论文作者团队:来自杜克大学 CEI Center,由实习生陈欣骅、黄思韬及郭聪博士共同完成,指导教师为李海教授、陈怡然教授。
扩散大语言模型(dLLMs)凭借并行解码与独特的全局规划能力,有望解决自回归(AR)大模型的效率瓶瓶颈和规划能力缺陷。但其「全局规划」能力依赖于其双向注意力对所有后文的关注,这带来了严重的计算冗余,从而导致现有开源模型的潜力远远未被释放。
当前的 dLLM 存在「路线之争」:一是保留全局规划能力但推理效率极低的「全局双向注意」(如 LLaDA),二是追求速度却牺牲规划能力的「块内双向注意」(如 Block Diffusion)。如何在这两条路线之间调和折中,让模型既能「着眼全局」,又能加速推理,已成为学界日益关注的问题。
针对以上问题,杜克大学陈怡然团队另辟蹊径,揭示了 dLLM 中实现全局规划的「草稿纸机制」,并发现其存在高度冗余。据此,他们提出免训练方法 DPad(Diffusion Scratchpad),通过先验地丢弃大量无效后缀 token,既极大地降低了计算量,又保留了核心规划能力,尝试在两条路线中走出一条「中间路线」。该方法与现有优化技术结合后,在几乎无损的模型精度下,可实现高达 61.4 倍的推理加速。

-
论文标题:DPad: Efcient Difusion Language Models with Sufx Dropout
-
论文地址 :arxiv.org/abs/2508.14...
dLLM 独特的「草稿纸」机制:
实时记录语义信息
不同于自回归模型,dLLM 采用双向注意力机制,在解码时既能回顾前文,也能「展望」后文。基于这一点,文本序列可被清晰地划分为三部分:
-
前缀 token (Prefix Tokens) :已完全解码的文本,语义和位置信息完整。
-
当前块 token (Current Block) :正在解码的文本,拥有部分语义和完整的位置信息。
-
后缀 token (Suffix Tokens) :使用 Mask 初始化的未来文本,仅有位置信息,初始没有语义信息。可在每层 Transformer block 执行的过程中,逐步记录语义信息,对未来的文本进行规划。
研究团队通过分析双向注意力机制后发现:dLLM 中的后缀 token 是一种独特的「草稿纸」。模型在解码「当前块」时,会巧妙将这些后缀 token 作为临时存储空间,用于在每一层 Transformer block 中记录自己对后文的构思。这种方法能够实现对整个文本的规划,使输出的前后文更一致,提高语言模型的整体性能。
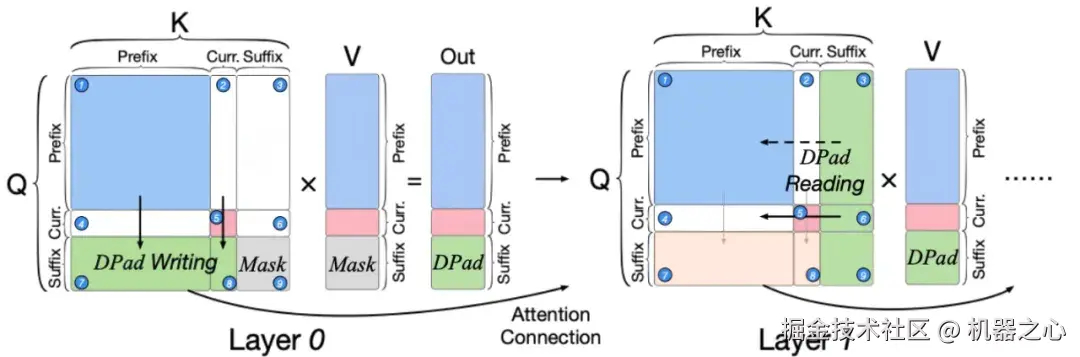
草稿纸机制示意图。左图显示在浅层(Layer 0),信息从 Prefix 和 Current「写入」(DPad Writing)到 Suffix 区域。右图显示在深层(Layer 1),信息被 Current Block 从 Suffix 区域「读取」(DPad Reading)回来,辅助解码。
如上图所示,前缀、当前和后缀三种类型将注意力分数分为了 9 个区域,使得模型的前向过程存在一个「写---读」的工作流:
-
写入 (Write) :在第 0 层 Transformer block,后缀 token 通过注意力机制,从前缀(⑦)和当前(⑧)块中捕获信息。这个过程相当于模型对后文的构思作为「草稿」记录下来。
-
读取 (Read) :在第 1 层 Transformer block,当前块反过来从后缀 token 读取信息(⑥)。此时的后缀 token 已不再是「白板」,而是承载了上一层写入的「草稿」。所以从后文读取的信息可以用于辅助当前块的解码。
研究团队认为,这种「写---读」的行为就像一本「草稿纸」,将模型在浅层对后文的构思传递到深层------这正是 dLLM 具备强大全局规划能力的关键。它让模型在生成当前内容的同时,能初步构思和约束未来的生成方向,实现了前后文的协同共进。
符合直觉的发现:
「草稿纸」也要详略得当
DPad 的核心思想,源于一个非常符合直觉的类比。想象一下您在创作一部鸿篇巨制:
-
对于当前章节,你会反复修改,精雕细琢。
-
对于临近几章,你会先列好提纲,构思重点情节,确保情节自然衔接。
-
对于后续章节,或许只是随手记下几个天马行空的灵感,寥寥几笔。
DPad 正是基于这一思想,避免让作者(dLLM)在创作每个章节(当前块 Token)时,对所有未来的「草稿纸」(后缀 Token)进行强行填充,从而,才能集中注意力并节省资源(降低算力和存储)。其核心思想便是聚焦当下,展望未来,留白长远,让模型的每一次「下笔」都更加高效。
通过对 dLLM 注意力机制的分析,研究团队发现了支撑这种核心思想的关键性数据:
-
「草稿纸」大量冗余:离当前块较远的后缀 token 往往被写入了极其相似的「草稿」,其中大部分成了无效计算。
-
注意力随距离衰减:对当前解码起关键作用的,主要是附近少数几页「草稿纸」,远处的「草稿」重要性显著降低。

预先解码出来的后缀 token 存在大量重复
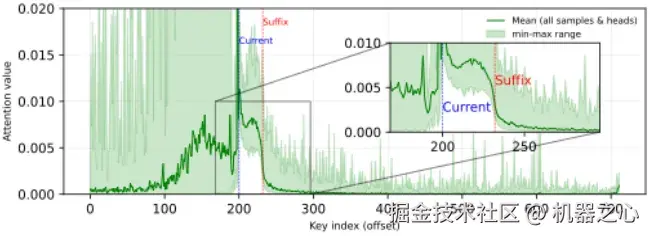
当前块对后缀 token 的注意力分数图。可以看到,注意力(绿线)在进入 Suffix 区域后迅速衰减,表明远处 token 的影响力逐渐减小。
那么,是否可以更大胆一些呢?如下图所示,研究人员进行了一个反直觉的实验:强行删除那些注意力分数最高的远端 token。出人意料的是,准确率几乎没有任何损失!dLLM 似乎有「自愈能力」,会将注意力自动转移到邻近 token 上,补偿丢失的信息。
这个「注意力迁移」现象有力地证明:比起某一张特定位置的「草稿纸」,dLLM 其实仅要求在未来某个位置区间内存在可用的「草稿纸」即可。因此,与其空耗算力确定重要 token 的位置,不如直接先验丢弃。
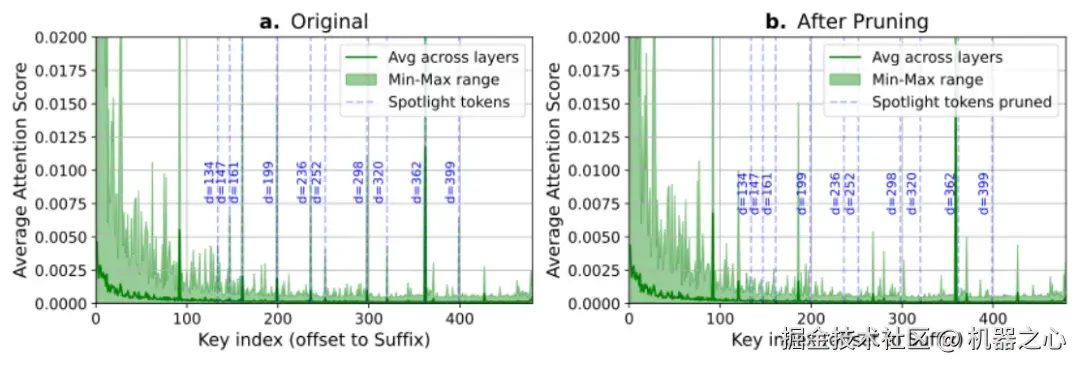
左图展示了 dLLM 中当前块 token 对后缀 token 的注意力分布:整体随距离衰减,远端 token 偶尔出现「尖峰」(如 d = 362)。当删除这些尖峰 token 后(右图),模型的注意力并没有消失,而是自然地转移到了邻近的 token 上(如,362 号 token 的注意力被转移到 359 号)。
DPad:
简单高效的「先验丢弃」
基于以上洞见,DPad 方法应运而生。它的核心思想是:与其等模型算完再「剪枝」,不如在解码开始前,就先验地丢掉一批冗余的「草稿纸」。DPad 的实现非常简洁,主要包含两大策略:
-
滑动窗口 (Sliding Window) :只保留当前解码位置附近一个固定长度的后缀窗口作为「草稿纸」,远处的直接丢弃。
-
「近多远少」采样 (Distance-decay Dropout) :在滑动窗口内部,根据「越近越重要」的原则,以一个随距离递减的概率保留后缀 token。
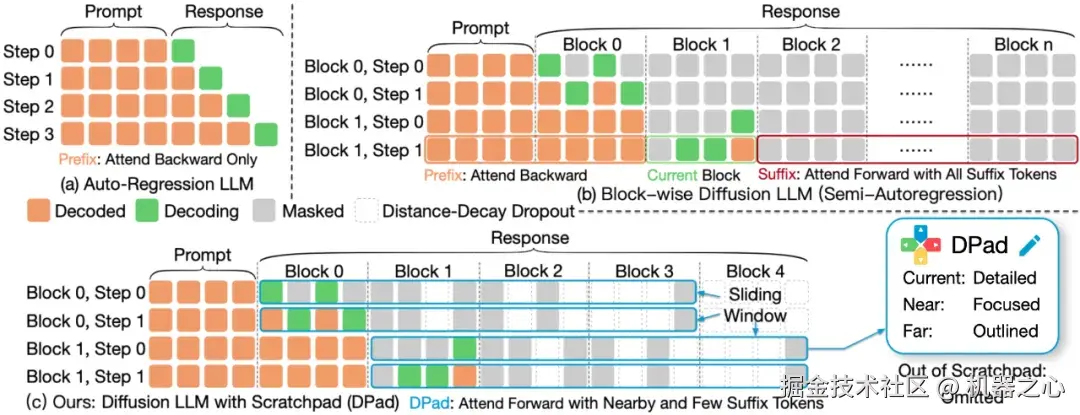
(a) 自回归模型;(b) 传统 dLLM,需要关注所有后缀 token;(c) DPad,仅关注附近少数经过筛选的后缀 token。
实验结果:
更快更准
DPad 在 LLaDA 和 Dream 系列等多个主流 dLLM 上进行了全面测试,结果喜人。
大幅提升推理效率
在现实的长输出场景(少示例、长回答)中,DPad 可谓大放异彩:
-
在 GSM8K 数据集上,DPad 为 LLaDA-1.5 带来了 20.3 倍的单独加速比。
-
与 Fast-dLLM 等并行解码技术结合后,综合加速比高达 61.39 倍。
-
在 HumanEval 数据集上,当输出长度达到 2048 个 token 时,DPad 与 Fast-dLLM 的组合为 Dream 模型带来了 97.32 倍的惊人加速。

图 6 在 GSM8K(1024 tokens, 1-shot)任务上,DPad 结合其他优化技术,让 LLaDA-1.5 实现了 61.39 倍的加速。
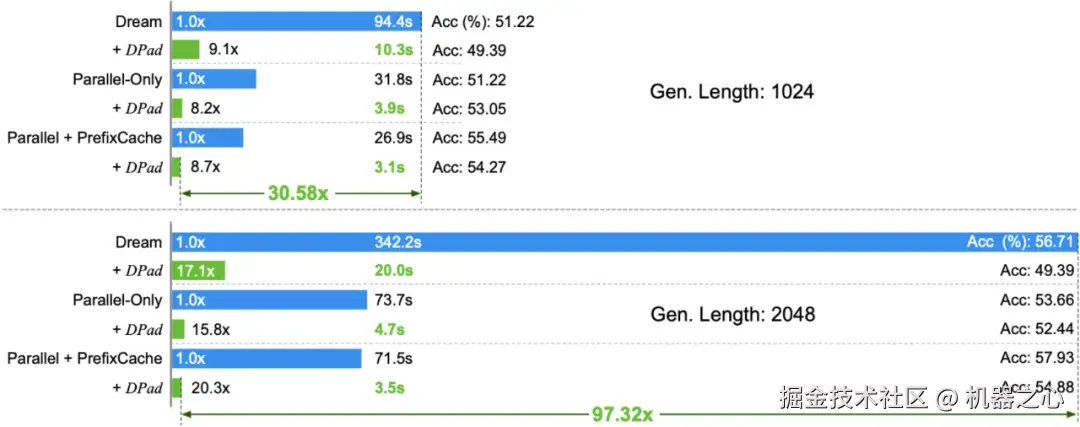
在 HumanEval(2048 tokens, 0-shot)任务上,DPad 结合其他优化技术,让 Dream-Base 实现了 97.32 倍的加速。
意外之喜:显著提升语境学习能力 (In-Context Learning)
通常,推理加速会以牺牲部分模型精度为代价。但 DPad 却带来了意外的惊喜:在多个任务上,尤其是在 LLaDA 系列模型上,它不仅没有降低精度,反而显著提升了模型的准确率,尤其是「严格匹配」(Strict Match)得分。
「严格匹配」不仅要求答案正确,还要求模型严格遵循输入示例给出的格式,是衡量模型语境学习能力的关键指标。

在 GSM8K 任务中,原始模型(左)虽然算对了答案(通过 Flexible-Match),但未能按要求格式输出答案,未能通过 Strict-Match。而应用了 DPad 的模型(右),则精准复刻了示例格式,同时给出了正确答案。
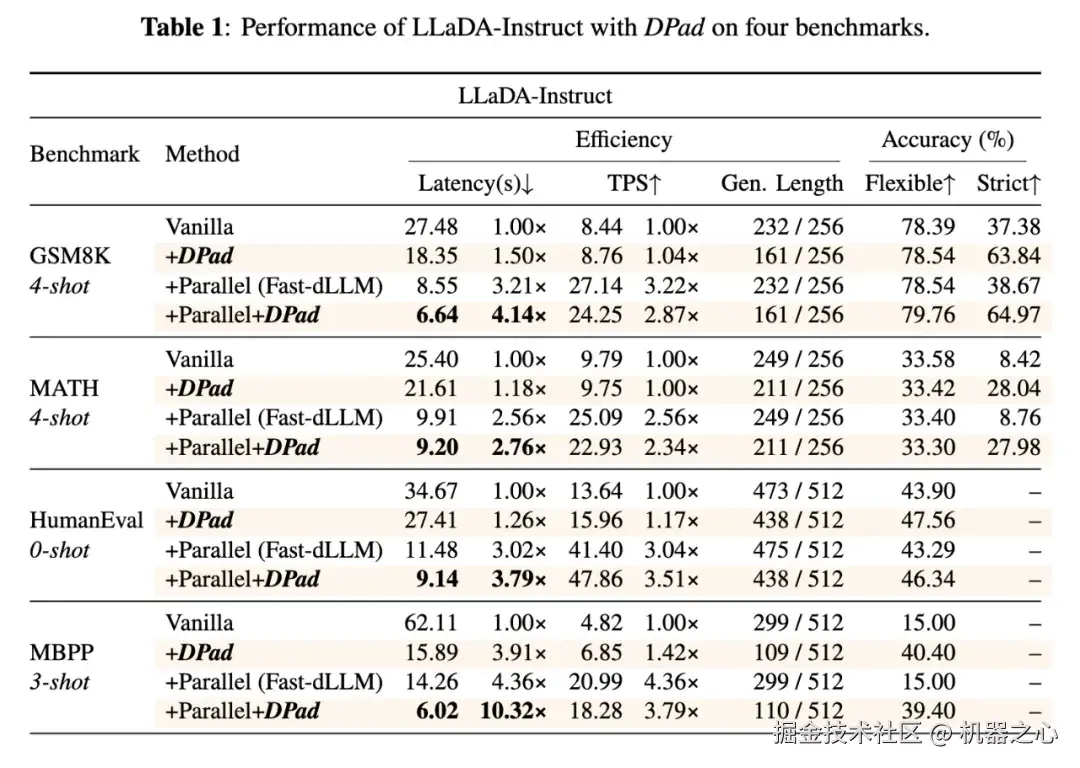
DPad 在 LLaDA-Instruct 上与原始模型 (Vanilla) 和 Fast-dLLM 的对比
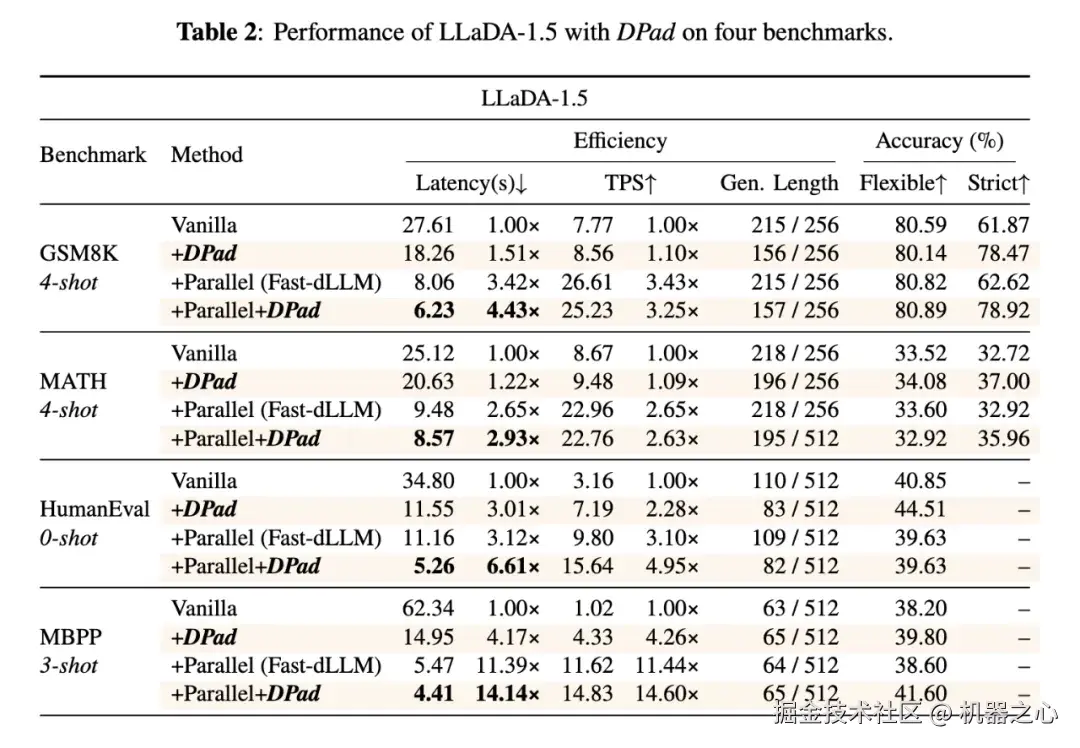
DPad 在 LLaDA-1.5 上与原始模型 (Vanilla) 和 Fast-dLLM 的对比
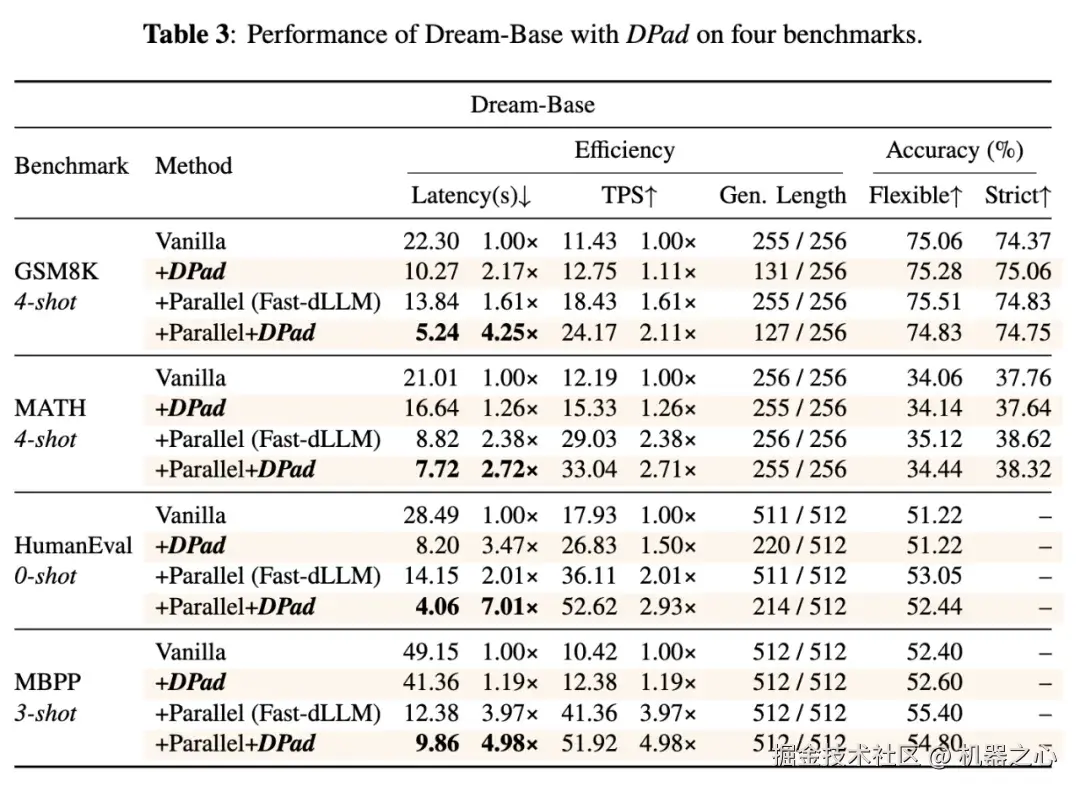
DPad 在 Dream-Base 上与原始模型 (Vanilla) 和 Fast-dLLM 的对比
DPad 团队认为,这是因为丢弃了大量冗余的后缀 token 后,模型能将更多注意力集中在信息量丰富的前缀 token(prompt)上,从而更好地理解和学习示例中蕴含的格式与规范。
总结与展望
面对当前 dLLM 的两条路线之争,DPad 巧妙地介于两者之间,尝试着开辟一条「中间路线」。它既通过「草稿纸机制」,揭示了后缀 token 对于 dLLM 全局规划能力的重要性;又向 Block Diffusion 靠拢,通过稀疏化后缀 token 大幅提升了推理效率。
DPad 的提出预示着我们似乎并不需要在速度和规划能力之间做出非此即彼的选择。未来,若将 DPad 的思想引入到模型的微调甚至预训练阶段,或许能博采众长,训练出更高效、更强大的下一代扩散大语言模型。