你是否曾有过这样的经历?在AI上输入一个问题,结果返回的内容让你怀疑自己是不是在火星上网?或者问AI一个问题,它给你的答案却南辕北辙?别担心,这不是你的问题,而是背后的"检索器"没有练好内功!
在RAG(检索增强生成)这门武功中,检索器就像是掌门人的左膀右臂,它的好坏直接决定了最终的武功效果。今天,我们就来聊聊这个看似简单实则暗藏玄机的检索器江湖。
为什么要学习检索器?
想象一下,你有一个聪明的朋友,他记忆力超群,但是有个奇怪的特点:他只能回答你问他的问题,如果你问得不准确,他的回答就会离谱。这就是大语言模型的真实写照!而RAG系统中的检索器,就是帮助你"问对问题"的智囊团。
掌握了检索器的设计与优化,你就能:
- 让AI回答更准确、更相关
- 减少幻觉,增加事实依据
- 处理复杂问题,实现多步骤推理
- 构建适合特定领域的知识系统
检索器的武林门派
在检索器的江湖中,有几大主要门派,各有各的独门绝技。
密集段落检索(DPR)派
DPR是武林中人气最高的门派之一,他们的核心心法是"双塔功"。
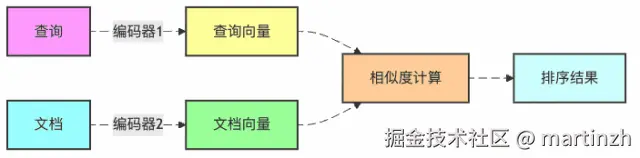
图1:DPR双塔功心法图解
想象一下,你在图书馆寻找一本书。传统方法是看目录和索引,而DPR则是理解书的"灵魂"------它不只看关键词匹配,而是理解语义本质。
"我昨天吃了一个苹果"和"我使用的是苹果手机"中的"苹果"虽然字面相同,但DPR能分辨它们的不同意思。这就像武林高手能从对手微小的肌肉变化中预判出招一样精准!
实战应用:当你问"什么是量子计算"时,即使文档中没有这个确切短语,DPR也能找到讲解量子计算原理的相关段落。
ColBERT精细互动派
如果说DPR是用整体印象来判断相关性,那么ColBERT就是更加细致入微,它保留了每个词的向量表示。
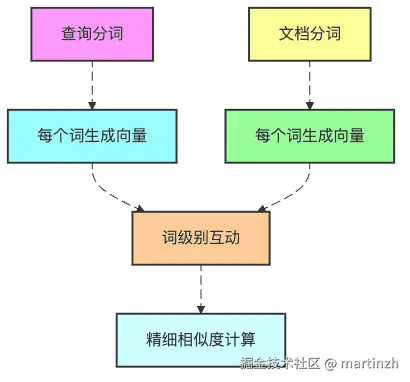
图2:ColBERT精细互动功法
这就像两个人在交谈,不仅仅是听完整句话才理解,而是每个词都在实时互动和理解。
我朋友小李前几天就用ColBERT做了一个法律文档检索系统。有意思的是,当用户查询"合同违约赔偿标准"时,系统不仅能找到直接包含这些词的文档,还能找到使用"违反协议的补偿规则"这种不同表达方式的相关条款。这种细粒度的匹配能力,就是ColBERT的独门绝技!
多向量派
多向量派的高手认为,一篇文档复杂多变,用一个向量表示太单薄了,就像用一句话概括《三国演义》一样不够全面。
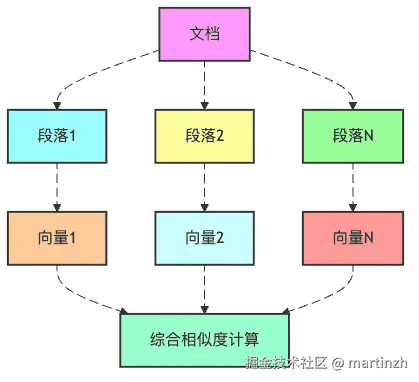
图3:多向量表示法
想象你在描述一个人,你会说他是"高个子、戴眼镜、喜欢打篮球",而不是简单地说"是个男的"。多向量法就是这样,它从多个角度来描述文档的特征。
我之前用单向量搜索"苹果公司的创始人",系统可能会把包含"苹果派的制作方法"的文档也检索出来(因为都含有"苹果"这个关键词)。而采用多向量后,每个段落都有独立的语义表示,能更精准地匹配到乔布斯创立苹果公司的相关信息。
图检索派
图检索派是检索江湖中的关系网高手,他们擅长构建知识之间的联系。

图4:知识图谱检索示意图
这就像一个老江湖,不仅知道每个人的特长,还知道谁和谁是师兄弟,谁曾经跟谁有过过节。当你需要找特定信息时,他能通过这张关系网,找到最合适的人选。
举个例子,如果你问"谁是牛顿的老师",传统检索可能需要直接找包含答案的文档。但图检索能先定位到牛顿这个节点,然后查找与之相连的"师承"关系,最后找到答案,即使单篇文档中没有直接说明这个关系。
检索策略优化:从入门到精通
查询扩展:一招变多招
查询扩展就像武功中的"一招变多招",不再拘泥于固定的招式。
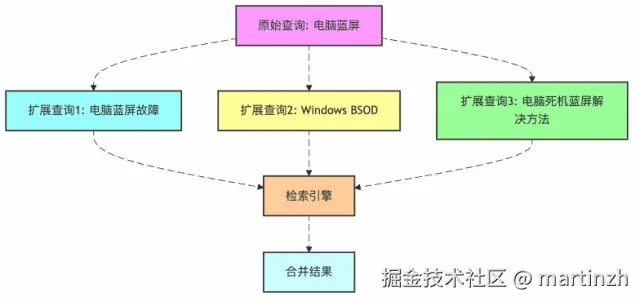
图5:查询扩展的多管齐下策略
想象你在淘宝搜索一款耳机,但不知道专业术语。你可能输入"好听的耳机",但系统会帮你扩展为"高音质耳机"、"音质好的降噪耳机"等更专业的术语,从而找到更相关的产品。
上周我在做一个医学RAG系统时,用户查询"头痛怎么办",系统自动扩展为"偏头痛治疗方法"、"紧张性头痛缓解"、"头痛药物推荐"等多个查询,然后综合结果,大大提高了信息的全面性和准确性。
伪相关反馈:试探与调整
伪相关反馈有点像武侠小说中的"试招"------先出几招试试对方实力,再根据反应调整战术。
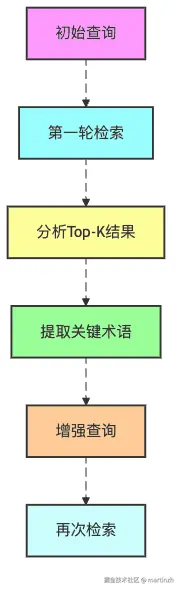
图6:伪相关反馈的迭代改进过程
生活中的例子:你去一家新餐厅,不知道哪些菜好吃,于是先点了几道看起来不错的菜。吃过之后,你发现这家店的海鲜特别新鲜,下次再来就会重点考虑他们的海鲜菜品。
在实际应用中,假设用户搜索"气候变化影响",系统首先检索出一批文档,分析后发现这些文档中频繁出现"全球变暖"、"海平面上升"等术语,于是在第二轮检索中加入这些术语,得到更精准的结果。
多跳检索:武功连招
多跳检索就像武侠中的"连招",一招接一招,步步为营,最终达到目标。

图7:多跳检索的推理链条
想象你在准备一次复杂的旅行:先查航班,然后是酒店,接着是当地的景点和交通方式。每一步都依赖前一步的信息,逐步完善你的旅行计划。
前段时间我在做一个学术问答系统,用户问"量子纠缠对量子计算有什么影响"。系统先检索量子纠缠的基本概念,提取关键信息后再检索量子计算相关文档,最后才能把两者联系起来给出完整答案。这个过程如果一步到位,很可能找不到直接解答的文档。
时间感知检索:武功也要与时俱进
时间感知检索就像武侠世界的"与时俱进",了解不同时期的武功特点和变化。
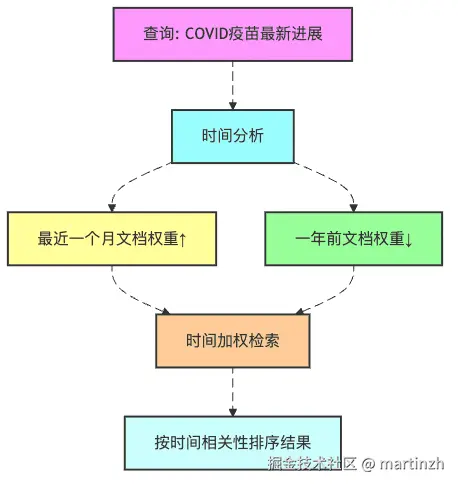
图8:时间感知检索的权重调整
生活中,如果你问朋友"最近有什么好看的电影",你期望的肯定是近期上映的电影,而不是十年前的经典。同理,当你搜索"iPhone最新型号"时,你希望看到的是最新发布的机型,而不是几年前的产品。
在一个新闻RAG系统中,当用户查询"俄乌冲突现状"时,系统会优先检索最近的新闻报道,而将较旧的背景资料放在后面,确保信息的时效性。
检索结果处理:精益求精
检索结果过滤:明察秋毫
结果过滤就像武林中的"明察秋毫"功夫,能够在繁杂信息中过滤掉无关紧要的内容。

图9:多层次检索结果过滤流程
就像你在购物网站上使用筛选条件:先选品牌,再选价格区间,然后是评分...一步步筛选出最符合你需求的商品。
在一个法律文档RAG系统中,我们设置了多层过滤:首先过滤掉相似度低于0.7的文档,然后去除90%以上重复的内容,最后通过一个小模型评估文档质量,只保留高质量、高相关的结果。这样一来,生成的法律建议既准确又言之有物。
相关性重排序:独孤求败
重排序技术如同武林中的"独孤求败"剑法,在初步比较后进行更精细的判断,找出真正的高手。
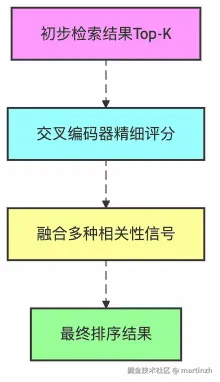
图10:重排序技术精细评分过程
这就像招聘流程:简历筛选后,还要通过面试、背景调查等多个环节,全方位评估应聘者,而不仅仅看纸上的资历。
举个例子,在一个产品推荐系统中,我们先用快速检索找出50个相关产品,然后使用更复杂的交叉编码器分析每个产品与用户查询的深层语义关联,最后结合用户历史行为、产品评分等多种信号,得出最终的推荐排序。
多样性检索:八面玲珑
多样性检索如同"八面玲珑"的江湖高手,能从多个角度解决问题,不拘泥于单一方案。
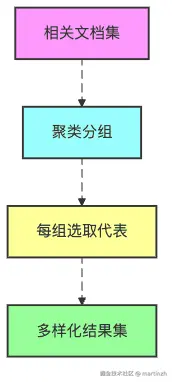
图11:基于聚类的多样性检索方法
就像你查询"减肥方法",不希望看到10个都在讲"少吃多运动"的结果,而是期望了解"饮食控制"、"有氧运动"、"力量训练"、"间歇性断食"等不同角度的方法。
我之前做过一个旅游推荐系统,当用户搜索"日本旅游"时,传统检索可能返回10个都是关于东京的结果。采用多样性检索后,系统会确保结果中包含东京、大阪、京都、北海道等不同地区的信息,大大提升了用户体验。
检索结果摘要:化繁为简
结果摘要技术如同武功秘籍的"精要总结",把长篇大论提炼为精华要点。
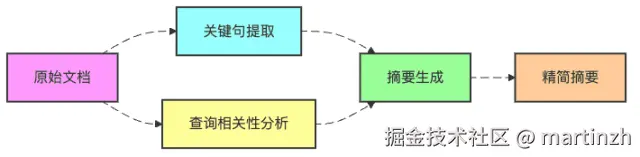
图12:查询相关的摘要生成流程
就像你看电影前先看预告片,或者看书前先读目录和简介,好的摘要能让你快速了解核心内容。
在实际应用中,一个医学RAG系统收到"糖尿病治疗方法"的查询后,不会直接把长达几十页的医学论文扔给大语言模型,而是先提取每篇文档中最相关的2-3个段落,如"口服药物治疗"、"生活方式干预"等关键信息,再送入生成模型,大大提高了回答的针对性和效率。
实战案例:构建完美的RAG检索器
想象你正在为一家在线教育平台构建一个学习助手,需要回答学生关于各种学科的问题。
第一步:选择基础检索器
- 我们选择DPR作为基础架构,因为它在语义理解上表现优异
- 使用适合教育领域的嵌入模型进行微调,确保理解学科专业术语
第二步:实施查询增强
- 针对学生的口语化问题自动扩展专业术语
- 例如:"牛顿怎么发现重力的" → "牛顿重力理论发现历史"+"万有引力定律发现过程"
第三步:构建多跳检索链
- 针对需要推理的问题,如"为什么恐龙灭绝会影响今天的生物多样性"
- 第一跳:检索恐龙灭绝原因
- 第二跳:检索生态系统演变
- 第三跳:连接到现代生物多样性
第四步:优化结果处理
- 过滤教育级别不匹配的内容(小学生不需要看到博士级解释)
- 对结果进行重排序,优先考虑权威教材和经过验证的资源
- 生成适合学生理解水平的摘要
效果对比:
- 优化前:回答宽泛,信息过载或不够精确
- 优化后:针对学生实际问题和水平提供精准、易懂的解答
检索器的武功心法
通过本文的江湖游历,我们领略了检索器的各种武功秘籍:
- 基础功法:DPR、ColBERT、多向量、图检索等基础架构
- 进阶心法:查询扩展、伪相关反馈、多跳检索等策略优化
- 点穴绝技:结果过滤、重排序、多样性、摘要等精细处理
记住,优秀的RAG系统不是靠一招制敌,而是融会贯通各种技巧,灵活应对不同场景。就像武侠小说中的绝世高手,不是只会一门绝技,而是能够见招拆招,随机应变。
下次当你构建或优化RAG系统时,希望这些"检索器江湖秘籍"能帮你在信息检索的武林中称霸一方!
你现在明白了吗?RAG系统的强大不仅仅在于大语言模型有多聪明,更在于检索器能多精准地找到相关信息。就像再厉害的大厨,如果给他的食材不对,也做不出完美的菜肴。
现在,是时候用这些武功秘籍武装你的RAG系统了!