1. yarn资源调度框架
1.1 yarn资源管理平台
Apache Hadoop Yarn(Yet Another Reasource Negotiator,另一种资源协调者)是Hadoop2.x版 本后使用的资源管理器,可以为上层应用提供统一的资源管理平台,Yarn主要由 ResourceManager、NodeManager、ApplicationMaster、Container组成。架构如下下图所示:
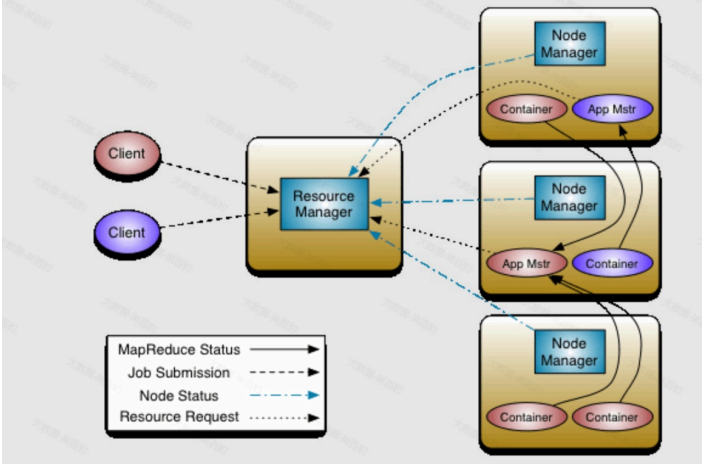
1.1.1 ResourceManager
ResourceManager是Yarn集群中的中央管理器,负责整个集群的资源分配与调度。 ResourceManager负责监控NodeManager节点状态、汇集集群资源,处理Client提交任务的资源 请求,为每个Application启动AppliationMaster并监控。
1.1.2 NodeManager
NodeManager负责管理每个节点上的资源(如:内存、CPU等)并向ResourceManager报告。当 ResourceManager向NodeManager分配一个容器(Container)时,NodeManager负责启动该 容器并监控容器运行,此外,NodeManager还会接收AplicationMaster命令为每个Application启动容器(Container)。
1.1.3 ApplicationMaster
每个运行在Yarn中的应用程序都会启动一个对应的ApplicationMaster,其负责与 ResourceManager申请资源及管理应用程序任务。ApplicationMaster本质上也是一个容器,由 ResourceManager进行资源调度并由NodeManager启动,ApplicationMaster启动后会向 ResourceManager申请资源运行应用程序,ResourceManager分配容器资源后, ApplicationMaster会连接对应NodeManager通知启动Container并管理运行在Container上的任 务。
1.1.4 Container
Container 容器是Yarn中的基本执行单元,用于运行应用程序的任务,它是一个虚拟环境,包含应 用程序代码、依赖项及运行所需资源(内存、CPU、磁盘、网络)。每个容器都由 ResourceManager分配给ApplicationMaster,并由NodeManager在相应的节点上启动和管理。 容器的资源使用情况由NodeManager监控,并在必要时向ResourceManager报告。 Yarn核心就是将MR1中JobTracker的资源管理和任务调度两个功能分开,分别由 ResourceManager和ApplicationMaster进程实现,ResourceManager负责整个集群的资源管理 和调度;ApplicationMaster负责应用程序任务调度、任务监控和容错等。
1.2 Yarn任务运行流程

- 在客户端向Yarn中提交MR任务,首先会将MR任务资源(Split、资源配置、Jar包信息)上传 到HDFS中。
- 客户端向ResourceManager申请启动ApplicationMaster。
- ResourceManager会选择一台相对不忙的NodeManager节点,通知该节点启动 ApplicationMaster(Container)。
- ApplicationMaster启动之后,会从HDFS中下载MR任务资源信息到本地,然后向 ResourceManager申请资源用于启动MR Task。
- ResourceManager返回给ApplicationMaster资源清单。
- ApplicationMaster进而通知对应的NodeManager启动Container
- Container启动之后会反向注册到ApplicationMaster中。
- ApplicationMaster 将Task任务发送到Container 运行,Task任务执行的就是我们写的代码业 务逻辑。
2. yarn集群搭建与启动
安装前,请先安装hdfs
hdfs高可用部署![]() https://mp.csdn.net/mp_blog/creation/editor/150605552
https://mp.csdn.net/mp_blog/creation/editor/150605552
2.1 集群规划
|-----------|----|----|------|----|-----------------|-------------|
| 节点 | NN | DN | ZKFC | JN | ResourceManager | NodeManager |
| hadoop101 | √ | | √ | | √ | |
| hadoop102 | √ | | √ | | √ | |
| hadoop103 | √ | √ | √ | √ | | √ |
| hadoop104 | | √ | | √ | | √ |
| hadoop105 | | √ | | √ | | √ |
2.2 yarn-site.xml
XML
<configuration>
<property>
<!-- MR On yarn 支持数据Shuffle -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- NodeManager 上Container可以继承的环境变量 -->
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop101</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop102</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop101:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop102:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>2.3 mapred-site.xml
XML
<configuration>
<property>
<!-- 指定MapReduce运行时框架为Yarn -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.4 sbin/start-yarn.sh,stop-yarn.sh
配置$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh两个文件顶部添加以下参数,防止启动错
XML
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=roo2.5 yarn-env.sh
yarn的pid文件默认放在/tmp目录下,过段时间系统会自动清理,我们换一个目录保存,修改etc/hadoop/yarn-env.sh文件。在顶部添加以下配置。
XML
export YARN_PID_DIR=/opt/module/hadoop-3.3.6/pids2.6 分发配置,启动测试
以上五个文件需要分发到集群的全部节点;
2.7 启动yarn
XML
start-yarn.sh
单节点启停yarn命令
XML
#启动/停止 ResourceManager
yarn --daemon start resourcemanager
yarn --daemon stop resourcemanager
#启动/停止NodeManager
yarn --daemon start nodemanager
yarn --daemon stop nodemanage