一.一维数组传参的本质
1.1数组名的理解
在 C 语言中,我们可以通过 &arr[0] 的方式获取数组第一个元素的地址。但实际上,数组名本身就代表着地址,更确切地说,它表示的是数组首元素的地址。
我们通过一个简单的程序来验证这一点:
cpp
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("&arr[0] = %p\n", &arr[0]); // 打印数组首元素的地址
printf("arr = %p\n", arr); // 打印数组名表示的地址
return 0;
}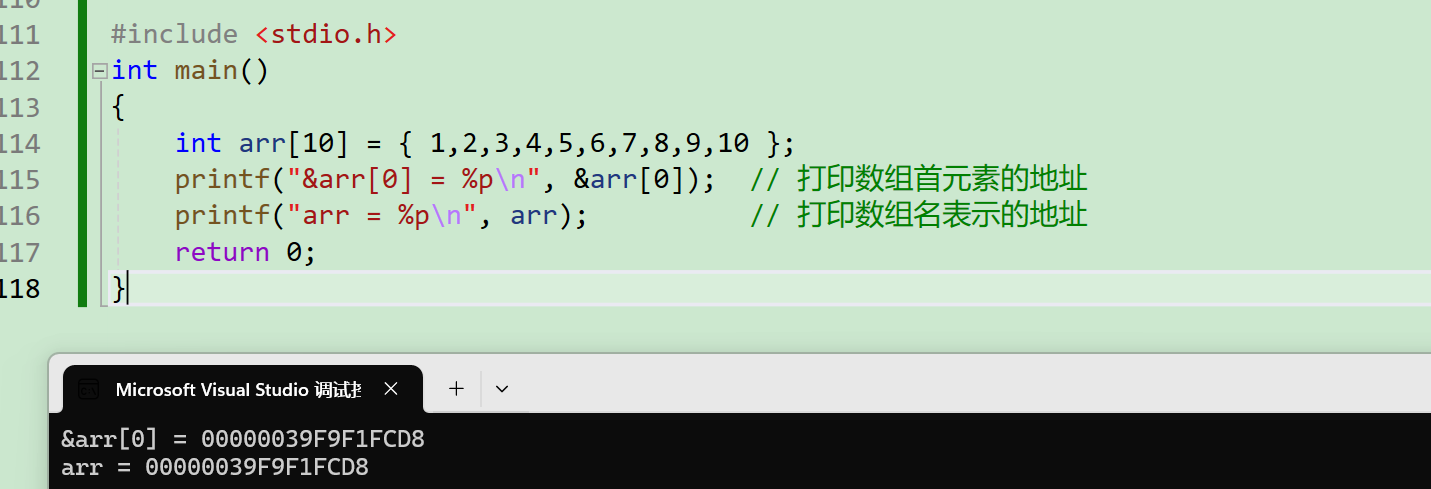
程序的输出结果显示,&arr[0] 和 arr 打印出的地址值完全相同。这一结果证实了:在 C 语言中,数组名本质上就是数组首元素的地址。
这种特性使得我们在使用指针操作数组时更加便捷,比如可以直接用 arr 来初始化指向数组首元素的指针,而不必显式地写成 &arr[0]。
既然数组名代表数组首元素的地址,那该如何理解下面这段代码的输出呢?
cpp
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d\n", sizeof(arr));
return 0;
}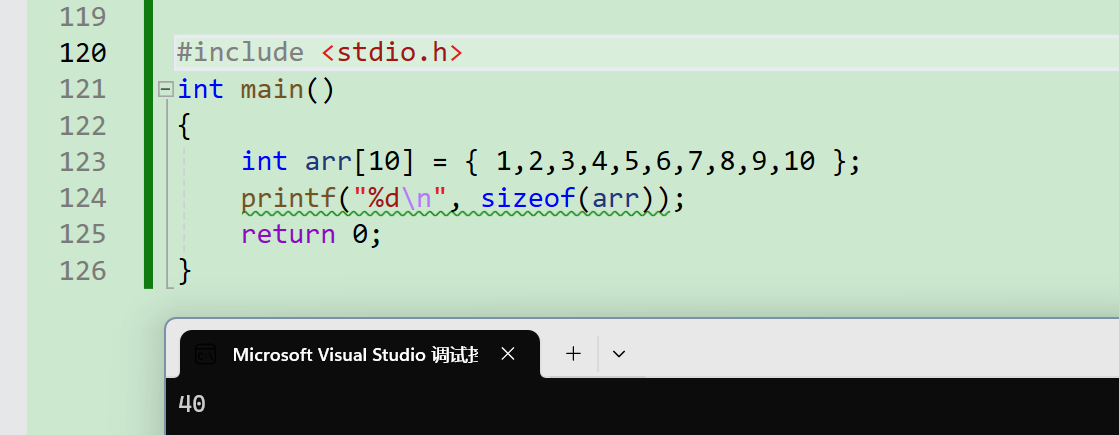
这段代码的输出结果是 40。如果数组名 arr 仅仅是首元素的地址,那么输出应该是 4(32 位系统)或 8(64 位系统)才对,因为这是指针变量的大小。
其实,"数组名表示数组首元素的地址" 这一说法基本正确,但存在两个特殊情况:
-
当数组名出现在
sizeof运算符中时(即sizeof(数组名)),这里的数组名代表整个数组,sizeof计算的是整个数组所占用的字节总数。在上面的例子中,int 类型占 4 字节,10 个元素总共就是 40 字节。 -
当对数组名使用取地址符时(即
&数组名),这里的数组名也表示整个数组,取出的是整个数组的地址。虽然这个地址值和数组首元素的地址值相同,但它们的含义不同:前者指向整个数组,后者指向数组的第一个元素。
除了这两种特殊情况外,在其他任何场景中使用数组名时,它都表示数组首元素的地址。
我们来看下面这段代码及其输出结果,进一步理解数组名在不同场景下的含义:
cpp
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}输出结果:
bash
&arr[0] = 0077F820
&arr[0]+1 = 0077F824
arr = 0077F820
arr+1 = 0077F824
&arr = 0077F820
&arr+1 = 0077F848从结果中可以观察到:
&arr[0]与&arr[0]+1相差 4 个字节arr与arr+1也相差 4 个字节
这是因为 &arr[0] 和 arr 都表示数组首元素的地址,对它们执行 +1 操作会跳过一个元素(在 32 位系统中,int 类型占 4 字节)。
而 &arr 与 &arr+1 则相差 40 个字节(0077F848 - 0077F820 = 40(十进制)),这是因为 &arr 表示整个数组的地址,对其执行 +1 操作会跳过整个数组(10 个 int 元素,共 4×10 = 40 字节)。
虽然 &arr[0]、arr 和 &arr 打印出的地址值相同,但它们的本质含义不同:
&arr[0]和arr指向数组的第一个元素&arr指向整个数组
1.2指针访问数组
有了前面知识的基础,结合数组的特性,我们可以很方便地使用指针来访问数组元素。
cpp
#include <stdio.h>
int main()
{
int arr[10] = {0};
// 输入
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
int* p = arr;
for(i=0; i<sz; i++)
{
scanf("%d", p+i);
// scanf("%d", arr+i); // 也可以这样写
}
// 输出
for(i=0; i<sz; i++)
{
printf("%d ", *(p+i));
}
return 0;
}理解了这段代码后,我们再深入思考一下:既然数组名arr是首元素的地址,可以赋值给指针p,那么在这个场景下arr和p是否等价呢?我们知道可以用arr[i]访问数组元素,那p[i]是否也能访问数组元素呢?
cpp
#include <stdio.h>
int main()
{
int arr[10] = {0};
// 输入
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
int* p = arr;
for(i=0; i<sz; i++)
{
scanf("%d", p+i);
// scanf("%d", arr+i); // 也可以这样写
}
// 输出
for(i=0; i<sz; i++)
{
printf("%d ", p[i]);
}
return 0;
}将*(p+i)换成p[i]后,程序依然能正常打印数组元素。这说明p[i]本质上等价于*(p+i)。
同理,arr[i]也等价于*(arr+i)。实际上,编译器在处理数组元素访问时,会将arr[i]转换为 "首元素地址加上偏移量 i" 得到元素地址,然后通过解引用操作来访问该元素。
这种等价关系体现了数组和指针在访问方式上的内在联系,也让我们能更灵活地选择数组或指针的方式操作数据。
那么 arr 和 p 的区别?
虽然数组名 arr 和指针变量 p 在很多场景下表现相似(比如都能通过 +i 偏移访问元素,都支持 [i] 形式的访问),但它们本质上有显著区别,主要体现在以下几个方面:
- 本质类型不同
arr是数组名 ,代表一块连续的内存空间本身(存储了多个同类型元素),它不是变量,而是一个常量标识符 (编译时确定,无法被赋值)。
- 例如:
arr = p;是错误的,因为数组名不能被修改。p是指针变量 ,它是一个独立的变量,本身占用内存(4 字节或 8 字节),专门用于存储地址,可以被多次赋值修改。
- 例如:
p = arr;p = &arr[5];都是合法的,指针可以指向不同的地址。
sizeof运算结果不同
sizeof(arr)计算的是整个数组的总大小 (单位:字节)。
- 对于
int arr[10],sizeof(arr) = 4×10 = 40(假设 int 占 4 字节)。sizeof(p)计算的是指针变量本身的大小 (与指向的数据无关)。
- 在 32 位系统中
sizeof(p) = 4,64 位系统中sizeof(p) = 8。
- 取地址操作的含义不同
&arr表示整个数组的地址 ,类型是 "指向整个数组的指针"(如int (*)[10])。
- 对其
+1会跳过整个数组(偏移 40 字节,如前面的例子)。&p表示指针变量自身的地址 ,类型是 "指向指针的指针"(如int**)。
- 对其
+1只会跳过一个指针变量的大小(4 或 8 字节)。
- 存储位置不同
- 数组
arr的元素存储在数据段或栈区(取决于是否为全局数组),数组名只是这块空间的 "标识",不占用额外内存。- 指针变量
p本身存储在栈区(局部变量时),需要单独的内存空间来存放它所指向的地址。
总结
arr和p的相似性(如arr[i]与p[i]等价)是因为编译器在处理数组访问时,会将数组名隐式转换为指向首元素的指针(除了sizeof(arr)和&arr两种特殊情况)。但本质上,数组名是 "内存块的标识",指针是 "存储地址的变量",二者不可混为一谈。
1.3数组传参本质
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
void test(int *arr)//接收数组首元素地址
{
int len1 = sizeof(arr) / sizeof(arr[0]);//arr数组首元素的地址,64位环境下指针大小为8字节
printf("%d", len1);// 首元素int类型4个字节 8/4=2
}
int main()
{
int arr[10] = { 0 };
int len = sizeof(arr) / sizeof(arr[0]);//sizeof(数组名)计算的是整个数组的大小=40
printf("%d\n", len);// 首元素int类型4个字节 40/4=10
test(arr);//arr数组名,没有&,也没有单独放在sizeof里,是数组首元素地址
return 0;
}大家看一下这段代码 ,大家觉得代码输出的结果是什么 ?有人会觉得都是数组的大小/数组受元素的大小 ==40/4=10 。那结果就是两个10。是不是呢?
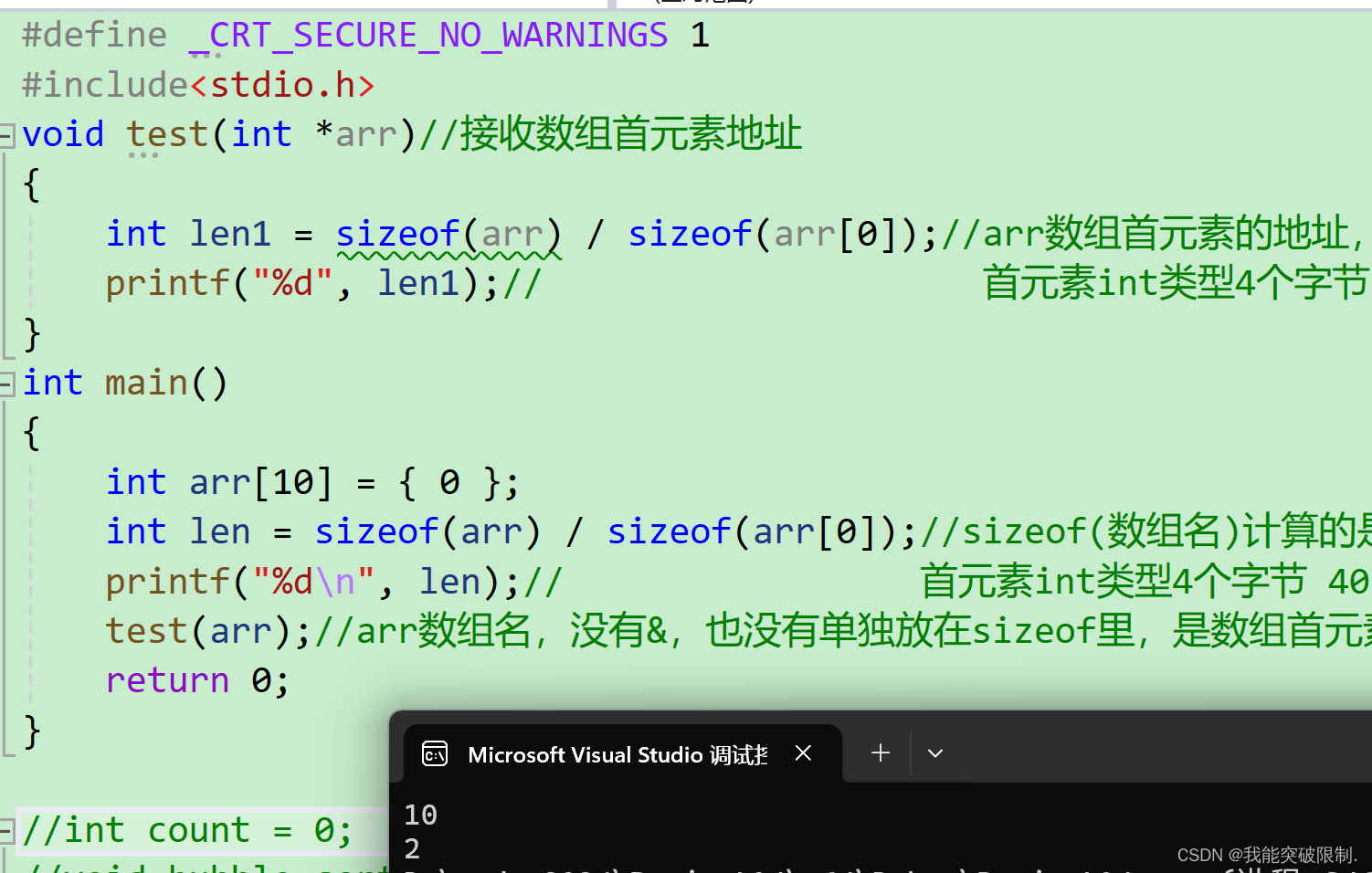
大家可以看到结果是一个10,一个2 。那2是咋来的 呢?这里就涉及到了一维数组传参的本质 。test(arr)这里的数组名没有& ,也没有单独放在sizeof 里面,所以这里的arr是数组首元素的地址 。所以test函数 的sizeof(arr)这里的arr 并不是数组的地址,是数组首元素的地址 。地址就是指针 ,指针的大小在64位环境下是8个字节 。8/4=2 。所以一维数组传参的本质 传的是数组首元素的地址 ,写成数组接收 是为了方便理解 ,实际本质上传的是地址 ,用指针变量接收。
结论:一维数组传参的本质是传数组首元素的地址
- 为什么不传递整个数组?
如果传递整个数组,意味着需要将数组的所有元素复制一份到函数栈帧中。对于大型数组,这会导致:
- 内存空间的浪费(重复存储相同数据)
- 函数调用效率低下(复制大量数据耗时)
C 语言设计为传递地址而非整个数组,正是为了避免这些问题,提高程序效率。
- 数组传参时的隐式转换
当数组名作为实参传递给函数时,编译器会自动将其转换为指向数组首元素的指针 (即 &arr[0])。
例如,下面的函数调用:
cpp
int arr[10] = {1,2,3};
func(arr); // 传递数组名等价于:
cpp
func(&arr[0]); // 传递首元素地址- 函数形参的本质是指针
接收数组参数的函数,其形参看似是数组形式,实则会被编译器解析为指针。
例如,以下三种函数声明是完全等价的:
cpp
// 形式1:看似接收数组
void func(int arr[]);
// 形式2:数组长度无意义(编译器会忽略)
void func(int arr[10]);
// 形式3:显式声明为指针(本质)
void func(int* arr);编译器会将前两种形式自动转换为第三种 ------ 即形参是一个指向 int 类型的指针,用于接收数组首元素的地址。
4. 函数内部如何操作数组?
由于形参本质是指针(首元素地址),函数内部可以通过指针偏移来访问原数组的所有元素:
cpp
void func(int* arr, int sz) // sz 需单独传递数组长度
{
for(int i=0; i<sz; i++)
{
printf("%d ", arr[i]); // 等价于 *(arr+i)
}
}这里的 arr[i] 与指针访问数组的逻辑一致,都是通过 "首地址 + 偏移量" 定位元素。
- 注意:数组长度无法通过形参获取
正因为数组传参本质是传地址,函数内部无法通过 sizeof(arr) 获取原数组的总大小(此时 sizeof(arr) 计算的是指针的大小,即 4 或 8 字节)。
因此,传递数组时通常需要额外传递数组长度(如上面的 sz)。
总结
一维数组传参的本质是传递首元素地址,这是 C 语言为了效率而设计的特性。函数形参看似是数组,实则是指针,通过指针偏移实现对原数组的访问。理解这一点,就能明白为什么函数内部无法直接获取数组总长度,以及数组传参时的各种 "表面矛盾"(如形参写 [10] 却能接收任意长度数组)。
二.冒泡排序(优化版)
冒泡排序的核心思想可以优化得更精准、简洁:
冒泡排序的核心思想是通过多轮相邻元素比较与交换,使最大(或最小)元素逐步 "浮" 到数组末端。具体可优化为:
-
外层循环控制排序轮次 :最多执行
n-1轮(n为数组长度)。因为每轮至少能确定 1 个元素的最终位置,当只剩 1 个元素时无需排序。 -
内层循环控制每轮比较范围 :第
i轮(从 0 开始)只需比较前n-1-i个元素。因为数组后i个元素已通过前i轮排好序,无需再参与比较。 -
相邻元素比较交换:若相邻元素顺序不符合要求(如前大后小),则交换两者位置,确保较大元素向数组末端移动。
-
优化点:
- 增加交换标记 (如
flag),若某轮未发生任何交换,说明数组已完全有序,可直接终止后续循环,避免无效比较 - 记录最后一次交换位置,作为下一轮比较的终点,进一步减少无意义的比较次数
- 增加交换标记 (如

但是像这样的数组 无需排序 ,如果按照 原来的思路 仍会按部就班的排序,所以我们可以对他 进行优化 。用 flag做标记 , 判断 是否数组 本身就是有序 ,如果是就直接 break跳出即可。
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int count = 0;
void bubble_sort(int arr[],int sz)
{
for (int i = 0; i < sz - 1; i++)//控制趟数
{
int flag = 0;
for (int j = 0; j < sz - 1 - i; j++)//控制比较次数
{
count++;//记录循环次数
if (arr[j] > arr[j + 1])//判断是否交换
{
flag = 1;
int tmp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = tmp;//交换
}
}
if (flag == 0)
break;//已经排好序直接结束循环
}
printf("count=%d\n", count);//输出循环次数
}
void printf_arr(int arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);//遍历打印数组
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);//数组长度
bubble_sort(arr,sz);
printf_arr(arr, sz);
return 0;
}这里我们用count变量记录循环次数 ,对比优化前后的循环次数。
优化前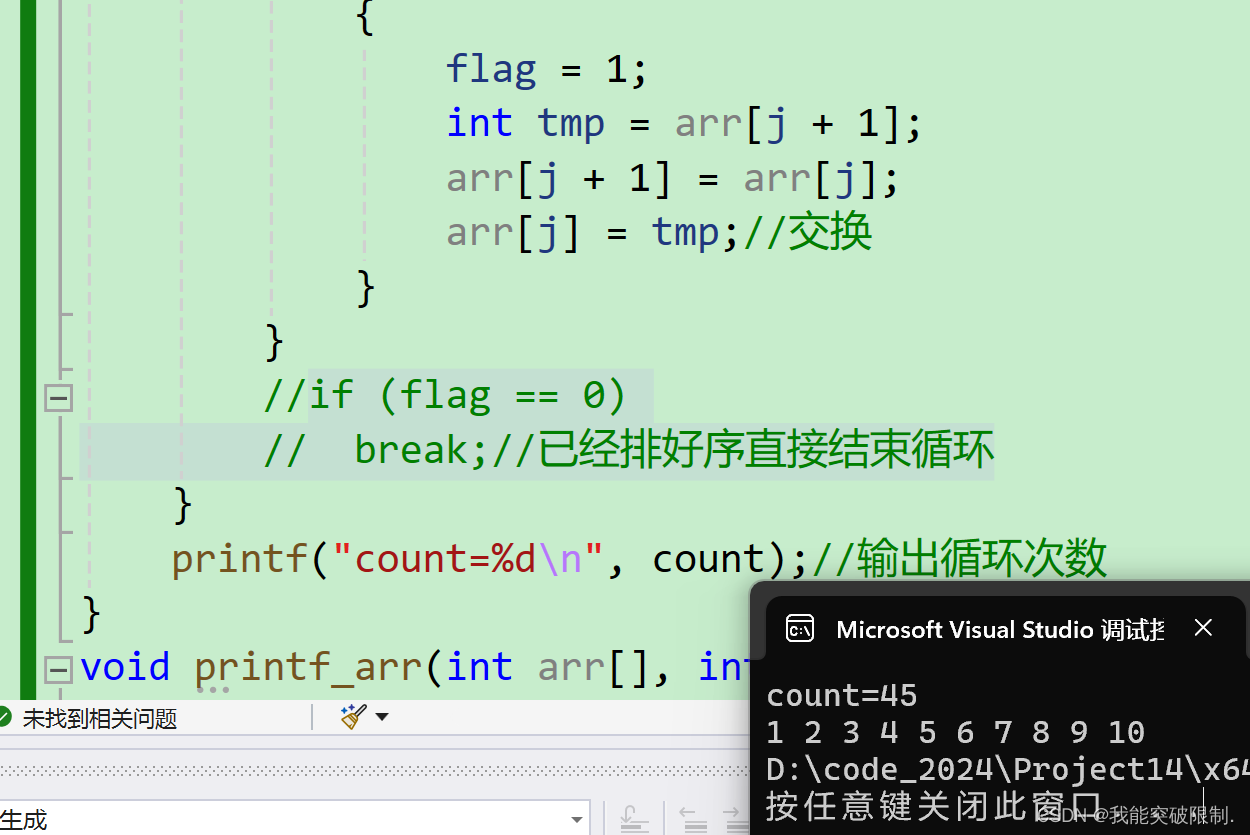
优化后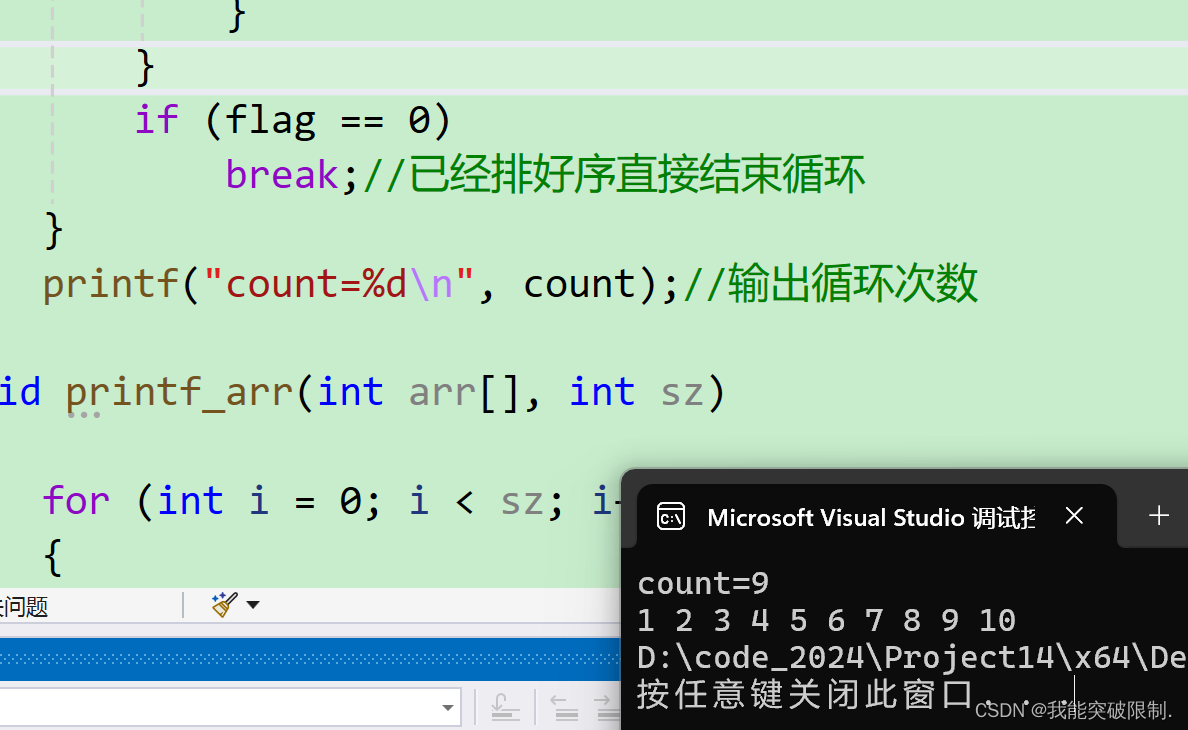
大家可以看到优化前需要循环45次 ,优化后循环9次 即可。这就是优化后的效果
三.二级指针
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int a = 10;
int* p = &a;//一级指针
int** pp = &p;//二级指针
int*** ppp = &pp;//三级指针
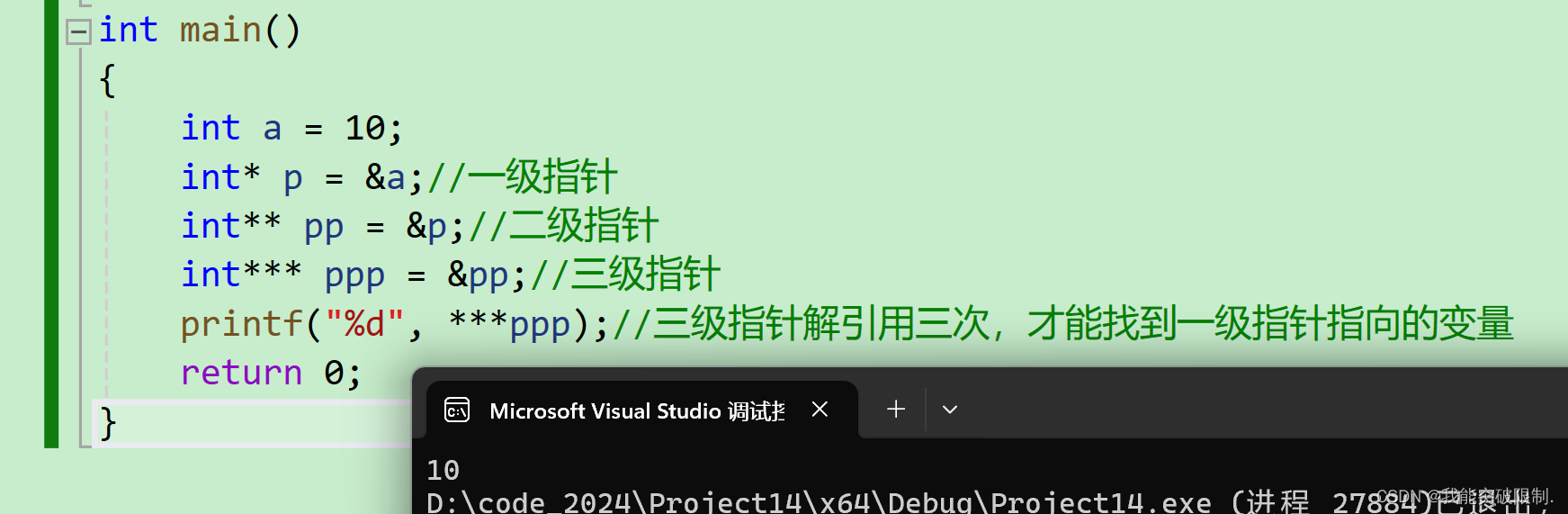
printf("%d", ***ppp);//三级指针解引用三次,才能找到一级指针指向的变量
return 0;
}指针变量也是变量 ,是变量就有地址 ,那指针变量的地址存在哪里呢 ?答案是存在二级指针 。二级指针就是接收一级指针地址的指针 。以此类推,三级指针就是接收二级指针地址的指针。

*说明这是一个指针 ,前面的int加上一个星号 说明指针指向的是个一级指针 ,那么这个指针就是二级指针 。大家可以发现有多少个星号就说明这是几级指针。
结论:二级指针是存放一级指针地址的指针,有多少个星号说明是几级指针。
四.指针数组与数组指针
4.1指针数组的概念
指针数组是数组,只不过这个数组中存放的元素类型是指针。
我们可以通过类比来理解:
- 整型数组,是专门用来存放整型数据的数组
- 字符数组,是专门用来存放字符数据的数组
以此类推,指针数组就是专门用来存放指针的数组。
它的本质仍然是数组,具备数组的基本特性(如连续的内存空间、固定的长度等),只是其存储的元素类型特殊 ------ 不是普通的整型、字符型等数据,而是指针(即内存地址)。
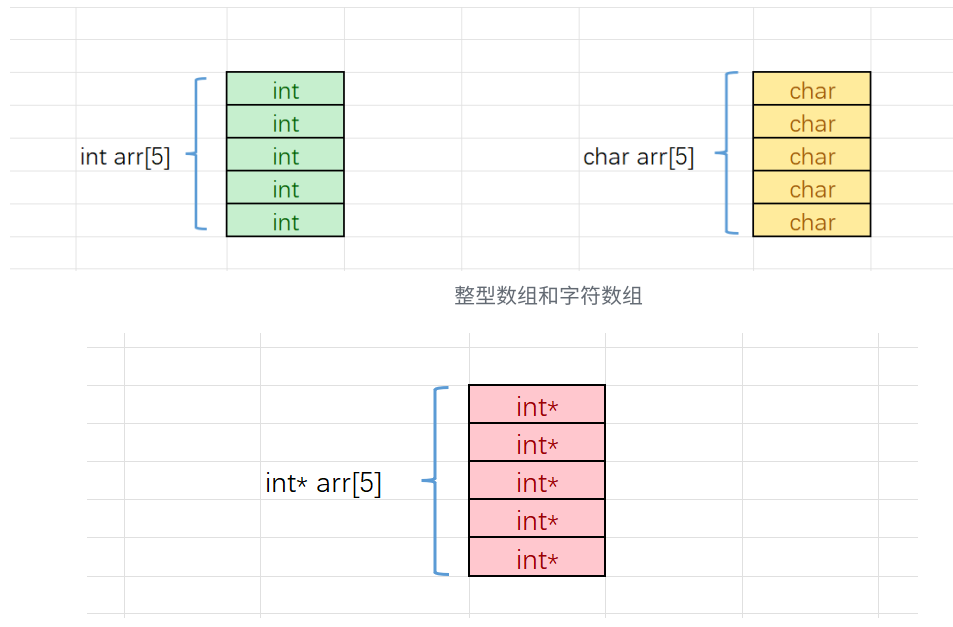
例如 int* arr[5]; 定义的就是一个指针数组:
arr首先是一个数组(因为[]的优先级高于*)- 数组中包含 5 个元素
- 每个元素都是
int*类型的指针(指向整型数据的指针)
4.2指针数组模拟二维数组
cpp
#include <stdio.h>
int main()
{
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
// 数组名表示首元素地址(类型为int*),因此可以存入parr数组
int* parr[3] = {arr1, arr2, arr3};
int i = 0;
int j = 0;
for(i=0; i<3; i++)
{
for(j=0; j<5; j++)
{
// 原写法
printf("%d ", parr[i][j]);
// 等价的解引用写法
// printf("%d ", *(*(parr + i) + j));
}
printf("\n");
}
return 0;
}代码解析:
-
指针数组的定义 :
int* parr[3]定义了一个包含 3 个元素的指针数组,每个元素都是int*类型(指向整型的指针)。 -
存储内容 :我们将三个一维数组的首地址(
arr1、arr2、arr3)存入parr中,此时parr数组就像一个 "容器",收纳了指向不同整型数组的指针。 -
访问方式:
parr[i]用于访问指针数组的第i个元素(即指向某个一维数组的指针)parr[i][j]等价于*(parr[i] + j),表示通过指针访问第i个一维数组的第j个元素
与二维数组的对比:
从输出结果看,这段代码通过指针数组模拟出了类似二维数组的访问效果(分行打印多个数组),但本质上与二维数组不同:
- 内存布局 :二维数组的所有元素在内存中是连续存储的;而这里的
arr1、arr2、arr3是三个独立的一维数组,它们在内存中的位置并不连续。 - 结构本质:指针数组是 "数组存放指针,指针指向数组" 的间接结构;二维数组是直接的二维连续存储空间。
这种通过指针数组组合多个一维数组的方式,虽然能实现类似二维数组的访问形式,但在内存管理和数据连续性上有本质区别。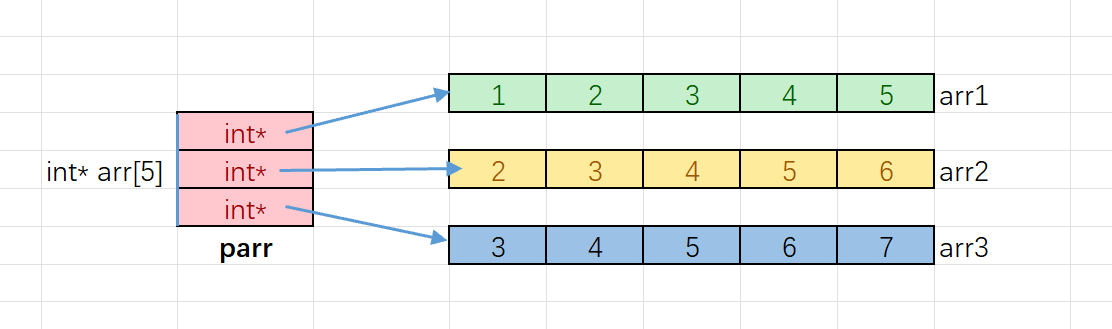
4.3数组指针的概念
前面我们学习了指针数组,它本质是一种数组,只是数组中存放的元素是地址(指针)。
那么数组指针变量,它是指针变量呢?还是数组?
答案是:指针变量。
我们可以通过已熟悉的概念类比理解:
- 整型指针变量(
int *pint):存放整型变量的地址,能够指向整型数据 - 浮点型指针变量(
float *pf):存放浮点型变量的地址,能够指向浮点型数据
以此类推,数组指针变量就是:专门存放数组的地址,能够指向数组的指针变量。
如何区分数组指针变量?
看下面两段代码,哪个才是数组指针变量?
cpp
int *p1[10];
int (*p2)[10];要区分p1和p2的本质,关键在于理解运算符的优先级:[]的优先级高于*。
-
对于
int *p1[10]:由于
[]优先级更高,p1先与[10]结合,说明p1是一个数组;数组的元素类型是int *(整型指针)。因此,p1是指针数组。 -
对于
int (*p2)[10]:括号
()改变了优先级,p2先与*结合,说明p2是一个指针变量;这个指针指向的是一个 "包含 10 个 int 元素的数组"。因此,p2是数组指针变量。
简言之,int (*p)[10]的解读是:
p是一个指针变量,它指向的是一个大小为 10 的整型数组 ------ 这就是数组指针的核心定义。这里的括号必不可少,它确保了p首先被识别为指针,而非数组。
提问 数组指针变量int (*p2)[10] 和 int * p=arr有什么区别?
数组指针变量(如 int (*p)[10])与 int* p = arr 定义的指针看似都和数组有关,但它们的指向对象、类型、操作逻辑有本质区别,核心差异在于 "指向的是数组整体还是数组元素"。
1. 本质与指向对象不同
-
int* p = arrp是整型指针(指向单个整型元素的指针)。- 它指向的是数组
arr的首元素 (即&arr[0]),本质是 "指向单个int类型数据"。
-
int (*p)[10]p是数组指针(指向数组整体的指针)。- 它指向的是整个数组 (如
int arr[10]),本质是 "指向一个包含 10 个int元素的数组"。
2. 指针类型与步长不同
指针的 "类型" 决定了它进行 +1 等偏移操作时的 "步长"(跳过的字节数),这是最关键的区别:
-
int* p(整型指针)- 类型是 "指向
int的指针",步长 =sizeof(int)(通常 4 字节)。 - 例:
p+1会跳过 1 个int元素,指向数组的下一个元素(&arr[1])。
- 类型是 "指向
-
int (*p)[10](数组指针)- 类型是 "指向
int[10]数组的指针",步长 =sizeof(int[10])(10×4=40 字节)。 - 例:
p+1会跳过整个数组(40 字节),指向内存中该数组后面的位置。
- 类型是 "指向
3. 初始化与赋值的区别
-
int* p = arr- 数组名
arr会隐式转换为 "首元素地址"(&arr[0]),与int*类型匹配,可直接赋值。
- 数组名
-
int (*p)[10] = &arr- 必须用整个数组的地址 (
&arr)初始化,不能直接用arr(arr是首元素地址,类型不匹配)。 - 若写成
int (*p)[10] = arr会报错(类型不兼容:int*无法转换为int (*)[10])。
- 必须用整个数组的地址 (
4. 访问数组元素的方式不同
假设数组为 int arr[10] = {0,1,2,...,9}:
-
用
int* p = arr访问元素- 通过指针偏移访问单个元素:
*(p+i)等价于arr[i](如*(p+3)访问arr[3])。
- 通过指针偏移访问单个元素:
-
用
int (*p)[10] = &arr访问元素- 需先解引用得到数组本身(
*p等价于arr),再访问元素:(*p)[i]等价于arr[i](如(*p)[3]访问arr[3])。 - 若直接写
p[i]会错误地跳过整个数组(因步长为 40 字节),访问到的是数组外的无效内存。
- 需先解引用得到数组本身(
总结:核心区别表
| 对比项 | int* p = arr(整型指针) |
int (*p)[10] = &arr(数组指针) |
|---|---|---|
| 指向对象 | 数组首元素(单个 int) |
整个数组(int[10] 类型) |
| 类型 | int* |
int (*)[10] |
+1 步长 |
4 字节(1 个 int) |
40 字节(整个数组) |
| 访问元素方式 | *(p+i) 或 p[i] |
(*p)[i] 或 *(*p + i) |
简单说:int* p 是 "元素级指针",用于逐个访问数组元素;int (*p)[10] 是 "数组级指针",用于指向整个数组(常见于二维数组操作等场景)。
4.4数组指针的初始化
要存储数组的地址,就需要用到数组指针变量,而获取数组地址的方式,正是我们之前学过的 &数组名(注意:&数组名 取的是整个数组的地址,而非首元素地址)。
举个具体例子:
cpp
int arr[10] = {0}; // 定义一个包含10个int元素的数组
&arr; // 这里的&arr获取的是整个数组的地址,而非首元素&arr[0]由于 &arr 的类型是 "指向 int 10 数组的指针"(即 int (*)[10]),普通指针无法存储它,必须用对应的数组指针变量来接收,写法如下:
cpp
int (*p)[10] = &arr; // p是数组指针变量,专门存储整个数组的地址这里的赋值完全匹配:等号左侧 p 的类型是 int (*)[10](指向 10 个 int 元素的数组指针),右侧 &arr 的类型也是 int (*)[10](整个数组的地址类型),符合类型兼容的规则。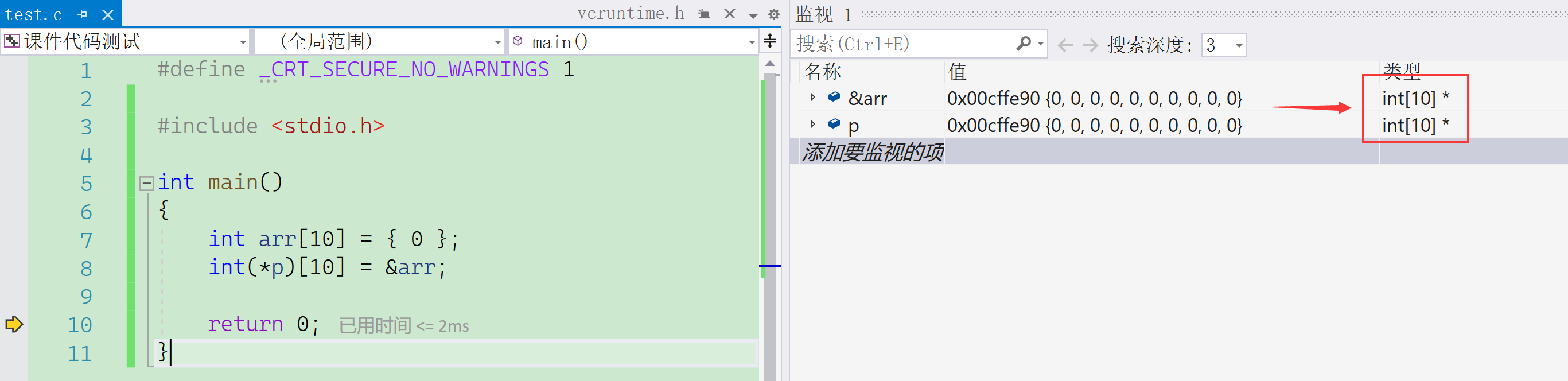
通过调试也能清晰看到,&arr(数组的地址)与数组指针变量 p 的类型完全一致,进一步验证了两者的匹配性。
我们可以将数组指针的定义 int (*p)[10] = &arr; 拆解,逐部分解析其类型含义:
cpp
int (*p) [10]
| | |
| | |------ 表示 p 指向的数组中,包含 10 个元素(数组的长度)
| |
| |------ 表示 p 是一个指针变量(括号确保 p 先与 * 结合,优先识别为指针)
|
|------ 表示 p 指向的数组中,每个元素的类型是 int(数组元素的基础类型)4.5数组指针类型
数组指针类型 该怎么写呢?首先p是指针那我们就让p和*结合,说明p是个指针 。再在星号p后面写上方括号\[\] ,说明指针指向一个数组 。那数组有几个元素 呢?方括号里面的数字就代表指向数组的元素数。那数组元素的类型 是什么呢?最前面的类型加粗样式 就是数组元素的类型。所以数组指针类型我们可以这样写。
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int arr[4] = { 1,2,3,4 };
int (*p)[4] = &arr;//&arr表示整个数组的地址
//*表示是个指针[4],表示指向的数组4个元素,4不可省略
//int表示数组元素类型是int类型
return 0;
}注意方括号里的数组表示指向数组的元素个数 ,所以不可省略 ,并且指向的数组元素不同 ,即使类型相同 指针变量的类型也是不同的 。变量名p去掉后剩下的就是数组指针类型。
- 字符数组指针
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
char arr[] = "abcd";
char (*p)[5] = &arr;//&arr表示整个数组的地址
//指针类型:char (*)[5]//注意是五个字符的数组才是这样
return 0;
}- 指针类型 为:char (*)具体数组元素个数。
- 整型数组指针
cpp
#include<stdio.h>
int main()
{
int arr[4] = { 1,2,3,4 };
int (*p)[4] = &arr;//&arr表示整个数组的地址
//指针类型:char (*)[4]//注意是4个整型的数组才是这样
return 0;
}- 指针类型 为:int (*)具体数组元素个数。
数组指针类型的区别?
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int arr[] = { 1,2,3,4 };
printf("%d\n", arr);//数组名表示数组首元素的地址
printf("%d\n", arr+1);//指向的是数组元素+1,跳过一个元素,4字节
printf("%d\n", &arr[0]);//取出数组首元素的地址
printf("%d\n", &arr[0] + 1);//指向的是数组元素+1,跳过一个元素,4字节
printf("%d\n", &arr);//&数组名表示整个数组的地址,但也是指向数组首元素地址
printf("%d\n", &arr + 1);//指向的是数组+1,跳过一个数组,16字节
return 0;
}以这个代码为例 。大家看一下代码结果 是啥?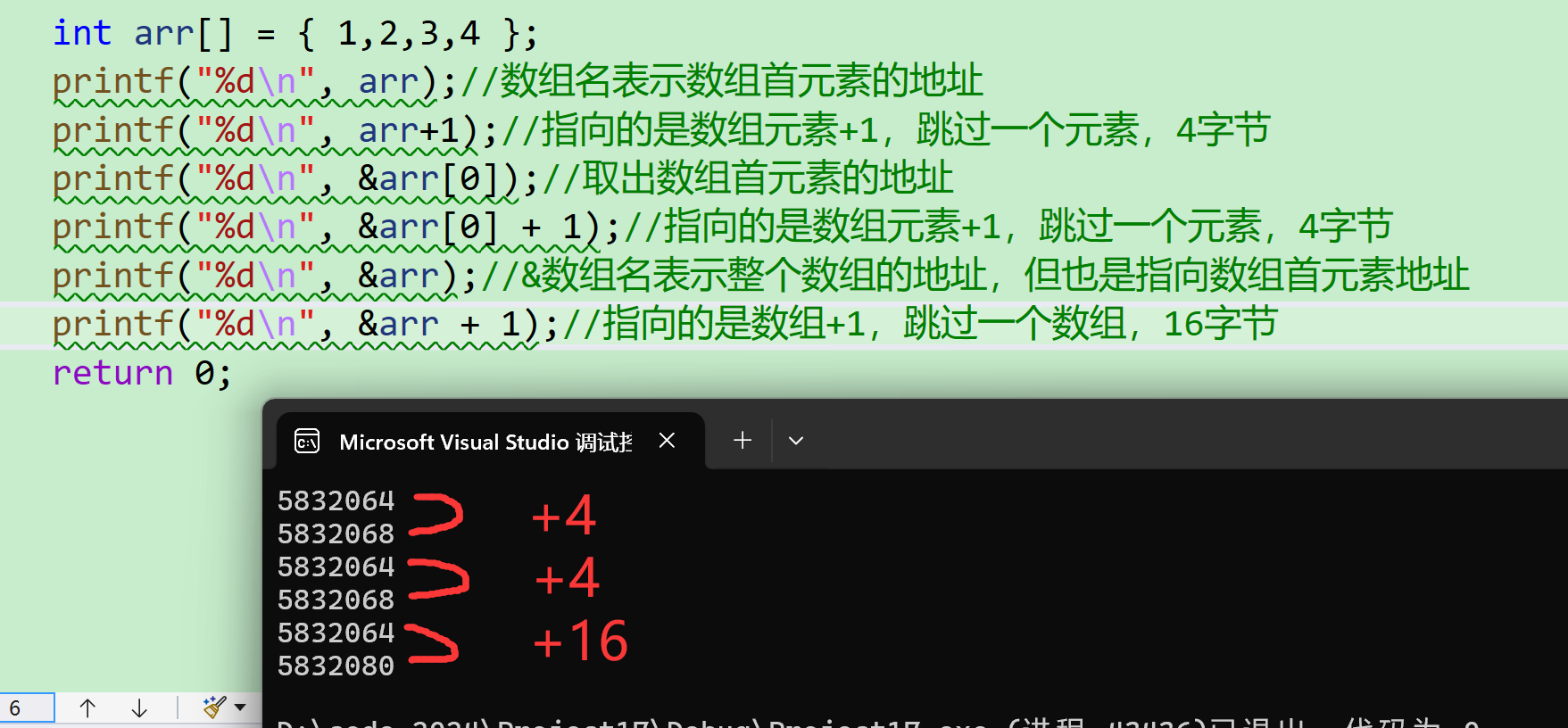 为什么 会出现这样的结果呢?
为什么 会出现这样的结果呢?
我们知道指针类型决定了指针加1向前移动多大距离 。&arr 的指针类型是int (*p)4* \*指向一个四个整形的数组,所以+1跳过整个数组 ,也就是4个整型,16个字节。
结论:指针类型决定指针加1向前移动多大距离,变量名去掉后就是数组指针的类型。
五.二维数组传参的本质
5.1二维数组的理解
从内存存储的本质 来看,二维数组在内存中是连续存储的 "一维结构" ,但从逻辑定义和使用场景来看,它是 "按行 / 列组织的二维结构"------ 可以理解为 "由多个一维数组(行数组)拼接而成的连续内存块",本质上是对连续一维内存的 "二维逻辑封装"。
1. 核心结论:内存中是连续的,逻辑上是二维的
以典型的二维数组 int arr[3][4] = {1,2,3,4, 5,6,7,8, 9,10,11,12}; 为例(3 行 4 列):
- 逻辑上 :它被看作 "3 个一维数组"(每行是一个长度为 4 的一维数组,即
arr[0]、arr[1]、arr[2]分别是第 1、2、3 行的 "行数组名"); - 内存中 :所有 12 个元素会按 "行优先" 顺序(先存完第 1 行,再存第 2 行,最后存第 3 行)连续排列,没有任何空隙,完全等同于一个长度为 12 的一维数组
int arr1[12]的内存布局。
2. 用内存地址验证 "连续性"
通过打印每个元素的地址,可以直观看到二维数组的连续存储特性(假设int占 4 字节,地址为十六进制):
| 元素 | arr00 | arr01 | arr02 | arr03 | arr10 | arr11 | ... | arr23 |
|---|---|---|---|---|---|---|---|---|
| 内存地址 | 0x100 | 0x104 | 0x108 | 0x10C | 0x110 | 0x114 | ... | 0x12C |
可以发现:
- 同一行内,相邻元素地址差 4(
int的字节数),连续存储; - 跨行时(如
arr[0][3]到arr[1][0]),地址从0x10C直接跳到0x110(差 4),没有空隙 ------ 说明 "行与行之间也连续",整个二维数组就是一块连续的内存。
3. 关键区别:二维数组 vs 一维数组(逻辑层面)
虽然内存连续,但二维数组的类型和访问方式与一维数组完全不同,这是 "逻辑封装" 的核心体现:
| 对比维度 | 二维数组 int arr[3][4] |
等效一维数组 int arr1[12] |
|---|---|---|
| 数组名含义 | arr 是 "指向第 0 行的数组指针"(类型 int (*)[4]),表示 "整个二维数组的首地址" |
arr1 是 "指向首元素的整型指针"(类型 int*),表示 "一维数组首元素地址" |
| 元素访问方式 | 支持 arr[i][j](行索引 + 列索引,符合二维逻辑) |
仅支持 arr1[k](唯一索引,一维逻辑) |
| 行数组特性 | 存在 "行数组"(如 arr[0] 是第 0 行的数组名,类型 int*),可单独操作某一行 |
无 "行" 概念,只有单个元素的线性排列 |
总结
二维数组不是 "独立的二维结构",而是 "用二维逻辑管理的连续一维内存"------ 可以理解为 "多个长度相同的一维数组,在内存中无缝拼接而成"。这种设计既满足了 "矩阵、表格" 等二维数据的逻辑表达需求,又遵循了内存 "线性连续" 的底层存储规则。
5.2二维数组传参本质
二维数组本质 其实就是一个特殊的(内存连续的)一维数组 。数组每个的元素是一个一维数组。以下面的代码为例。

cpp
void test(int arr[3][5], int r, int c)
{
for (int i = 0; i < r; i++)
{
for (int j = 0; j < c; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
test(arr, 3, 5);
return 0;
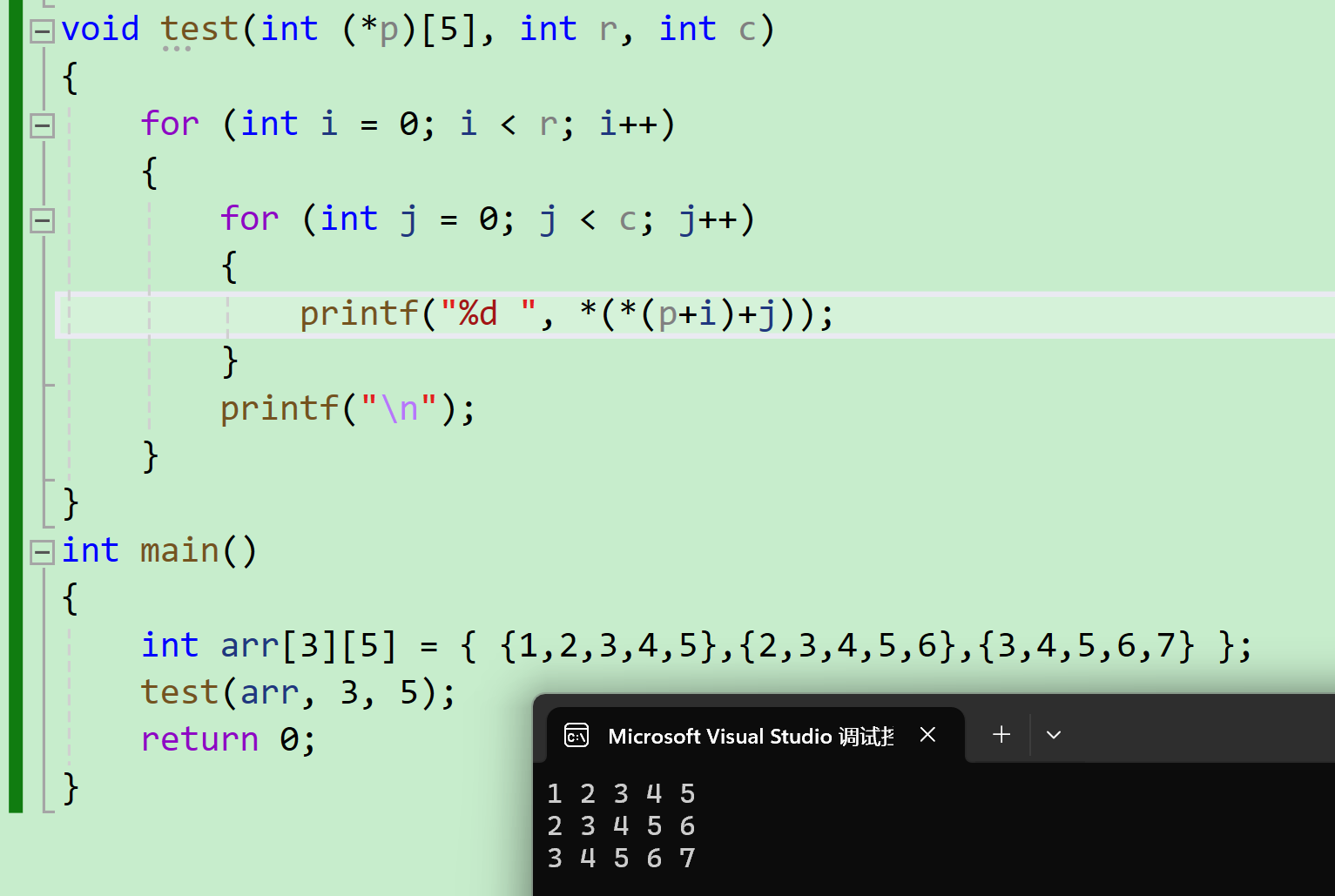
}这是我们常用的二维数组使用方式 。现在我们可以根据二维数组的本质 进行改写。 传的是数组名 ,数组名代表首元素地址 。二维数组首元素是个一维数组 ,那我们就用数组指针 接收。我们在用星号(arr+i)访问第i行数组 ,星号(*(arr+i)+j)访问 第i行第j个元素 。所以代码就可以写成这样。
传的是数组名 ,数组名代表首元素地址 。二维数组首元素是个一维数组 ,那我们就用数组指针 接收。我们在用星号(arr+i)访问第i行数组 ,星号(*(arr+i)+j)访问 第i行第j个元素 。所以代码就可以写成这样。
cpp
void test(int (*p)[5], int r, int c)
{
for (int i = 0; i < r; i++)
{
for (int j = 0; j < c; j++)
{
printf("%d ", *(*(p+i)+j));
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
test(arr, 3, 5);
return 0;
}
后言
今天给大家分享的内容有点多,感谢各位小伙伴的耐心阅读。到这里指针的内容我们已经快讲完了。坚持就是胜利!