Gemini 2.5 系列模型作为 Google DeepMind 推出的新一代 AI 模型家族,凭借在推理、多模态、长上下文处理及智能体能力上的突破性进展,重新定义了大语言模型的性能基准与应用边界。
原文链接:https://arxiv.org/pdf/2507.06261
沐小含将持续分享前沿算法论文,欢迎关注...
一、模型家族全景:覆盖能力与成本的全帕累托前沿
Gemini 2.5 系列构建了完整的模型矩阵,包含 Gemini 2.5 Pro、Gemini 2.5 Flash、Gemini 2.0 Flash 和 Gemini 2.0 Flash-Lite 四个核心模型,全面覆盖从高性能到轻量化的各类需求,实现了能力与成本的最优平衡。
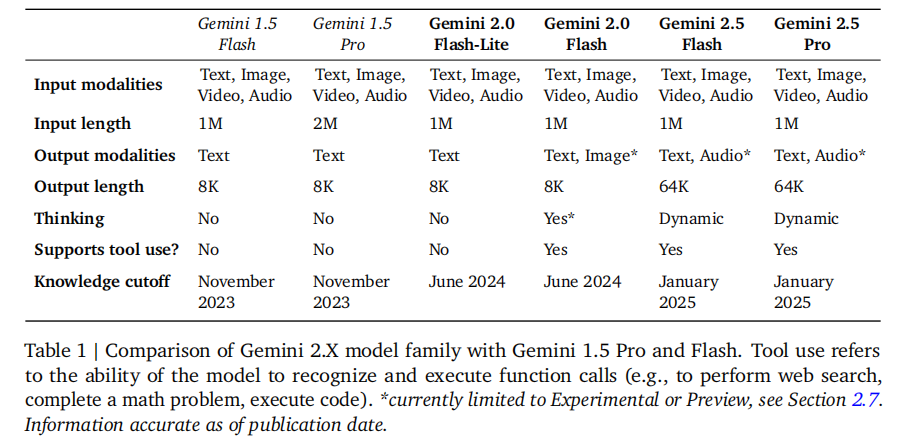
1.1 模型核心特性对比
各模型在输入输出模态、上下文长度、推理能力等关键维度差异显著,具体参数如下表所示:
1.2 模型定位与核心优势
- Gemini 2.5 Pro:系列中最强大的 "思考型" 模型,具备卓越的推理和编码能力,擅长开发交互式 Web 应用、理解整个代码库,同时拥有新兴的多模态编码能力,可处理长达 3 小时的视频内容。
- Gemini 2.5 Flash:混合推理模型,支持可控的思考预算,在保证复杂任务处理能力的同时,平衡质量、成本和延迟之间的关系。
- Gemini 2.0 Flash:面向日常任务的高效非思考型模型,兼顾速度与成本效益。
- Gemini 2.0 Flash-Lite:极致轻量化模型,专为大规模部署设计,提供最快响应速度和最低使用成本。
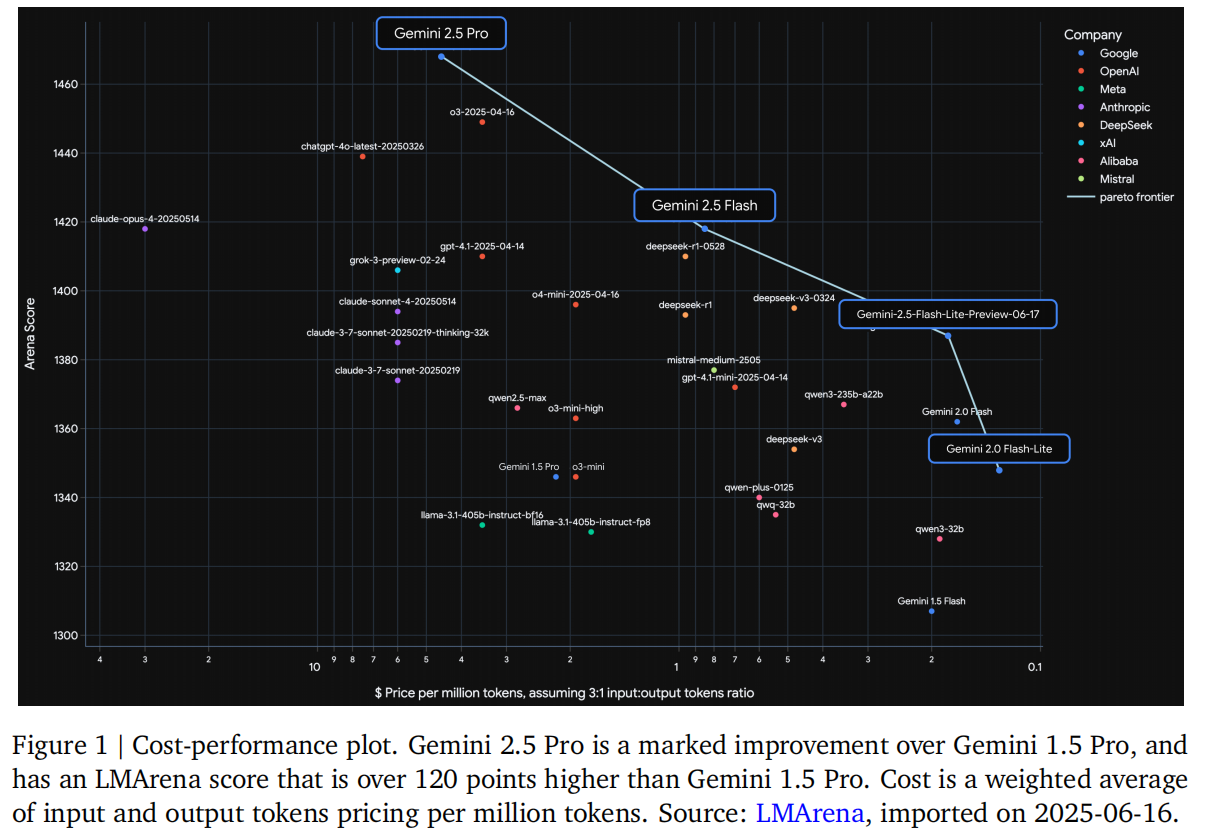
如图 1 所示,Gemini 2.X 系列模型全面覆盖了能力与成本的帕累托前沿,在各类核心能力、应用场景中实现了性能突破。
在响应速度方面,Gemini 2.5 系列展现出优异表现。如图 2 所示,Gemini 2.5 Flash 和 Gemini 2.0 Flash-Lite 在输出 tokens 速率上领先,满足实时交互场景需求。

二、核心技术创新:架构、训练与能力突破
Gemini 2.5 系列的性能飞跃源于架构设计、训练方法和能力优化等多维度的技术创新,构建了更高效、更稳定、更强大的 AI 基础。
2.1 稀疏混合专家架构(Sparse MoE)
Gemini 2.5 模型基于稀疏混合专家(MoE)Transformer 架构,原生支持文本、视觉和音频多模态输入。其核心创新在于:
- 动态路由机制:每个输入 token 仅激活部分模型参数(专家),实现模型容量与计算成本的解耦。
- 训练稳定性提升:通过优化信号传播和优化动态,解决了大型 Transformer 和稀疏 MoE 模型常见的训练不稳定性问题,预训练阶段即实现性能大幅提升。
- 视觉处理优化:改进的视觉处理架构显著提升图像和视频理解能力,支持 3 小时视频处理和视频到交互式编码应用的转换。
2.2 数据集与训练基础设施
- 多样化预训练数据:涵盖网页文档、多语言代码、图像、音频和视频等多模态数据,2.0 版本知识截止到 2024 年 6 月,2.5 版本更新至 2025 年 1 月,同时采用先进的数据过滤和去重方法提升数据质量。
- TPUv5p 训练集群:首次基于 TPUv5p 架构训练,采用同步数据并行策略,跨多个数据中心的 8960 芯片集群部署。
- 弹性训练与 SDC 防护:切片粒度弹性机制可在局部故障时自动调整 TPU 切片数量,中断恢复时间从 10 分钟以上缩短至数十秒;分阶段 SDC 检测通过轻量级确定性重放快速定位数据损坏,将故障检测时间从数小时缩短至几分钟。
2.3 突破性训练技术
- 蒸馏优化:小型模型(Flash 及以下)采用知识蒸馏技术,通过 k 稀疏分布近似教师模型的下一个 token 预测分布,在提升模型质量的同时降低部署成本。
- 强化学习增强:增加强化学习计算资源投入,采用可验证奖励和基于模型的生成式奖励,优化长训练过程中的稳定性,支持多步骤动作和工具使用场景的学习。
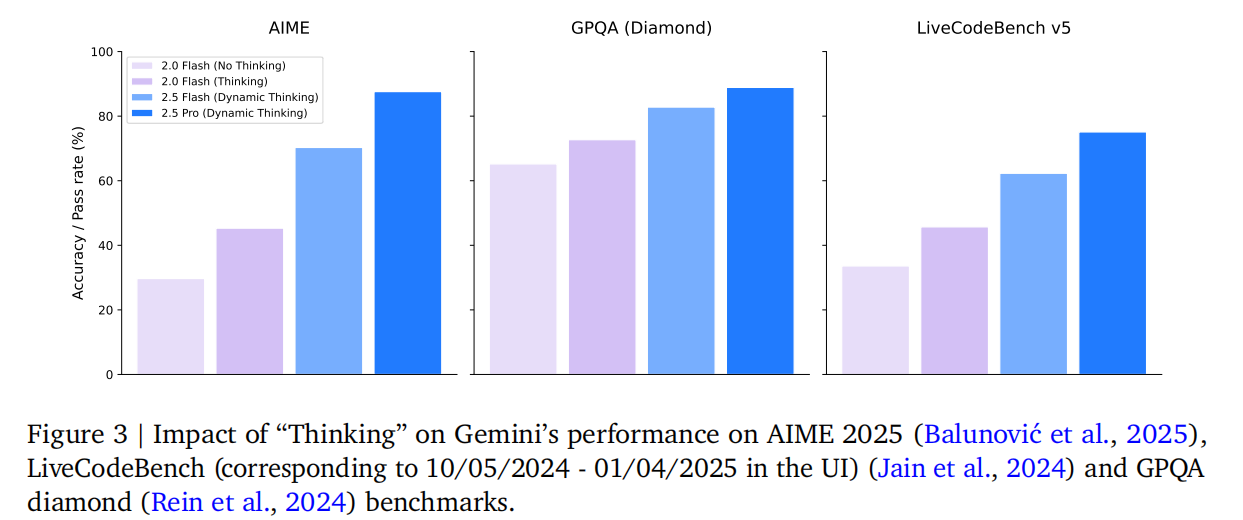
- 思考机制(Thinking):通过强化学习训练模型在推理时分配额外计算资源,在响应前进行数千次前向传播思考,可通过设置思考预算平衡性能与成本。如图 3 所示,思考机制显著提升了模型在数学、编码和推理基准测试中的表现。
思考预算的调整可灵活控制模型性能,如图 4 所示,随着思考预算(token 数量)增加,模型在各类基准测试中的准确率显著提升。
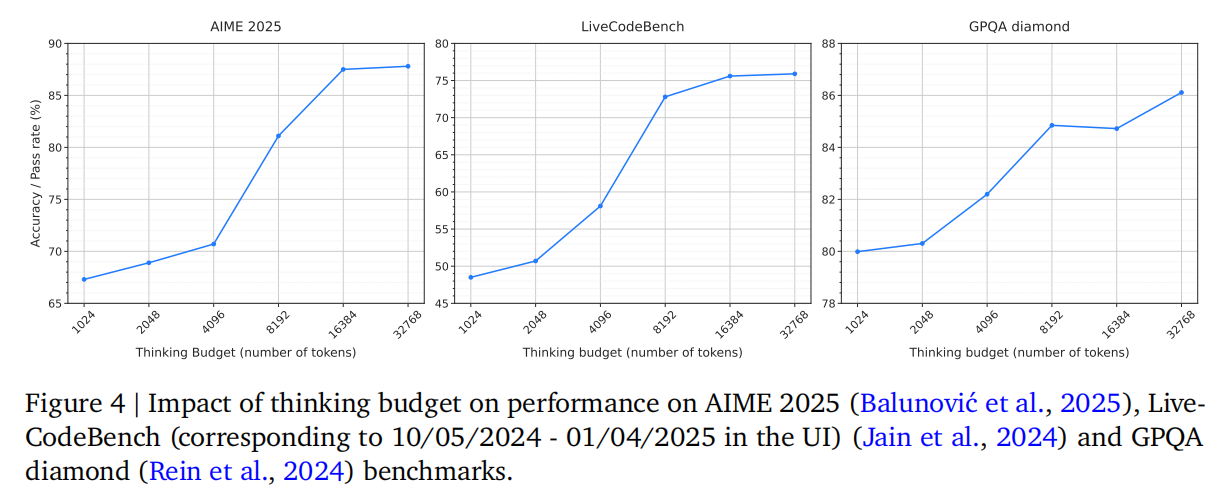
2.4 专项能力优化
Gemini 2.5 在编码、事实性、长上下文等关键能力上实现专项突破:
- 编码能力:通过扩充代码训练数据和优化训练技术,Gemini 2.5 Pro 在 LiveCodeBench 的通过率从 Gemini 1.5 Pro 的 30.5% 提升至 74.2%,Aider Polyglot 从 16.9% 提升至 82.2%。
- 事实性保障:原生集成 Google 搜索等工具,结合高级推理能力,实现多跳查询处理和事实验证,在 SimpleQA、FACTS Grounding 等事实性基准测试中表现领先。
- 长上下文处理:优化 100 万 token 上下文窗口的响应质量,在 LOFT、MRCR-V2 等长上下文任务中实现 SOTA 性能,可精准召回 46 分钟视频中 1 秒的关键场景。
- 多语言支持:覆盖 400 多种语言,通过数据质量优化和模型创新,在印度语、中日韩等语言上实现质量和解码速度的双重提升。
- 音视频能力:支持文本到语音、音视频到音频对话等生成任务,采用因果音频表示实现低延迟流式对话,视频处理效率提升至 3 小时 / 1M tokens。
三、性能评估:全方位基准测试领先
Gemini 2.5 系列在编码、数学、推理、多模态等多个领域的基准测试中表现卓越,全面超越前代模型并领先业界同类产品。
3.1 核心能力评估结果
如表 3 所示,Gemini 2.5 模型在各项核心能力基准测试中实现显著提升:
- 数学推理:Gemini 2.5 Pro 在 AIME 2025 的准确率从 Gemini 1.5 Pro 的 17.5% 提升至 88.0%,HiddenMath-Hard 从 44.3% 提升至 80.5%。
- 长上下文检索:LOFT(1M 上下文)任务中,Gemini 2.5 Pro 准确率达 69.8%,远超 Gemini 1.5 Pro 的 47.1%。
- 多模态理解:MMMU 基准测试中,Gemini 2.5 Pro 准确率达 82.0%,较 Gemini 1.5 Pro 提升 14.3 个百分点。
- 多语言能力:Global MMLU(Lite)中,Gemini 2.5 Pro 准确率达 89.2%,ECLeKTic 达 46.8%,展现强大的跨语言处理能力。
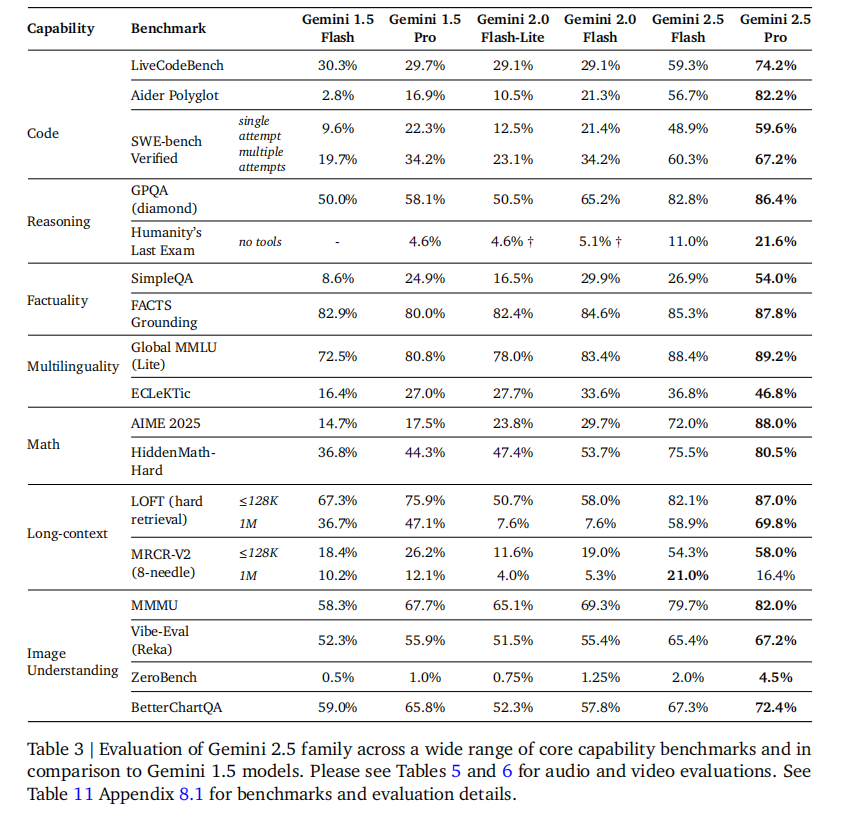
3.2 与主流大模型对比
如表 4 所示,Gemini 2.5 Pro 在多个关键基准测试中超越业界同类模型:
- 编码任务:Aider Polyglot 通过率达 82.2%,领先其他模型。
- 事实性任务:SimpleQA 准确率 54.0%,FACTS Grounding 达 87.8%,均位列第一。
- 长上下文处理:唯一支持 100 万 token 上下文的模型,在 LOFT(128K)任务中准确率达 87.0%,实现 SOTA。
- 综合推理:Humanity's Last Exam(无工具)准确率 21.6%,GPQA(钻石级)达 86.4%,表现突出。
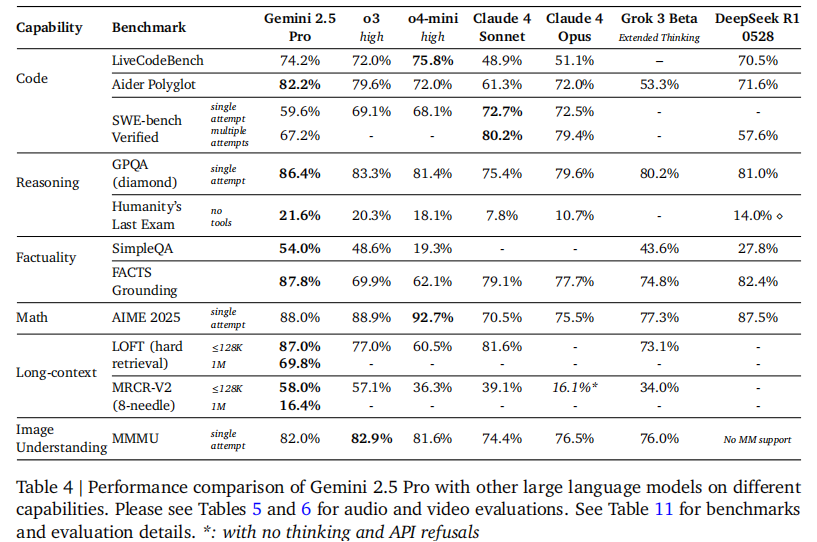
3.3 音视频理解专项评估
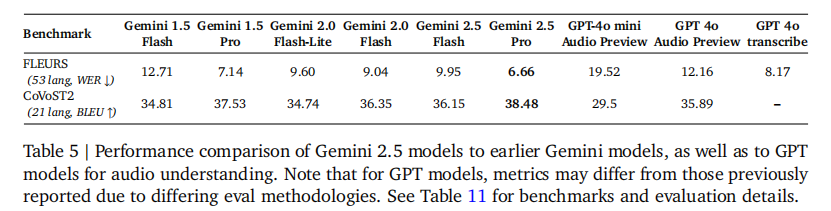
在音频理解方面,Gemini 2.5 Pro 在 FLEURS(语音识别)任务中 WER 低至 6.66,CoVoST2(语音翻译)BLEU 值达 38.48,优于 GPT 系列模型。如表 5 所示:
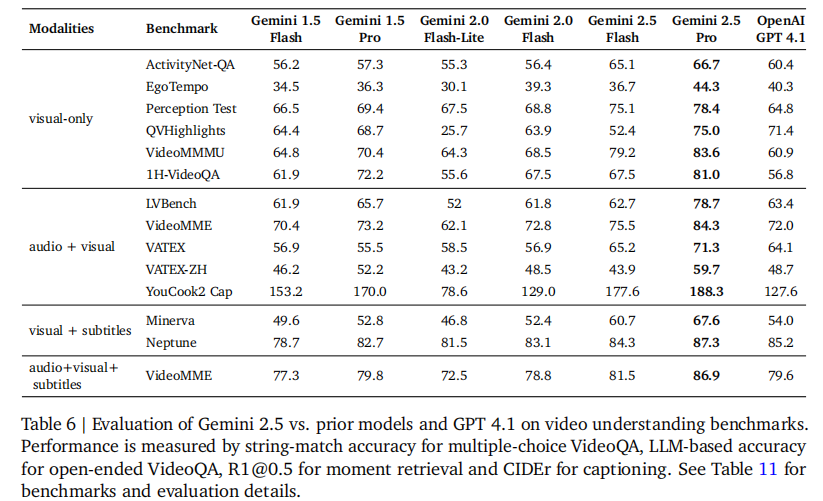
视频理解领域,Gemini 2.5 Pro 在 ActivityNet-QA、VideoMMMU、1H-VideoQA 等多个基准测试中实现 SOTA,超越 GPT 4.1。例如在 VideoMME 任务中,Gemini 2.5 Pro 准确率达 84.3%,较 GPT 4.1 高出 12.3 个百分点。如表 6 所示:
四、实际应用:从游戏智能体到产品落地
Gemini 2.5 的强大能力已在多个实际场景中得到验证,从复杂游戏挑战到 Google 产品集成,展现出广泛的应用价值。
4.1 Gemini Plays Pokémon:智能体能力验证
独立开发者 Joel Zhang 构建的 Gemini Plays Pokémon 智能体,基于 Gemini 2.5 Pro 实现了《精灵宝可梦蓝》的完整通关:
- 首轮通关耗时 813 小时,第二轮优化后仅需 406.5 小时,效率提升 50%。
- 展现出卓越的长上下文工具使用能力,可解决复杂迷宫、推石谜题等难题,推理上下文长度达 10 万 + tokens。
- 具备长期任务连贯性,能够平衡战术目标(如获取隐藏技能)与战略目标(通关成为冠军),成功应对游戏中的各类挑战。
如图 6 所示:
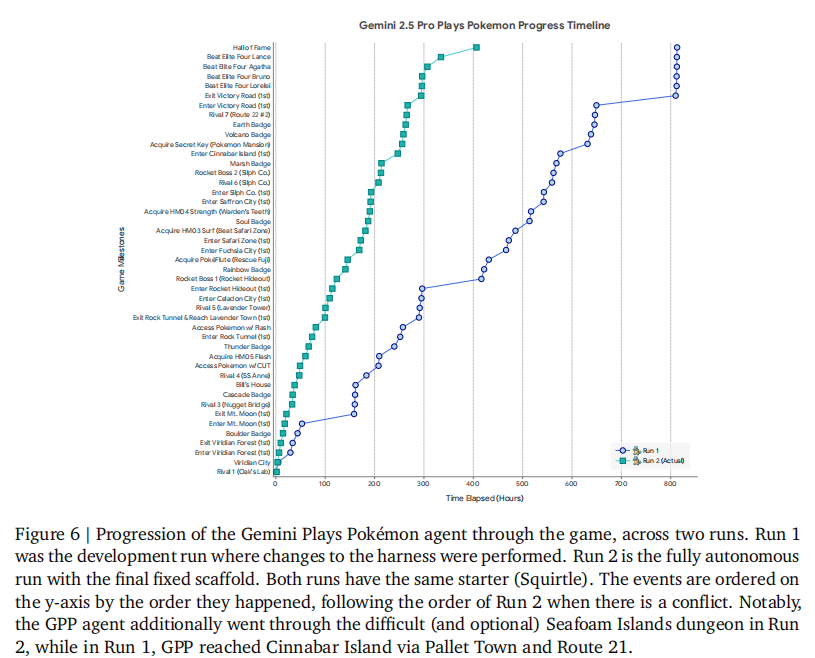
尽管表现出色,模型仍存在一些局限:屏幕像素直接识别能力较弱,需依赖 RAM 状态转换的文本信息;上下文超过 10 万 tokens 时可能出现动作重复,缺乏新颖规划。
4.2 多场景创新应用
Gemini 2.5 Pro 可将多样化非结构化输入转化为交互式应用:
- 教育领域:将戏剧 PDF 脚本生成台词练习工具,将讲座视频转化为知识测试应用。
- 创意领域:基于书架照片创建书籍推荐应用,将图像转换为 HTML/SVG 结构表示,生成傅里叶级数 Logo 等数学可视化内容。
- 专业工具:开发定制地图工具、从文本描述生成照片级 3D 用户界面,构建复杂的太阳系模拟模型。
4.3 Google 产品集成
Gemini 已深度集成到 Google 多款产品中,包括:
- 搜索领域:AI 概览和 AI 模式,为 15 亿月活用户提供服务。
- 研究工具:Gemini Deep Research、NotebookLM(支持播客生成和音频概述)。
- 开发工具:编码智能体 Jules、网页浏览智能体 Project Mariner。
- 交互系统:视听对话智能体 Project Astra、多模态创作工具。
五、安全与责任:全方位保障框架
Google DeepMind 构建了完善的安全与责任体系,确保 Gemini 2.5 在强大能力的同时,实现安全可控的部署。
5.1 安全流程与政策
- 严格的安全政策:禁止生成儿童性虐待、仇恨言论、危险内容等有害输出,覆盖所有模态。
- 全生命周期安全管理:从数据过滤、预训练监控,到监督微调、强化学习,全程融入安全机制。
- 独立评估机制:由独立团队进行保障评估,结合外部专家和政府机构测试,识别潜在风险盲点。
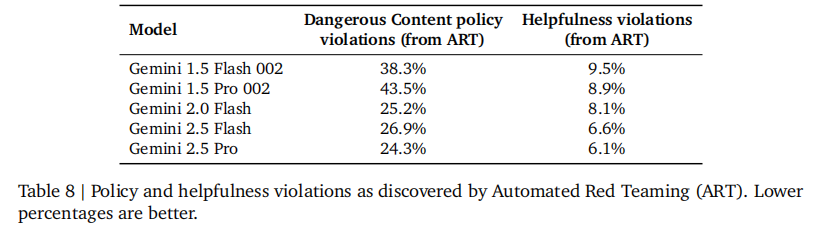
5.2 自动化红队与安全测试
- 自动化红队(ART):通过多智能体对抗方式,大规模测试模型安全漏洞,生成数千个测试案例 / 小时,显著提升风险覆盖度。
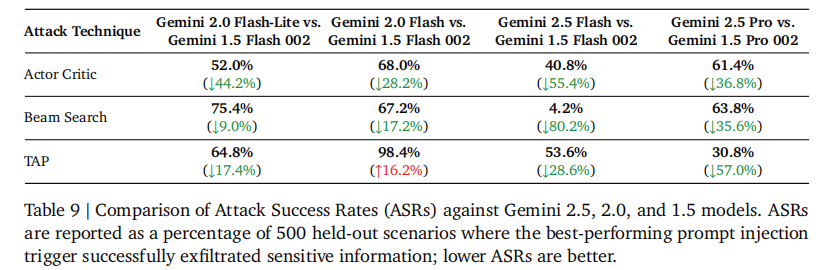
- prompt 注入防护:针对间接 prompt 注入攻击进行专项优化,Gemini 2.5 系列在 Actor Critic、Beam Search 等攻击测试中的成功率显著降低。
如表 8 所示:
如表 9 所示:
5.3 记忆与隐私保护
- 低记忆率设计:Gemini 2.X 系列长文本记忆率显著低于前代模型,且以近似记忆为主,精确记忆占比极低。
- 敏感信息防护:通过 Google Cloud SDP 服务检测,Gemini 2.X 模型输出中未发现包含个人信息的记忆内容,隐私风险可控。
- 发散攻击防护:在发散攻击测试中,Gemini 2.5 系列发散率降至 59%,且发散输出中的记忆内容仅为 0.2%,主要为模板代码或网页内容。
5.4 前沿安全框架评估
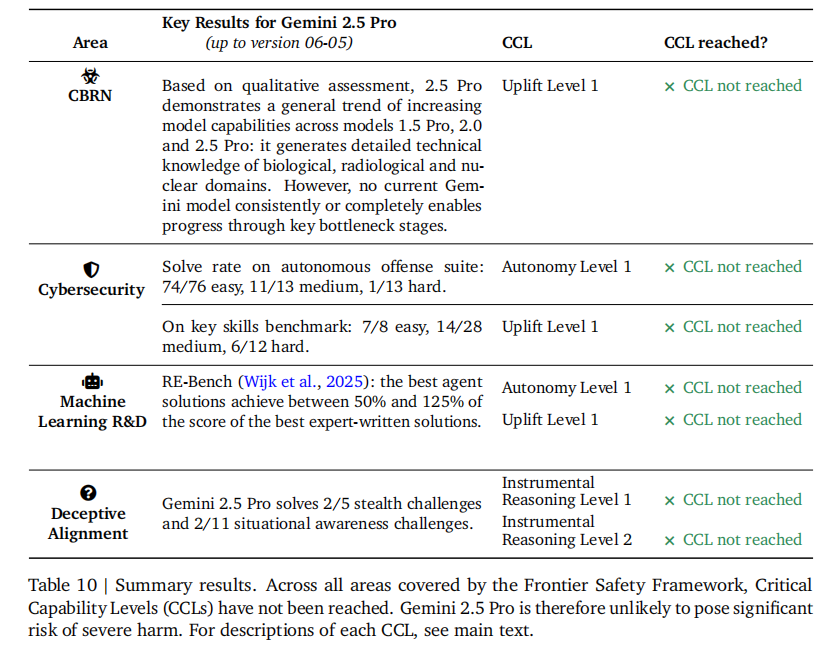
基于 Google DeepMind 的前沿安全框架(FSF),Gemini 2.5 Pro 在四大风险领域进行了严格评估。如表 10 所示:
- CBRN(化学、生物、放射、核信息风险):未达到关键能力等级(CCL),虽能生成专业技术知识,但无法持续突破关键技术瓶颈。
- 网络安全:自治攻击套件解决率提升,但未达 CCL;已触发网络提升 1 级 CCL 的预警阈值,将加强高频测试和缓解措施。
- 机器学习研发:RE-Bench 基准测试中,最佳智能体解决方案达到专家方案的 50%-125%,但未达 CCL。
- 欺骗性对齐:在隐蔽性和情境感知挑战中表现有限,未达到工具性推理 1 级和 2 级 CCL。
5.5 外部安全测试
外部独立团队对 Gemini 2.5 Pro 进行了多维度安全测试:
- 自治系统风险: scheming 能力与同类模型相当,可能存在奖励黑客等轻微危害,但不足以造成灾难性伤害。
- 网络滥用风险:在漏洞发现、利用等关键网络技能上能力显著提升,但仍受限于复杂真实场景。
- CBRN 风险:输出信息准确但缺乏足够技术细节,无法支持恶意行为实施。
- 社会风险:针对民主危害和激进主义的结构化评估中,模型能有效识别有害输入,合规性良好。
六、挑战与展望:AI 发展的新征程
Gemini 2.5 系列的成功标志着 AI 技术的重要里程碑,但仍面临诸多挑战,同时也指明了未来发展方向。
6.1 当前挑战
- 基准测试饱和:模型能力提升速度远超基准测试开发速度,现有基准难以充分评估模型真实能力,新基准开发成本高、周期长。
- 长上下文推理局限:百万 token 上下文的多步骤生成式推理仍存在动作重复、规划僵化等问题,智能体与模型的协同设计需进一步优化。
- 安全平衡难题:模型能力提升与安全防护存在固有张力,复杂场景下的安全边界需持续探索。
6.2 未来方向
- 评估体系创新:开发更具挑战性、贴近真实应用场景的评估基准,实现能力覆盖与难度的规模化提升。
- 智能体能力深化:优化长上下文推理效率,开发自动工具创建能力,解锁更复杂的多步骤任务处理。
- 安全技术升级:基于前沿安全框架,持续强化高风险领域的防护能力,构建自适应安全机制。
- 多模态融合:进一步提升跨模态理解与生成的连贯性和准确性,实现更自然的人机交互。
七、总结
Gemini 2.5 系列通过架构创新、训练优化和能力深化,构建了覆盖全场景需求的 AI 模型家族,在高级推理、多模态理解、长上下文处理和智能体能力上实现突破性进展。其不仅在各类基准测试中展现出 SOTA 性能,更在实际应用场景中验证了实用价值,同时通过完善的安全框架保障了技术的负责任部署。
作为迈向通用 AI 助手的重要一步,Gemini 2.5 系列不仅推动了 AI 技术的边界,更为行业树立了能力与安全平衡的典范。随着技术的持续迭代,Gemini 将在教育、科研、开发、创意等更多领域释放价值,加速 AI 从研究走向现实的进程。