分层校验的原则
一、动静分离
将静态数据和动态数据分开处理,静态数据(如商品详情页等)尽量缓存在客户端或前端服务器,减少后端服务器的压力。
二、缓存策略
将大量的读数据缓存在Web端或客户端浏览器,减少对数据库的直接访问,提高响应速度。
三、一致性校验
对读数据不做强一致性校验,以减少系统瓶颈。
对写数据行强一致性校验,确保数据的准确性和一致性。
时间分片对写数据进行基于时间的合理分片,过滤掉过期的或无效的请求。
限流保护对写请求进行限流,防止系统过载,确保系统在高并发下的稳定性。
对大流量系统的数据做分层校验也是一项重要的设计原则,分层校验就是用"漏斗"式的设计来处理请求,如下图
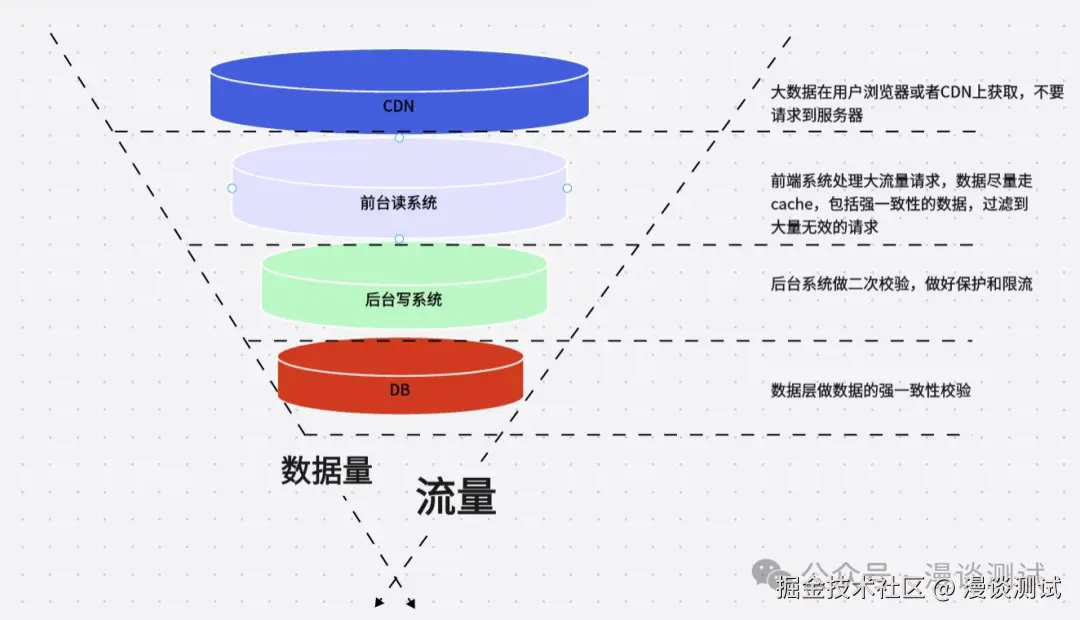
它的核心思想是在不同的层次、不断尽可能地过滤掉无效请求,只有"漏斗"最末端的才是有效请求 要达到此效果就必须对数据做分层的校验,以下是分层校验基本原则:
- 先做数据的动静分离;
- 将90%的数据缓存在客户端浏览器;
- 将动态请求的读数据 Cache Web 端;
- 对读数据不做强一致性校验;
- 对写数据进行基于时间的合理分片
- 对写请求做限流保护;
- 对写数据进行强一致性校验。
分层校验具体实现
一、前端校验
用户资格检查:检查用户是否具有参与秒杀的资格。
商品状态检查:检查商品是否处于可售状态。
秒杀状态检查:检查秒杀活动是否已经开始或已经结束。
答题验证(如适用):验证用户是否通过了某些答题验证。
二、中间件校验
在应用层或中间件层进行进一步校验,如检查请求是否合法、营销等价物(如优惠券、淘金币等)是否充足等。
三、后端校验
在写数据系统中进行最终校验,如检查库存是否充足、订单信息是否完整等。
使用数据库事务机制保证数据的一致性,如在下单减库存时,通过数据库事务控制库存的减少。
秒杀系统正是按照这个原则设计的,它的系统架构如下图所示
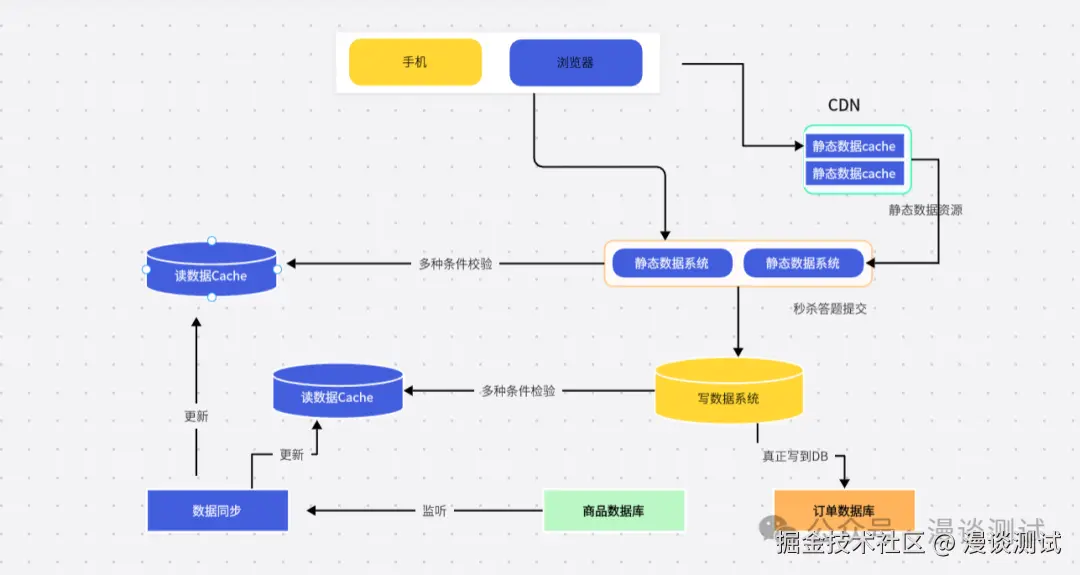
把大量静态、不需要检验的数据放在离用户最近的地方;在前端读系统中检验一些基本信息如用户是否具有秒杀资格 、商品状态是否正常 用户答题是否正确 、秒杀是否已经结束等;在写数据系统中再校验一些信息:是否非法请求、营销等价物(淘金币等)是否充足、写的数据一致性(检查库存)如何......最后在数据库层保证数据最终准确性(如库存不能减为负数)
分层校验的优势
提高系统响应速度,通过缓存和动静分离,减少了对数据库的访问次数,提高了系统的响应速度。
增强系统稳定性,通过限流和分片策略,防止了系统在高并发下的过载和崩溃。
保证数据准确性,通过强一致性校验和数据库事务机制,确保了数据的准确性和一致性。