在分布式系统中,Redis是当之无愧的"瑞士军刀"------它既是高性能缓存,也是分布式锁工具,还能做计数器、消息队列、会话存储,甚至实时排行榜。
从电商秒杀的库存缓存,到社交APP的点赞数统计,再到金融系统的分布式事务锁,Redis几乎无处不在。
本文从数据模型、核心原理、关键特性到实战避坑,全面拆解Redis的底层逻辑,帮你从"会用set/get"到"懂原理、调优、避坑",真正掌握这个分布式系统必备中间件。
一、先搞懂:Redis是什么?为什么这么火?
Redis(Remote Dictionary Server)是一个开源的高性能键值对数据库,核心特点可以用"快、多、活"三个字概括:
- 快:单机QPS轻松过10万,延迟毫秒级(内存操作+单线程模型+IO多路复用的共同作用);
- 多:支持8种数据结构(String、Hash、List、Set、ZSet等),能满足缓存、计数、排队等多样化需求;
- 活:支持持久化(数据不丢)、主从复制(读写分离)、哨兵(高可用)、集群(水平扩展),适配从单机到分布式的全场景。
一句话总结:Redis是"基于内存的、支持多种数据结构的、可持久化的高性能键值数据库",这也是它能在缓存、分布式锁等场景中"封神"的根本原因。
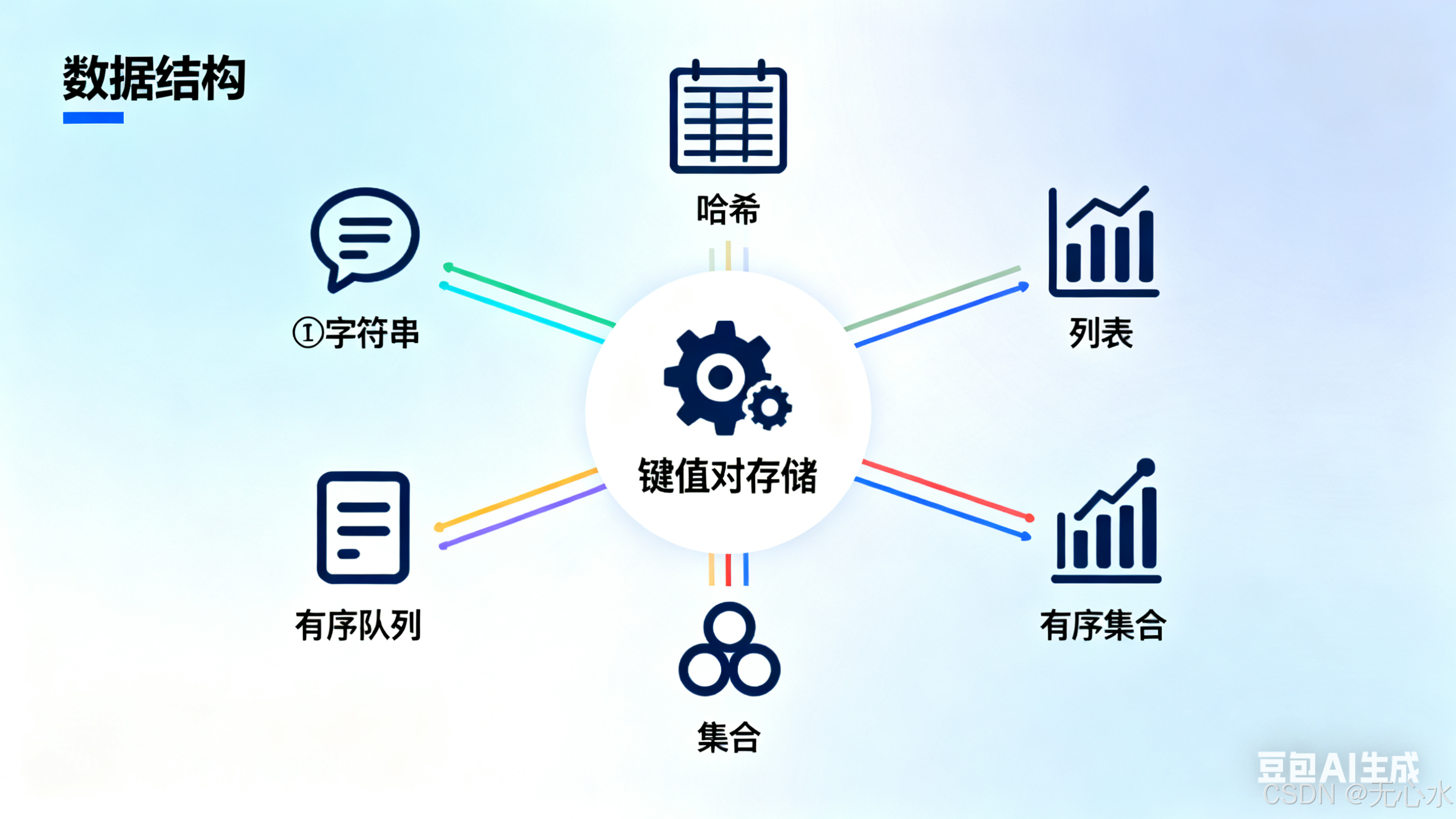
二、核心数据模型:8种数据结构,各自有何神通?
Redis的核心竞争力之一是"丰富的数据结构",每种结构都对应特定的业务场景,理解它们的底层实现,才能用好Redis。
| 数据结构 | 底层实现(简化版) | 核心特性 | 典型场景 |
|---|---|---|---|
| String(字符串) | 动态字符串(SDS,类似Java的ArrayList,预分配空间减少扩容开销) | 可存文本/二进制数据,支持自增(INCR)、拼接(APPEND) | 缓存用户信息、计数器(文章阅读量)、分布式ID |
| Hash(哈希) | 压缩列表(小数据)/哈希表(大数据) | 键值对集合,适合存储对象(如用户信息:name/age/addr) | 缓存用户/商品详情(比String更灵活,可单独修改字段) |
| List(列表) | 压缩列表(小数据)/双向链表(大数据) | 有序、可重复,支持两端插入/弹出(LPUSH/RPOP) | 消息队列(简单FIFO队列)、最新评论列表 |
| Set(集合) | 哈希表/整数集合(元素为整数且密集) | 无序、不可重复,支持交集(SINTER)、并集(SUNION) | 标签系统(用户标签去重)、共同好友计算 |
| ZSet(有序集合) | 压缩列表(小数据)/跳表+哈希表(大数据) | 有序(按score排序)、不可重复,支持范围查询(ZRANGE) | 实时排行榜(如商品销量TOP10)、延迟队列 |
| Bitmap(位图) | 字符串(按位存储) | 用bit表示状态(0/1),极大节省空间 | 签到统计(365天仅需46字节)、用户在线状态 |
| HyperLogLog | 基数估算算法 | 极小空间统计独立元素个数(误差约0.8%) | UV统计(无需存储所有用户ID,节省内存) |
| Geospatial | ZSet(经纬度转score存储) | 存储地理位置,支持距离计算、附近的人 | 外卖骑手定位、附近的商家推荐 |
关键提醒:数据结构的"底层优化"
Redis对数据结构做了"小数据优化":当数据量较小时(如Hash的键值对少于512个),会用更紧凑的"压缩列表"存储(节省内存);数据量大时自动转为哈希表/双向链表(保证操作效率)。这也是Redis"内存高效"的原因之一。
三、高性能核心:为什么Redis能做到"万级QPS"?
Redis的高性能源于三个核心设计:内存操作+单线程模型+IO多路复用,三者缺一不可。
1. 内存操作:速度的根基
Redis的数据全部存储在内存中(区别于MySQL等磁盘数据库),内存读写速度(约100ns)是磁盘(约10ms)的10万倍。这是Redis"快"的基础,但也带来一个问题:内存断电易失,因此需要"持久化机制"(后文详解)。
2. 单线程模型:避免线程开销
Redis处理命令的核心逻辑是单线程(注意:持久化、集群同步等是多线程),很多人会疑惑:"单线程怎么支撑高并发?" 原因有二:
- 避免线程切换开销:多线程的上下文切换(保存/恢复寄存器、栈信息)会消耗CPU,单线程无需切换,效率更高;
- 内存操作无阻塞:Redis的命令都是内存操作(无磁盘IO),执行速度极快(微秒级),单线程足以处理万级QPS。
关键前提 :单线程模型要求"所有命令必须是短耗时操作",禁止执行KEYS *(遍历所有键,耗时随数据量增长)、HGETALL(全量获取大Hash)等长命令,否则会阻塞整个线程,导致其他请求超时。
3. IO多路复用:高效处理网络请求
单线程如何同时处理成千上万个客户端连接?靠"IO多路复用"(类似"一个接线员同时接听多个电话"):
- 客户端的连接和请求通过Socket通信,Redis用
epoll(Linux)/kqueue(Mac)等IO多路复用器,同时监听多个Socket的读写事件; - 当某个Socket有数据(如客户端发送
SET key value),IO多路复用器会通知Redis处理,处理完再继续监听,无需为每个连接创建线程。
简单说:IO多路复用让单线程Redis能"同时监听并处理多个客户端请求",兼顾了单线程的高效和多连接的并发需求。
四、核心特性:从"单机可用"到"分布式可靠"
Redis的"能打"不仅在于性能,更在于它通过四大特性,解决了"数据持久化、高可用、水平扩展"等分布式系统难题。
1. 持久化:内存数据不丢失
Redis是内存数据库,为避免断电丢失数据,设计了两种持久化机制:
(1)RDB(Redis Database):快照式持久化
- 原理 :按配置的时间间隔(如"5分钟内有1000次写入"),将内存中的所有数据生成快照(二进制文件,
dump.rdb),写入磁盘; - 优点:文件小、恢复速度快(直接加载二进制文件到内存);
- 缺点:可能丢失最后一次快照后的所有数据(如5分钟内宕机,丢失5分钟数据);
- 适用场景:非核心数据(如商品详情缓存),可容忍少量数据丢失,追求恢复速度。
配置示例:
ini
# 5分钟内有1000次写入,触发RDB
save 300 1000
# 10分钟内有10次写入,触发RDB
save 600 10(2)AOF(Append Only File):日志式持久化
- 原理 :将所有写命令(如
SET、HSET)以文本形式追加到appendonly.aof文件,重启时重新执行命令恢复数据; - 优点:数据安全性高(支持"每秒同步"或"每写同步",最多丢失1秒数据);
- 缺点:文件体积大(命令重复存储)、恢复速度慢(需重新执行所有命令);
- 适用场景:核心数据(如用户余额、订单状态),不容忍数据丢失。
配置示例:
ini
# 开启AOF
appendonly yes
# 同步策略:everysec(每秒同步,平衡安全和性能)
appendfsync everysec最佳实践:RDB+AOF混合持久化
Redis 4.0后支持混合模式:AOF文件中包含"RDB快照+增量AOF命令",兼顾RDB的快速恢复和AOF的高安全性,是生产环境首选。
2. 主从复制:读写分离与数据备份
单节点Redis有"单点故障"风险,主从复制通过"一主多从"架构解决:
- 主节点(Master) :接收写请求(
SET、HSET等),并将数据同步给从节点; - 从节点(Slave) :仅接收读请求(
GET、HGET等),数据从主节点同步而来。
核心价值:
- 读写分离:主节点负责写,从节点分担读压力(如秒杀时,大量
GET请求由从节点处理); - 数据备份:从节点是主节点的副本,主节点宕机后数据不丢失。
同步流程:
- 从节点启动时,向主节点发送
SYNC命令,请求全量同步; - 主节点生成RDB快照,发送给从节点,从节点加载快照;
- 全量同步后,主节点将后续写命令实时同步给从节点(增量同步)。
3. 哨兵(Sentinel):高可用自动故障转移
主从复制解决了"数据备份",但主节点宕机后,需要人工切换从节点为主,无法自动恢复。哨兵机制通过"哨兵集群"实现自动化故障转移:
- 哨兵的核心功能 :
- 监控:定期检查主从节点是否存活(发送
PING命令); - 通知:主节点宕机时,通过API通知管理员或其他应用;
- 自动故障转移:主节点宕机后,从哨兵集群中选举新主节点(选一个从节点升级为主),并让其他从节点同步新主。
- 监控:定期检查主从节点是否存活(发送
部署规格:哨兵集群至少3个节点(避免脑裂,少数服从多数原则),确保高可用判断的准确性。
4. 集群(Cluster):水平扩展,突破单机瓶颈
单节点Redis的内存和QPS有限(如单机内存最多100GB),集群通过"分片存储"实现水平扩展:
- 将所有键通过哈希算法映射到16384个"哈希槽"(Hash Slot);
- 集群中的每个节点负责一部分哈希槽(如3个节点,分别负责5000、5000、6384个槽);
- 客户端访问时,根据键的哈希值找到对应的槽和节点,直接访问。
核心优势:
- 容量扩展:新增节点时,迁移部分哈希槽过去,轻松扩容内存;
- 性能扩展:多节点并行处理请求,QPS随节点数增长(理论上线性增长)。
五、实战避坑:Redis最容易踩的5个坑
1. 缓存穿透:查询不存在的键,直击数据库
现象 :黑客恶意请求不存在的键(如user:10086不存在),Redis缓存 miss 后,所有请求打到数据库,导致数据库宕机。
解决:
- 缓存空值:对不存在的键,缓存
null(设置短期过期时间); - 布隆过滤器:提前过滤不存在的键(如用布隆过滤器判断
user:10086是否存在,不存在直接返回)。
2. 缓存击穿:热点键过期,瞬间压垮数据库
现象 :某热点键(如秒杀商品goods:100)过期瞬间,大量请求同时命中数据库,导致数据库压力骤增。
解决:
- 互斥锁:第一个请求获取锁后去数据库查询,其他请求等待锁释放后从缓存获取;
- 热点键永不过期:核心热点键不设置过期时间,通过后台异步更新。
3. 缓存雪崩:大量键同时过期,数据库被冲垮
现象 :缓存中大量键在同一时间过期(如凌晨2点批量过期),请求全部落到数据库,导致数据库崩溃。
解决:
- 过期时间加随机值:每个键的过期时间=基础时间+随机数(如
3600 + rand(0, 300)),避免同时过期; - 多级缓存:本地缓存(如Caffeine)+ Redis,即使Redis过期,本地缓存可临时兜底。
4. 单线程阻塞:长命令拖慢整个Redis
现象 :执行KEYS *(遍历所有键)、HGETALL bighash(全量获取大Hash)等长命令,阻塞单线程,导致其他请求超时。
解决:
- 禁用长命令:用
SCAN替代KEYS(分批遍历),HSCAN替代HGETALL(分批获取Hash); - 监控慢查询:开启
slowlog(配置slowlog-log-slower-than 10000,记录耗时>10ms的命令),定期排查。
5. 持久化配置不当:数据丢失或性能下降
现象 :仅用RDB且间隔太长,宕机丢失大量数据;AOF用"每写同步",导致Redis写入性能暴跌。
解决:
- 核心数据:开启混合持久化(RDB+AOF),AOF同步策略选
everysec; - 非核心数据:仅用RDB,调整合理的快照间隔(如15分钟+10000次写入)。
六、总结:Redis为什么是分布式系统的"必选项"?
Redis的成功源于"极致性能+灵活数据结构+完善的分布式支持":
- 性能上,内存操作+单线程+IO多路复用,支撑万级QPS,满足高并发场景;
- 功能上,8种数据结构覆盖缓存、计数、队列等多样化需求,开箱即用;
- 可靠性上,持久化+主从复制+哨兵+集群,从单机到分布式场景都能稳定运行。
无论是中小团队的简单缓存需求,还是大型企业的高可用分布式系统,Redis都能通过灵活的配置和特性,成为架构中的"关键一环"。
互动话题:你在项目中用Redis解决过哪些棘手问题?遇到过哪些印象深刻的坑?欢迎在评论区分享你的实战经验~