Apache Spark:统一化大规模数据分析引擎的技术内核解析
1. 整体介绍
1.1 项目概况
Apache Spark 是一个开源的、分布式、统一的计算框架,旨在处理大规模数据集。其项目源码托管于 GitHub。作为Apache软件基金会的顶级项目,Spark拥有庞大的社区和广泛的企业应用,是当今大数据生态系统的核心组件之一。其设计哲学在于通过内存计算、统一的编程模型和丰富的上层库,为批处理、流处理、交互式查询和机器学习提供一个高性能的集成平台。
1.2 核心功能与解决的核心问题
面临的问题:
在大数据时代早期,数据处理任务通常依赖多个独立的系统,例如:
- 批处理:使用 Apache Hadoop MapReduce。
- 交互式查询:使用 Apache Hive 或 Impala。
- 流处理:使用 Apache Storm。
- 机器学习 :使用 Mahout 等。
这种"多系统架构"导致了一系列问题:
- 数据孤岛与冗余:在不同系统间移动和复制数据带来巨大的I/O开销和一致性挑战。
- 开发与运维复杂:开发者需要学习多种编程模型和API,运维团队需维护多个独立集群。
- 延迟高:MapReduce等基于磁盘的模型在迭代计算(如机器学习)中效率低下。
Spark的解决方案:
Spark提出了一种统一的解决思路,核心是基于内存的弹性分布式数据集(RDD)模型及其上的高级抽象。
- 以前的解决方式:以Hadoop MapReduce为代表的两阶段(Map-Shuffle-Reduce)磁盘计算模型,中间结果持久化到HDFS。
- 新方式的优点 :
- 内存优先计算:RDD允许将中间结果缓存于内存中,对于迭代算法和交互式查询,性能可提升数个数量级。
- 统一的编程模型:所有高级API(SQL、Streaming、MLlib)最终都编译成基于RDD的DAG执行计划,实现了底层引擎的统一。
- 丰富的算子与流式增量模型:提供比MapReduce更丰富的转换(Transformation)和行动(Action)算子。Structured Streaming引入的"微批"和"连续处理"模型,使得流处理能够复用批处理的执行引擎和代码。
- 容错高效:RDD通过血统(Lineage)信息实现容错,而非数据复制,在故障恢复时只需重新计算丢失的分区,开销更小。
商业价值预估逻辑:
商业价值可从"降低成本"和"创造效益"两方面估算。
- 成本侧:统一技术栈减少了在多个独立系统(如Hadoop, Storm, 单独ML系统)上的许可、开发、运维和集群资源成本。开发效率的提升直接缩短了数据分析产品的上市时间。
- 效益侧 :更快的处理速度使得实时决策(如欺诈检测、个性化推荐)成为可能,直接创造商业机会。其覆盖的问题空间(批、流、交互查询、ML、图计算)几乎涵盖所有大规模数据分析场景,效益乘数显著。一个粗略的估算模型可以是:
商业价值 ≈ (替代系统的总拥有成本节约) + (处理速度提升带来的新业务收入增量)。Spark已成为许多数据驱动型企业的标准基础设施,其价值已得到市场广泛验证。
2. 详细功能拆解
从产品与技术结合的视角看,Spark的核心功能设计分为三层:
| 层级 | 产品/模块 | 技术核心设计 |
|---|---|---|
| 统一引擎层 | Spark Core | 弹性分布式数据集(RDD) :不可变、分区的数据集合抽象,是内存计算和容错的基石。 有向无环图(DAG)调度器 :将用户作业转换为DAG,并进行阶段(Stage)划分与优化。 任务调度器 :将Stage中的任务(Task)分发到集群Executor上执行。 内存管理器:统一管理执行内存和存储内存,支持堆内、堆外(Off-Heap)内存。 |
| 结构化API层 | Spark SQL | Catalyst 优化器 :基于规则的、可扩展的查询优化器,执行逻辑计划优化(如谓词下推、常量折叠、列剪枝)。 Tungsten 执行引擎 :使用堆外内存和缓存敏感计算,优化CPU和内存效率。 DataFrame/Dataset API:类型安全的、面向对象的结构化数据API,编译时检查优于RDD。 |
| 领域专用库层 | Structured Streaming | 增量处理模型 :将无限数据流视为一张不断追加的表,在微批次或连续模式下进行查询。 事件时间与水印:处理乱序事件,基于事件时间进行窗口聚合。 |
| MLlib | Pipeline API :将特征提取、转换、模型训练封装成可组合的工作流。 分布式算法:基于RDD或DataFrame实现的可扩展机器学习算法。 | |
| GraphX | 属性图抽象 :顶点和边均可携带属性的图模型。 Pregel API:基于顶点为中心的批量同步并行计算模型。 |
3. 技术难点挖掘
- 高效的内存与CPU利用:在JVM环境下管理大规模内存、避免Full GC、优化序列化/反序列化(SerDe)开销是持续挑战。Tungsten项目致力于解决此问题。
- DAG的智能划分与调度:如何将复杂的RDD依赖链最优地划分为Stage,最小化Shuffle数据量,是调度器的核心难点。
- Shuffle的稳定性与性能:Shuffle是分布式计算中最昂贵和易出错的环节。Spark的Shuffle实现(Sort、Tungsten-Sort等)需要在磁盘I/O、内存使用、网络传输间取得平衡。
- 统一批流语义:如何让流处理拥有与批处理完全一致的API和语义(如事件时间、窗口、状态管理),同时保证低延迟和高吞吐,是Structured Streaming的设计难点。
- 多语言API与执行桥接:如何高效地将Python(PySpark)、R中的用户代码与JVM核心引擎通信,特别是处理UDF(用户定义函数)的性能问题。
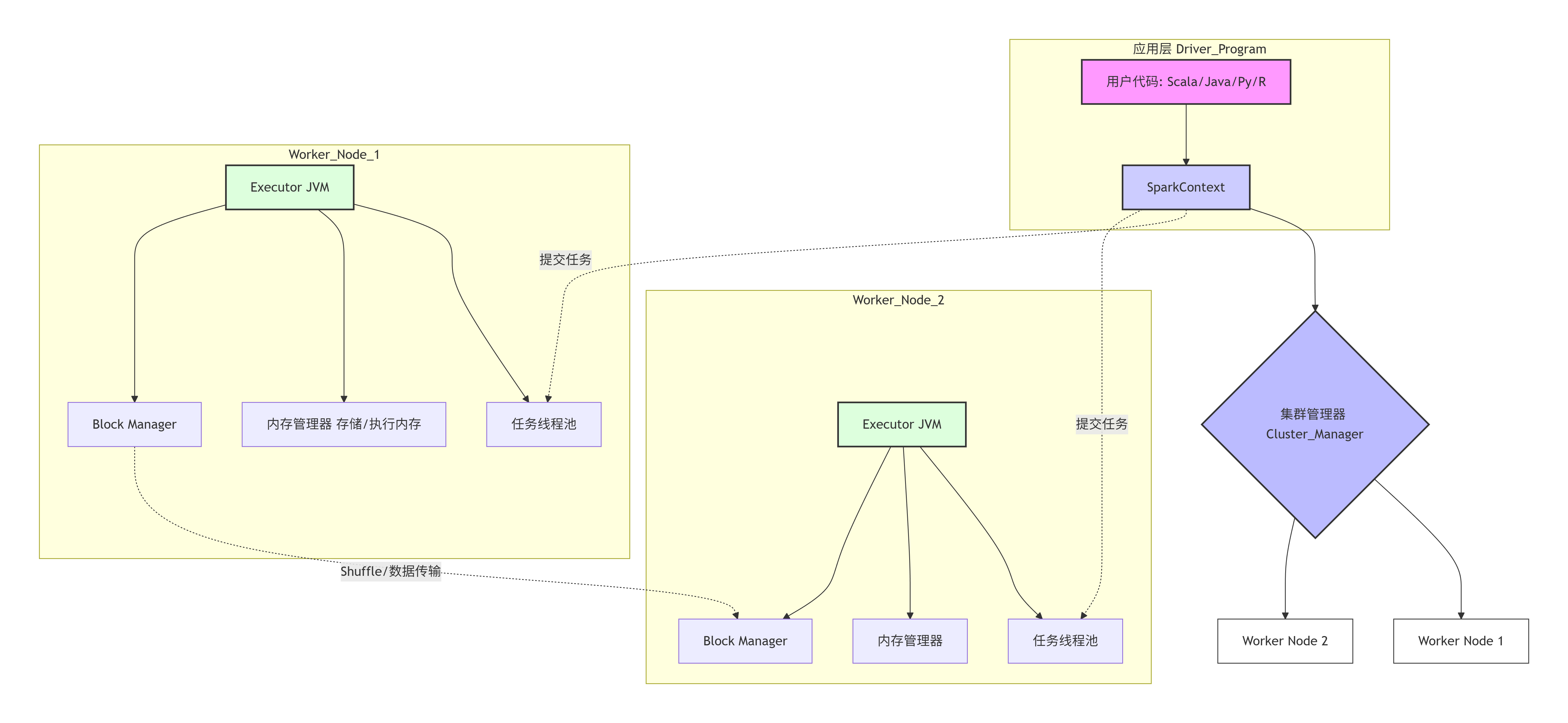
4. 详细设计图
4.1 核心架构图
4.2 Spark SQL 查询执行核心链路序列图
RDD Planner Catalyst SparkSession User RDD Planner Catalyst SparkSession User 应用优化规则 (谓词下推、常量折叠等) `spark.sql("SELECT ...")` 解析SQL,生成**逻辑计划** 优化逻辑计划 将逻辑计划转换为**物理计划** 选择最佳策略(如join算法选择) 生成最终可执行的**RDD转换链** 触发Action,执行DAG调度与任务计算 返回结果集(DataFrame)
4.3 RDD核心抽象类图(简化)
has
has many
RDD<T>
-sc: SparkContext
-dependencies: SeqDependency\[_]
-partitions: ArrayPartition
-compute(split: Partition, ...) : : Iterator<T>
-getPartitions() : : ArrayPartition
+mapU(f: T => U) : : RDD<U>
+filter(f: T => Boolean) : : RDD<T>
+reduce(f:(T, T) => T) : : T
+collect() : : ArrayT
<<abstract>>
Dependency
+rdd: RDD_
NarrowDependency
+getParents(pid: Int) : : SeqInt
ShuffleDependency
-shuffleId: Int
-partitioner: Partitioner
<<abstract>>
Partition
+index: Int
ParallelCollectionRDD
HadoopRDD
ShuffledRDD
MapPartitionsRDD
5. 核心函数解析
5.1 RDD的compute方法与血统(Lineage)
RDD的核心在于其惰性计算和基于血统的容错。每个RDD都包含如何从其他RDD(或其数据源)计算而来的逻辑。
核心原理 :当对一个RDD调用行动操作(如collect())时,调度器会根据RDD的血统(依赖关系图)构建一个DAG。每个RDD的compute方法定义了如何计算其分区数据。
scala
// 伪代码:展示MapPartitionsRDD的compute方法原理
class MapPartitionsRDD[U: ClassTag, T: ClassTag](
prev: RDD[T], // 前一个RDD(依赖)
f: (Iterator[T]) => Iterator[U] // 用户定义的转换函数
) extends RDD[U](prev) {
override def compute(split: Partition, context: TaskContext): Iterator[U] = {
// 1. 获取父RDD对应分区的数据迭代器
val parentIterator = firstParent[T].iterator(split, context)
// 2. 将用户函数 `f` 应用到父迭代器上,生成新的迭代器
f(parentIterator)
}
override protected def getPartitions: Array[Partition] = firstParent[T].partitions
}注释:
firstParent[T].iterator(split, context):这是关键。它递归地调用父RDD的compute方法,最终追溯到数据源(如HDFS文件块),从而"拉取"数据。f(parentIterator):应用用户转换逻辑(如map、filter)。这个过程是**管道化(pipelined)**的,数据通过迭代器链流动,避免了物化中间结果。- 整个
compute链定义了RDD的血统。如果某个分区丢失,调度器只需根据这个血统重新计算该分区及其上游依赖,无需备份整个数据集。
5.2 DataFrame的Catalyst优化器规则示例
Spark SQL的性能很大程度上得益于Catalyst优化器。它是一组可扩展的规则,作用于查询计划树。
scala
// 伪代码:一个简化的Catalyst优化规则示例(谓词下推)
object PushDownPredicate extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
// 匹配模式:Filter操作符在DataSource(如Scan)之上
case filter @ Filter(condition, child @ DataSourceScan(...)) =>
// 尝试将Filter条件"下推"到数据源中
if (canPushDown(condition, child)) {
// 创建新的数据源扫描节点,将过滤条件下推给它
val newScan = child.copy(pushedFilters = child.pushedFilters :+ condition)
// 如果过滤条件全部下推,则可以移除上层的Filter节点
if (allFiltersPushed(condition)) {
newScan
} else {
// 否则,保留部分未下推的条件在上层Filter
Filter(remainingCondition(condition), newScan)
}
} else {
filter // 无法下推,保持原样
}
}
}注释:
plan transform {...}:Catalyst使用模式匹配遍历和转换逻辑计划树。canPushDown:检查数据源(如Parquet、JDBC)是否支持直接应用该过滤条件。例如,Parquet支持按列过滤,可以跳过不相关的数据块,大幅减少I/O。- 这种优化对用户透明,用户写的
df.filter($"age" > 18).select($"name")会被自动优化,在读取数据时尽早过滤。
5.3 Structured Streaming的增量查询模型
Structured Streaming的核心是将流计算视为对一张不断增长的表的连续查询。
scala
// 伪代码:展示微批次执行的概念模型
val inputStream: DataFrame = spark.readStream.format("kafka")... // 输入流
// 用户定义一个流式聚合查询
val wordCounts = inputStream
.groupBy($"value") // 按单词分组
.count() // 计数
// 内部执行逻辑(伪代码表示):
// 对于每个触发间隔(如1秒)的微批次:
// 1. 增量计划(Incremental Planning)
val newDataBatch = getNewDataFromSource() // 获取新到达的数据
val currentState = getPersistedAggregationState() // 从状态存储中获取当前聚合状态
// 2. 增量执行
val (updatedCounts, outputRows) = executeIncrementalAggregation(
newDataBatch,
currentState
)
// 3. 更新状态并输出
persistState(updatedCounts) // 将新的聚合状态写回状态存储
writeOutput(outputRows) // 将本批次的结果输出到Sink(如控制台、Kafka)
// 这等价于在每个微批次上运行一次批处理查询,但状态是持续累积的。注释:
- 状态管理 :聚合(如
count、reduceByKey)需要中间状态。Spark将其可靠地存储到检查点目录(如HDFS)。 - 端到端容错:结合偏移量跟踪(如Kafka offset)和状态检查点,确保每条输入记录被精确处理一次(Exactly-Once)。
- 与批处理统一 :执行引擎与Spark SQL共享,因此
groupBy().count()在流和批中的代码、优化逻辑完全一致。
总结:Apache Spark通过创新的RDD内存计算模型、统一的DAG调度引擎以及Catalyst、Tungsten等底层优化技术,成功构建了一个高效、通用、易用的大规模数据处理平台。其对批流一体、API统一的追求,深刻影响了后续大数据系统(如Flink)的设计方向。深入理解其核心抽象(RDD/DataFrame)、调度原理(DAG Scheduler)和优化技术(Catalyst),是高效运用和扩展Spark的基础。