1. 基本信息

-
标题: RMT: Retentive Networks Meet Vision Transformers
2. 核心创新点
-
提出曼哈顿自注意力 (MaSA) :通过引入基于曼哈顿距离的空间衰减矩阵,为自注意力机制注入了显式的空间先验知识。
-
设计可分解的注意力形式:提出一种沿图像坐标轴分解MaSA的方法,在不破坏空间先验的前提下,将全局信息建模的计算复杂度降至线性级别。
-
构建高性能视觉骨干网络RMT:基于MaSA构建了一个通用的、强大的视觉骨干网络RMT,在图像分类、目标检测和分割等多个任务上取得了SOTA性能。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/eHTpQt-xasy8xsRaxGye0w
https://mp.weixin.qq.com/s/eHTpQt-xasy8xsRaxGye0w
3. 方法详解
整体结构概述
RMT是一个分层的视觉骨干网络,其整体架构如 图3 所示。输入图像首先通过一个卷积主干(Conv Stem)进行分词(Tokenization)和嵌入。随后,特征图依次通过四个阶段(Stage)的RMT模块进行处理,每个阶段之间通过步长为2的卷积层进行下采样。前三个计算量较大的阶段使用计算高效的分解式MaSA ,而最后一个阶段则使用完整的MaSA。每个RMT模块由一个MaSA层和一个前馈网络(FFN)组成,并辅以深度可分离卷积(DWConv)和层归一化(LN)。
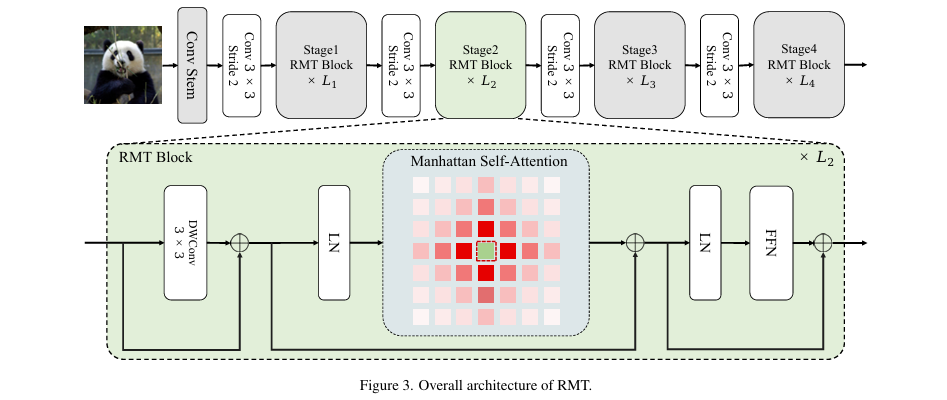
步骤分解
RMT的核心是曼哈顿自注意力(Manhattan Self-Attention, MaSA),它源于NLP领域的Retentive Network (RetNet),并经过了针对视觉任务的改造。
-
从单向到双向衰减:
-
RetNet最初为文本数据设计,采用单向因果模型,即一个词元(token)只关注其前面的词元。
-
为适应不具备因果关系的图像任务,论文首先将其扩展为双向形式,使得每个词元可以关注所有其他词元。其注意力矩阵形式如下,其中
|n-m|表示一维序列中两个词元的距离。
-
-
从一维到二维空间衰减:
-
为了处理二维图像数据,论文进一步将一维距离衰减扩展为二维。
-
使用词元在二维平面上的坐标
(x, y),通过曼哈顿距离来定义空间衰减矩阵D_2d。距离越远的词元,其注意力得分衰减越大,从而引入了显式的空间位置先验。
- 与RetNet不同,RMT保留了Softmax函数来引入非线性,最终的MaSA形式如下:
-
-
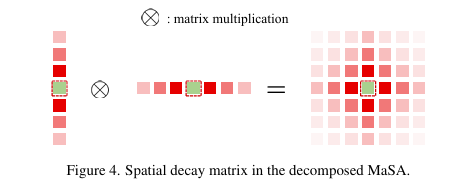
**分解式曼哈顿自注意力 (Decomposed MaSA)**:
-
为解决全局注意力带来的二次方计算复杂度问题,论文提出了一种注意力分解方法。
-
该方法将注意力计算分别沿图像的横向(W)和纵向(H)进行。首先计算横向注意力,然后将结果转置,再计算纵向注意力。衰减矩阵也相应地分解为一维形式
D_H和D_W。 -
这种分解方式在保持全局感受野(如 图4 所示)和空间先验的同时,将计算复杂度降低到线性级别。
-
- **局部上下文增强 (LCE)**:
- 为了进一步增强模型的局部特征表达能力,在MaSA模块后并行加入了一个由深度可分离卷积(DWConv)构成的局部上下文增强模块。
4. 即插即用模块作用
本报告的核心分析对象为论文提出的 曼哈顿自注意力 (MaSA) 模块。
适用场景
MaSA作为一个通用的自注意力变体,旨在替代标准自注意力或窗口自注意力,可广泛应用于各种基于Transformer的视觉骨干网络中。论文验证了其在以下任务中的有效性:
-
图像分类: 如ImageNet-1K上的图像识别。
-
目标检测: 如在COCO数据集上的目标框检测。
-
实例分割: 如在COCO数据集上的像素级实例掩码分割。
-
语义分割: 如在ADE20K数据集上的场景解析。
主要作用
MaSA模块为视觉Transformer模型带来了以下核心价值:
-
引入显式空间先验: 通过基于曼哈顿距离的衰减机制,模拟了"距离越近,关系越紧密"的视觉先验,弥补了标准自注意力缺乏空间归纳偏置的短板。
-
大幅降低计算复杂度 : 其分解形式将全局注意力的计算复杂度从
O(N^2)降低到O(N),在处理高分辨率图像或密集预测任务时,显著节省了计算资源和内存。 -
保持全局感受野: 与Swin Transformer等基于窗口的方法不同,分解式MaSA依然能够高效地建模全局依赖关系,避免了窗口划分带来的信息交互限制。
-
提升模型性能与效率: 实验结果表明,与现有SOTA模型相比,RMT在相似的计算量下取得了更优的性能,实现了速度与精度的平衡。
总结
曼哈顿自注意力 (MaSA) 是一种高效的自注意力机制,它通过引入与距离相关的空间衰减先验,并结合创新的轴向分解方法,在实现线性计算复杂度的同时保留了全局感受野,是提升视觉Transformer性能与效率的强大模块。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/eHTpQt-xasy8xsRaxGye0w
https://mp.weixin.qq.com/s/eHTpQt-xasy8xsRaxGye0w