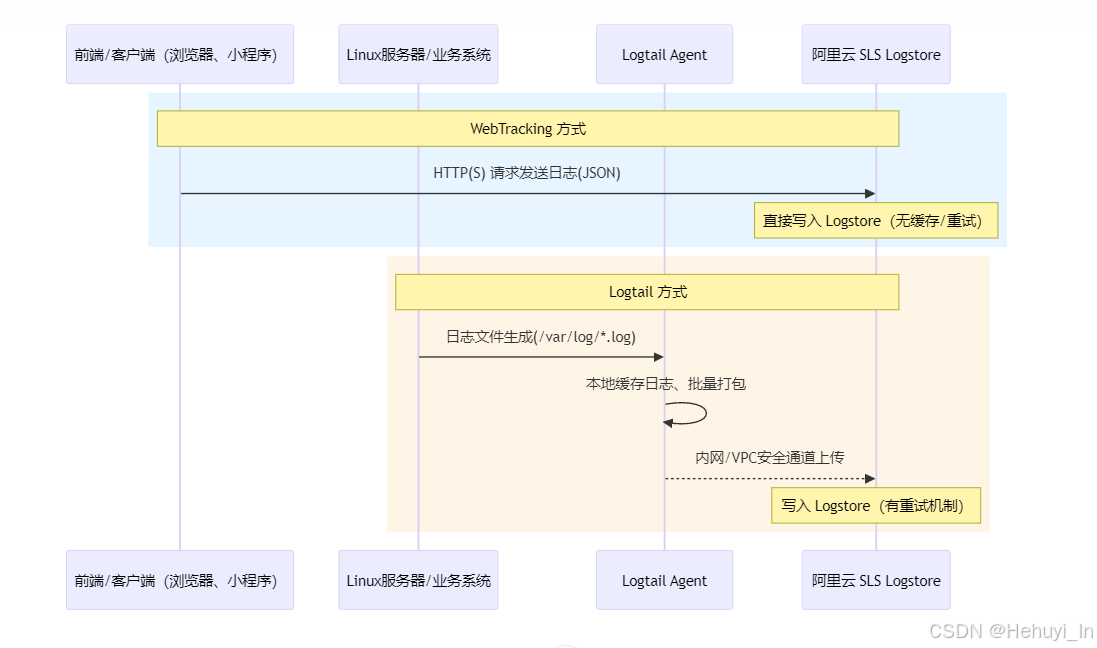
创建代码
python
from aliyun.log import LogClient, LogException
import os
# 本示例从环境变量中获取AccessKey ID和AccessKey Secret
access_key_id = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID', '')
access_key_secret = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET', '')
# 日志服务的服务接入点
endpoint = "cn-shenzhen.log.aliyuncs.com"
client = LogClient(endpoint, access_key_id, access_key_secret)
# Project名称
project_name = 'sls-project'
# 待创建 logstore 列表
logstore_names = ['a-http-vm', 'b-http-vm', 'c-http-vm', 'd-http-vm']
ttl=15
shard_count=2
append_meta=True
enable_tracking=False
def main():
for logstore_name in logstore_names:
print(f'正在创建 logstore: {logstore_name}')
try:
res = client.create_logstore(project_name, logstore_name, ttl=ttl, shard_count=shard_count,enable_tracking=enable_tracking, append_meta=append_meta)
print(f'成功创建 logstore: {logstore_name}')
except LogException as e:
if e.get_error_code() == 'LogStoreAlreadyExist':
print(f'logstore 已存在: {logstore_name}')
else:
print(f'创建 logstore 失败: {logstore_name}, 错误: {e}')
if __name__ == '__main__':
main()四、 创建机器组
顾名思义,要从哪些机器采集日志数据
python
from aliyun.log import LogClient, MachineGroupDetail
import os
# 本示例从环境变量中获取AccessKey ID和AccessKey Secret
access_key_id = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID', '')
access_key_secret = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET', '')
# 日志服务的服务接入点
endpoint = "cn-shenzhen.log.aliyuncs.com"
# 实例化LogClient类
client = LogClient(endpoint, access_key_id, access_key_secret)
project_name = "sls-project"
# 组名和IP列表
group_names = [
"a-http-vm",
"b-http-vm",
"c-http-vm",
"d-http-vm"
]
machine_ips = [
"192.168.1.126",
"192.168.1.127",
"192.168.1.128",
"192.168.1.129"
]
def main():
client = LogClient(endpoint, access_key_id, access_key_secret)
for group_name, ip in zip(group_names, machine_ips):
machine_type = "ip"
machine_list = [ip] # 每组对应一个IP
group_detail = MachineGroupDetail(group_name, machine_type, machine_list)
try:
res = client.create_machine_group(project_name, group_detail)
print(f'创建机器组 {group_name} 成功,IP: {ip}')
res.log_print()
except Exception as e:
print(f'创建机器组 {group_name} 失败,IP: {ip}。错误:{e}')
if __name__ == '__main__':
main()五、 创建采集配置 & 机器组绑定
相对来说这步是参数最多最复杂的,核心参数设置如下
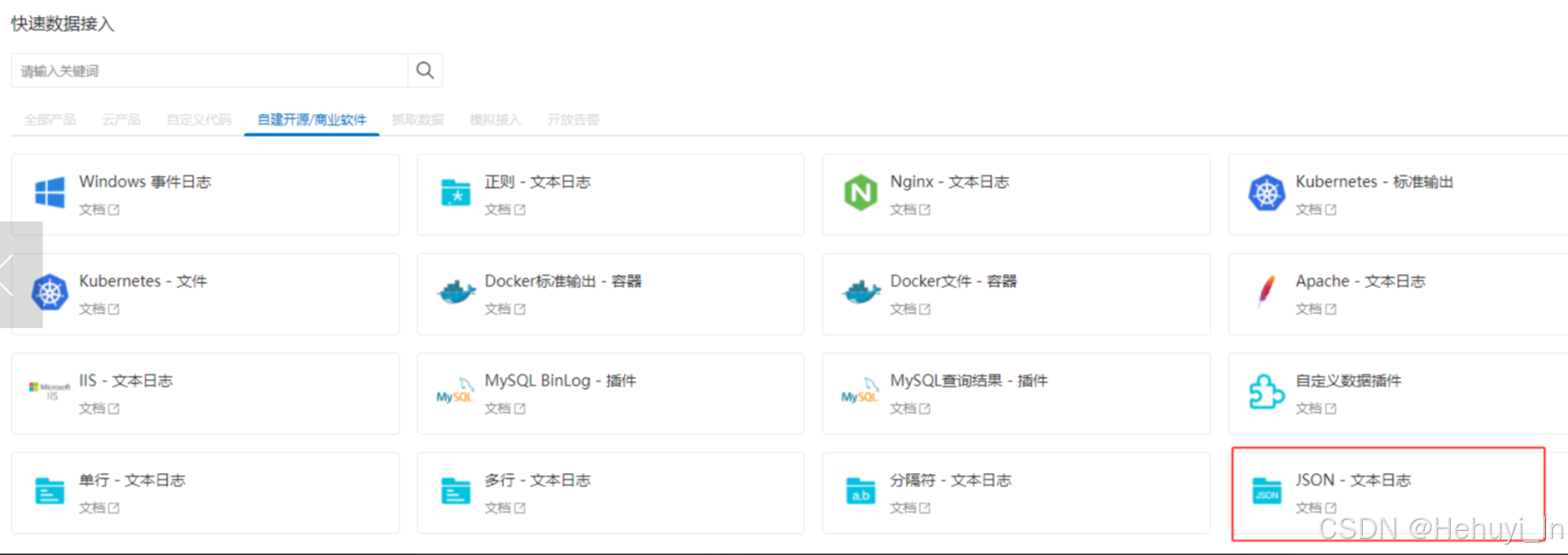
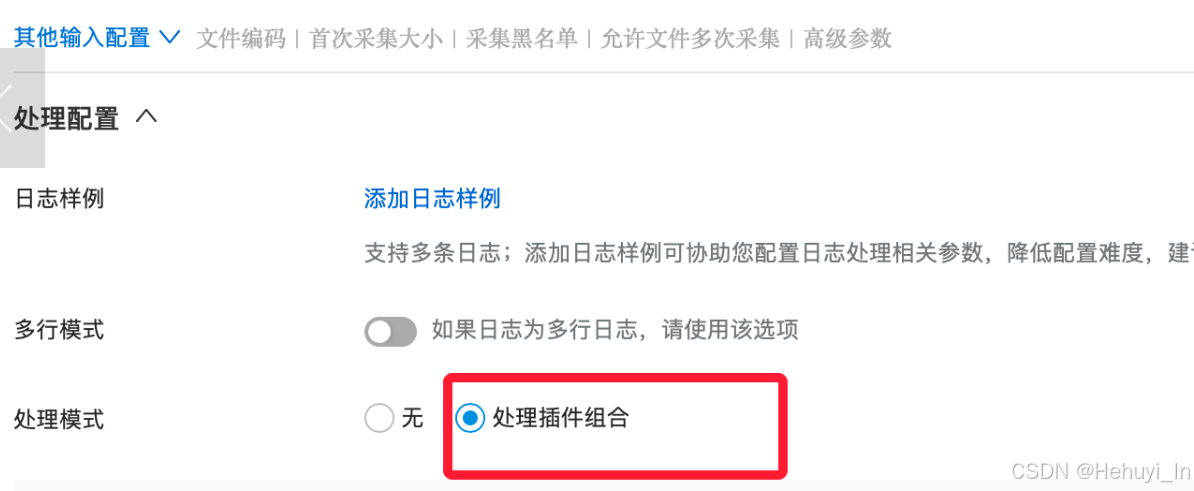
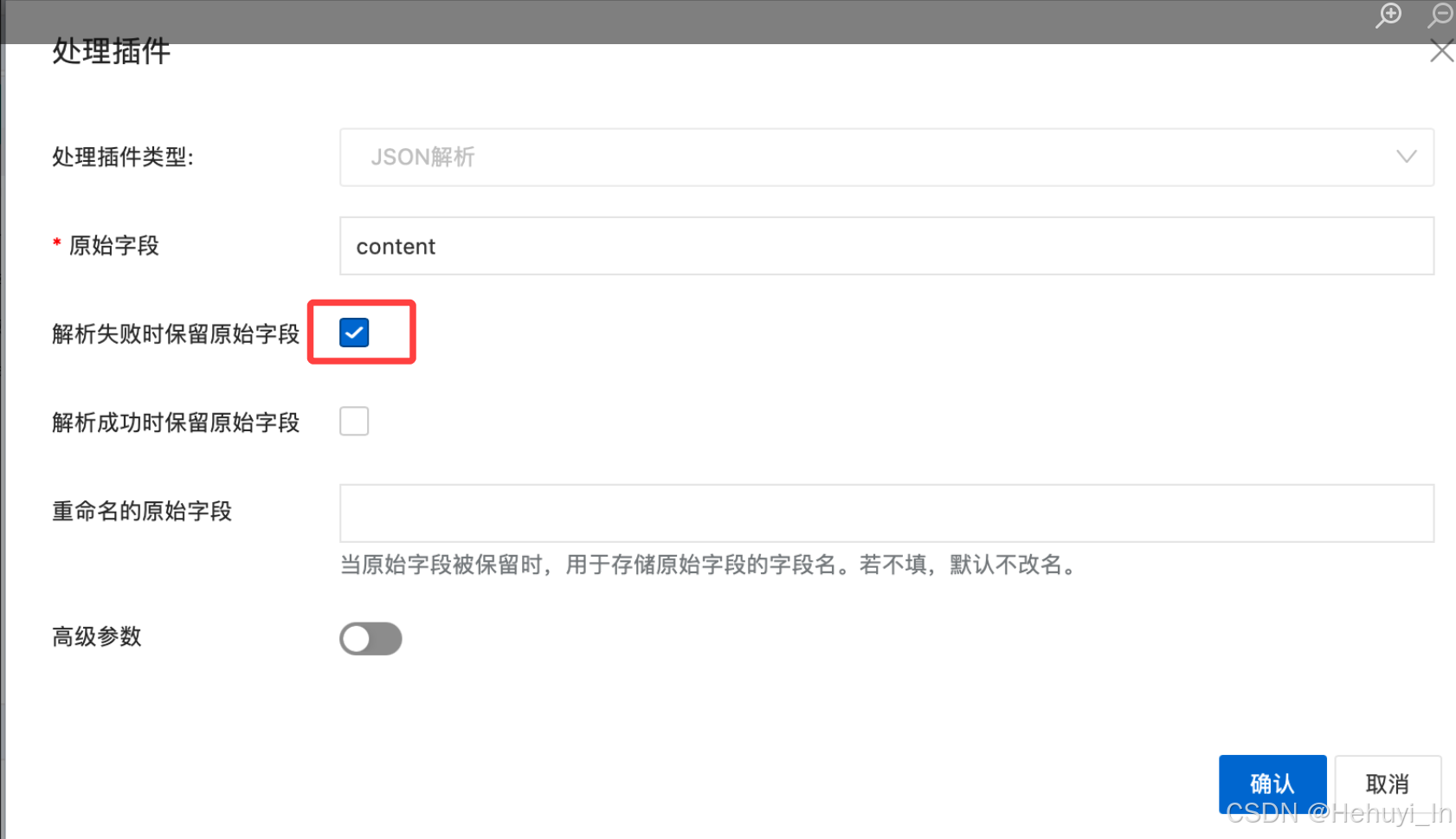
代码如下
python
from aliyun.log import LogClient
from aliyun.log.logtail_config_detail import SimpleFileConfigDetail
import os
# 本示例从环境变量中获取AccessKey ID和AccessKey Secret
access_key_id = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID', '')
access_key_secret = os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET', '')
# 日志服务的服务接入点
endpoint = "cn-shenzhen.log.aliyuncs.com"
client = LogClient(endpoint, access_key_id, access_key_secret)
project = "sls-project"
# 数据源:一一对应
logstore_names = [
"a-http-vm",
"b-http-vm",
"c-http-vm",
"d-http-vm"
]
group_names = [
"a-http-vm",
"b-http-vm",
"c-http-vm",
"d-http-vm"
]
logs = [
"/var/log/nginx/logstash_access.log",
"/var/log/nginx/logstash_access.log",
"/var/log/nginx/logstash_access.log",
"/var/lib/gerrit/logs/httpd_log.json"
]
# 公共配置
timeFormat = ''
timeKey = ''
localStorage = True
enableRawLog = False
topicFormat = 'none'
fileEncoding = 'utf8'
maxDepth = 0
preserve = True
preserveDepth = 0
filterKey = []
filterRegex = []
adjustTimezone = False
delayAlarmBytes = 0
delaySkipBytes = 0
discardNonUtf8 = False
discardUnmatch = False
dockerFile = False
logBeginRegex = '.*'
logTimezone = ''
logType = 'json_log'
maxSendRate = -1
mergeType = 'topic'
priority = 0
sendRateExpire = 0
sensitive_keys = []
tailExisted = False
def main():
for logstore, group, logfile in zip(logstore_names, group_names, logs):
logPath = os.path.dirname(logfile) # 获取目录前缀
filePattern = os.path.basename(logfile) # 获取日志文件名
configName = logstore # 这里用 logstore 作为配置名
try:
config_detail = SimpleFileConfigDetail(
logstoreName=logstore,
configName=configName,
logPath=logPath,
filePattern=filePattern,
timeFormat=timeFormat,
timeKey=timeKey,
localStorage=localStorage,
enableRawLog=enableRawLog,
topicFormat=topicFormat,
fileEncoding=fileEncoding,
maxDepth=maxDepth,
preserve=preserve,
preserveDepth=preserveDepth,
filterKey=filterKey,
filterRegex=filterRegex,
adjustTimezone=adjustTimezone,
delayAlarmBytes=delayAlarmBytes,
delaySkipBytes=delaySkipBytes,
discardNonUtf8=discardNonUtf8,
discardUnmatch=discardUnmatch,
dockerFile=dockerFile,
logBeginRegex=logBeginRegex,
logTimezone=logTimezone,
logType=logType,
maxSendRate=maxSendRate,
mergeType=mergeType,
priority=priority,
sendRateExpire=sendRateExpire,
sensitive_keys=sensitive_keys,
tailExisted=tailExisted
)
# 创建 logtail 配置
print(f"创建 Logtail 配置: {configName}, 日志路径: {logPath}, 文件: {filePattern}")
res = client.create_logtail_config(project, config_detail)
res.log_print()
# 绑定到机器组
print(f"绑定日志采集配置 {configName} 到机器组 {group}")
res = client.apply_config_to_machine_group(project, configName, group)
res.log_print()
# 查询配置
res = client.get_logtail_config(project, configName)
res.log_print()
print("="*80)
except Exception as e:
print(f"[错误] 创建 {configName} 失败: {e}")
if __name__ == '__main__':
main()六、 开启索引
如果要在查看和分析日志,必须先开启索引
这块虽然也可以用代码实现,但接口目前无"自动生成索引"功能,需要自行分析日志结构并写入代码处理。如果是大批量标准化的日志,这块可以实现,如果非标,直接点击界面效率更高。
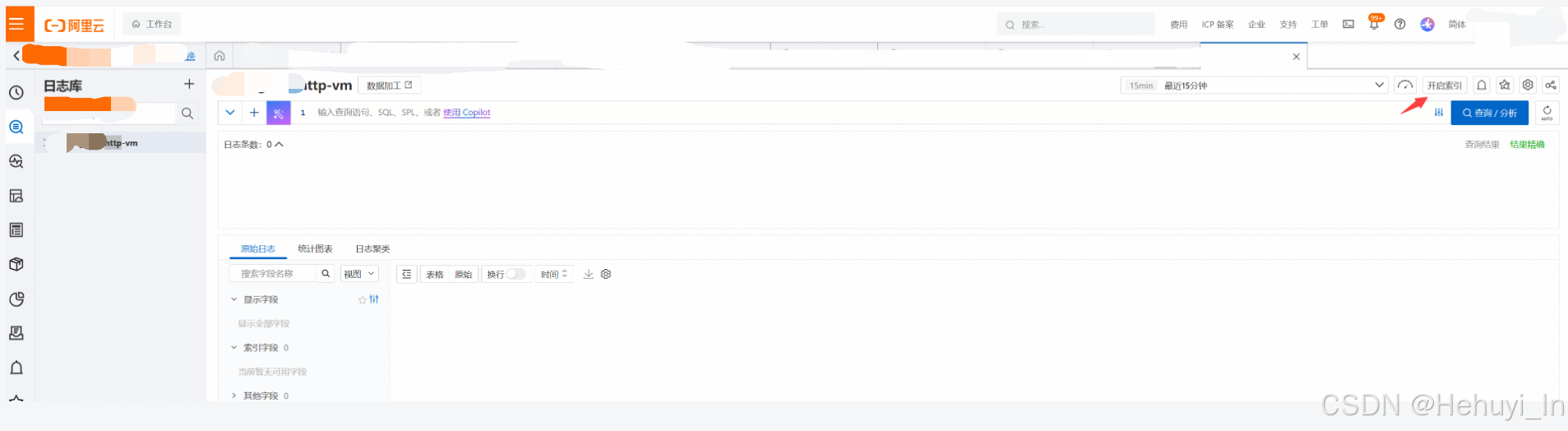
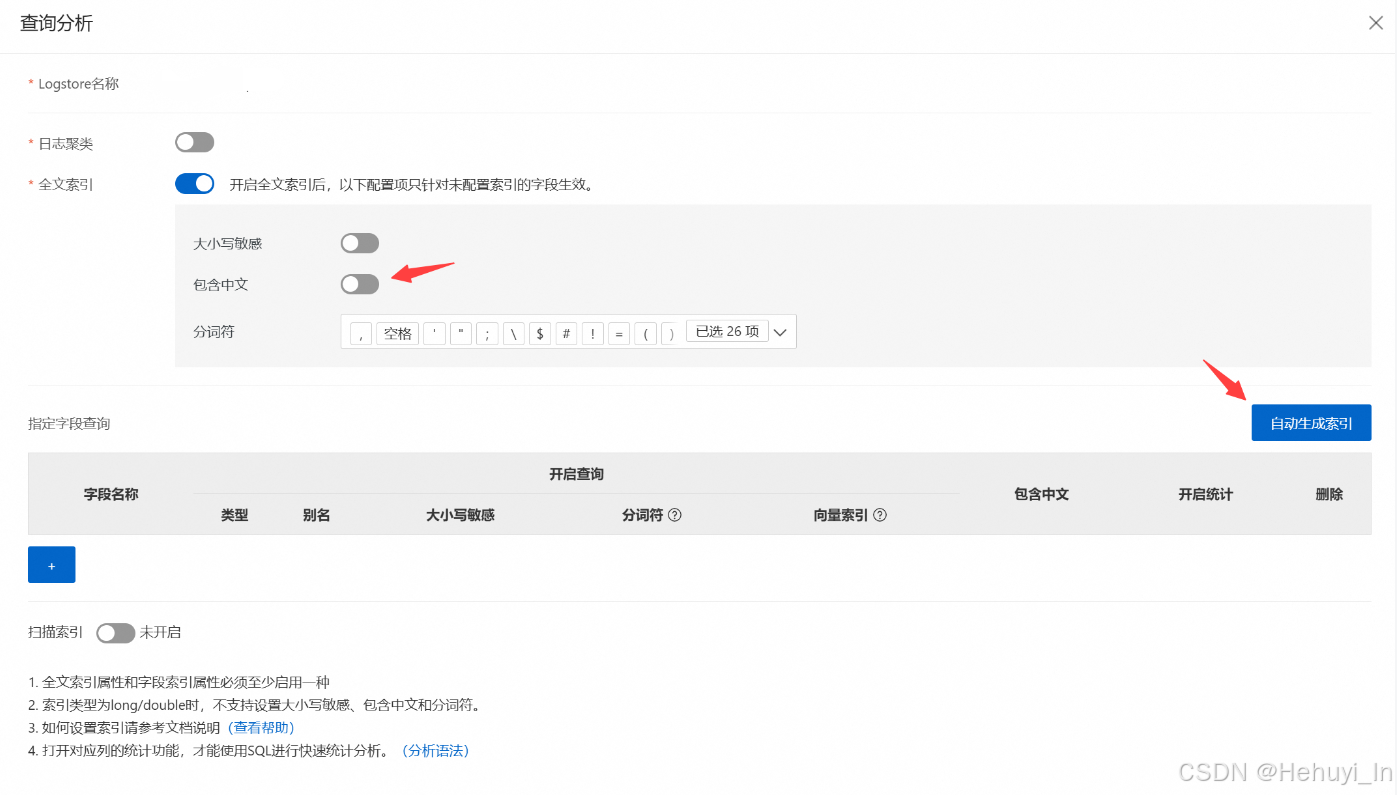
开启后等两分钟,若接入正常,应该可以看到日志
七、 授权用户访问/读写
这里一般按project或logstore授权
1. 只读权限
python
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"log:ListProjects",
"log:GetAcceleration",
"log:ListDomains",
"log:GetLogging",
"log:ListTagResources"
],
"Resource": "acs:log:*:*:project/*"
},
{
"Effect": "Allow",
"Action": "log:GetProject",
"Resource": "acs:log:*:*:project/sls-project"
},
{
"Effect": "Allow",
"Action": "log:ListLogStores",
"Resource": "acs:log:*:*:project/sls-project/logstore/*"
},
{
"Effect": "Allow",
"Action": [
"log:GetLogStore",
"log:GetLogStoreHistogram",
"log:GetIndex",
"log:ListShards",
"log:GetLogStoreContextLogs",
"log:GetLogStoreLogs",
"log:GetCursorOrData"
],
"Resource": "acs:log:*:*:project/sls-project/logstore/a-http-vm"
},
{
"Effect": "Allow",
"Action": "log:*SavedSearch",
"Resource": "acs:log:*:*:project/sls-project/*"
},
{
"Effect": "Allow",
"Action": "log:*",
"Resource": "acs:log:*:*:project/sls-project/dashboard/*"
}
]
}2. 读写权限
python
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": "log:*",
"Resource": [
"acs:log:*:*:project/sls-project/logstore/a-http-vm",
"acs:log:*:*:project/sls-project/logstore/a-http-vm/*"
]
},
{
"Effect": "Allow",
"Action": "log:ListProject",
"Resource": "*"
}
]
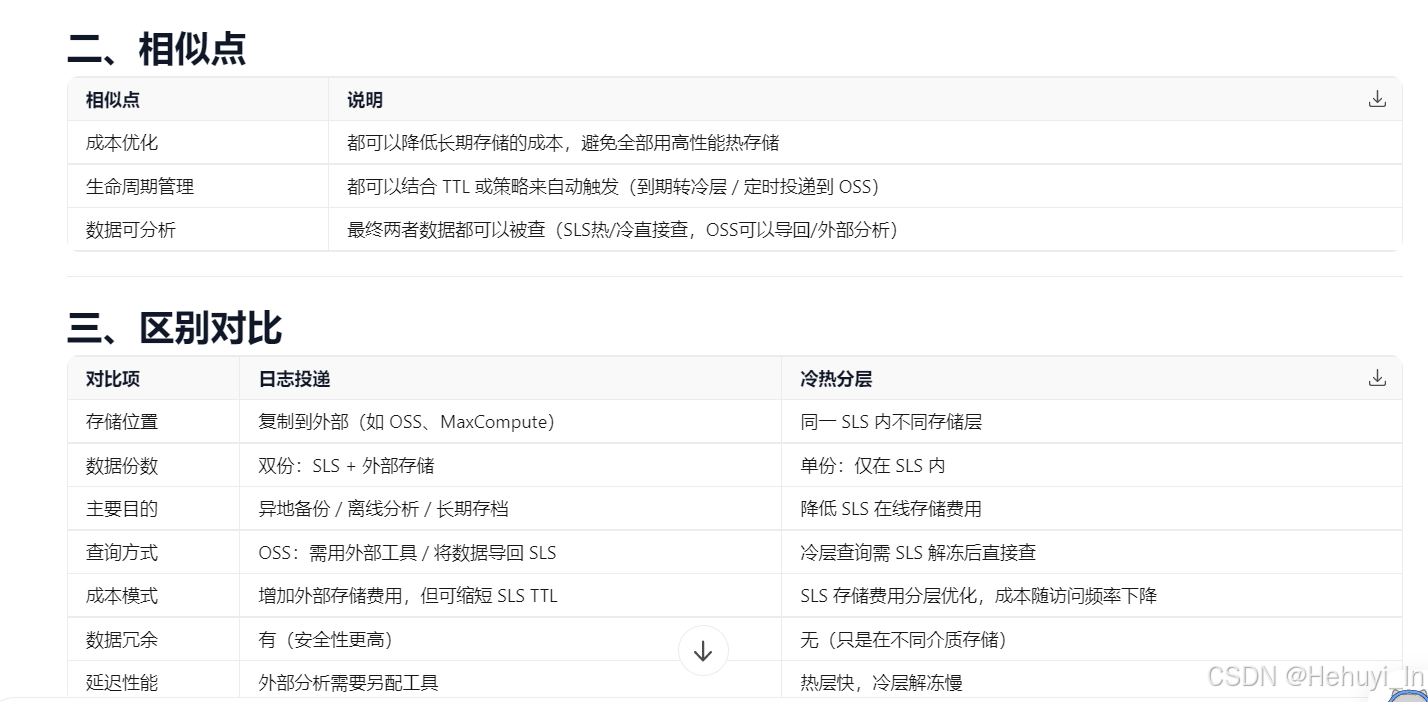
}八、 日志投递/冷热分层
1. 数据流转方式
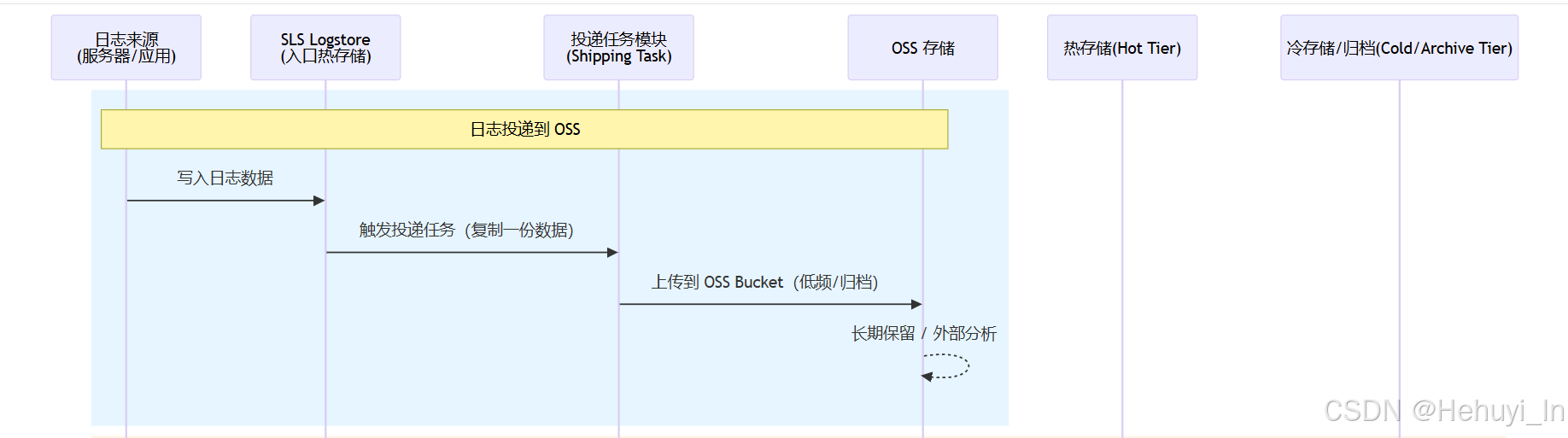

2. 相似及区别
参考
管理日志项目Project_日志服务(SLS)-阿里云帮助中心
GPT 5