
Markdown (.md) 是一种在网页开发、文档撰写和技术写作中广受欢迎的格式。其简洁直观的语法不仅能够提升写作效率,还能让内容阅读更加顺畅。然而,浏览器无法直接解析 Markdown,因此将 Markdown 转换为 HTML 是保证内容结构清晰、排版规范,并能够在各类网页平台上正常显示的关键步骤。
E-iceblue旗下Spire系 列产品 是国产文档处理领域的优秀产品,支持国产化 ,帮助企业高效构建文档处理的应用程序。本教程将展示如何使用 Python 和**++Spire.Doc for Python++** 高效实现 Markdown 到 HTML 的转换。内容涵盖详细步骤与实用代码示例,既支持单文件转换,也可进行批量处理,帮助您快速掌握完整流程,实现高效、可靠的文档转换。
什么是 Markdown?
Markdown 是一种轻量级标记语言,旨在提升可读性和易写性。与繁琐的 HTML 相比,Markdown 使用简单的语法来表示标题、列表、链接和图片等元素。
示例 Markdown:
# 这是一个标题
这是一个包含 **粗体文本** 和 *斜体文本* 的段落。
- 项目 1
- 项目 2即使在原始格式下,Markdown 也非常易于阅读,这使得它在文档、博客、README 文件和技术写作中备受青睐。
为什么要将 Markdown 转换为 HTML?
虽然 Markdown 非常适合撰写内容,但网页浏览器并不能直接解析它。将 Markdown 转换为 HTML 可以为您带来以下好处:
- 网站发布:大多数内容管理系统需要使用 HTML 格式来发布网页内容。
- 增强样式:HTML 支持 CSS 和 JavaScript,使您能够实现更加复杂的格式和交互效果。
- 保持兼容性:HTML 在所有主流浏览器中得到广泛支持,确保您的内容能够正确显示。
- 与 Web 框架集成:如 React、Vue 和 Angular 等框架都依赖于 HTML 作为渲染组件的基础。
通过将 Markdown 转换为 HTML,您可以充分利用这些优势,提升内容的展示效果和用户体验。
Spire.Doc for Python 介绍
Spire.Doc for Python是一个多功能的文档处理库,能够读取 Word 文档和 Markdown 文件,并将内容导出为 HTML。这个库让开发者可以用极少的代码轻松地将 Markdown 转换为 HTML,同时保持良好的格式和结构。
此外,++Spire.Doc for Python++ 还支持 将 Markdown 转换为 Word 或 PDF,这使其成为一个完整的解决方案,适合希望使用同一工具处理 Markdown 并输出为多种格式的开发者。
使用++Spire.Doc for Python++进行 Markdown 到 HTML 转换的优势
- 易于使用的 API:提供简单直观的方法,显著减少开发工作量。
- 精准的格式保留:能够完美保留所有 Markdown 元素,如标题、列表和链接。
- 无额外依赖:不需要手动解析或依赖第三方库,使用方便。
- 灵活性:支持单文件转换和批量处理,满足不同需求。
如何使用 Python 将 Markdown 转换为 HTML
现在您已经了解了将 Markdown 转换为 HTML 的目的和好处,接下来,我们将逐步演示如何在 Python 中将 Markdown 文件转换为适合网页使用的 HTML。
步骤 1:安装 Spire.Doc for Python
首先,确保在您的环境中安装了 Spire.Doc for Python。您可以通过运行以下 pip 命令从 PyPI 安装它:
pip install spire.doc步骤 2:准备 Markdown 文件
接下来,创建一个示例 Markdown 文件,例如 example-zh.md,作为转换的对象。
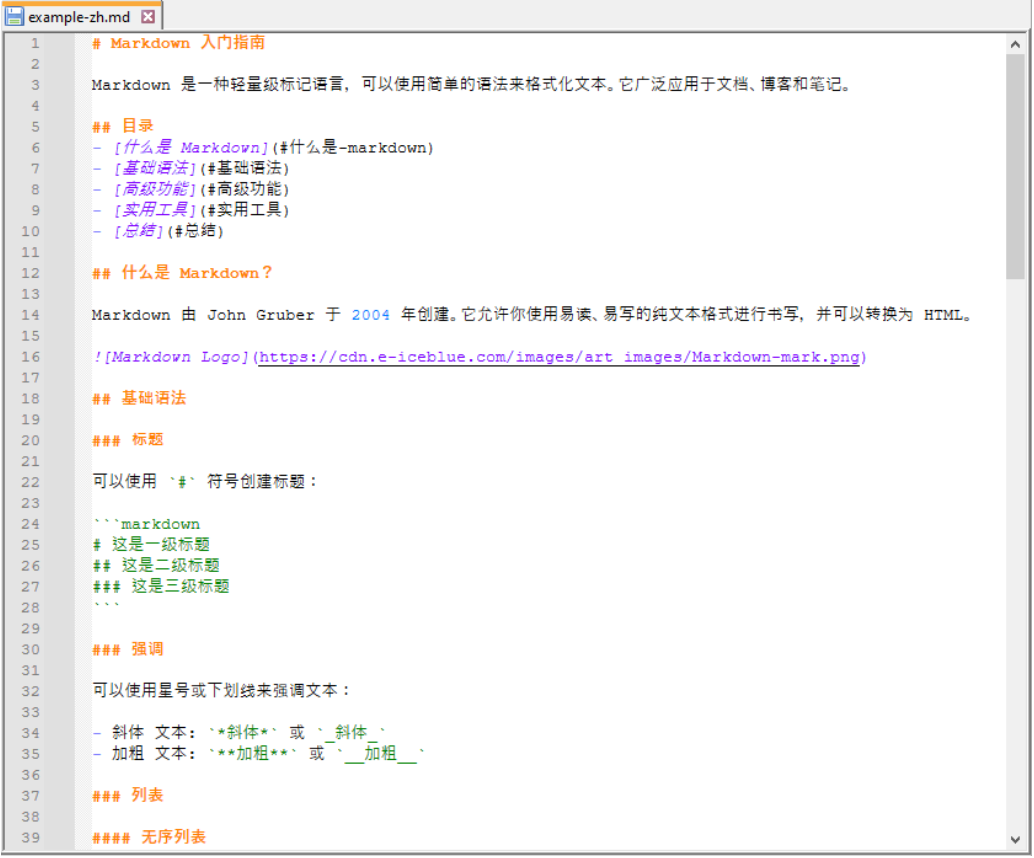
步骤 3:编写 Python 脚本
编写一个 Python 脚本,加载 Markdown 文件并将其转换为 HTML:
from spire.doc import *
# 创建 Document 对象
doc = Document()
# 从文件加载 Markdown
doc.LoadFromFile("example-zh.md", FileFormat.Markdown)
# 将文档保存为 HTML
doc.SaveToFile("example-zh.html", FileFormat.Html)
# 关闭文档
doc.Close()代码说明:
- Document():初始化一个新的Document对象。
- LoadFromFile("example-zh.md", FileFormat.Markdown):将 Markdown 文件加载到Document对象中。
- SaveToFile("example-zh.html", FileFormat.Html):将内容转换为 HTML 并保存到磁盘。
- doc.Close():确保资源正确释放,这在处理多个文件或执行批处理时尤为重要。
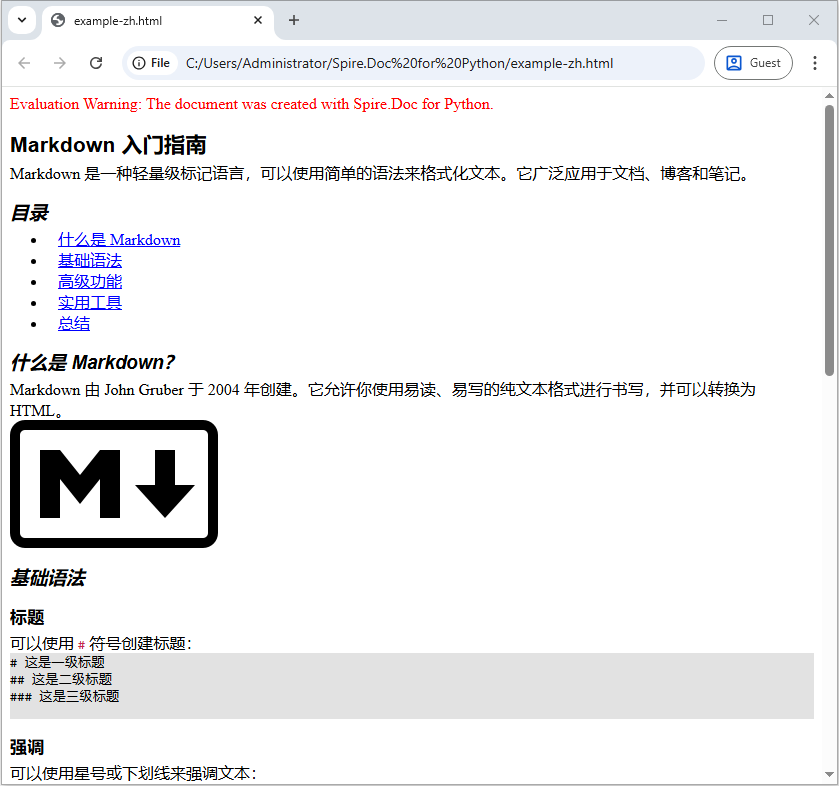
步骤 4:验证 HTML 输出
最后,在网页浏览器或 HTML 编辑器中打开生成的 example-zh.html 文件,确认 Markdown 内容是否已正确转换。
自动化批量转换多个 Markdown 文件为 HTML
您可以自动化地转换文件夹中的多个 Markdown 文件。以下是示例代码:
import os
from spire.doc import *
# 设置包含 Markdown 文件的文件夹
input_folder = "markdown_files"
# 设置 HTML 文件保存的文件夹
output_folder = "html_files"
# 如果输出文件夹不存在,则创建
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
# 仅处理 Markdown 文件
if filename.endswith(".md"):
# 为每个文件创建一个新的 Document 对象
doc = Document()
# 将 Markdown 文件加载到 Document 对象中
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Markdown)
# 设置输出文件路径
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# 将 Markdown 内容保存为 HTML
doc.SaveToFile(output_file, FileFormat.Html)
# 关闭文档以释放资源
doc.Close()这种方法能够高效处理多个 Markdown 文件,并自动生成相应的 HTML 文件。通过批量转换,您可以节省时间并提升工作效率。
Markdown 到 HTML 转换的实用建议
虽然以上步骤已经可以完成 Markdown 到 HTML 的转换,但遵循一些实用建议可以帮助您避免常见问题,提升转换质量和输出效果:
- 使用正确的 Markdown 语法:确保标题、列表、链接和强调的书写规范。
- 使用 UTF-8 编码:始终以 UTF-8 编码保存 Markdown 文件,以避免特殊字符或非英文文本的问题。
- 批量处理:如果需要转换多个文件,可以将脚本放入循环中,处理整个文件夹。这样不仅节省时间,还能确保文件格式一致。
- 丰富样式:HTML 允许您添加 CSS 和 JavaScript,以实现自定义布局、响应式设计和交互性,这是原始 Markdown 所无法实现的。
总结
通过使用 Python 和 Spire.Doc,您可以轻松将 Markdown 文件转换为 HTML。这种方法不仅高效便捷,还能完整保留文档的格式和结构,确保生成的 HTML 输出既美观又实用。无论您是处理单个文件还是进行批量转换,按照本指南的步骤,您都能高效地完成任务,提升工作效率。
常见问题解答
Q1: 我可以在 Python 中将多个 Markdown 文件转换为 HTML 吗?
A1: 可以。您可以通过遍历目录中的 Markdown 文件,并对每个文件应用转换逻辑,实现批量转换。
Q2: 转换后的 HTML 会保留所有 Markdown 的格式吗?
A2: 会。Spire.Doc 能够有效保留 Markdown 格式,包括标题、列表、粗体、斜体文本、链接等。
Q3: 在转换过程中如何处理 Markdown 中的图片?
A3: Spire.Doc 支持转换嵌入在 Markdown 中的图片,确保它们保留在生成的 HTML 中。
Q4: 除了 Spire.Doc,我还需要其他库吗?
A4: 不需要额外的库。Spire.Doc for Python 提供了一个全面的解决方案,可以在没有外部依赖的情况下将 Markdown 转换为 HTML。
Q5: 我可以在 Web 框架中使用生成的 HTML 吗?
A5: 可以,生成的 HTML 与流行的 Web 框架(如 React、Vue 和 Angular)完全兼容。