| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之SpringAI |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
本文章目录
- 零基础学AI大模型之AI大模型常见概念
-
- 一、先搞懂:什么是AI大模型?
- 二、AI大模型的6个核心概念
-
- [1. 提示词(Prompts)](#1. 提示词(Prompts))
- [2. 令牌(Tokens):大模型的"语言最小单位"](#2. 令牌(Tokens):大模型的“语言最小单位”)
- [3. 嵌入(Embeddings)](#3. 嵌入(Embeddings))
- [4. 结构化输出(Structured Output)](#4. 结构化输出(Structured Output))
- [5. 检索增强生成(RAG)](#5. 检索增强生成(RAG))
- [6. 工具调用(Tool Calling/Function Call)](#6. 工具调用(Tool Calling/Function Call))
- [6. AI大模型概念总结](#6. AI大模型概念总结)
零基础学AI大模型之AI大模型常见概念
一、先搞懂:什么是AI大模型?
AI大模型(AI Models)本质是具备大规模参数、能模拟人类认知功能的信息处理算法------它不仅能"读懂"输入(比如文本、语音、图像),还能"生成"符合需求的输出(比如对话、图片、代码),核心优势是"泛化能力强":不用针对单个场景单独训练,就能应对多种任务(比如既会写邮件,也能做数据分析)。
而SpringAI作为开发者常用的框架,直接为大模型提供了"落地工具",支持多种核心模型类型,覆盖大部分业务场景:
- 聊天模型:核心是"对话与文本生成",比如客服机器人回复咨询、自动生成周报,甚至帮开发者写接口文档;
- 嵌入模型:负责"文本向量化",把文字变成计算机能理解的"数字向量",是后续语义搜索、相似内容匹配的基础;
- 图像生成模型:实现"文本→图像"转换,比如输入"蓝色天空下的白色风车",就能生成对应的图片;
- 语音模型:处理"语音↔文本"双向转换,比如会议录音转文字、文字稿合成播报语音。
二、AI大模型的6个核心概念
如果把AI大模型比作"智能大脑",下面这些概念就是它的"神经中枢"------决定了它"怎么思考""怎么干活""怎么不犯错"。
1. 提示词(Prompts)
提示词不是简单的"一句话提问",而是引导模型输出符合预期的"语言输入基础"。在SpringAI里,它被拆成了3个关键部分,分工明确:
- 系统消息:定"规则",比如"你是一名技术文档助手,回答需简洁,只讲Java相关内容";
- 用户消息:提"需求",比如"帮我解释SpringAI的嵌入模型用法";
- 助手消息:存"历史",记录模型之前的响应,确保对话连贯(比如多轮咨询时,模型不会忘记上一轮的问题)。
开发者还能用StringTemplate等模板引擎优化提示词,比如做一个"生成笑话"的模板:"讲一个{type}类型的笑话,主角是{role}",后续只需填充"冷笑话""程序员"这样的占位符,就能快速适配不同用户输入。
2. 令牌(Tokens):大模型的"语言最小单位"
你可能听过"ChatGPT3只能处理4K内容",这里的"4K"指的就是令牌(Tokens)------大模型处理语言的基本单位,相当于人类说话的"词语片段"。
- 换算规则:英文里1个Token约等于0.75个单词(比如《莎士比亚全集》90万字,约合120万Token);中文里1个Token约对应1-2个汉字;
- 核心影响:直接关联"成本"和"能力上限":
- 费用:AI服务按"输入+输出"的Token总数收费,比如输入1000Token、输出500Token,就按1500Token计费;
- 限制:每个模型有"上下文窗口"(Token上限),比如GPT3是4K、GPT4有8K/16K/32K版本,超过上限的内容会被"截断",模型无法处理。
DeepSeek示例
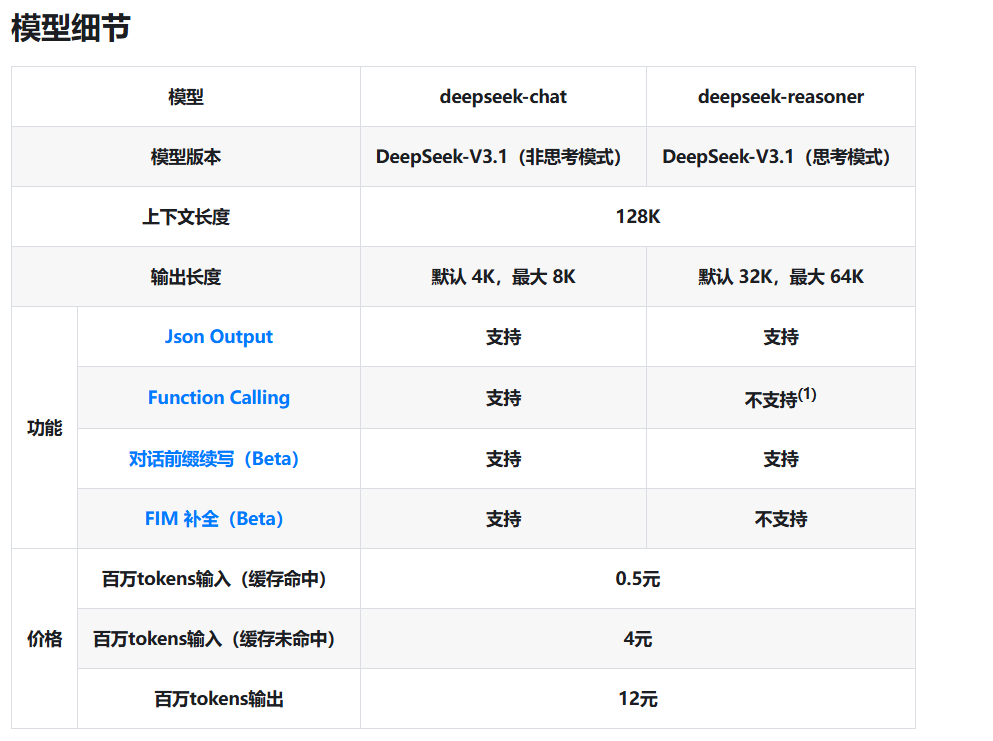
3. 嵌入(Embeddings)
嵌入是大模型"理解语义"的关键技术------把文本、图像等信息转换成浮点数组(向量),就像给每个内容分配一个"数字坐标":语义越相似的内容,坐标越近(比如"猫"和"狗"的向量距离,比"猫"和"汽车"近)。
- 核心用途:最常见于"语义搜索",比如在企业文档库里搜"请假流程",嵌入模型能找到"休假申请步骤""事假审批规则"等相似内容;
- 与RAG的关联:后续要讲的RAG技术,核心就是靠嵌入模型把文档转成向量,再存到向量数据库里,方便后续检索。
4. 结构化输出(Structured Output)
传统AI输出是字符串(比如即使返回JSON,也得手动转成Java对象),而结构化输出能让模型直接生成开发者需要的数据格式 ,省去解析步骤。
比如在SpringAI里,想获取5个"Order"对象,只需这样写:
java
List<Order> Order = chatClient.prompt()
.user("CCC给我5个订单信息")
.call()
.entity(new ParameterizedTypeReference<List<Order>>() {});5. 检索增强生成(RAG)
大模型有个短板:训练数据有"截止日期"(比如2023年的模型不知道2024年的新政策),而RAG(Retrieval Augmented Generation)就是通过"实时检索外部数据",让模型输出更精准、更实时。
- 核心流程(类似ETL管道):
- 提取:把非结构化数据(比如PDF文档、Word手册)拿出来;
- 转换:拆分成"符合Token限制"的片段(关键是不拆段落、代码方法,保留语义),再用嵌入模型转成向量;
- 加载:把向量存到向量数据库里;
- 应用场景:比如用户问"2024年个税起征点是多少",RAG会先从数据库里检索2024年的个税政策文档,再把"政策内容+用户问题"一起传给模型,让模型基于最新数据回答,避免"答非所问"。
6. 工具调用(Tool Calling/Function Call)
大模型本身不能查天气、查股票,但工具调用能让它"调用外部API",获取实时数据或执行操作,相当于给模型装了"外接大脑"。
- 简化流程(以SpringAI为例):
- 用@Tool注解定义工具(比如"天气查询工具",说明参数是"城市名""日期");
- 模型判断是否需要调用工具(比如用户问"北京明天天气",模型会决定调用天气API);
- 应用执行工具,返回"北京明天晴,气温15-25℃";
- 模型基于这个结果,生成自然语言回答。
- 价值:让模型从"只懂理论"变成"能做实事",比如自动查物流、生成实时报表。
6. AI大模型概念总结
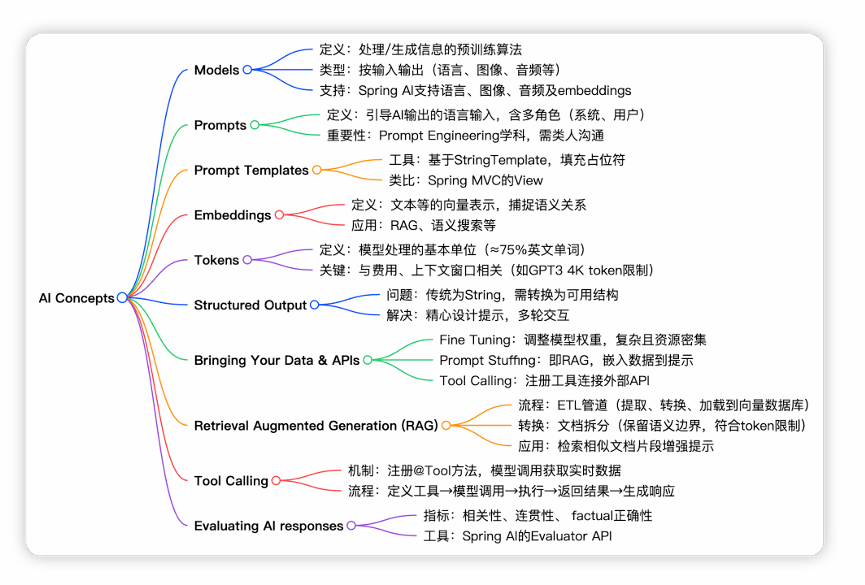
觉得有用请点赞收藏!
如果有相关问题,欢迎评论区留言讨论~