在当今数字化时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活和工作方式。AI应用的广泛落地离不开强大的算力支持,而GPU作为AI计算的核心硬件,一直是推动AI发展的关键力量。然而,随着国际形势的变化和技术竞争的加剧,依赖单一供应商的GPU芯片已经无法满足国内AI产业的长期发展需求。在这种背景下,将AI应用从英伟达显卡迁移到国产显卡,不仅是技术发展的必然选择,更是保障我国AI产业安全和可持续发展的紧迫任务。
一、迁移的紧迫性和必要性
(一)国际形势的挑战
近年来,美国对中国的高科技产业实施了一系列限制措施,尤其是对高端AI芯片的出口禁令,严重影响了国内AI产业的正常发展。2024年12月3日,中国半导体行业协会等四大协会联合发布声明,呼吁企业谨慎采购美国芯片,并扩大与其他国家和地区芯片企业的合作。这一举措凸显了我国在AI芯片领域实现自主可控的紧迫性。
(二)技术自主可控的需求
依赖进口芯片不仅存在供应风险,还可能面临技术封锁和安全威胁。国产AI芯片的崛起为我国AI产业提供了新的选择。通过将AI应用迁移到国产显卡,可以有效降低对国外芯片的依赖,确保技术的自主可控,保障国家信息安全。
(三)国内市场的潜力
国内AI市场庞大且应用场景丰富,从智能安防到自动驾驶,从医疗影像到金融科技,AI技术的应用无处不在。国产显卡的性能不断提升,已经具备了替代进口芯片的能力。将AI应用迁移到国产显卡,不仅可以满足国内市场的多样化需求,还能为国产芯片的发展提供广阔的市场空间。
二、迁移到底难在哪?
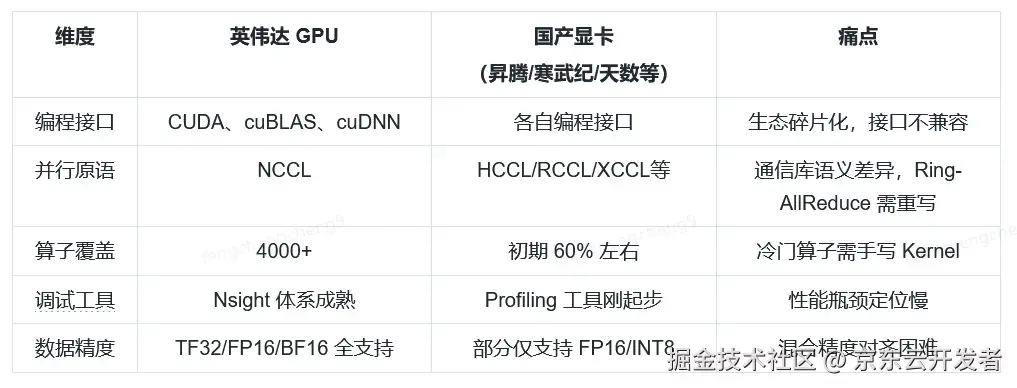
痛点的核心在于缺乏一套基于国产显卡的端到端迁移工具链和解决方案,支持算法人员无感知地从GPU迁移至国产算力。
三、JoyScale "零感知"迁移栈
京东云JoyScale异构算力管理平台经过在京东内场和外场万卡集群打磨,完成了 40+ 主流模型迁移,沉淀出 JoyScale 全栈方案,其核心思想是:
- 零侵入:算法代码一行不改,仅通过后端切换完成迁移。
- 可验证:每一步都有黄金对照(GPU 基线),误差可量化、可回滚。
- 可扩展:新增芯片≈插件式接入,核心框架保持不变。
- 全链路:训练→微调→推理→上线监控,端到端覆盖。
3.1 系统架构
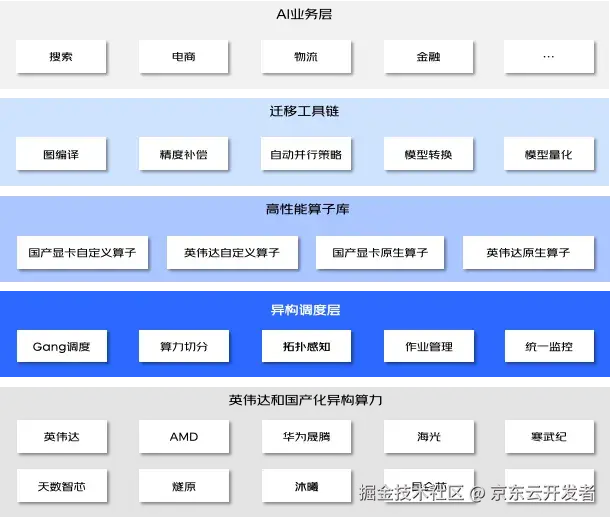
3.2 迁移方案
- 硬件适配
-
- 加速卡调度适配针对国产显卡的卡间互联技术,开发适配的调度插件。例如,昇腾910B的HCCS架构要求同一Pod内的处理器必须在同一HCCS环内,否则任务会失败。
- 算子支持度分析通过工具(如Pytorch Profiler)提取GPU算子,与国产显卡支持的API清单进行对比,对不支持的算子进行适配开发。
- 性能调优结合国产显卡的硬件特性,通过Profile获取每个算子的执行时间,对较慢算子进行精细优化,通常要结合底层硬件架构特性进行优化,例如数据对齐,转换为连续内存等。同时也可以使用厂商API将多个算子进行融合以及转换为子图方式提交到加速卡等加速手段。
- 软件适配
-
- 程序迁移 将基于CUDA的代码迁移到国产显卡支持的框架。例如,将
torch.cuda.xxx()接口替换为torch.npu.xxx()接口。 - 框架优化在框架层为国产显卡和英伟达GPU提供统一的API接口,实现了一套API下NPU和GPU用户无感、0成本无缝切换训练。
- 程序迁移 将基于CUDA的代码迁移到国产显卡支持的框架。例如,将
- 模型适配
-
- 模型量化通过模型量化技术,减少模型的计算量和存储需求,提高在国产显卡上的运行效率。
- 软硬协同深度优化: 通过Triton编译和CANN融合等技术对热点算子(如flash attention、rotary_embedding、npu_matmul_add_fp32等)进行精细调优,实施锯齿Attention、动态输入拼接、全子图下发以及重计算流水线的独立调度和自适应重计算等深度优化措施,实现了百卡 MFU达60%。同时,通过权重更新通信隐藏、CoC计算通信并行、启发式自动并行策略搜索、BF16低精度通信和多机间RDMA通信等技术,达到了百卡扩展系数0.93,从而实现了千亿至万亿参数模型训练的近线性横向扩展。
- 推理优化
-
- 通过GE图编译优化和ATB高性能算子技术对Paged Attention、Flash Attention、Sub_Mul_Concat等操作进行深度优化,实现整图下发能力,通过算子setup(workspace、tiling)、下发、计算实现流水线并行,有效隐藏了算子调度开销。同时支持W8A8 SmoothQuant量化、W4A16 AWQ量化技术,显著较少了计算量与访存密度。
- 模型服务采用双后端热备,流量 5% → 30% → 100%逐级灰度上线国产算力,失败率 > 0.1% 自动回滚英伟达GPU。
- 统一调度和监控
-
- 自研基于云原生的万卡级异构算力统一调度系统,自动识别CPU NUMA和网络拓扑,确保任务被分配到最优的计算和网络资源上,从而最大化任务的执行效率。通过Gang调度、算力切分池化等技术提高集群的整体占用率。
- 支持可视化监控体系,统一监控异构显卡的算力利用率、显存利用率,以及AI负载的服务吞吐、失败率、延时、token数等服务化指标。
四、典型落地场景
- 零售场景: 利用多模态模型对商品视频进行分析,抽取能够表征视频的一系列tag。从英伟达GPU无缝迁移到国产NPU,与GPU比对效果无明显差异。在输出Token数量一致的前提下,二者平均响应时长基本保持一致。
- 智能客服基于大模型的客服Agent助手,使用过往沉淀QA数据对模型进行微调,迁移到国产算力进行微调后,与基于英伟达GPU微调的模型分析结果相似,且96%问题分配下游处理路径相同。
- 物流场景基于国产算力微调的模型与基于英伟达GPU微调的模型在物流地址解析等任务的训练结果分别达到了91.03%与91.08%,二者表现基本一致,AI预分拣已上线多个省份,每天识别3万条以上异常地址。
五、结语
将AI应用从英伟达显卡迁移到国产显卡,不仅是技术发展的必然选择,更是保障我国AI产业安全和可持续发展的紧迫任务。迁移不是可选项,而是生存项! 越早动手,窗口期越长。京东云JoyScale通过完整且成熟的迁移软件堆栈,帮助客户有效降低迁移成本,提高迁移效率,确保AI应用在国产显卡上的高效运行,让客户更多地把精力更多放在算法创新上。京东云愿意与更多客户携手,一起把国产算力推向极致。