Google GFS 深度解析:分布式文件系统的开山之作
Google 文件系统(GFS)作为分布式存储领域的里程碑技术,其设计理念深刻影响了 HDFS、TFS 等后续系统。GFS 专为大规模数据处理场景优化,通过创新的架构设计和租约机制,解决了海量数据存储的可靠性、扩展性和性能难题。本文将从系统架构、核心组件、租约机制及技术特点等方面全面解析 GFS,揭示其成为分布式文件系统标杆的底层逻辑。
GFS 核心定位与设计目标
GFS 是 Google 为内部大规模数据处理场景(如搜索索引、日志分析、机器学习训练)设计的分布式文件系统,核心目标包括:
- 海量存储:支持 PB 级数据存储,单集群可容纳数万台服务器;
- 高容错性:基于普通硬件构建,通过多副本和故障自动恢复确保数据不丢失;
- 高吞吐量:优化批量读写性能,满足大数据处理场景的高 IO 需求;
- 简单实用:针对 Google 内部应用特点定制,放弃部分 POSIX 接口以换取更高效率。
GFS 系统架构:三角色的协同设计
GFS 采用 主从架构(Master-Slave) ,由三种核心角色构成:主控服务器(GFS Master) 、数据块服务器(ChunkServer) 和 客户端(Client)。三者分工明确,通过协同工作实现分布式文件存储与访问。
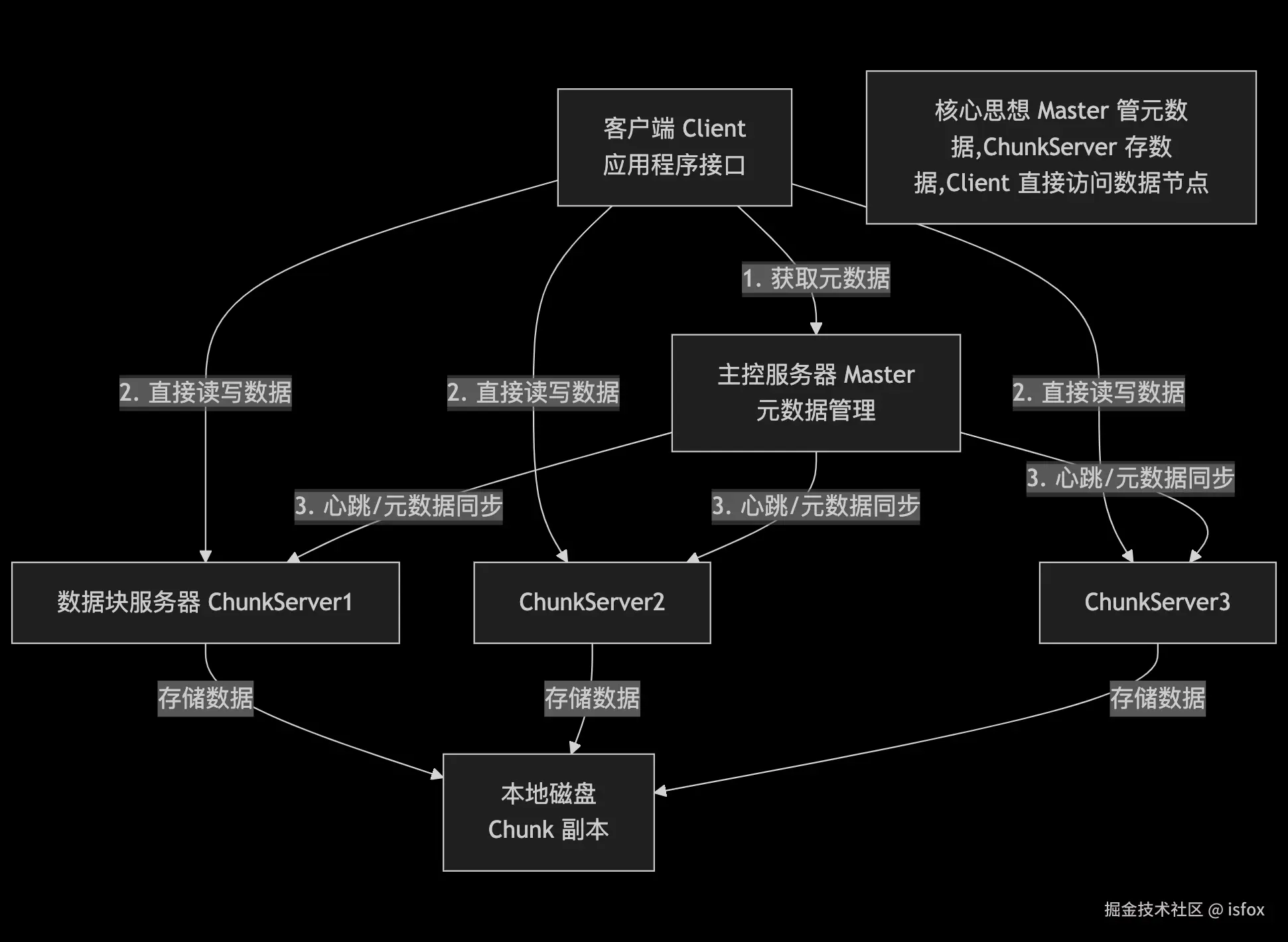
核心角色详解
1. 主控服务器(GFS Master)
Master 是 GFS 的 "大脑",负责全局元数据管理和系统协调,但不直接参与数据读写,以避免成为性能瓶颈。
核心功能
- 元数据存储 :维护三类关键元数据(均存储在 Master 内存中,通过日志持久化):
- 文件与目录结构:文件命名空间(目录树)、访问权限等;
- 文件 - 数据块映射:记录每个文件由哪些数据块(Chunk)组成;
- 数据块位置信息:每个 Chunk 存储在哪些 ChunkServer 上(非持久化,由 ChunkServer 定期汇报)。
- 全局控制 :
- Chunk 租约管理:通过租约机制授权 ChunkServer 处理写操作(详见下文 "租约机制");
- 数据块复制:确保每个 Chunk 有足够副本(默认 3 个),在节点故障时自动补全副本;
- 负载均衡:将 Chunk 均匀分布到 ChunkServer,避免单点过载;
- 垃圾回收:识别并回收无用 Chunk(如文件删除后遗留的 Chunk)。
性能优化
- 元数据全内存存储:Master 将元数据保存在内存中,减少磁盘 IO 开销,支持高效查询;
- 元数据持久化:通过操作日志(Operation Log)记录元数据变更,确保 Master 重启后可恢复状态;
- 轻量级交互:仅响应 Client 的元数据查询和 ChunkServer 的心跳请求,不参与数据传输。
2. 数据块服务器(ChunkServer)
ChunkServer 是 GFS 的 "存储节点",负责实际数据的存储与读写,通常部署在普通服务器上,通过本地磁盘存储数据。
核心功能
- 数据块管理 :
- 将文件划分为固定大小的 Chunk(数据块),默认大小为 64MB(远大于普通文件系统的块大小);
- 每个 Chunk 由 Master 分配唯一的 64 位全局标识符(Chunk Handle);
- 以普通 Linux 文件形式存储 Chunk 数据,每个 Chunk 对应磁盘上的一个文件。
- 副本存储:每个 Chunk 存储多个副本(默认 3 个),分布在不同的 ChunkServer 上,确保容错性;
- 数据读写:接收 Client 的读写请求,执行实际的 IO 操作,参与写操作的一致性协调(如租约机制中的主 / 备节点)。
性能关注点
- 磁盘 IO:优化 Chunk 读写效率,采用大 Chunk 减少元数据量和寻址开销;
- 网络 IO:支持批量数据传输,减少网络往返次数,提升吞吐量。
3. 客户端(Client)
Client 是应用程序访问 GFS 的接口,提供一组专用 API(非 POSIX 兼容),负责协调元数据查询和数据读写。
核心流程
- 元数据查询:Client 访问文件前,先向 Master 请求元数据(如文件包含的 Chunk 列表、每个 Chunk 的存储节点);
- 数据读写:Client 直接与 ChunkServer 交互完成数据传输,无需经过 Master;
- 缓存优化:Client 缓存元数据(如 Chunk 位置),减少对 Master 的请求次数。
典型 API 操作
create(path):创建文件;append(path, data):追加数据到文件(GFS 主要写操作,支持并发追加);read(path, offset, length):读取文件数据;delete(path):删除文件。
GFS 核心技术:Chunk 与租约机制
GFS 的高性能和可靠性依赖两大核心技术:大 Chunk 设计 和租约机制。
1. 大 Chunk 设计(64MB)
GFS 将文件划分为 64MB 的固定大小 Chunk,远大于普通文件系统的块(如 4KB),这一设计带来多重优势:
- 减少元数据量:每个 Chunk 仅需一条元数据记录,Master 内存可容纳海量 Chunk 信息;
- 提升 Client 缓存效率:Client 缓存的 Chunk 位置信息有效期更长,减少元数据查询;
- 优化批量操作:大 Chunk 适合大数据处理场景的连续读写,降低 IO 次数;
- 简化副本管理:单个 Chunk 的副本复制和故障恢复成本更低。
2. 租约机制:高效协调写操作
GFS 中最常见的写操作是 追加(Append) ,为避免每次写操作都请求 Master 导致瓶颈,GFS 引入 租约(Lease)机制 授权 ChunkServer 自主协调写操作。
租约机制核心流程
- 租约授予 :Master 为某个 Chunk 选择一个 ChunkServer 作为 主 ChunkServer(Primary) ,授予其租约(默认有效期 60 秒),其他副本所在节点为 备 ChunkServer(Secondary);
- 写操作协调 :
- Client 将数据发送到所有副本节点(Primary + Secondary)的缓存;
- Client 向 Primary 发送写请求,Primary 确定写顺序并通知所有 Secondary 执行;
- 所有节点完成写操作后,Primary 向 Client 返回成功响应;
- 租约续期:Primary 可在租约到期前向 Master 请求续期,确保连续写操作无需频繁请求 Master。
作用与优势
- 减轻 Master 负担:Master 仅需授予租约,无需参与每次写操作的协调;
- 保证一致性:由 Primary 统一协调写顺序,确保所有副本的数据一致性;
- 支持并发追加:多个 Client 可同时追加数据到同一 Chunk,Primary 负责合并顺序并处理冲突。
GFS 读写流程详解
1. 读操作流程
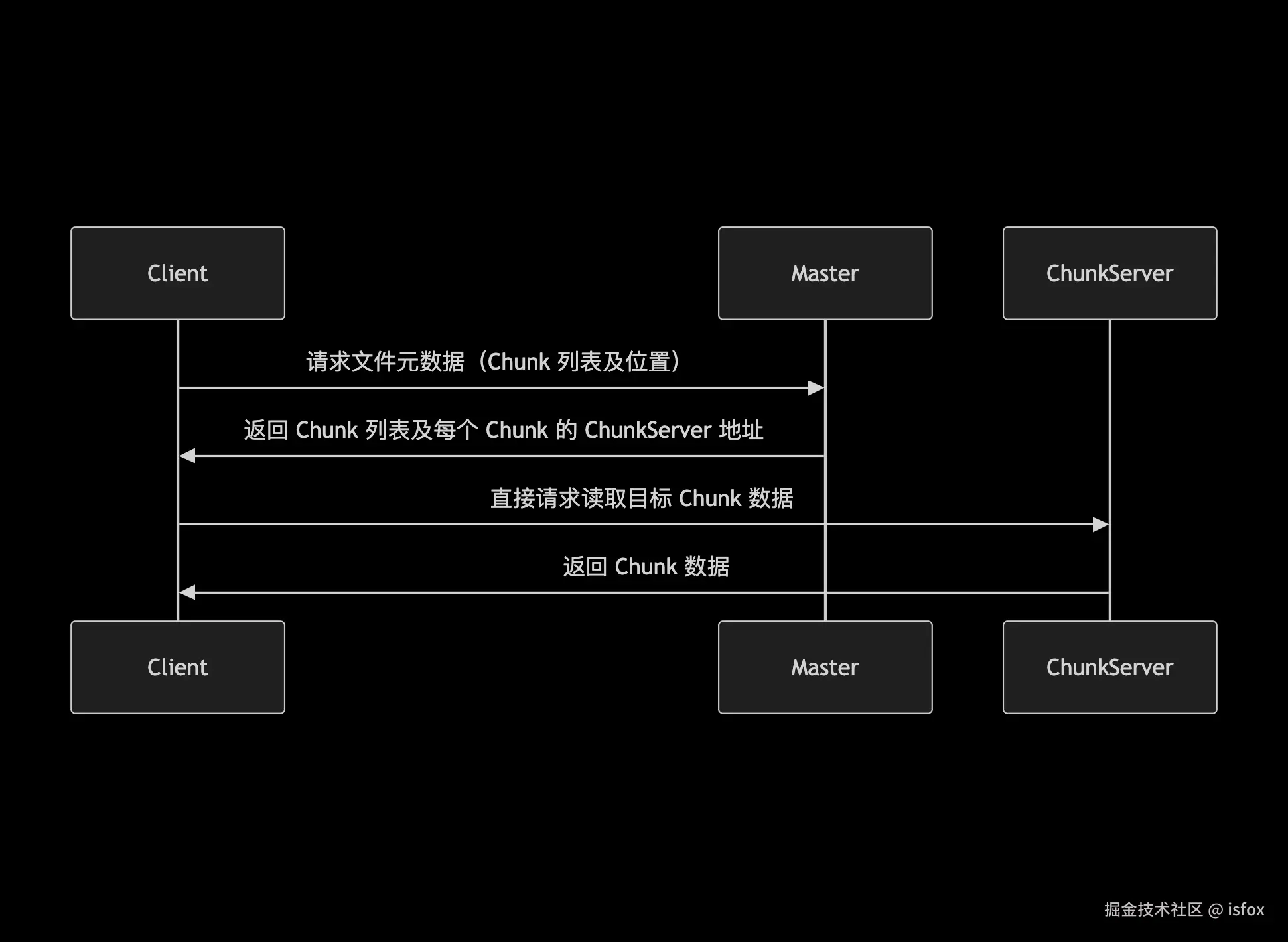
- 关键优化:Client 缓存 Chunk 位置,后续读操作无需再请求 Master。
2. 追加(Append)操作流程(基于租约机制)
- 一致性保证:Primary 确保所有副本按相同顺序写入,避免数据错乱;
- 原子性:即使并发追加,每个记录的追加操作也是原子的(要么完全成功,要么失败)。
GFS 核心技术特点总结
- 高容错性:通过多副本存储和自动故障恢复,即使节点宕机也不丢失数据;
- 高吞吐量:大 Chunk 设计和批量 IO 优化,适合大规模连续数据读写;
- 强扩展性:Master 管元数据,ChunkServer 存数据,集群规模可线性扩展;
- 简单实用:放弃部分 POSIX 接口,针对追加写和批量读优化,适配大数据场景;
- 高效协调:租约机制减少 Master 参与,提升写操作效率。
GFS 与 HDFS 的对比
HDFS 作为 GFS 的开源实现,几乎完全借鉴了 GFS 的设计理念,但存在细节差异:
| 特性 | Google GFS | HDFS(Hadoop Distributed File System) |
|---|---|---|
| 数据块大小 | 64MB | 128MB(默认,可配置) |
| 主节点 | GFS Master | NameNode |
| 从节点 | ChunkServer | DataNode |
| 分布式协调 | 依赖内部服务 | 依赖 ZooKeeper(替代 GFS 的内部协调机制) |
| 租约机制 | 用于写操作协调 | 无租约机制,由 NameNode 直接协调 |
| 主要写操作 | 追加(Append) | 追加(Append),支持有限的随机写 |
| 容错性 | 多副本(默认 3 个) | 多副本(默认 3 个) |
参考文献