在任何编程语言中,第一步都是读取输入源代码的单个字符 ,并判断哪些字符应当归为一组 。类比自然语言,这就像查看相邻的字母序列以识别"单词"。在编程语言里,字符簇会组成变量名 、保留字 ,或有时是多个字符构成的运算符或标点 。本章将教你如何读取源代码,并用模式匹配从原始字符中识别出"单词"和"标点"。
本章将涵盖以下主题:
- 词素(lexeme)、词法类别(lexical category)与记号(token)
- 正则表达式(Regular expressions)
- 使用 UFlex 与 JFlex
- 为 Jzero 编写扫描器(scanner)
- 什么时候"仅靠正则表达式还不够"
首先看看程序源代码中会出现的几类"单词"。自然语言的读者必须区分名词、动词和形容词,才能理解句子含义。同样地,你的编程语言也必须为源代码中的每个实体分类,以决定该如何解释它。
技术要求
本章会带你动手处理一些技术内容。你可以从本书的 GitHub 仓库下载示例代码:
github.com/PacktPublis...
本章的"Code in Action"演示视频在此: bit.ly/3Fnn2c2。
要跟着实践,你需要安装一些工具并下载示例。先看如何安装 UFlex 与 JFlex 。UFlex 随 Unicon 提供,无需单独安装。
对于 JFlex,请从 jflex.de/download.ht... 下载 jflex-1.9.1.tar.gz(或更新版本)。根据你系统上 tar(1) 的版本,可能需要先用 gunzip 解压,把 .tar.gz 转成 .tar。你可以从 www.gzip.org/ 或 gnuwin32.sourceforge.net/packages/gzip.htm 等处获取 gunzip。
之后用 tar 从 .tar 文件中解包。它会在你运行 tar 的目录下解出一个子目录(例如 jflex-1.9.1)。在 Windows 上,如果你没有把 JFlex 安装移动到 C:\JFLEX,则需要设置环境变量 JFLEX_HOME 指向你的安装位置,并把 JFLEX\bin 加入 PATH 。在 Linux 上,你可以把 JFLEX/bin 加入 PATH ,或为 JFLEX\bin\jflex 脚本创建符号链接。
如果你把 JFlex 解包在 /home/myname/jflex-1.9.1,可以这样把 /usr/bin/jflex 链接到解包后的脚本:
bash
sudo ln -s /home/myname/jflex-1.9.1/bin/jflex /usr/bin/jflex前文提到,本书的示例会以 Unicon 与 Java 两种版本并行给出。受版面限制,无法并排展示:我们先给出 Unicon 示例,再给出对应的 Java 代码。通常,Unicon 代码就是良好的可执行伪代码 ,Java 实现由此推导而来。安装并准备好 UFlex 和/或 JFlex 后,我们先讲要做什么;然后讲如何使用 UFlex 和 JFlex 生成词法分析器 (也称扫描器)的代码。
词素、词法类别与记号
编程语言会读取字符,并在这些字符属于同一语言实体时把相邻字符分组 。这个实体可能是多字符的名字或保留字 、一个常量值 ,或一个运算符。
词素(lexeme)是指一串相邻字符,作为一个单一实体 出现。多数标点本身就是独立的词素,同时也起到把前后内容分隔开的作用。在"讲道理"的语言中,空白字符(空格、制表符等)除了承担分隔词素的职责外会被忽略。
几乎所有语言都支持注释 ,且通常把注释与空白同等看待:它们可以作为两个词素的边界,但会被丢弃,不再参与后续处理。
每个词素都有一个词法类别(lexical category) 。在自然语言里,这相当于词性(名词、动词、形容词等)。在编程语言实现里,词法类别通常用一个整数代码 表示,供语法分析使用。变量名 是一类词法类别;常量 至少也是一类------在多数语言中,不同数据类型的常量会有多种 类别。大多数保留字 都有各自的类别,因为它们在语法中的出现位置彼此不同;在很多文法里,即便某些保留字在语法上可互换,也仍然分别赋予独立类别。类似地,运算符 通常每个优先级至少一个类别,甚至每个运算符 独立成类。一个典型的编程语言往往有 50~100 种词法类别,远多于我们在自然语言中能叫出名字的"词性"。
编程语言为每个读入的词素收集的信息包称为记号(token) 。记号通常表示为一个结构体(或其指针)或一个对象。记号的字段一般包括:
- 词素本身(字符串)
- 类别(整数)
- 文件名(该词素所在文件的字符串名)
- 行号(该词素在文件中的行号,整数)
- 可能的其他信息(列号、二进制表示等)
在阅读编程语言的书籍时,你会发现一些作者会在不同语境下用"token"分别指代字符串(词素) 、类别整数 或结构体/对象 。弄清 词素---类别---记号 这套术语后,我们接下来要看一套用于把一组词素 同其对应类别 关联起来的记法------这种模式就叫正则表达式。
正则表达式
正则表达式(RE)是描述文件中符号模式 的最广泛使用的方式。它由非常简单、易懂的规则构成。对正则表达式而言,定义它们所用符号的那套集合称为字母表(alphabet) 。本节的"字母表"不是英语的 A~Z,而更接近所谓的 ASCII 集合。
在某些输入符号集上,正则表达式使用输入符号集的成员 再加上少量正则表达式运算符 ,来描述字符串集合 的模式。既然是"描述集合"的记法,我们谈论正则能匹配的字符串集合时,自然会使用成员、并集、交集等术语。下面先给出构造正则表达式的规则,再配合示例说明。
正则表达式规则
多年来,许多工具使用过正则表达式,并发明了不少非标准扩展 。本书只展示示例所需的运算符------它比理论书上给出的"最小必需集合"略多,但又避免了一些工具里少见且过度 的运算符。我们考虑的规则如下(除第一条外,其余都与把小正则串接成大正则有关,用以匹配更复杂的模式):
-
字母表中的任一符号 (如
a)本身就是一个正则,匹配该符号本身。反斜杠 `` 作为转义符,可以把一个"RE 运算符"转义为"仅匹配该符号本身"的正则。 -
括号 可包围一个正则表达式
(r),其匹配与r相同。括号用于强制优先级,使括号内的运算先于外部运算符应用。 -
连接(concatenation) :当两个正则
re1与re2相邻时,re1 re2匹配"一个re1的实例后接 一个re2的实例"。这个连接运算很"隐形",因为它没有显式符号 。任意一段双引号 括起的字符串,表示"按原样的字符序列",即连接在一起。正则运算符在双引号内不生效 ,而\n等常见转义可使用。 -
选择(alternation) :任意两个正则
re1 | re2匹配"属于re1或re2的一个成员"。方括号 是对大量"竖线分隔的单字符选择"的速记 :[abcd]等价于(a|b|c|d);范围速记如[a-d]也等价于(a|b|c|d);[^abcd]则表示"不是 a/b/c/d 的任一单字符 "。对"速记的速记",还有点号.:它等价于[^ \n ],即匹配除换行以外 的任意单字符。 -
重复运算符 :任意正则
re后接- 星号
*:re*匹配"零次或多次 "重复的re; - 加号
+:re+匹配"一次或多次 "重复的re; - 问号
?:re?匹配"零次或一次 "的re。
- 星号
这些规则不 包含正则表达式里的空白 或注释 ------编程语言有这些概念,但正则记法没有 !如果你的模式需要一个空格,可以把空格转义 ,或放在双引号 或方括号 里;但如果你在正则里看到一个未转义的空格或注释 ,那就是bug 。不能为了"美观"就随意在正则中插入空白。如果你必须写注释来解释一个正则,那你大概把它写得过于复杂 了;正则本应是自说明 的------若做不到,考虑重写它们。
尽管我一再主张"保持简单",这 5 条简单规则可以组合出十分强大的模式,匹配非常丰富的字符串集合。进入使用这些规则的词法分析器生成器之前,我们先通过一些额外示例,帮助你直观把握正则表达式能描述的模式类型。
正则表达式示例
一旦你写过几个正则表达式,就会发现它们其实不难。下面是一些有可能在你的扫描器中用到的示例:
-
正则表达式
while可以看作由五个正则拼接而成,每个字母一个:w、h、i、l、e。它匹配字符串while(不含双引号)。 -
正则表达式
"+"|"-"|"*"|"/"匹配长度为 1 的字符串,该字符要么是加号、要么是减号、要么是星号、要么是斜杠。这里用双引号是为了确保这些标点不会 被当作正则运算符解释。你也可以写成[+-*/]。注意:像*这样的正则运算符在方括号内 不生效;在方括号里,标点符号被当作普通符号(除了像连字符-或插入符号^这类在方括号内有特殊含义的字符,需要用反斜杠转义)。 -
正则表达式
[0-9]*.[0-9]*匹配"零个或多个数字,接一个点,再接零个或多个数字"。点号要转义,否则它表示"除换行外的任意单字符"。虽然这个模式像是在匹配实数,但它允许点号两边都没有数字!你需要写得更严谨些。比如:css([0-9]+.[0-9]*|[0-9]*.[0-9]+)虽然啰嗦,但至少能保证这个 token 确实是某种数字。
-
正则表达式
"""[^"]*"""(即"""[^"]*""")匹配:一个双引号,然后是零个或多个 "非双引号字符",再跟一个双引号。这是新手常见的"字符串常量"正则写法。问题在于:它允许换行 出现在字符串中------而多数编程语言不允许。另一个问题是:它不能 在字符串常量里放入双引号。多数语言会提供转义机制 来实现这一点。一旦允许转义字符,你就必须明确规定它们。若只允许转义双引号,可写成:python"""([^"\\n]|\")*"""对于像 C 这样的语言,更通用的版本可能是:
python"""([^\\n]|\([abfnrtv\?0]|[0-7][0-7][0-7]|x[0-9a-fA-F][0-9a-fA-F]))*"""
这些例子说明,正则表达式可以从微不足道 到庞然大物 不等。某种程度上,正则是一种"只写不读"的记法------写 起来比读 起来容易。有时如果你的正则写错了,重写 比调试反而更省事。看过这些示例之后,接下来我们来了解用正则表达式记法来生成源代码扫描器 的工具------也就是 UFlex 与 JFlex。
使用 UFlex 与 JFlex
手写扫描器对想"吃透底层工作原理"的程序员来说确实很有趣,但它会拖慢语言开发进度,并让后续维护更困难。
好消息是:源自 UNIX 的一类工具 lex ,可以把正则表达式生成 成扫描函数。主流语言几乎都有与 lex 兼容的工具。C/C++ 最常用的是 Flex (github.com/westes/flex... 使用 UFlex ,Java 则可以用 JFlex 。这些工具各有扩展,但在与 UNIX lex 兼容的范围内,我们可以把它们当作同一种"扫描器描述语言"来讲解。本书的示例经过精心编写,甚至可以让 Unicon 与 Java 两个实现共用同一份输入文件!
lex 的输入文件通常称为(lex)规范 ,扩展名为 .l,由若干部分组成,用 %% 分隔。本文泛称它们为 "lex 规范",既可以供 UFlex 也可以供 JFlex 使用,而且大多数情况下,同样也能被 C 的 Flex 接受。
一个 lex 规范包含必需 的几个部分:头部(header) 、正则表达式 部分,以及可选的辅助函数 部分。JFlex 还在最前面加了一个 imports 部分,因为 Java 需要 import,并且需要能在"类定义之前"和"类定义之内"分别插入代码片段。就现在而言,你需要关注的是头部 与正则表达式这两个部分。我们先看头部。
头部(Header)部分
大多数 Flex 家族工具都支持在头部开启一些选项(各家略有不同,用到再说)。你也可以在这里插入宿主语言的代码片段,比如变量声明。不过,头部的主要目的 是定义命名宏,以便在正则表达式部分多次复用某些模式。lex 中的命名宏一行一个,格式如下:
name regex在宏行里,name 是一段字母序列,后面跟一个或多个空格,再跟一个正则表达式。之后在"正则表达式"部分,你可以用花括号 把宏名包起来来替换它,比如 {name}。新手最常犯的错误是------试图在宏定义的正则后面加注释 ,千万别这么做。lex 在这些行里不支持注释,你写的内容会被当作正则表达式的一部分来解析。
有点"悲剧"的是,JFlex 打破了兼容性,要求在名字后加一个等号,所以它的宏写法是:
ini
name=regex这个与 UNIX lex 的不兼容性确实挺"过分",因此本书示例里选择不使用宏 。在写作本书期间,我们给 UFlex 做了扩展,使其既能接受传统语法,也能接受带等号的语法。如果你愿意加一些宏,示例代码会稍微短一点。若不使用宏,你的头部 几乎是空的------那么接下来就进入 lex 规范的下一部分:正则表达式部分。
正则表达式部分
在一份 lex 规范中,正则表达式部分 是主体。每条正则表达式各占一行,后面跟一些空白,再跟一段语义动作 ------也就是当该正则被匹配时要执行的宿主语言代码(在本书中是 Unicon 或 Java)。注意:虽然每条正则规则都从新行开始 ,但如果语义动作按常规用花括号 包围一个语句块,那么它可以跨越多行源码;在找到配对的右花括号之前,lex 都不会去寻找下一条正则。
新手在"正则表达式部分"最常见的错误,是为了可读性在正则里插入空格或注释 。不要这么做;在正则中间插入空格会把正则截断在空格处 ,空格之后的内容会被当作宿主语言代码来解释。这样通常会得到一些让人摸不着头脑的报错信息。
当你运行 UNIX 的 lex(一个 C 工具)时,它会生成一个名为 yylex() 的函数,为每个词素返回一个整数类别 ;同时还会通过全局变量提供其他有用信息。整数 yychar 保存类别;字符串 yytext 保存该词素被匹配的字符;yyleng 告诉我们匹配了多少个字符。各家 lex 工具在这个公开接口上的兼容性不尽相同,有的工具还会自动为你多做一些工作。例如,JFlex 必须在类内部 生成扫描器,并通过成员函数 提供 yytext()。编程语言实现通常还需要更多细节,比如记号来自第几行。下面我们通过示例循序渐进地实现这些需求。
编写一个简单的源代码扫描器
这个示例可以用来检查你是否能成功运行 UFlex 与 JFlex 。它足够短小,你可以从本书的 GitHub 下载代码,也可以跟着边看边敲。它还能帮助你了解 UFlex 与 JFlex 的使用相似度。这个示例扫描器只识别名字 、数字 与空白 ;lex 规范放在名为 nnws.l 的文件中。编程语言工具读取源代码时首先要做的事,就是标定每个词素的类别 并返回它。这个示例把名字 记为 1 ,数字 记为 2 ;空白被丢弃 ;其余任何内容都视为错误。
nnws.l 的主体如下所示。这份规范可同时作为 UFlex 与 JFlex 的输入。下载或键入之后,本书会演示如何分别为 Unicon 与 Java 构建它------你可以选择其一或都做。由于 UFlex 的语义动作用 Unicon 代码、JFlex 的语义动作用 Java 代码,因此我们需要有所克制。
只有当我们把语义动作限制在两种语言共同的语法 (如方法调用 与return 表达式 )时,它才会在 Java 与 Unicon 中都合法。如果你加入 if 语句、赋值或任何语言特有 的语法,你的 lex 规范就会变成某个宿主语言(比如 Unicon 或 Java)专用。
即便是这个小例子,也包含了一些后面会用到的思路。前两行是给 JFlex 用的,UFlex 会忽略 。最开始的 %% 表示空的 JFlex import 部分 结束;第二行是头部 中的一个 JFlex 选项 。默认情况下,JFlex 的 yylex() 返回 Yytoken 类型的对象;%int 选项让它像 C 的 Flex 与 UFlex 一样返回整数 。第三行以 %% 进入正则表达式部分 。第四行的正则 [a-zA-Z]+ 匹配一个或多个 大小写字母:它会尽可能多地匹配相邻字母,并返回 1 。副作用是,被匹配的字符会被存入 yytext 。第五行的 [0-9]+ 匹配尽可能多的数字,并返回 2 。第六行用 [ \t\r\n]+ 匹配空白,不返回任何值 ;扫描器会继续在输入文件中前进,尝试匹配其它正则。除了大家熟悉的空格外,\t 是制表符 ,\r 是回车 ,\n 是换行 。第七行的点号 . 匹配除换行外的任意字符 ,因此能捕获前面模式都不允许的源代码,并在这种情况下报告错误 。错误通过一个名为 lexErr() 的函数上报(用于词法错误),该函数位于名为 simple 的对象中。后续编译流程我们还会需要更多报错函数:
csharp
%%
%int
%%
[a-zA-Z]+ { return 1; }
[0-9]+ { return 2; }
[ \t\r\n]+ { }
. { simple.lexErr("unrecognized character"); }这份规范会从 main() 函数中被调用,对输入中的每个单词 调用一次。每次调用时,它都会把当前输入位置同时 拿去尝试匹配所有正则 (这里是 4 条),并选择在当前位置匹配字符数最多 的那一条。如果有两条或更多正则出现"最长匹配并列 ",那么在规范文件中出现得更靠前 的那条获胜。
多种 lex 工具都能提供一个默认的 main() ,但若想完全掌控流程,建议自己编写 。此外,自己写 main() 还能演示如何在单独文件 中调用 yylex()------下一章把扫描器接到语法分析器上时,你就会需要这样做。
main() 的写法因语言而异 。Unicon 采用类似 C++ 的组织方式,main() 在任何对象之外 起始;而 Java 则把 main() 放在类内部。除此之外,两者代码有很多共同点。
Unicon 实现 可以放在任意以 .icn 为扩展名的文件中;这里叫它 simple.icn 。文件包含一个 main() 过程和一个名为 simple 的单例类 ------仅仅因为我们在 nnws.l 里用了一种"兼容 Java 的方式 "调用词法错误助手函数,即 simple.lexErr()。main() 过程通过把类构造函数替换为它返回的单个实例 来初始化 simple 类;随后从命令行第一个参数给出的文件名打开输入文件。词法分析器通过 yyin 知道读取哪个文件。之后在循环里调用 yylex() ,直到扫描结束:
arduino
procedure main(argv)
simple := simple()
yyin := open(argv[1])
while i := yylex() do
write(yytext, ": ", i)
end
class simple()
method lexErr(s)
stop(s, ": ", yytext)
end
endJava 版本 的 main() 必须放在一个类里,文件名为类名加 .java ;这里叫它 simple.java 。它通过创建 FileReader 打开文件,并在创建词法分析器 Yylex 对象时把 FileReader 作为参数传入。因为 FileReader 可能失败,我们需要在 main() 上声明会抛出异常。构造好 Yylex 对象后,main() 就反复调用 yylex() 直到输入耗尽;yylex() 在结束时返回 Yylex.YYEOF 这个哨兵值。
虽然代码更长一些,但这个 main() 做的事与 Unicon 版本相同。与 Unicon 的 simple 类相比,Java 版多了一个代理方法 yytext(),方便 simple 类中的其他函数或编译器其他部分在没有 Yylex 引用的情况下获取"最近一次词素字符串":
arduino
import java.io.FileReader;
public class simple {
static Yylex lex;
public static void main(String argv[]) throws Exception {
lex = new Yylex(new FileReader(argv[0]));
int i;
while ((i=lex.yylex()) != Yylex.YYEOF)
System.out.println("token "+ i +": "+ yytext());
}
public static String yytext() {
return lex.yytext();
}
public static void lexErr(String s) {
System.err.println(s + ": " + yytext());
System.exit(1);
}
}至此,你已经看完了第一个扫描器 的全部代码:一份 .l 文件中的词法规范 (由此生成 yylex()),以及一份 .icn 或 .java 的 main()(调用 yylex() 并检查其运作)。这个简单扫描器的主要目的,是让你看清各组件如何连线 。无论你是下载了代码还是手敲完成,现在都可以在 Unicon 、Java 或两者上试跑,以确保这套"管道"按我们预期工作。
运行你的扫描器
让我们在下面这个(很简单的)输入文件上运行示例,文件名为 dorrie.in:
csharp
Dorrie is 1 fine puppy在运行程序之前,你必须先编译 。UFlex 与 JFlex 会生成分别由 Unicon 或 Java 编写的、供你的编程语言其余部分调用的代码。若你想知道编译流程长什么样,下面这张图给出了示意:在 Unicon 中,这两个源文件会被编译并链接成名为 simple 的可执行文件;在 Java 中,这两个文件会被分别编译成 .class 文件;你通过包含 main() 方法的 simple.class 启动 Java,其他类在需要时再加载:
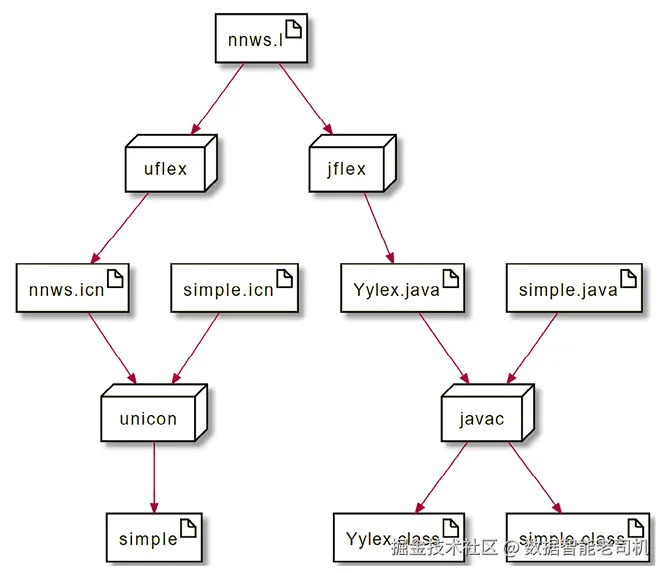
图 3.1:使用 nnws.l 同时构建 Unicon(左)与 Java(右)程序
你可以按下列"左列/右列"的命令,在 Unicon 或 Java 中编译并运行该程序:
uflex nnws.l jflex nnws.l
unicon simple nnws javac simple.java Yylex.java
simple dorrie.in java simple dorrie.in无论采用哪种实现,你都应该看到如下五行输出:
yaml
token 1: Dorrie
token 1: is
token 2: 1
token 1: fine
token 1: puppy到目前为止,这个示例只是用正则表达式对输入字符分组并分类,判断找到的是什么类型的词素。为了让编译器的其余部分工作,我们还需要关于该词素的更多信息,并把它们存放到**记号(token)**里。
记号与词法属性
除了标明每个词素所属的整数类别 之外,编程语言实现(在我们的案例中是编译器)还要求扫描器分配一个对象 来保存该词素的全部相关信息。这个对象称为记号(token) 。
一个 token 持有一组命名字段,称为词法属性(lexical attributes) 。需要记录哪些信息,取决于语言与实现。通常,token 会记录:整数类别、词素的字符串文本,以及该 token 来自的行号 。在真实的编译器里,token 往往还包含更多信息,比如文件名 以及该词素在所在行里的列号 。对某些 token(字面量常量)来说,编译器或解释器还可能会存储该字面量所表示的实际二进制值。
你可能会问:为什么要存 token 的列号 ?既然有词素文本,通常看看源码那一行就能找到它;而且大多数编译器在报错时只给行号 ,不给列号。确实,并不是所有实现都会存列号。不过,存了列号 的实现可以在同一行里同一 token 出现多次 时消除歧义 :错误出在第一个右括号,还是第三个?你可以把猜测留给人,也可以记录更多细节。是否存列号还取决于你的词法分析器是否会被 IDE 使用------当出错时,IDE 会把光标跳到具体的出错 token。如果这是你的需求之一,你就需要列号来实现这个功能。
扩展示例以构造记号
通常,每次调用 yylex() 都会分配一个新的 token 实例 。在 lex 中,token 通过把"指向新实例的指针"放入全局变量 yylval 的方式传递给语法分析器,每次调用 yylex() 都会这样做。作为迈向"真实扫描器"的过渡,我们将扩展前面的示例,让它能够分配这些 token 对象。
最优雅、最可移植的做法是:在语义动作 中插入一个名为 scan() 的函数;scan() 负责分配 token 对象,然后(通常)返回它的参数 ------即前面示例中的整数类别码。
实现这一点的 lex 规范在 nnws-tok.l 文件中。需要注意的是,在 JFlex 里,回车符 既不属于"换行",也不属于"除了换行之外的任意字符"的点号运算符;因此若使用 JFlex,必须显式处理回车 。在本例中,回车放在换行前是可选的:
ini
%%
%int
%%
[a-zA-Z]+ { return simple2.scan(1); }
[0-9]+ { return simple2.scan(2); }
[ \t]+ { }
\r?\n { simple2.increment_lineno(); }
. { simple2.lexErr("unrecognized character"); }下面是 Unicon 中更新后的 main(),文件名 simple2.icn 。scan() 依赖一个名为 yylineno 的全局变量:它在 main() 中设定,并在 yylex() 每次匹配到换行时更新。和前一个示例一样,simple2 是一个单例类 ,目的是让这份 lex 规范在 Unicon 与 Java 两端都无需修改 即可复用。token 的表示用 Unicon 的 record 类型 定义(类似 C/C++ 的 struct,或"无方法的类")。目前它只包含:整数类别码、词素字符串本身、以及其来源的行号:
css
global yylineno, yylval
procedure main(argv)
simple2 := simple2()
yyin := open(argv[1]) | stop("usage: simple2 filename")
yylineno := 1
while i := yylex() do
write("token ", i, " (line ",yylval.lineno, "): ", yytext)
end
class simple2()
method lexErr(s)
stop(s, ": line ", yylineno, ": ", yytext)
end
method scan(cat)
yylval := token(cat, yytext, yylineno)
return cat
end
method increment_yylineno()
yylineno +:= 1
end
end
record token(cat, text, lineno)对应的 Java 版本 main() 位于 simple2.java,如下:
arduino
import java.io.FileReader;
public class simple2 {
static Yylex lex;
public static int yylineno;
public static token yylval;
public static void main(String argv[]) throws Exception {
lex = new Yylex(new FileReader(argv[0]));
yylineno = 1;
int i;
while ((i=lex.yylex()) != Yylex.YYEOF)
System.out.println("token "+ i +
" (line " +yylval.lineno + "): "+ yytext());
}
public static String yytext() {
return lex.yytext();
}
public static void lexErr(String s) {
System.err.println(s + ": line " + yylineno +
": " + yytext());
System.exit(1);
}
public static int scan(int cat) {
yylval = new token(cat, yytext, yylineno);
return cat;
}
public static void increment_lineno() {
yylineno++;
}
}simple2 示例还需要另一个 Java 文件。token.java 定义了我们的 token 类(下一节还会扩展它):
arduino
public class token {
public int cat;
public String text;
public int lineno;
public token(int c, String s, int l) {
cat = c; text = s; lineno = l;
}
}下面这个输入文件 dorrie2.in 被扩展为多行,并在末尾加了一个句点,以便当出现"无法识别的字符"时能看到行号:
csharp
Dorrie
is 1
fine puppy.你可以这样在 Unicon 或 Java 中运行程序:
markdown
uflex nnws-tok.l jflex nnws-tok.l
javac token.java
unicon simple2 nnws-tok javac simple2.java Yylex.java
simple2 dorrie2.in java simple2 dorrie2.in无论采用哪种实现,预期输出如下:
arduino
token 1 (line 1): Dorrie
token 1 (line 2): is
token 2 (line 2): 1
token 1 (line 3): fine
token 1 (line 3): puppy
unrecognized character: line 3: .这个示例的输出包含了行号 ,而输入文件中故意包含了一个无法识别的字符 ,以便看到错误消息同样包含行号。
为 Jzero 编写扫描器
本节给出一个更大的示例:为 Jzero(我们定义的 Java 子集)编写扫描器。从这里开始,示例已足够庞大,如果你想运行它,多数读者会选择从本书的 GitHub 下载代码。这个示例把前面的 simple2 扩展到更接近真实语言的规模,并加入了列号 信息,以及字面量常量 的额外词法属性。最大的变化是:为了处理比先前更复杂的模式,引入了大量正则表达式 。扫描器能够识别整个 Java 语言 ,但其中相当一部分 Java 类别会导致执行以错误退出 ,这样下一章的语法(以及编译器其余部分)就不必考虑它们。
Jzero 的 flex 规范
与前面的示例相比,真实编程语言的 lex 规范会包含更多、且更复杂 的正则表达式。下面这个文件名为 javalex.l,会分几段展示。
javalex.l 的开头包含头部 以及注释与空白 的正则表达式。这些正则会匹配并消耗源代码中的字符,但不会返回 对应的整数代码;对编译器其余部分而言,它们是不可见 的。作为 Java 的子集,Jzero 同时包含 C 风格注释 (以 /* 与 */ 包围)与 C++ 风格注释 (以 // 开始直到行末)。C 风格注释的正则表达式非常"巨大";如果你的语言也有这类模式,很容易 、也很常见 会写错。它的含义是:从 /* 开始,随后"吃掉"一串非星号字符或不构成注释结束的星号,直到遇到"一个或多个星号后跟一个斜杠"为止:
erlang
%%
%int
%%
"/*"([^*]|"*"+[^/*])*"*"+"/" { j0.comment(); }
"//".*\r?\n { j0.comment(); }
[ \t\r\f]+ { j0.whitespace(); }
\n { j0.newline(); }javalex.l 的下一部分是保留字 ,它们的正则非常直接。由于这些词经常出现在语义动作中,因此用双引号强调"它们就是这些字符本身",以免看起来像语义动作代码。
这里的许多整数类别码 由语法分析器类 (在单独的文件中指定)提供。在本书后续章节中,整数代码都由语法分析器定义。为了让编译器的这两个阶段能成功通信,词法分析器必须使用语法分析器的这些代码。
你或许会问:为什么每个保留字都要用不同的整数类别码?实际上,只有当它们在语法中承担不同角色时,才需要分配不同的代码。能在同一处出现的保留字可以共用一个类别码。这样语法会更短,但具体差异 就留到后续语义分析 去处理,同时让语法变得更含糊 。例如 true 与 false:从语法上看它们是同类,因此都可以作为 BOOLLIT 返回。我们也可能发现其他保留字(如类型名)可以共用同一类别码------这就是一个需要权衡的设计决策 。拿不准时,建议稳妥 起见:每个保留字分配一个整数码。
kotlin
"break" { return j0.scan(parser.BREAK); }
"double" { return j0.scan(parser.DOUBLE); }
"else" { return j0.scan(parser.ELSE); }
"false" { return j0.scan(parser.BOOLLIT); }
"for" { return j0.scan(parser.FOR); }
"if" { return j0.scan(parser.IF); }
"int" { return j0.scan(parser.INT); }
"null" { return j0.scan(parser.NULLVAL); }
"return" { return j0.scan(parser.RETURN); }
"string" { return j0.scan(parser.STRING); }
"true" { return j0.scan(parser.BOOLLIT); }
"bool" { return j0.scan(parser.BOOL); }
"void" { return j0.scan(parser.VOID); }
"while" { return j0.scan(parser.WHILE); }
"class" { return j0.scan(parser.CLASS); }
"static" { return j0.scan(parser.STATIC); }
"public" { return j0.scan(parser.PUBLIC); }javalex.l 的第三部分是运算符与标点 。这些正则同样加引号 ,表示它们就是字面字符本身。与保留字类似,在某些情况下,如果若干运算符具有相同的优先级与结合性 ,也可以合并到一个共享的类别码,这会让语法更短,但也会更含糊。
与保留字相比还有一个"小状况":很多运算符与标点只占一个字符 。这时,用它们的 ASCII 码 作为整数类别码更短也更直观,因此我们就这么做。函数 j0.ord(s) 提供了在 Unicon 与 Java 上都通用的实现方式。对多字符运算符 ,像保留字那样使用语法分析器常量:
kotlin
"(" { return j0.scan(j0.ord("(")); }
")" { return j0.scan(j0.ord(")")); }
"[" { return j0.scan(j0.ord("[")); }
"]" { return j0.scan(j0.ord("]")); }
"{" { return j0.scan(j0.ord("{")); }
"}" { return j0.scan(j0.ord("}")); }
";" { return j0.scan(j0.ord(";")); }
":" { return j0.scan(j0.ord(":")); }
"!" { return j0.scan(j0.ord("!")); }
"*" { return j0.scan(j0.ord("*")); }
"/" { return j0.scan(j0.ord("/")); }
"%" { return j0.scan(j0.ord("%")); }
"+" { return j0.scan(j0.ord("+")); }
"-" { return j0.scan(j0.ord("-")); }
"<" { return j0.scan(j0.ord("<")); }
"<=" { return j0.scan(parser.LESSTHANOREQUAL);}
">" { return j0.scan(j0.ord(">")); }
">=" { return j0.scan(parser.GREATERTHANOREQUAL);}
"==" { return j0.scan(parser.ISEQUALTO); }
"!=" { return j0.scan(parser.NOTEQUALTO); }
"&&" { return j0.scan(parser.LOGICALAND); }
"||" { return j0.scan(parser.LOGICALOR); }
"=" { return j0.scan(j0.ord("=")); }
"+=" { return j0.scan(parser.INCREMENT); }
"-=" { return j0.scan(parser.DECREMENT); }
"," { return j0.scan(j0.ord(",")); }
"." { return j0.scan(j0.ord(".")); }javalex.l 的第四部分(也是最后一部分)包含更困难的正则表达式。变量名 的规则(其整数类别为 IDENTIFIER )必须放在所有保留字之后 。之所以保留字能**"压过"更一般的标识符规则,是因为 lex 在 最长匹配出现 并列时,会选择规范文件中更靠前**的那条规则。
如果能提高可读性,你可以写任意多条 正则表达式让它们返回同一个 整数类别。本例就为实数 (带小数点、科学计数法,或两者兼有)使用了多条规则。最后一条是兜底模式:当源代码出现二进制或其他奇怪字符时,生成词法错误。
ini
[a-zA-Z_][a-zA-Z0-9_]*{ return j0.scan(parser.IDENTIFIER);}
[0-9]+ { return j0.scan(parser.INTLIT); }
[0-9]+"."[0-9]*([eE][+-]?[0-9]+)? { return j0.scan (parser.DOUBLELIT);}
[0-9]*"."[0-9]+([eE][+-]?[0-9]+)? { return j0.scan (parser.DOUBLELIT);}
([0-9]+)([eE][+-]?([0-9]+)) {return j0.scan (parser.DOUBLELIT);}
"([^"])|(\.)*" { return j0.scan(parser.STRINGLIT); }
. { j0.lexErr("unrecognized character");}虽然这里分成四段来展示,javalex.l 实际并不长,大约 58 行 。而且它同时适用于 Unicon 与 Java ,这已经是非常高的性价比 了。的确,配套的 Unicon 与 Java 代码不算简单,但我们把大部分活儿交给了 lex(UFlex 与 JFlex) 来做。
Unicon 端的 Jzero 代码
Jzero 扫描器在 Unicon 中的实现位于 j0.icn 。Unicon 有预处理器,通常通过 $include 文件引入符号常量定义 。为了让同一份 lex 规范 可同时用于 Unicon 与 Java ,这个 Unicon 扫描器创建了一个 parser 对象,其字段(如 parser.WHILE)保存整数类别码:
css
global yylineno, yycolno, yylval
procedure main(argv)
j0 := j0()
parser := parser(257,258,259,260,261,262,263,264,265,
266, 267,268,269,270,273,274,275,276,
277,278,280,298,300,301,302,303,304,
306,307,256)
yyin := open(argv[1]) | stop("usage: simple2 filename")
yylineno := yycolno := 1
while i := yylex() do
write("token ", i, ":",yylval.lineno, " ", yytext)
endj0.icn 的第二部分是 j0 类。与前面 simple2.icn 的 simple2 类相比,增加了若干方法,供语义动作在遇到不同的空白 与注释 时调用。借此可以在全局变量 yycolno 中维护当前列号:
scss
class j0()
method lexErr(s)
stop(s, ": ", yytext)
end
method scan(cat)
yylval := token(cat, yytext, yylineno, yycolno)
yycolno +:= *yytext
return cat
end
method whitespace()
yycolno +:= *yytext
end
method newline()
yylineno +:= 1; yycolno := 1
end
method comment()
yytext ? {
while tab(find("\n")+1) do newline()
yycolno +:= *tab(0)
}
end
method ord(s)
return proc("ord",0)(s[1])
end
endj0.icn 的第三部分把 token 从 record 提升为 class ,因为它的构造器变复杂了,并新增了一个方法用于处理字符串转义 与计算字符串字面量的二进制表示 。在 Unicon 中,构造器代码写在方法末尾的 initially 区块中。
deEscape() 方法会丢弃首尾双引号 ,然后用 Unicon 的字符串扫描 逐字符处理字符串字面量。在字符串扫描控制结构 s ? { ... } 中,对字符串 s 从左到右检查;函数 move(1) 取出下一个字符,并将扫描位置前移 1。关于字符串扫描的更详细说明见附录 Unicon Essentials。
在 deEscape() 中,普通字符会原样从输入 sin 拷贝到输出 sout。遇到反斜杠引出的转义 ,后续一个或多个字符会被以不同方式解释。Jzero 子集只处理制表符 与换行 ;Java 里还有更多转义可补充。把反斜杠后跟 "t" 变成一个制表符看起来有点"魔法",但你用过的每个编译器都做过类似的事:
vbnet
class token(cat, text, lineno, colno, ival, dval, sval)
method deEscape(sin)
local sout := ""
sin := sin[2:-1]
sin ? {
while c := move(1) do {
if c == "\" then {
if not (c := move(1)) then
j0.lexErr("malformed string literal")
else case c of {
"t":{ sout ||:= "\t" }
"n":{ sout ||:= "\n" }
}
}
}
else sout ||:= c
}
}
return sout
end
initially
case cat of {
parser.INTLIT: { ival := integer(text) }
parser.DOUBLELIT: { dval := real(text) }
parser.STRINGLIT: { sval := deEscape(text) }
}
end
record parser(BREAK,PUBLIC,DOUBLE,ELSE,FOR,IF,INT,RETURN,VOID,
WHILE,IDENTIFIER,CLASSNAME,CLASS,STATIC,STRING,
BOOL,INTLIT,DOUBLELIT,STRINGLIT,BOOLLIT,
NULLVAL,LESSTHANOREQUAL,GREATERTHANOREQUAL,
ISEQUALTO,NOTEQUALTO,LOGICALAND,LOGICALOR,
INCREMENT,DECREMENT,YYERRCODE)对熟练的 Unicon 程序员来说,这里把一堆 token 类别名放在一个parser 记录 里看起来有点"多此一举":你完全可以用 $define 定义这些名字,而无需引入 parser 类型。但请记住 ,这么做是为了与 Java (尤其是 byacc/j )兼容。
Java 版 Jzero 代码
Jzero 扫描器在 Java 中的实现包含一个放在 j0.java 文件里的主类。它与前面的 simple2.java 示例相似。此处分四部分展示。第一部分包含 main() 函数------除了新增了用于跟踪当前列号 的 yycolno 等变量外,应该都很眼熟:
java
import java.io.FileReader;
public class j0 {
static Yylex lex;
public static int yylineno, yycolno;
public static token yylval;
public static void main(String argv[]) throws Exception {
lex = new Yylex(new FileReader(argv[0]));
yylineno = yycolno = 1;
int i;
while ((i=lex.yylex()) != Yylex.YYEOF) {
System.out.println("token " + i + ":" + yylineno + " " +
yytext());
}
}j0 类接下来给出若干在此前示例中已出现过的辅助函数:
arduino
public static String yytext() {
return lex.yytext();
}
public static void lexErr(String s) {
System.err.println(s + ": line " + yylineno +
": " + yytext());
System.exit(1);
}
public static int scan(int cat) {
last_token = yylval =
new token(cat, yytext(), yylineno, yycolno);
yycolno += yytext().length();
return cat;
}
public static void whitespace() {
yycolno += yytext().length();
}
public short ord(String s) {return(short)(s.charAt(0));}j0 类中用于处理换行符 的函数会将行号加一,并把列号重置为 1。处理注释的方法会逐字符遍历注释,以保持行号与列号的正确性:
csharp
public static void newline() {
yylineno++; yycolno = 1;
}
public static void comment() {
int i, len;
String s = yytext();
len = s.length();
for(i=0; i<len; i++)
if (s.charAt(i) == '\n') {
yylineno++; yycolno=1;
}
else yycolno++;
}
}还有一个名为 parser.java 的支撑模块。它提供一组命名常量 (类似枚举),但直接将常量声明为 short 整数,以兼容下一章将要讨论的 iyacc 语法分析器。常量取值从 256 以上开始,因为 iyacc 也是从那里开始编号,以避免与我们通过 j0.ord() 产生的单字节词素的整数类别码冲突:
ini
public class parser {
public final static short BREAK=257;
public final static short PUBLIC=258;
public final static short DOUBLE=259;
public final static short ELSE=260;
public final static short FOR=261;
public final static short IF=262;
public final static short INT=263;
public final static short RETURN=264;
public final static short VOID=265;
public final static short WHILE=266;
public final static short IDENTIFIER=267;
public final static short CLASSNAME=268;
public final static short CLASS=269;
public final static short STATIC=270;
public final static short STRING=273;
public final static short BOOL=274;
public final static short INTLIT=275;
public final static short DOUBLELIT=276;
public final static short STRINGLIT=277;
public final static short BOOLLIT=278;
public final static short NULLVAL=280;
public final static short LESSTHANOREQUAL=298;
public final static short GREATERTHANOREQUAL=300;
public final static short ISEQUALTO=301;
public final static short NOTEQUALTO=302;
public final static short LOGICALAND=303;
public final static short LOGICALOR=304;
public final static short INCREMENT=306;
public final static short DECREMENT=307;
public final static short YYERRCODE=256;
}另一个支撑模块 token.java 定义了 token 类。它增添了列号 字段;对字面量常量,还将其二进制表示分别存入 ival、sval、dval(对应整数、字符串、双精度)。用于构造字符串字面量"二进制值"的 deEscape() 方法在 Unicon 版本中已讨论过。其算法仍是逐字符 处理:通常直接拷贝字符;若遇到反斜杠,则取出后续字符并按转义规则解释。把这段代码与 Unicon 版本对比,可以直观体会 Java String 类的便利:
arduino
public class token {
public int cat;
public String text;
public int lineno, colno, ival;
String sval;
double dval;
private String deEscape(String sin) {
String sout = "";
sin = String.substring(sin,1,sin.length()-1);
int i = 0;
while (sin.length() > 0) {
char c = sin.charAt(0);
if (c == '\') {
sin = sin.substring(1);
if (sin.length() < 1)
j0.lexErr("malformed string literal");
else {
c = sin.charAt(0);
switch(c) {
case 't': sout = sout + "\t"; break;
case 'n': sout = sout + "\n"; break;
default: j0.lexErr("unrecognized escape");
}
}
}
else sout = sout + c;
sin = sin.substring(1);
}
return sout;
}
public token(int c, String s, int ln, int col) {
cat = c; text = s; lineno = ln; colno = col;
switch (cat) {
case parser.INTLIT:
ival = Integer.parseInt(s);
break;
case parser.DOUBLELIT:
dval = Double.parseDouble(s);
break;
case parser.STRINGLIT:
sval = deEscape(s);
break;
}
}
}token 构造器对所有记号都做了四项相同的赋值(即初始化各字段),随后针对三类字面量 记号通过 switch 进行额外初始化。这里用到 Java 内置的 Integer.parseInt() 与 Double.parseDouble() 来转换词素,这对 Jzero 来说是一种简化 ------真正的 Java 编译器在此还需要做更多工作。sval 由 deEscape() 生成,因为 Java 中并没有"直接把源码里的字符串字面量 转换成实际字符串值 "的内置函数。固然可以找到第三方库,但对 Jzero 而言,自备一个更简单。
运行 Jzero 扫描器
你可以像下面这样在 Unicon 或 Java 中运行程序。这一次,我们在如下名为 hello.java 的示例输入文件上运行:
typescript
public class hello {
public static void main(String argv[]) {
System.out.println("hello, jzero!");
}
}请记住:对你的扫描器而言,这个 hello.java 程序只是一串词素。编译与运行 Jzero 扫描器的命令与之前示例类似,只是出现了更多 Java 文件:
markdown
uflex javalex.l jflex javalex.l
unicon j0 javalex javac j0.java Yylex.java
javac token.java parser.java
j0 hello.java java j0 hello.java无论采用哪种实现,预期输出应类似如下:
arduino
token 258:1 public
token 269:1 class
token 267:1 hello
token 123:1 {
token 258:2 public
token 270:2 static
token 265:2 void
token 267:2 main
token 40:2 (
token 267:2 String
token 267:2 argv
token 91:2 [
token 93:2 ]
token 41:2 )
token 123:2 {
token 267:3 System
token 46:3 .
token 267:3 out
token 46:3 .
token 267:3 println
token 40:3 (
token 277:3 "hello, jzero!"
token 41:3 )
token 59:3 ;
token 125:4 }
token 125:5 }到下一章,当扫描器的输出作为语法分析器 的输入时,Jzero 扫描器会更有意义。不过在继续之前需要提醒你:正则表达式并不能覆盖词法分析可能需要做的一切;有时必须超越 lex 的扫描模型。下一节将给出一个真实世界的例子。
正则表达式并非万能
如果你上过"计算理论"课程,大概率会见到这样的证明:正则表达式无法匹配 编程语言中某些常见模式,尤其是同一模式可以嵌套自身的情形。本节还将展示,正则表达式在其他方面也并非总能胜任。
当正则表达式无法覆盖语言中的所有词法任务时,怎么办?你可以手写词法分析器 来处理由正则生成器搞不定的古怪情形------代价可能是多花上一天、一周,甚至一个月。不过,在几乎所有真实的编程语言中,正则表达式已经足够接近成品扫描器的需求,你只需再加**少数"额外招式"**即可。下面给出一个真实世界的小例子。
Unicon 与 Go 都提供了分号自动插入 。语言定义了一套词法规则,按需插入分号,从而让程序员大多数时候不必操心。你也许已经注意到:Unicon 的代码示例里几乎没有分号。不幸的是,这些"自动插入分号"的规则无法用正则表达式描述。
在 Go 中,你几乎可以这么做:记住上一个返回的 token ,并在"匹配到换行符"的语义动作里做一些检查;若满足条件,就把这个换行当作分号返回 。但在 Unicon 中,你必须继续向前扫描 ,在换行后读下一个 token,再决定是否应插入分号!因此,Unicon 的分号插入更精确,比 Go 更少出问题。比如,在 Go 中,你不能写出经典的 C 风格换行大括号:
csharp
func main()
{
...
}必须把左花括号写在函数头这一行:
csharp
func main() {
...
}要避免这种让人发笑的限制,词法分析器必须提供一个 token 的前瞻 :它需要读到下一行的第一个 token,再决定是否在换行处插入分号。
在我们的 Jzero 扫描器里实现分号插入,会很"不像 Java"。但如果真要做,也可以走 Go 式 或 Unicon 式 两条路。这里我们展示 Go 式 的一个子集。供参考,Go 的分号插入语义见:golang.org/ref/spec#Se...。
本例体现了 Go 分号插入语义的规则 #1 :看见换行 了------要不要插分号?我们只要记住上一个 token ,如果它是标识符、字面量、break、continue、return、++、--、)、] 或 } ,那么这个换行本身 就应该返回一个新的"伪造"分号 token 。你可以修改 newline() 方法:若应插入分号则返回布尔值 true。
这会打破我们"一份 lex 规范同时兼容 Unicon 与 Java "的策略。我们需要在 lex 规范里写"要不要返回分号 "的条件判断,但两种语言的语法不同 。在 Unicon 中,lex 规范里的 if 可能写成:
kotlin
\n { if j0.newline() then return j0.semicolon() }而在 Java 中,需要括号且没有关键字 then:
kotlin
\n { if (j0.newline()) return j0.semicolon(); }本书的 GitHub 仓库提供了带分号插入 的 Unicon 主模块修改版 j0go.icn 。它在 j0.icn 的基础上新增了全局变量 last_token,修改了 scan() 与 newline(),并添加了构造"人工 token"的 semicolon() 方法。变更的方法如下。判断"上一个 token 的类别是否属于触发分号的一组类别"时,示例顺便展示了 Unicon 的生成器 :表达式 !")]}" 是把 ")" | "]" | "}" 依次送入 ord() 的巧写法:
matlab
method scan(cat)
last_token := yylval := token(cat, yytext, yylineno)
return cat
end
method newline()
yylineno +:= 1
if (\last_token).cat ===
( parser.IDENTIFIER|parser.INTLIT|
parser.DOUBLELIT|parser.STRINGLIT|
parser.BREAK|parser.RETURN|
parser.INCREMENT|parser.DECREMENT|
ord(!")]}") ) then return
end
method semicolon()
yytext := ";"
yylineno -:= 1
return scan(parser.SEMICOLON)
end这里有两点很有意思。其一,同样是换行字符 (在多数语言里只是空白),有时 要返回一个(插入的分号)整数码 ,有时 什么也不返回------这就是我们在"换行"的语义动作里引入 if 的原因。其二,semicolon() 产出的人工 token :它的效果与"程序员在源码里键入了一个分号"无异。
Java 版本在仓库中的 j0go.java 。关键部分如下。它与 Unicon 版 j0go.icn 行为一致:新增 last_token,修改 scan() 与 newline(),并添加构造人工 token 的 semicolon()。只是代码略长。在 newline() 中,使用 switch 检查上一个 token的类别是否触发分号插入:
csharp
public static int scan(int cat) {
last_token = yylval =
new token(cat, yytext(), yylineno);
return cat;
}
public static boolean newline() {
yylineno++;
if (last_token != null)
switch(last_token.cat) {
case parser.IDENTIFIER: case parser.INTLIT:
case parser.DOUBLELIT: case parser.STRINGLIT:
case parser.BREAK: case parser.RETURN:
case parser.INCREMENT: case parser.DECREMENT:
case ')': case ']': case '}':
return true;
}
return false;
}
public int semicolon() {
yytext = ";";
yylineno--;
return scan(parser.SEMICOLON);
}完整的 Go 分号插入语义更复杂一些,但在匹配到换行的扫描阶段 插入分号其实不难。想了解 Unicon 如何做得更好的,可参考 Unicon Implementation Compendium :www.unicon.org/book/ib.pdf。
总结
本章介绍了编程语言在读取源代码字符 时用到的关键技术与工具。得益于这些技能,你的编译器/解释器处理的不再是海量字符,而是规模更小的词/记号序列。
我们覆盖了大量内容:当输入字符被读入时,会被分析并分组成词素(lexeme) ;词素要么被丢弃(注释与空白),要么被分类供后续语法分析使用。
除了对词素分类,你还学会了如何把它们封装为 token :每个被分类的词素会对应一个对象实例,记录词素文本、类别,以及其来源位置等信息。
这些词素类别 将作为下一章语法分析 算法的主要输入;在解析过程中,token 终将作为语法树的叶子节点被插入。
现在,你已准备好把"词"串成"短语"。下一章将讲述解析(parsing) :检查这些短语是否符合语言的文法。