1.在terminal中检查是否安装brew命令
brew --version
如果没有安装,在terminal中执行命令,安装brew
/bin/bash -c "$(curl -fsSL [https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"](https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)\ "https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"")
安装完成后,再重新打开teminal brew --version进行检查
2.下载安装hadoop
brew install hadoop
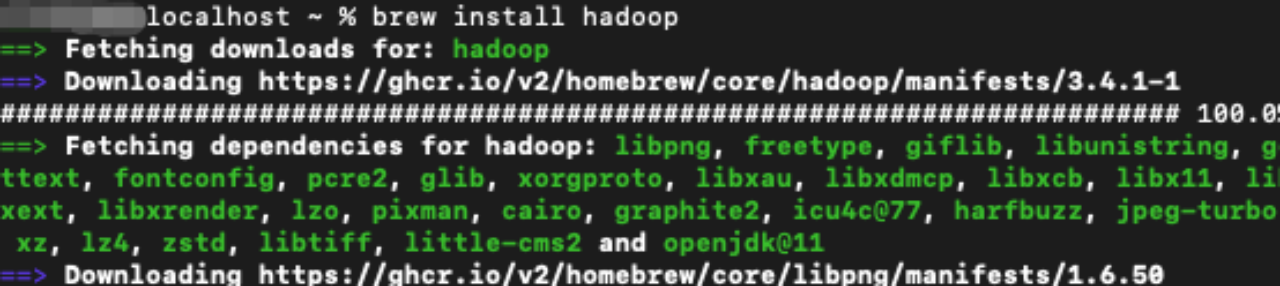
通过hadoop version 检查是否安装完成
3.查看是否可以远程登录,在terminal中执行命令
ssh localhost

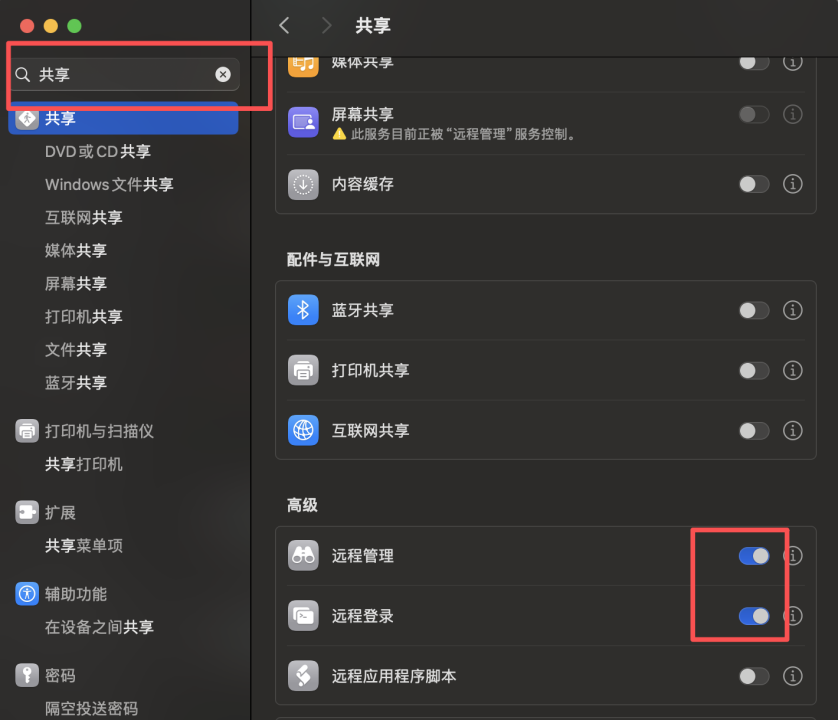
如果显示不允许登录,在系统中设置允许远程登录,进行系统设置

4.查看hadoop安装目录
brew --prefix hadoop

5.修改hadoop配置信息
cd /opt/homebrew/opt/hadoop/libexec/etc/hadoop
修改vi core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8082</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/homebrew/opt/hadoop/datatmp</value>
</property>
</configuration>修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--不是root用户也可以写文件到hdfs-->
<property>
<name>dfs.permissions</name>
<value>false</value> <!--关闭防火墙-->
</property>
<!--把路径换成本地的name坐在位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/homebrew/opt/hadoop/datatmp/dfs/name</value>
</property>
<!--在本地新建一个存放hadoop数据的文件夹,然后将路径在这里配置一下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/homebrew/opt/hadoop/datatmp/dfs/data</value>
</property>
</configuration>格式化namenode
输入hdfs namenode -format

修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:9000</value>
</property> 6.启动hdfs
在/opt/homebrew/opt/hadoop/libexec/sbin目录输入
./start-dfs.sh 如报以下错误
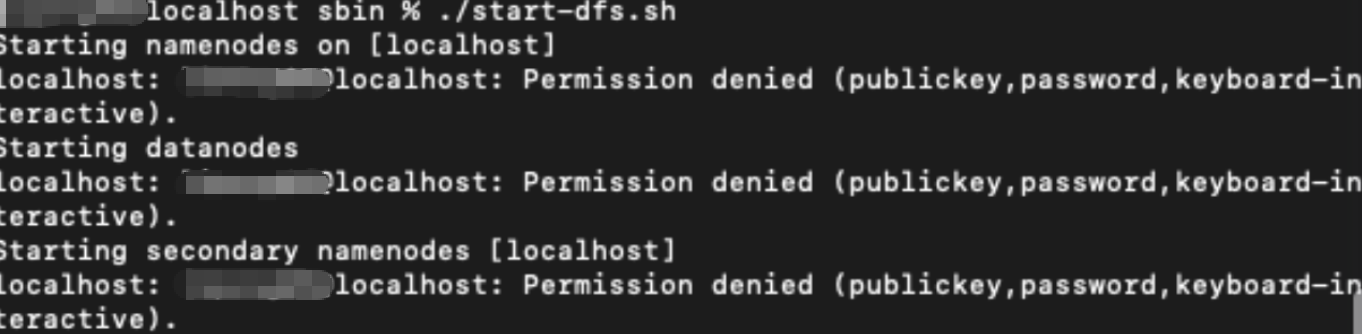
执行命令
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
chmod og-wx ~/.ssh/authorized_keys
重新启动
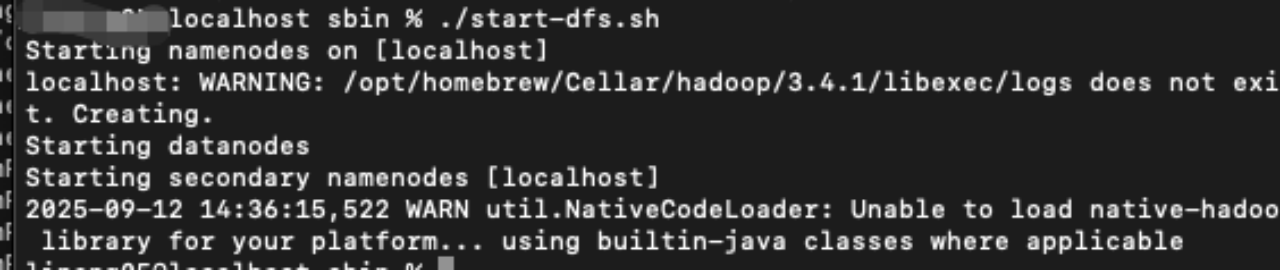
在sbin目录下输入./start-dfs.sh
在浏览器中输入http://localhost:9870/ 如果出现以下界面说明安装成功
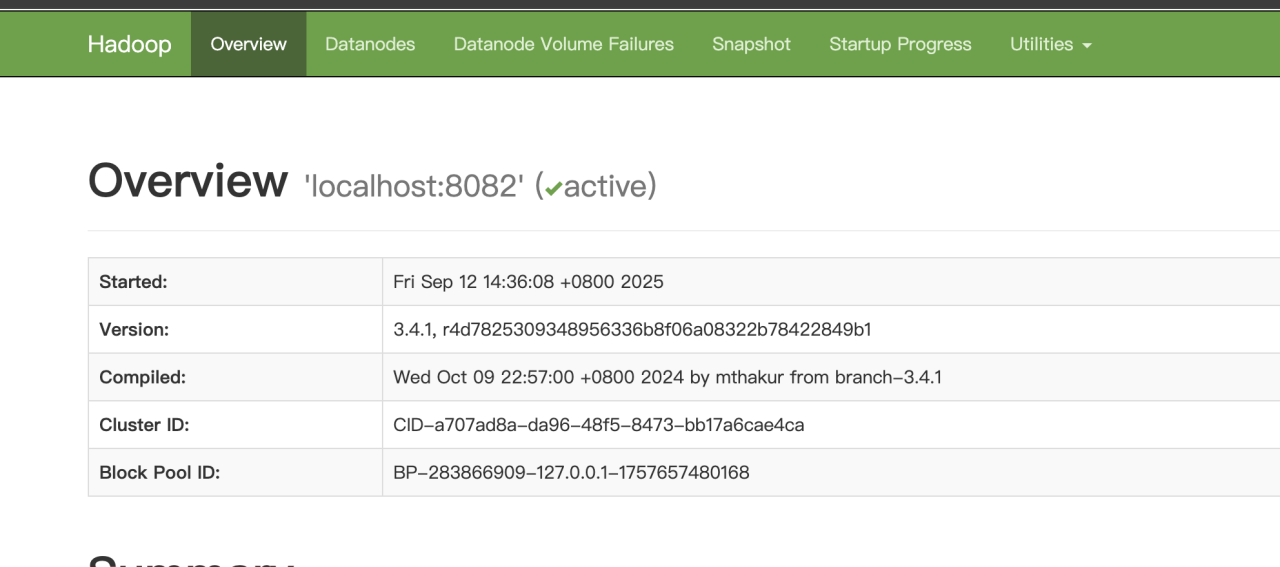
使用 ./stop-dfs.sh 关闭服务
7.启动yarn
在sbin目录下输入./start-yarn.sh
如果启动的过程中出现错误
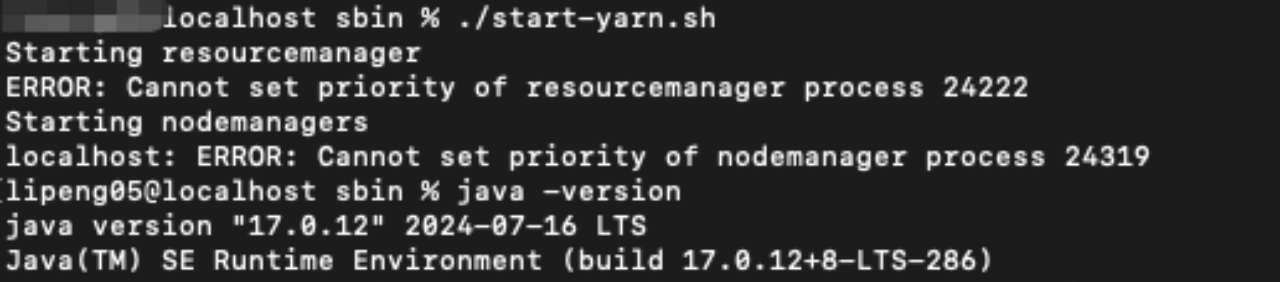
原因是jdk版本过高,安装jdk8.重新配置JAVA_HOME再启动,jdk下载地址
https://www.oracle.com/java/technologies/downloads/#java8
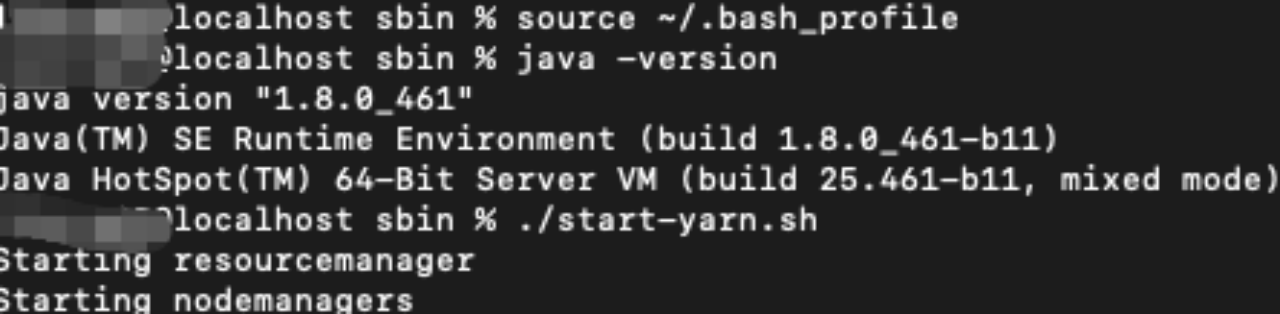
在浏览器输入 http://localhost:8088/ 出现下图页面成功
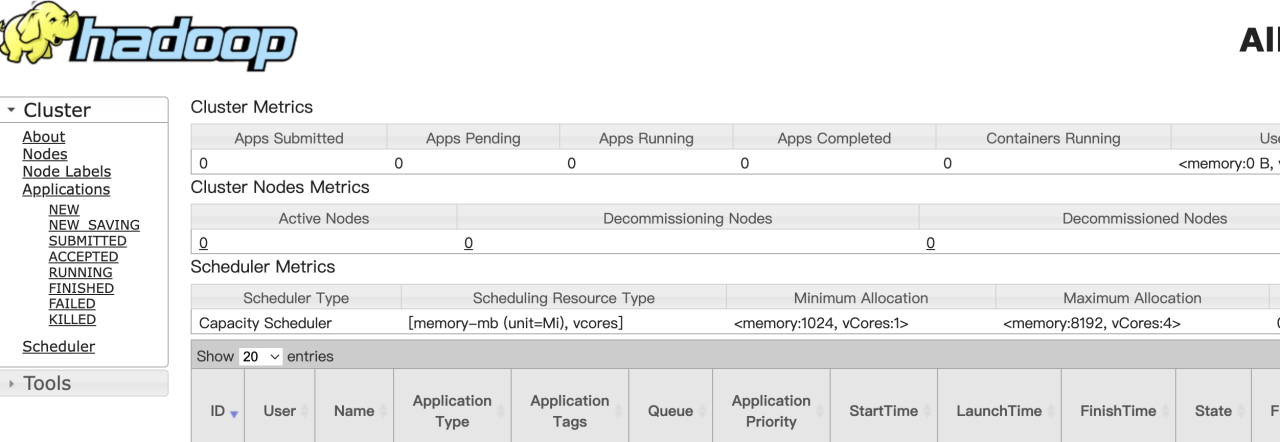
执行 ./stop-yarn.sh 关闭服务
参考:https://blog.csdn.net/zx1245773445/article/details/84875774