都知道 Redis 是跑在内存中的,既然在内存,能存储的数据是有限的,如果存储的数据太大,就必须引入更多的 Redis 服务来进行分摊数据,所以 Redis 中集群模式就是来解决这类问题的。
一 集群的 3 种实现
1. 哈希求余
前置:多个 Redis 服务管理的总数据,这些 Redis 服务称为分片。
和普通的哈希表类型,通过 Key 经过某个方式计算得到整数,在 mod 总分片的个数得到实际分配到哪个分片。
示例图:

比如上述的 Key 已经映射到了对应的分片中。
可以看到通过哈希函数和 mod 放到对应的 分片 中,操作很简单。
缺点:
- 如果引入了多个 Redis 服务,也就是扩容,带来的问题就是分片更多,mod 的时候要变换,原来所有的 Key 都要重新进行哈希运算并 mod 之后的分片总数。
- 可能有的 Key 在原来的分片中通过哈希计算到另一个分片中,就需要进行数据迁移,这里分片可能挂着多个从分片(提高可用性),所以不紧紧是原分片,从分片也需要迁移,工作量巨大。
主要因为要进行搬运和重新哈希计算导致效率极低,可以引入更多的集群直接把原分片中的 Key 计算后导入新的集群中,就避免了数据迁移,但成本高,所以哈希求余这种方式虽然简单但不高效。
2. 一致性哈希
预先让各个分片管理一个区域范围内从 Key。
示例:
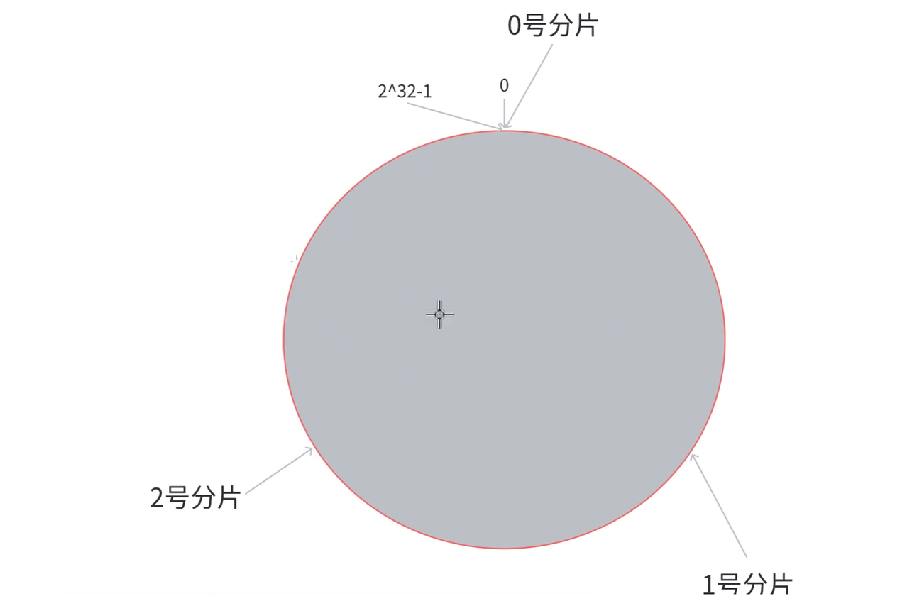
假设 Key 落到 0 ~ 1 号分片之间,顺序查找,查找到 1 号分片,该 Key 就归 1 号分片管理。
这些 0 ~ 1 号分片的 Key 是连续的,相比较上面的哈希求余的方式 Key 与 Key 之间是交替的。
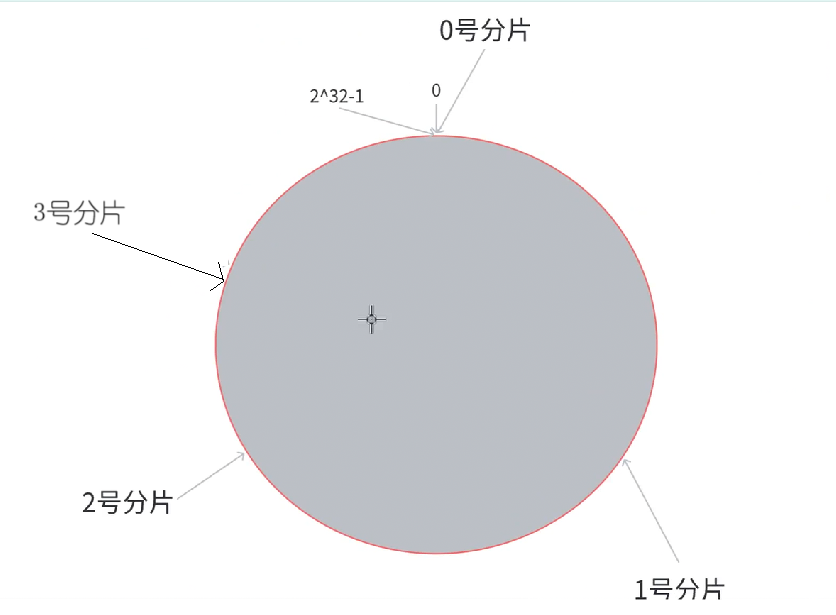
假设扩容,引入 3 号分片。3号分片落到 0 ~ 2 号之间,2 ~ 3 号之间归 3 号分片关,原来归 0 号分片管,现在只需要把这部分的 Key 迁移到 3 号分片即可,相比较哈希求余,迁移的数据量大大降低。
缺点:
- 可以看出来,虽然迁移的数据量降低,但每个分片管理的 Key 不均匀,导致 1,2 号分片管理更多的 Key 承受的压力更大,3,0 号分片管理少部分 Key 比较空闲。
一致性哈希虽然能减少数据量的迁移,但会造成分片倾斜问题,也就是分片之间管理的 Key 大小范围不一样,这里可以引入多个分片,比如插入到 0 ~ 1,1 ~ 2 ,号之间来全局的均摊 Key,但成本更高。
3. 哈希槽分区
事先定于好所有的槽位,并由分片动态管理每段区间的槽位,一般是 16384 个槽位。
假设有 3 个分片各自管理连续的槽位,这点像一致性哈希,Key 通过哈希函数计算,在 mod 16383 在特定的槽位,这点像哈希求余,所以本质是把 哈希函数 和 一致性哈希 结合了。
假设扩容 3 号分片:
- 3 号分片从 0 ~ 2 号分片中各拿一点槽位组成并尽量个其他分片持有的槽位保持一致。
- 拿出来的槽位会执行迁移操作并改变他所属的槽位,这里可以通过位图来标识每个分片管理哪些槽位,比如一共 16384 / 2 = 2 K。
- 迁移的数据量约为四分之一,管理的槽位数量基本均匀。
哈希槽分区相较于前 2 个算法的区别:
- 相较于哈希函数 :迁移的数据量不大。
- 相较于一致性哈希 :每个分片管理的槽位几乎均匀。
槽位一共 16384 个,分片是不是不能超过这个上限?
答:是的。
为什么是 16384 个槽位?
答:这些分片之间保持连通性势必要通过心跳包来维持,包含的字段有该分片持有哪些槽位,通过位图,一共携带 2K 的大小,如果更多,比如 65535 ,那就是 8 K了,心跳包发送的频率是很大的,心跳包的大小越大,网络带宽就越大,空间占用也越大,毕竟 Redis 是跑在内存中的,所以 16384 是足够满足的。

