在进行数据集成与同步时,PostgreSQL等数据库中的超大表(亿级数据)一直是ETL过程的挑战所在。传统的单线程、全量拉取方式不仅效率低下,更极易造成内存溢出(OOM)和网络拥堵,导致任务失败,影响整个数据流程。
一、配置数据源。
本次演示使用ETLCloud平台同步一千万的表的数据,将数据从postgresql同步到mysql中去。
来到平台首页进入数据源管理模块。
添加postgresql数据源连接。
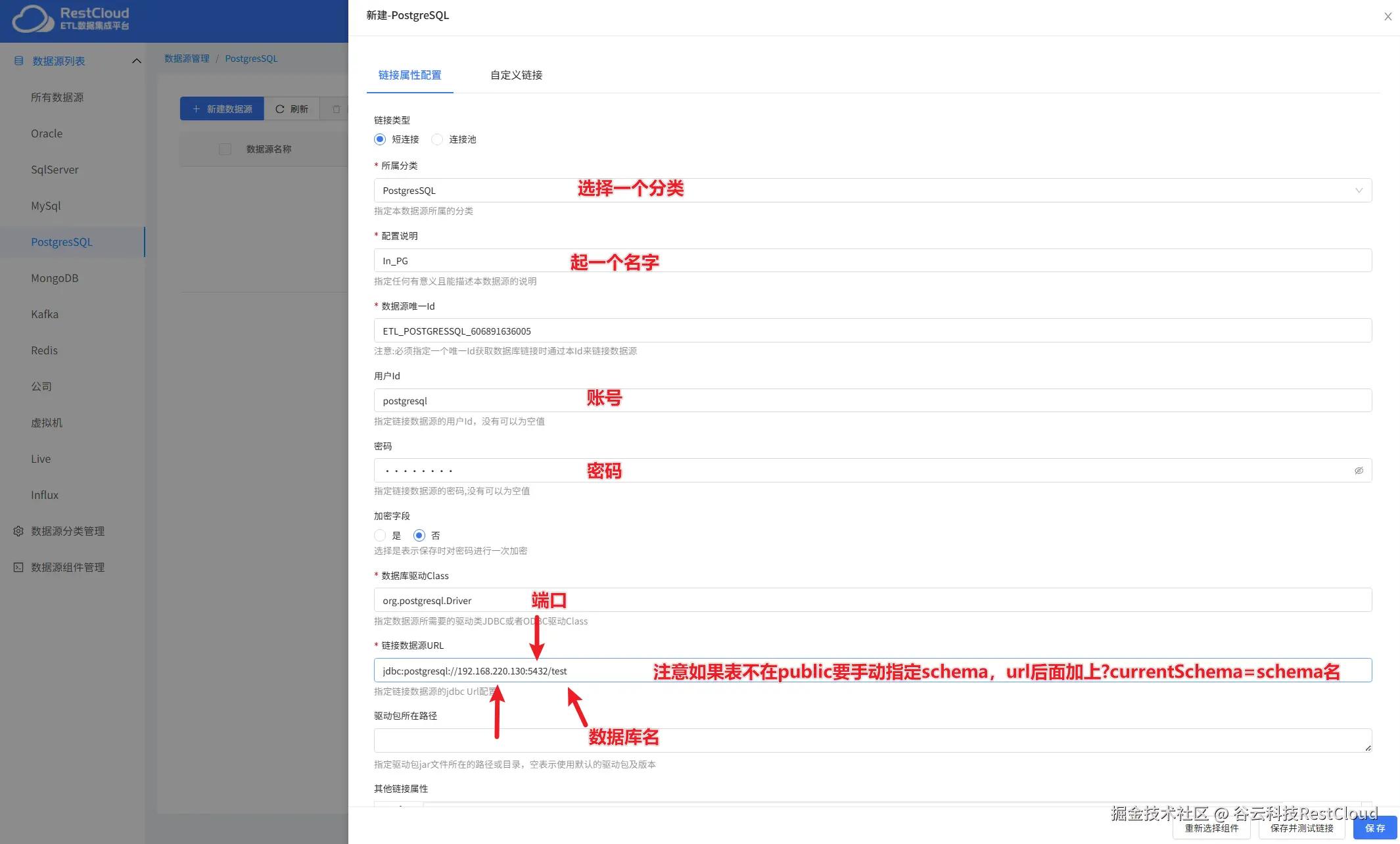
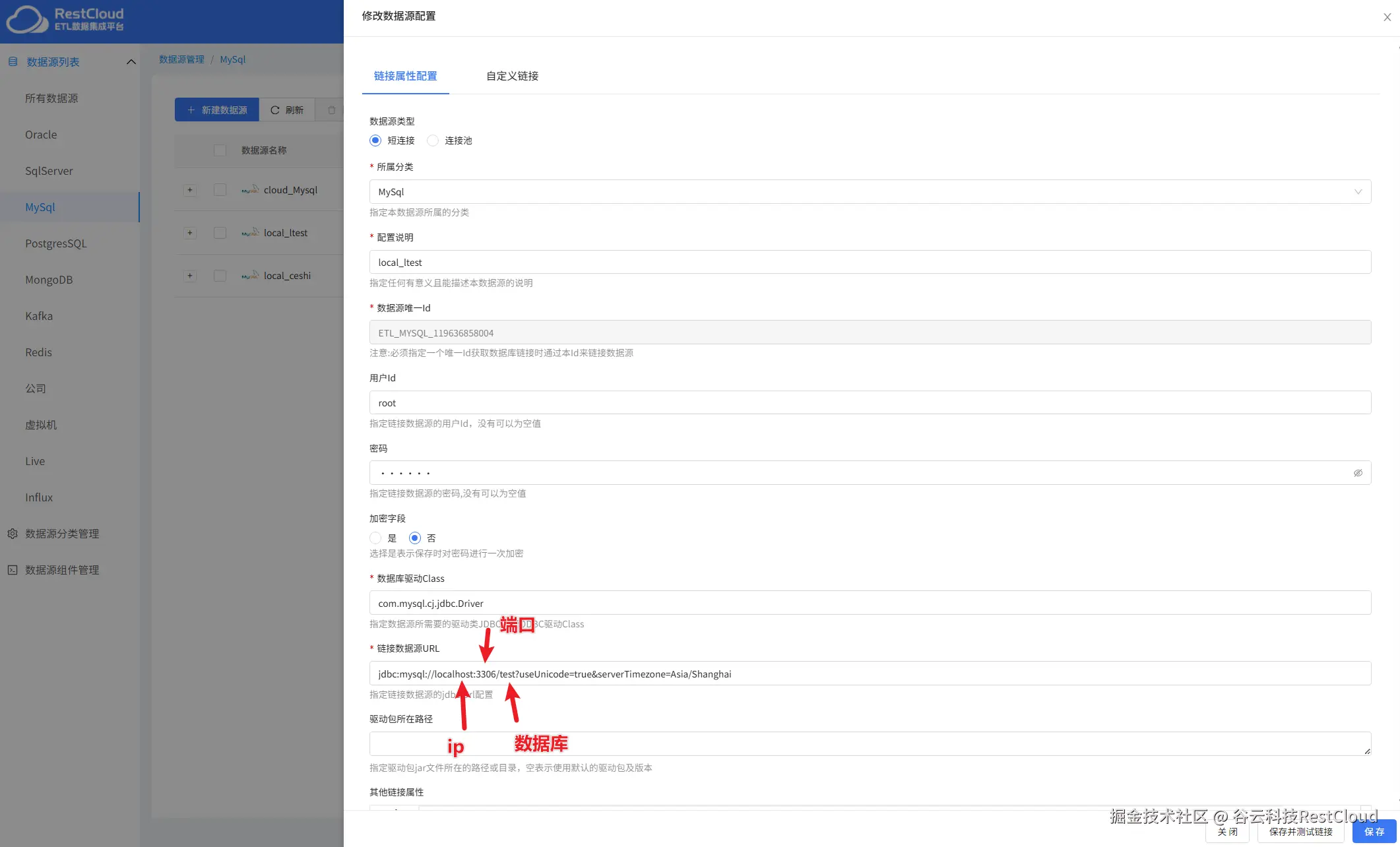
根据实际情况配置连接,注意url的配置。
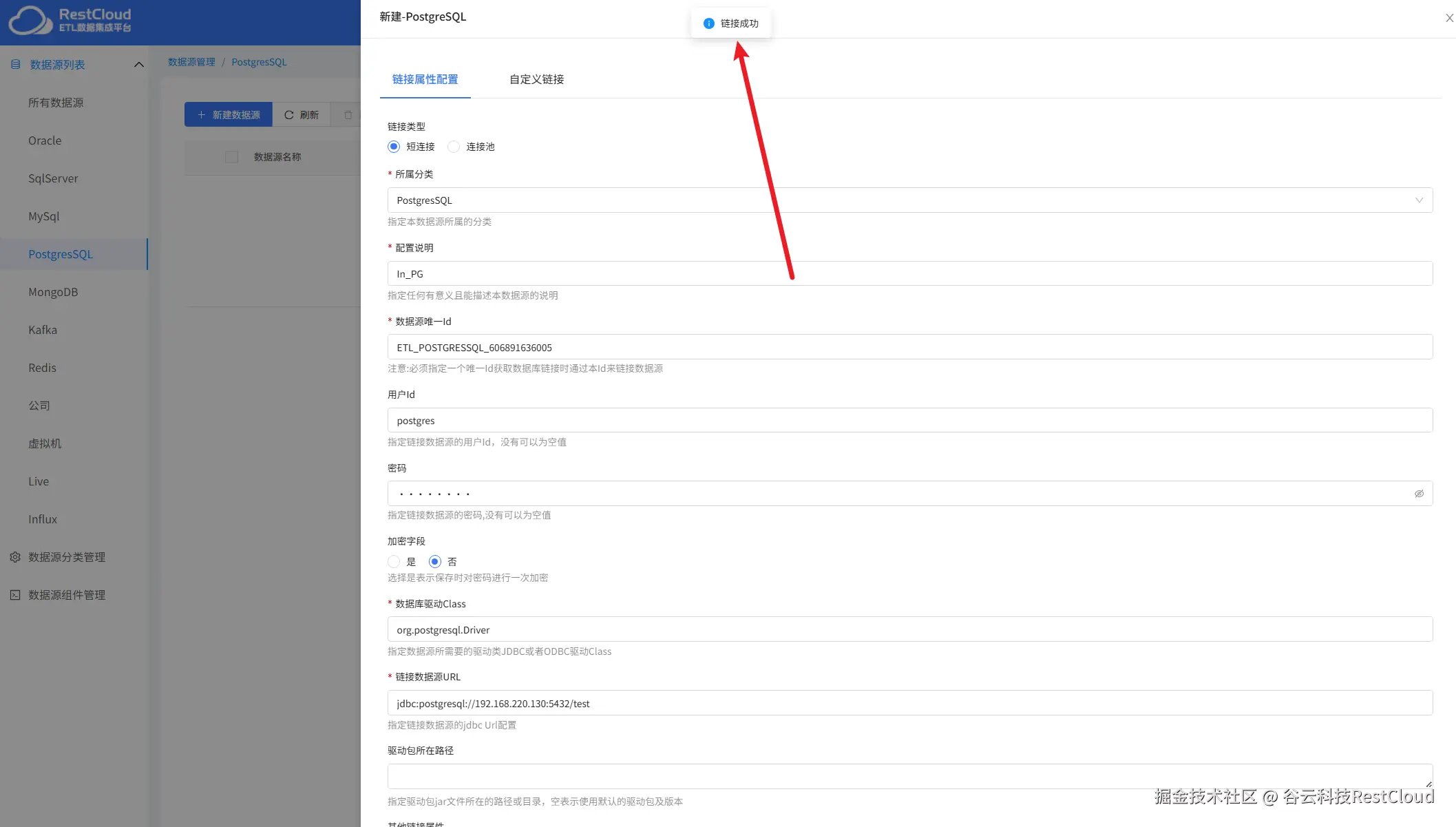
配置完成后点击保存并测试提示链接成功即可。
用同样的步骤再次配置一个目标端mysql数据源的链接。
现在postgresql有一张数据量是一千万的表。

二、同步流程设计
内存溢出(OOM)的解决方案 - 自动化分页机制
面对大表,初学者常会使用SELECT * FROM table这样的查询。一旦数据量超过JVM或客户端工具的内存限制,结果就是任务崩溃。
ETLCloud的应对策略:自动分页读取
ETLCloud无需用户编写复杂代码,即可实现高效、安全的分页查询。其流程设计如下:
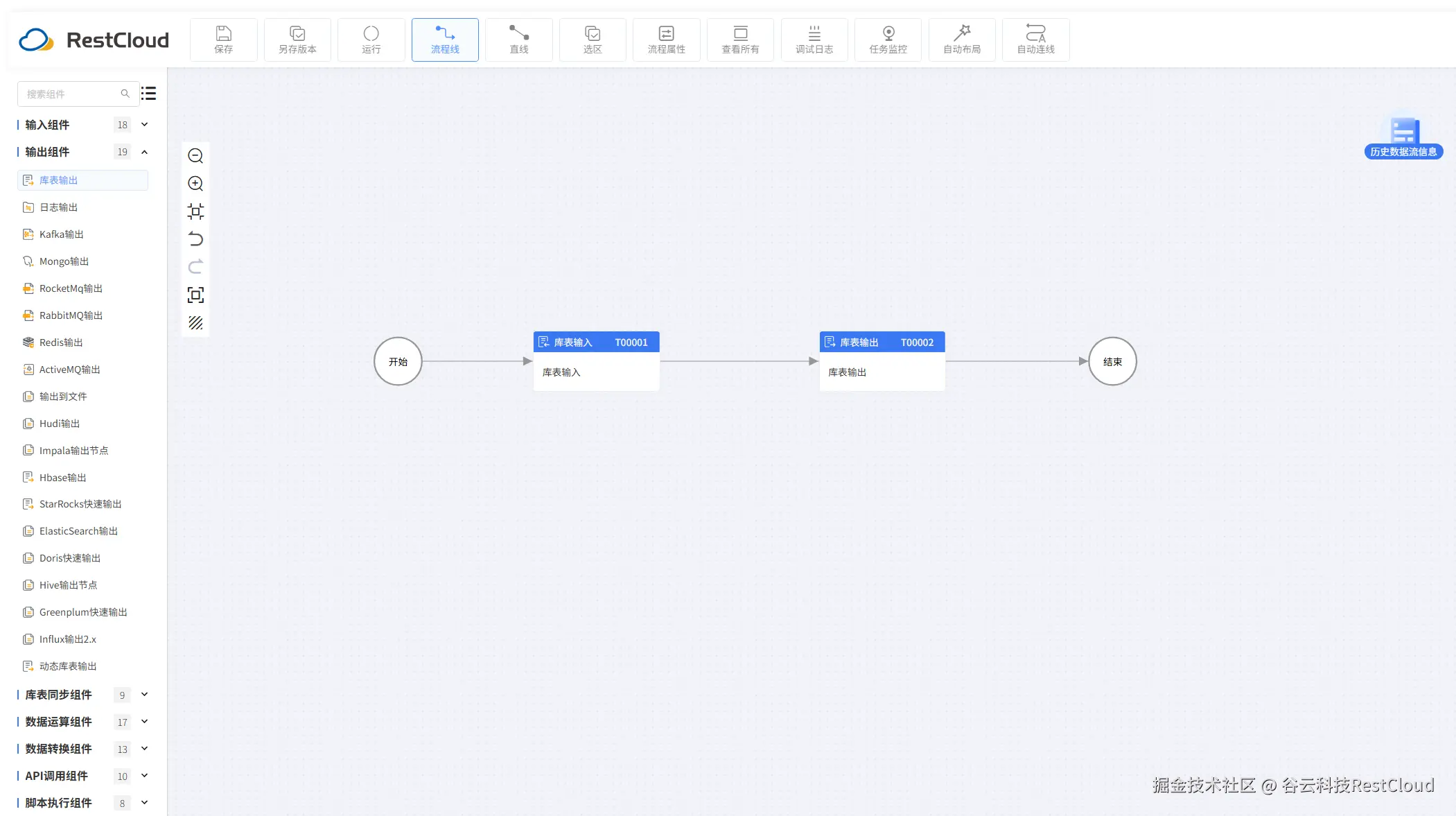
库表输入配置:
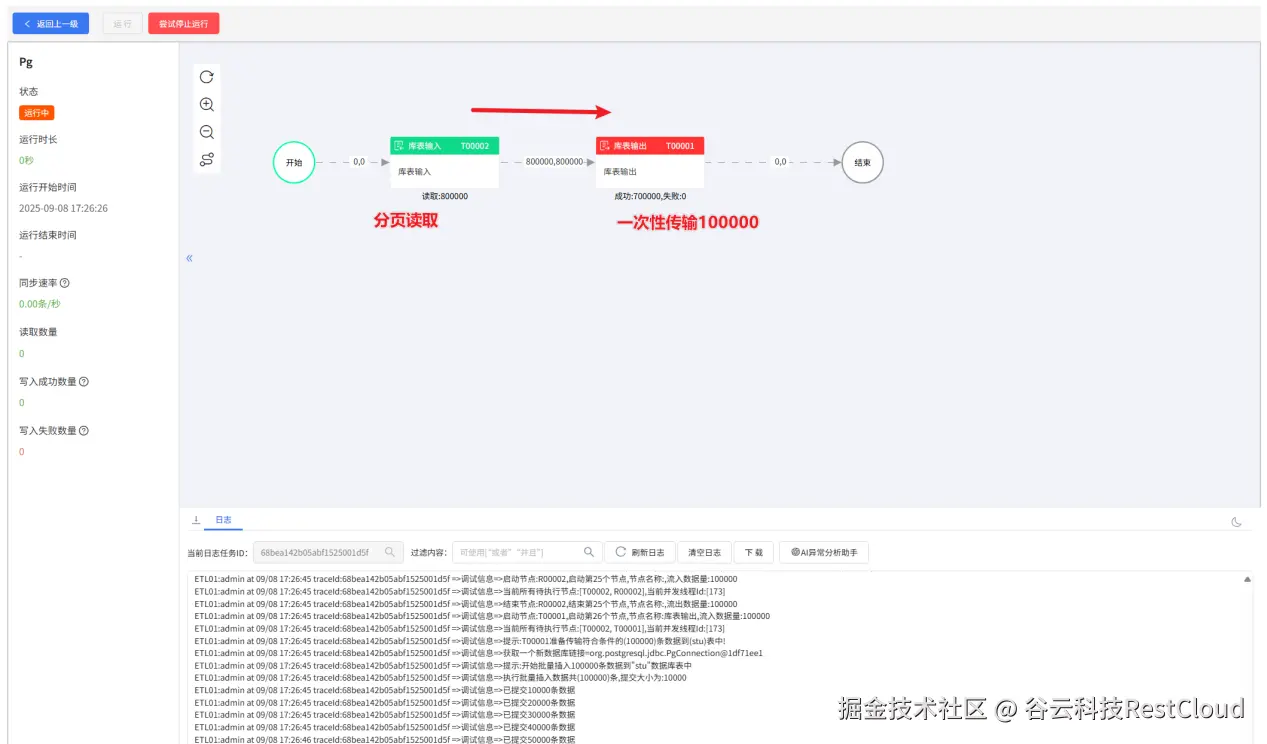
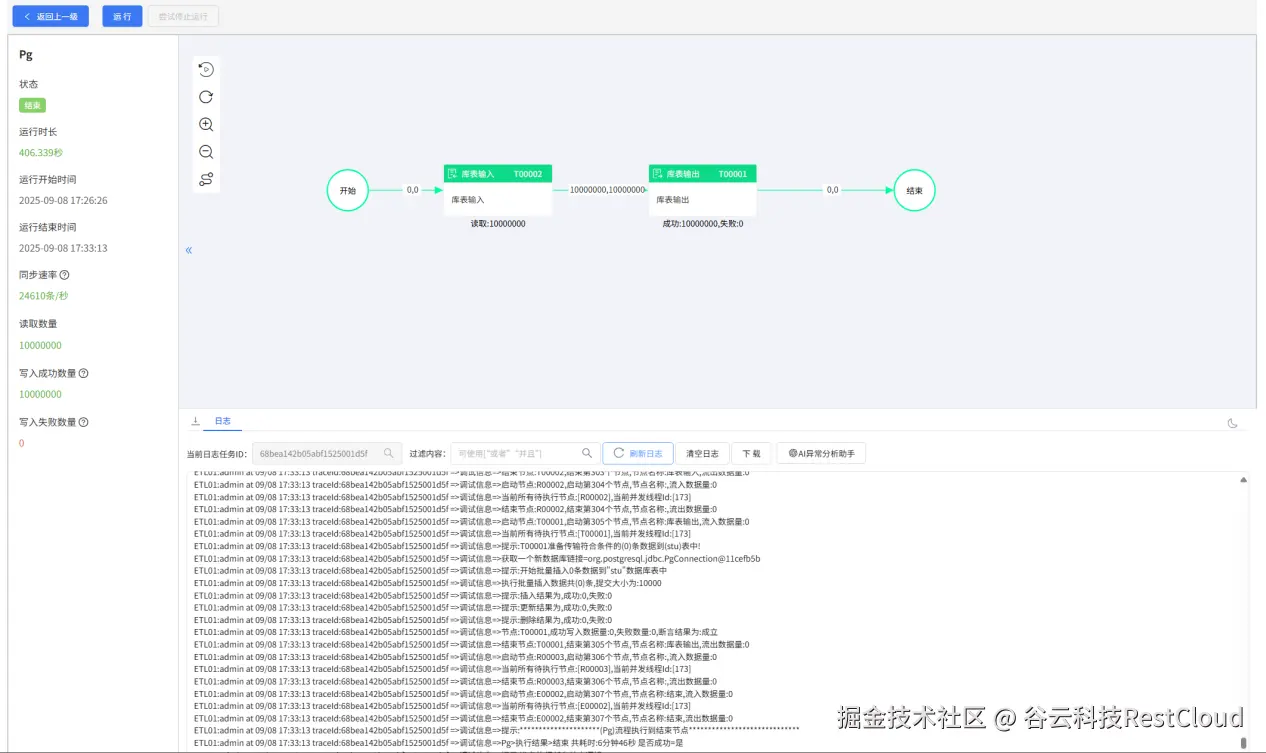
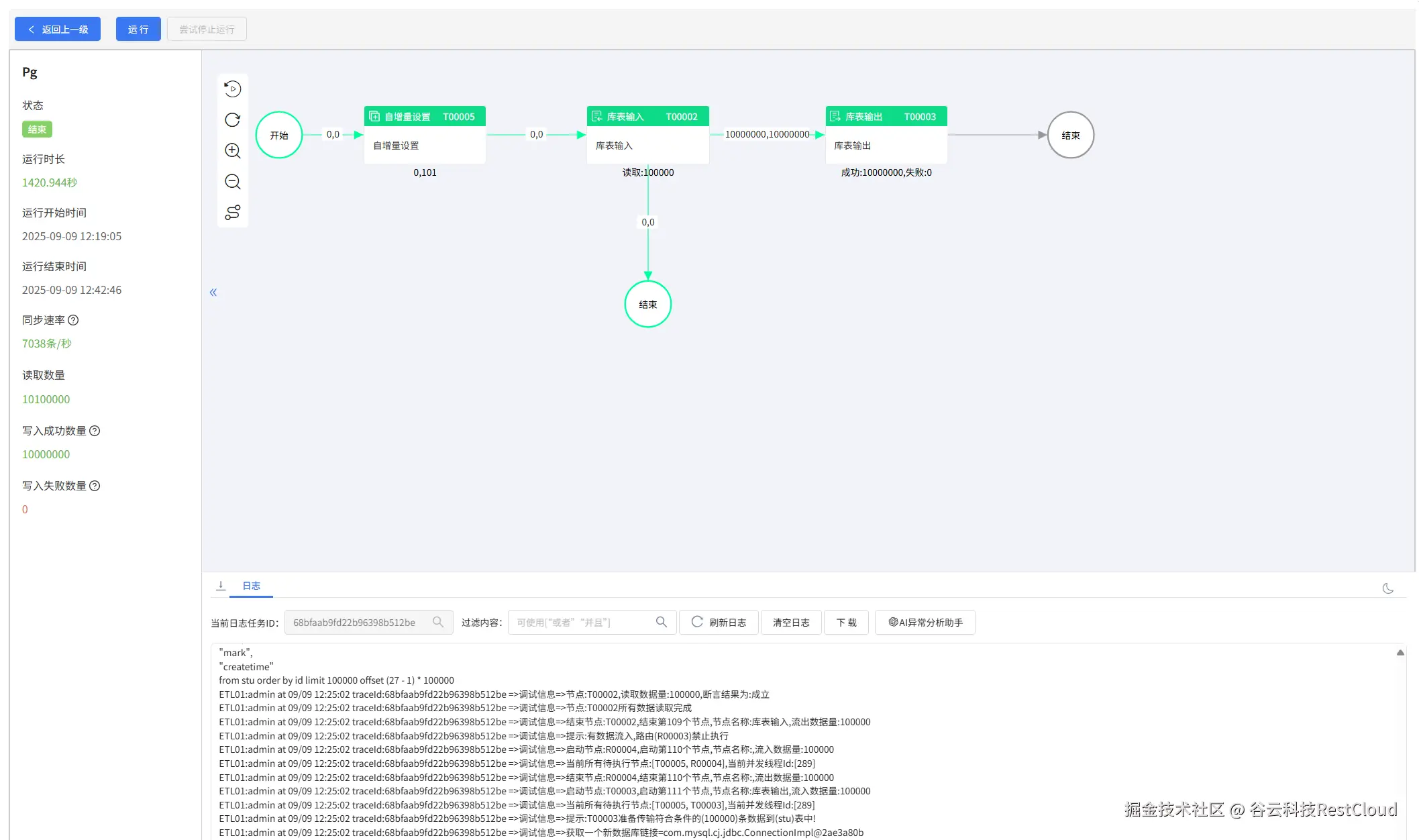
运行流程,可以看到,每次传输十五万的数据,自动实现了分页传输同步。
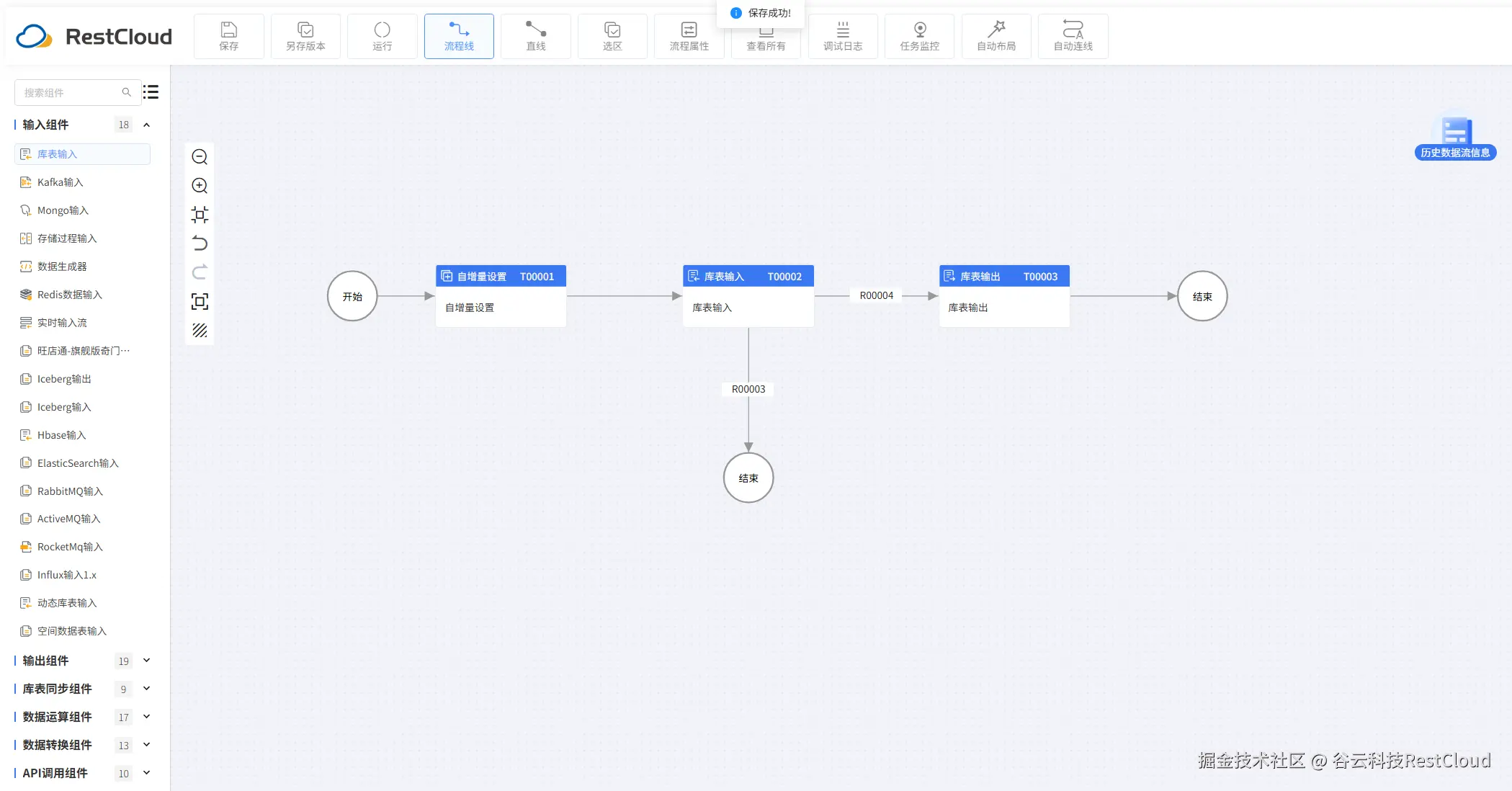
除了使用库表输入自带的分页配置,还可以手动设置循环去获取数据.
流程设计如图:
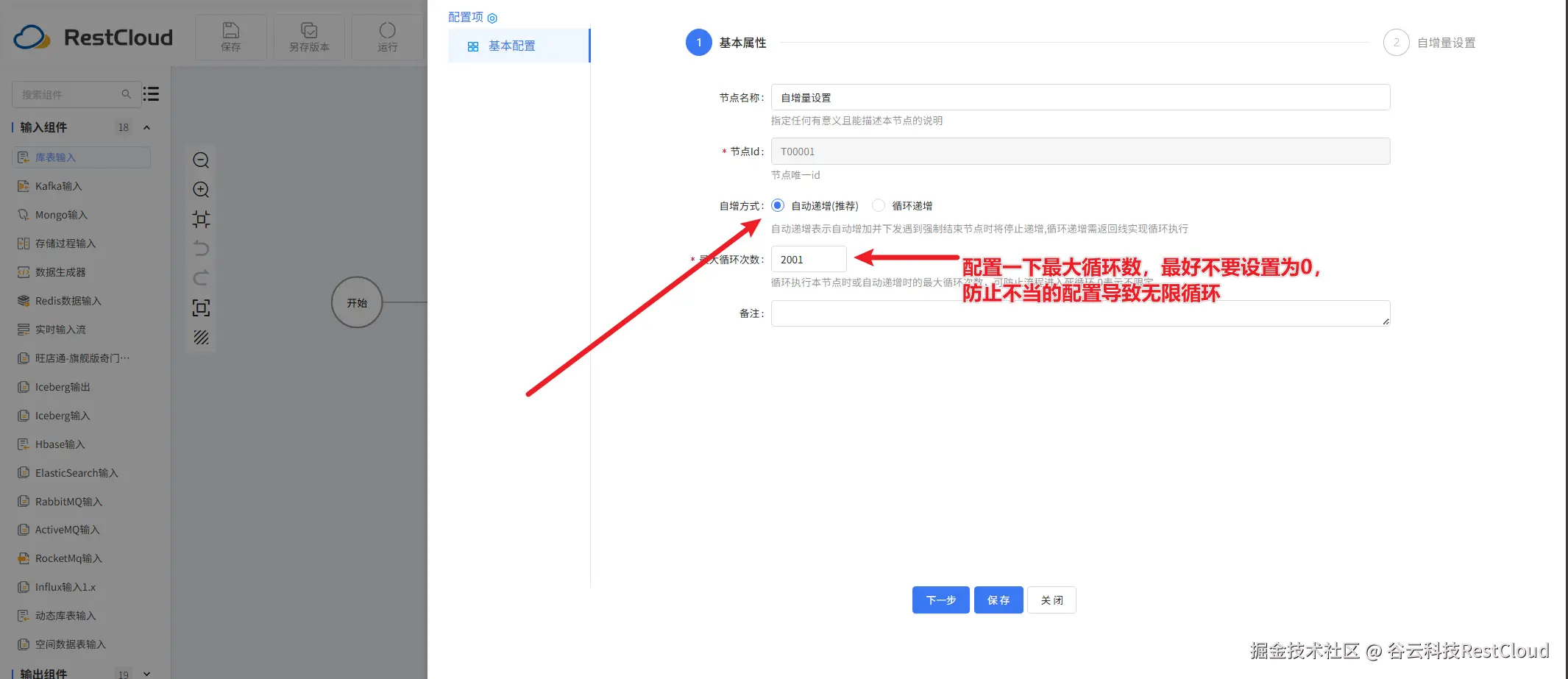
自增量设置组件要设置两个参数:
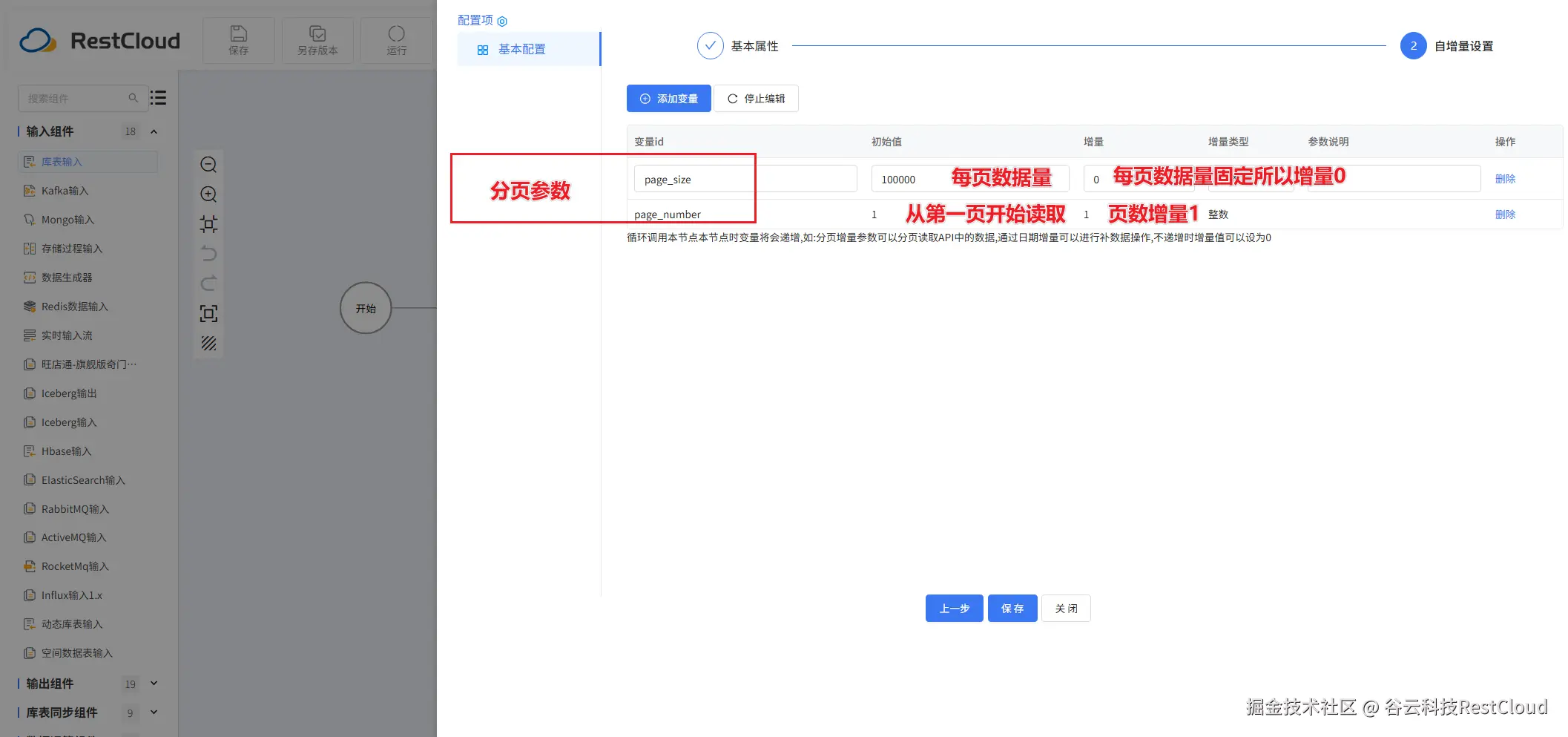
库表输入
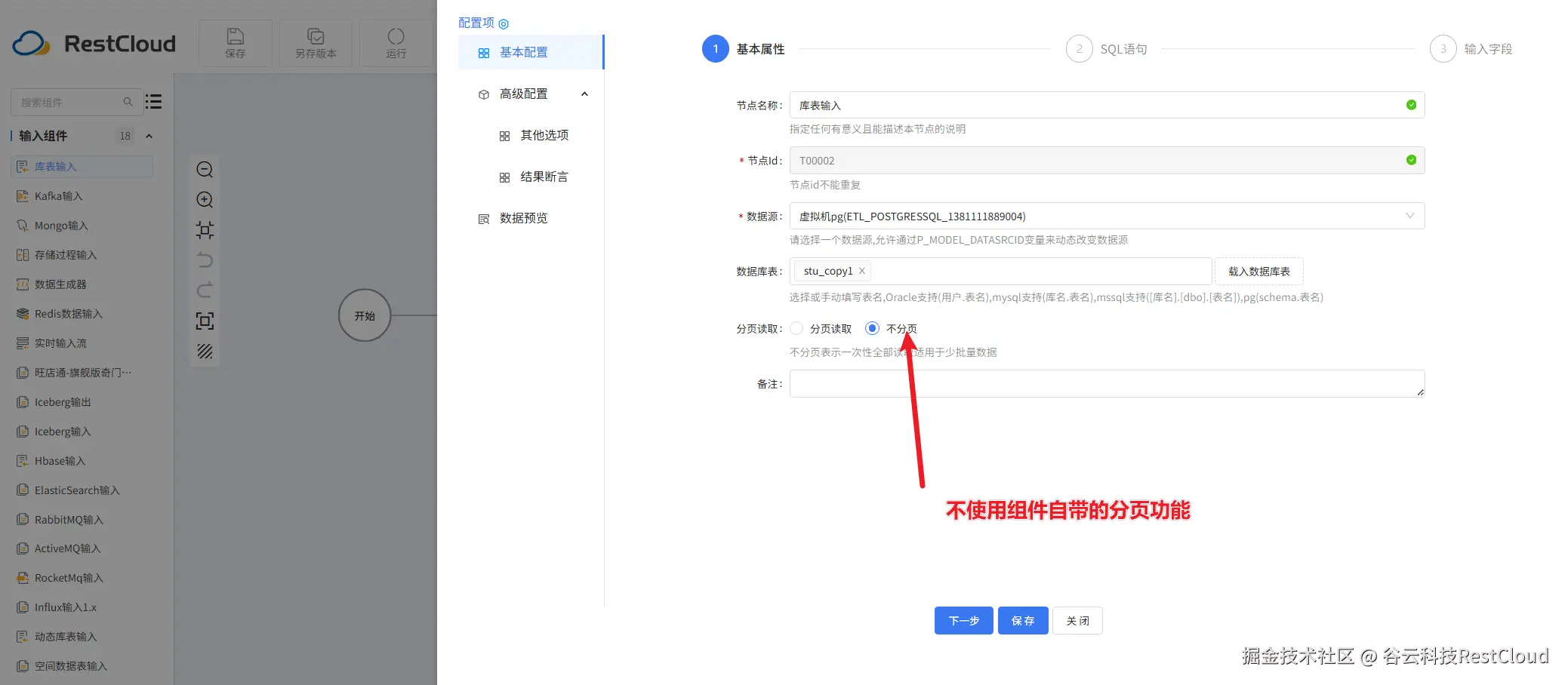
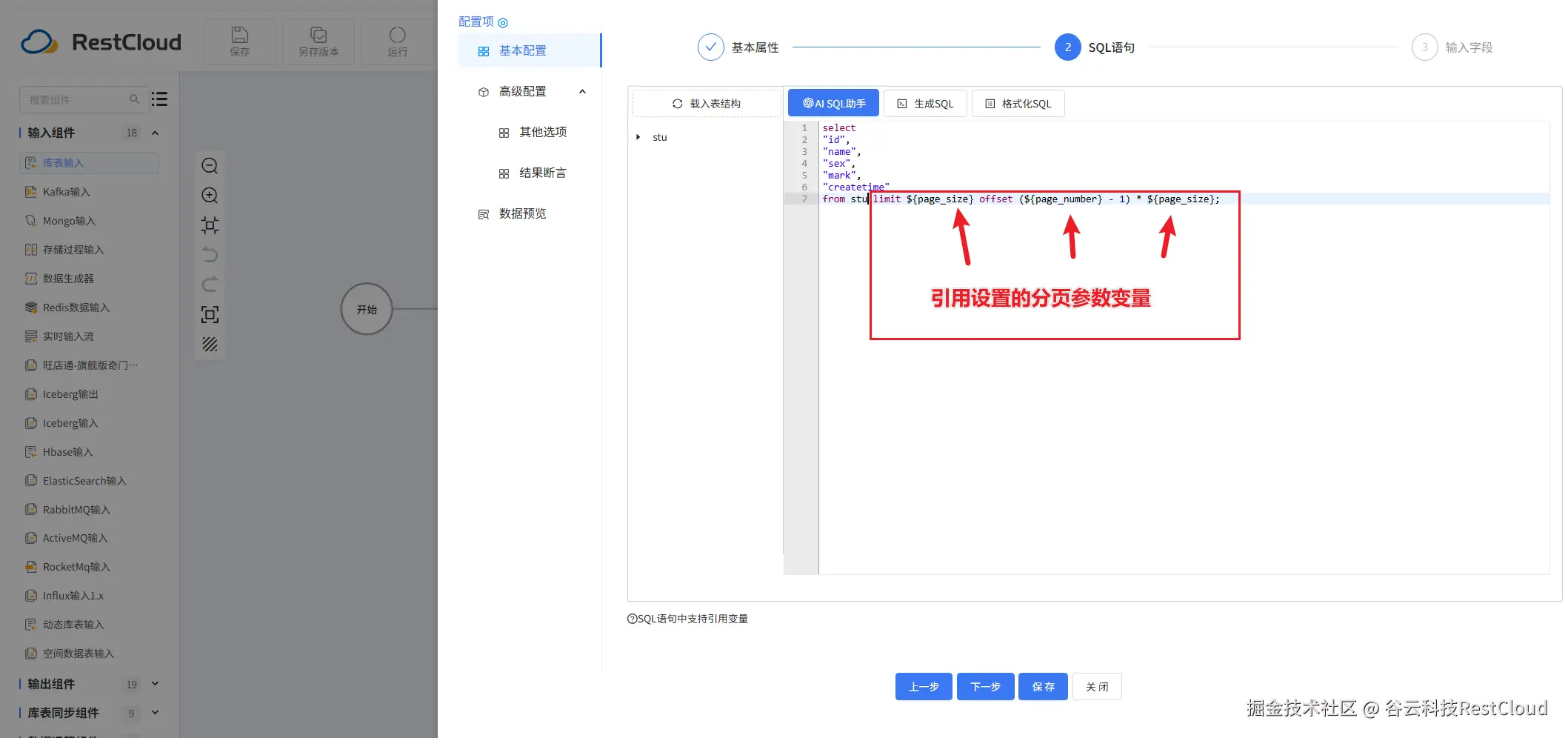
sql语句要进行改造
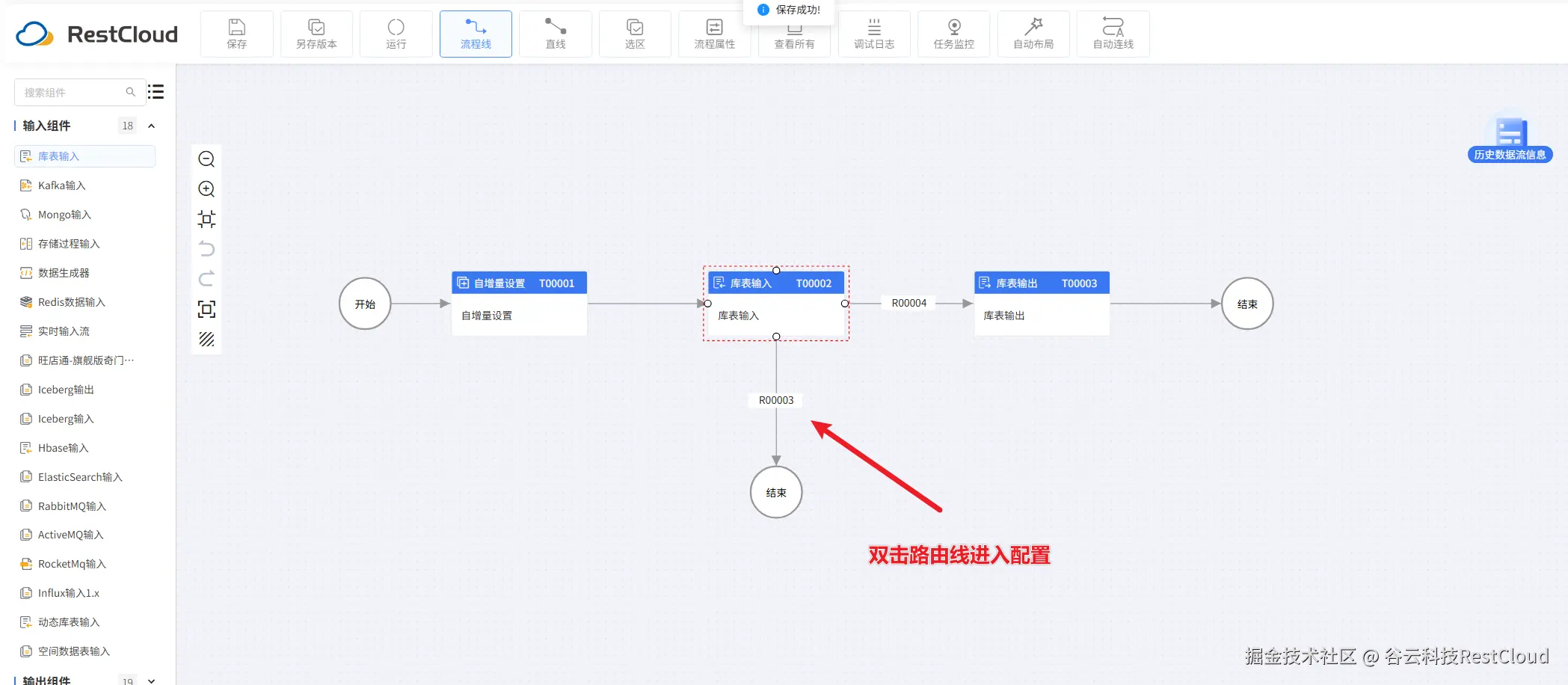
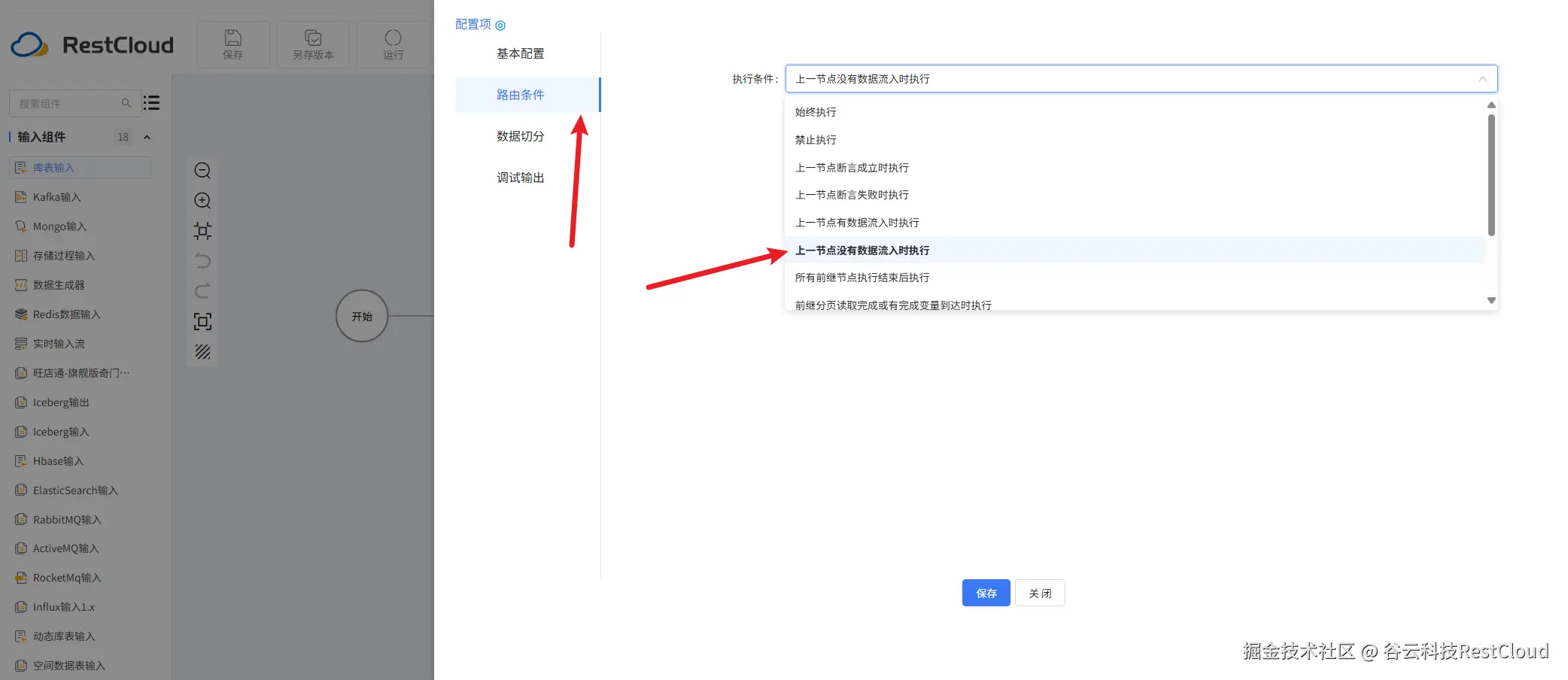
注意下面两条分支要配置路由条件
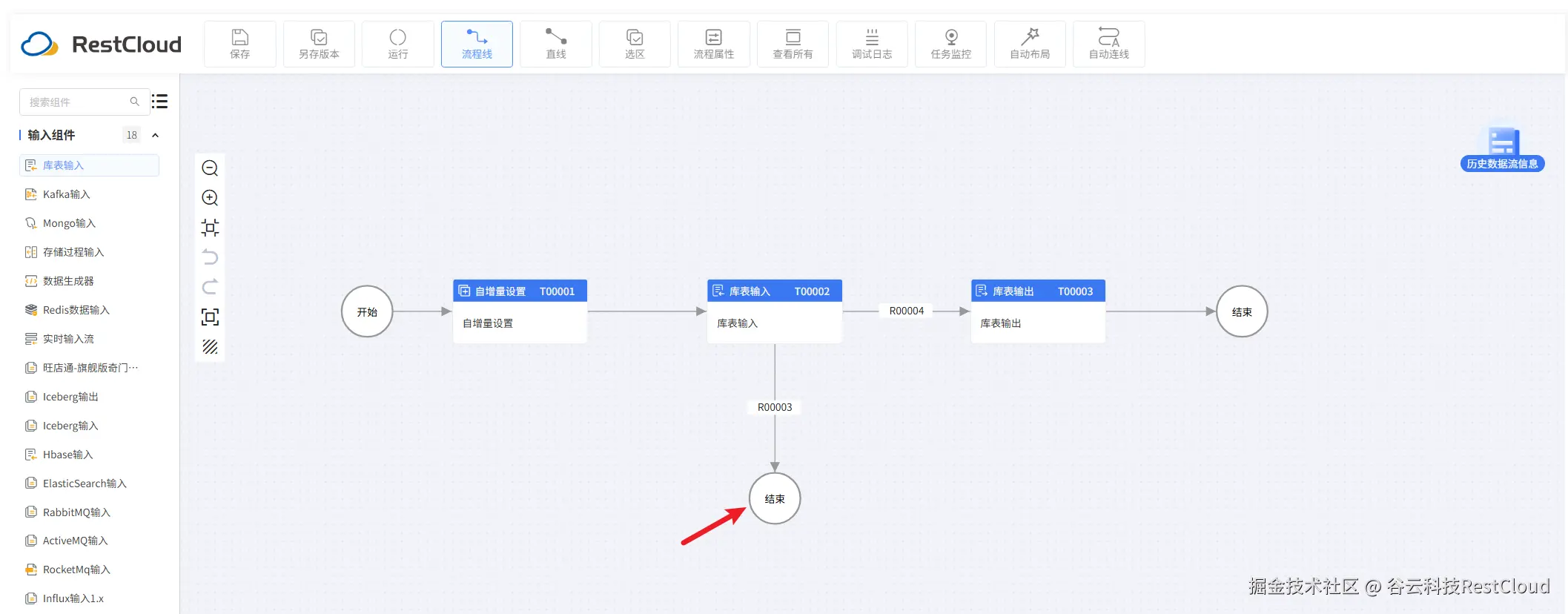
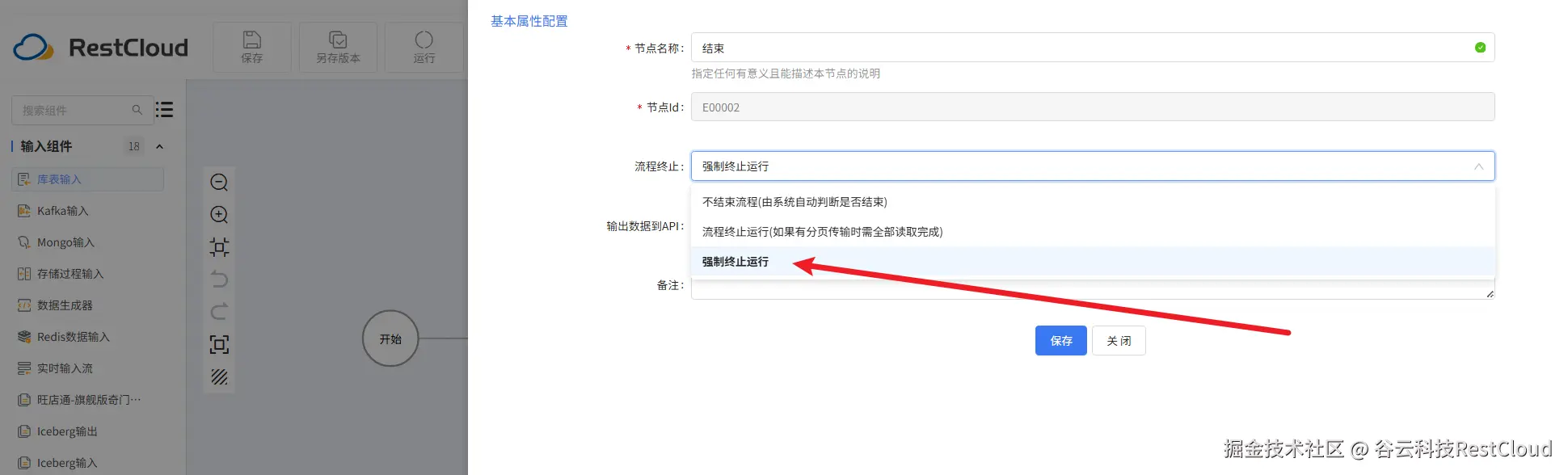
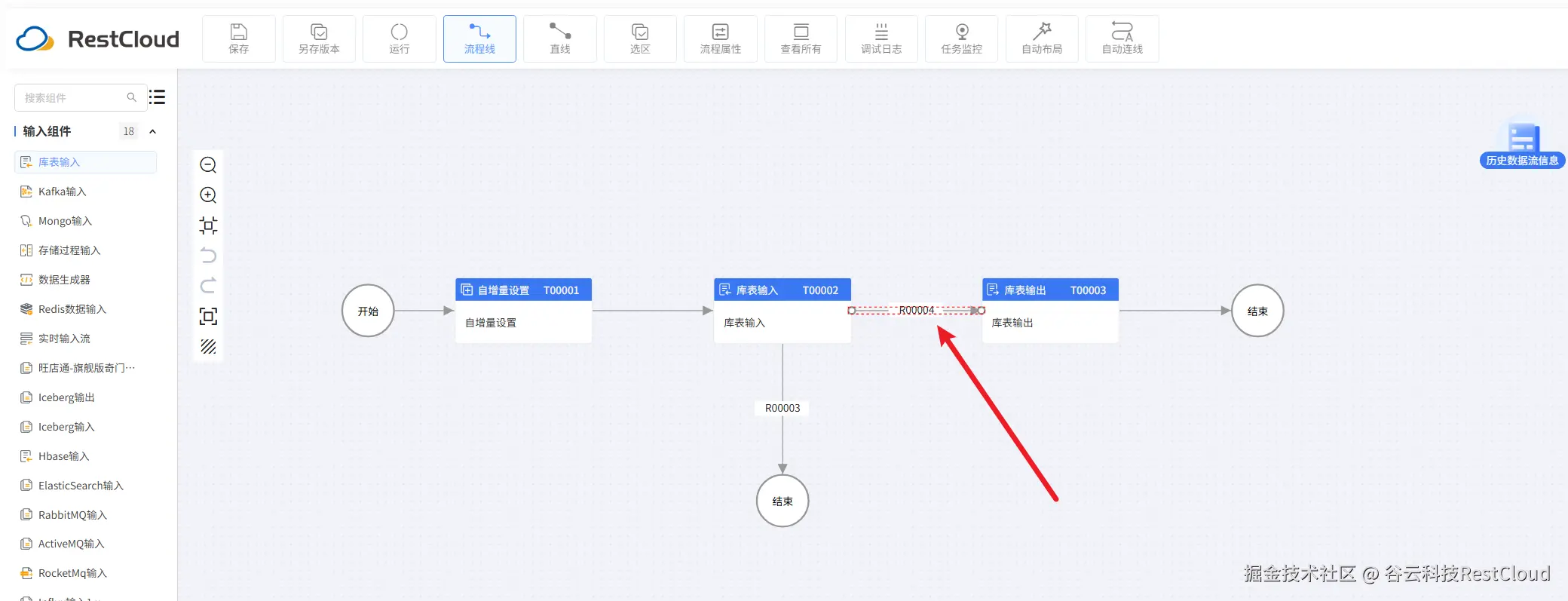
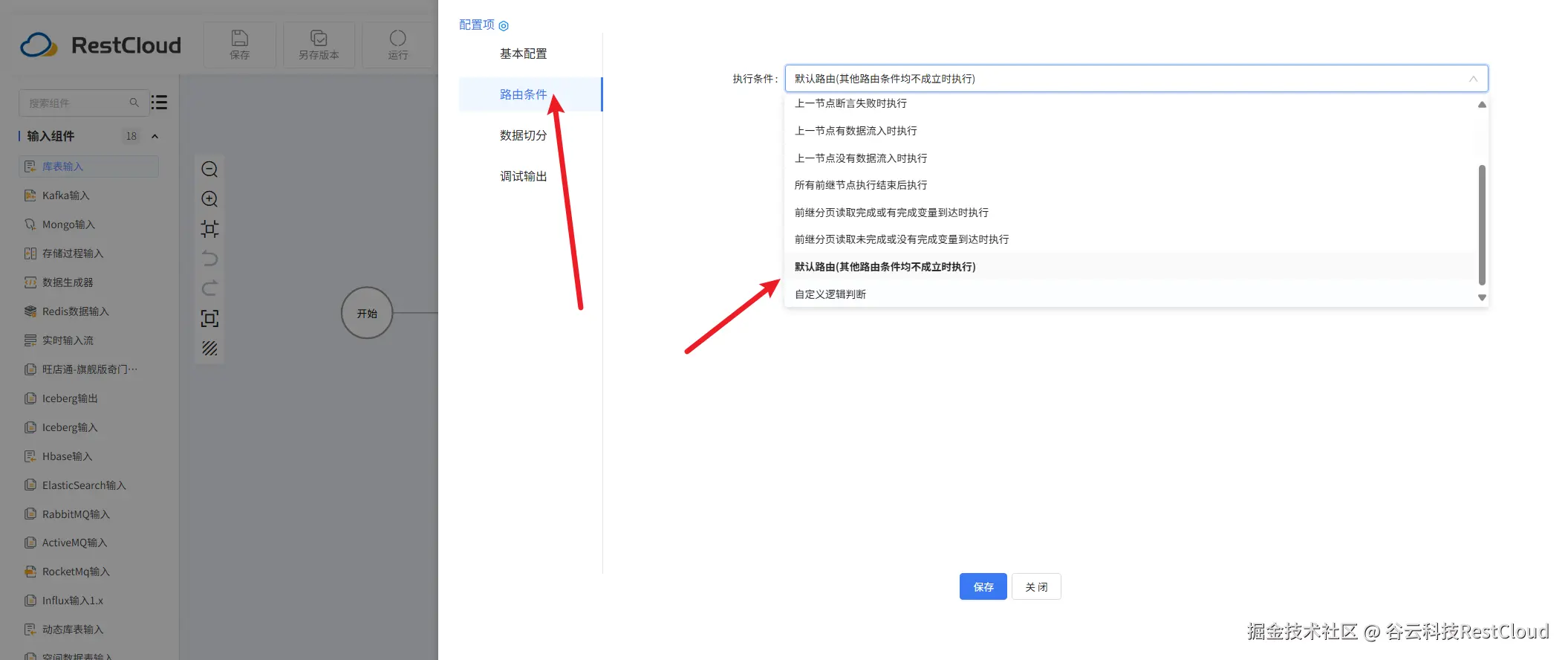
运行流程,可以看到数据成功同步。
三、最后
以上便是ETLCloud在面对服务器内存瓶颈时,大数据量表的同步方法,当服务器内存比较小时,我们可以使用自带的分页功能,或者我们手动循环去进行分页,都可以同步大数据量的表。
通过ETLCloud平台,我们无需成为数据库或网络专家,就能轻松应对PostgreSQL大表同步的挑战。其自动分页机制优雅地解决了内存瓶颈,而增量同步、数据压缩、批量处理等一系列功能则为突破网络瓶颈提供了多种强有力武器。通过灵活组合这些特性,数据工程师可以构建出高效、稳定、资源消耗可控的数据管道,让大数据同步变得简单而可靠。