文章目录
- sync.WaitGroup
- sync.Once
- sync.Lock
- 锁
-
- [互斥锁 Mutex](#互斥锁 Mutex)
- [读写锁 RWMutex](#读写锁 RWMutex)
- 死锁
- sync.Map
- sync/Atomic
- sync.pool
- select是什么
- IO多路复用
- select用法
在 Go 语言并发编程中,倡导使用通信共享内存 ,不要使用共享内存通信,goroutine之间尽量通过channel来协作,而 在其他的传统语言中,都是通过共享内存加上锁机制来保证并发安全的 ,同样go语言也提供了对共享内存并发安全机制的支持,这些功能都存在于sync包下。
sync.WaitGroup
在前面很多goroutine的示例中,我们都是通过time.Sleep()方法让主goroutine等待一段时间以便于gortoutine能够执行完打印结果,显然这不是一个很好的办法,因为我们不知道所有的子goroutine要多久才能执行完,不能确切的知道需要等待多久。那么怎么处理呢?
第一种方式:channel
看下面例子:
go
package main
import (
"fmt"
)
func main() {
ch := make(chan struct{}, 10)
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Printf("num:%d\n", i)
ch <- struct{}{}
}(i)
}
for i := 0; i < 10; i++ {
<-ch
}
fmt.Println("end")
}运行结果:
bash
num:0
num:2
num:1
num:4
num:6
num:7
num:5
num:8
num:9
num:3
endstruct{}是一个类型,可以理解为"空结构体类型",而struct{}{}才是一个空结构体类型的实例
我们在每个goroutine中,向管道里发送一条数据,这样我们在程序最后,通过for循环将管道里的数据全部取出,直到数据全部取完毕才能继续后面的逻辑,这样就可以实现等待各个goroutine执行完。
但是,这样使用channel显得并不优雅,其次,我们得知道具体循环的次数,来创建管道的大小,假设次数非常的多,则需要申请同样数量大小的管道出来,对内存也是不小的开销。
第二种方式:sync.WaitGroup
这里我们可以用sync包下的WaitGroup来实现,Go语言中可以使用sync.WaitGroup来实现并发任务的同步以及协程任务等待。
sync.WaitGroup是一个对象,里面维护者一个计数器,并且通过三个方法来配合使用
(wg * WaitGroup) Add(delta int) 计数器加delta
(wg * WaitGroup) Done() 计数器减1
(wg * WaitGroup) Wait() 会阻塞代码的运行,直到计数器减为0。
先看示例:
go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func myGoroutine() {
defer wg.Done()
fmt.Println("myGoroutine!")
}
func main() {
wg.Add(10)
for i := 0; i < 10; i++ {
go myGoroutine()
}
wg.Wait()
fmt.Println("end!!!")
}运行结果:
go
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
myGoroutine!
end!!!程序首先把wg的计数设置为10,每个for循环运行完毕都把计数器减1,main函数中执行到wg.Wait()会一直阻塞,直到wg的计数器为零。最后打印了10个myGoroutine!,是所有子goroutine任务结束后主goroutine才退出。
注意:**sync.WaitGroup对象的计数器不能为负数,否则会panic**,在使用的过程中,我们需要保证Add()的参数值,以及执行完Done()之后计数器大于等于零。
sync.Once
在我们写项目的时候,程序中有很多的逻辑只需要执行一次,最典型的就是项目工程里配置文件的加载,我们只需要加载一次即可,让配置保存在内存中,下次使用的时候直接使用内存中的配置数据即可。这里就要用到sync.Once。
sync.Once可以在代码的任意位置初始化和调用,并且线程安全。sync.Once最大的作用就是延迟初始化 ,对于一个sync.Once变量我们并不会在程序启动的时候初始化 ,而是在第一次用它的时候才会初始化,并且只初始化这一次,初始化之后驻留在内存里,这就非常适合我们之前提到的配置文件加载场景,设想一下,如果是在程序刚开始就加载配置,若迟迟未被使用,则既浪费了内存,又延长了程序加载时间,而sync.Once就刚好解决了这个问题。
使用示例:
go
// 声明配置结构体Config
type Config struct{}
var instance *Config
var once sync.Once // 声明一个sync.Once变量
// 获取配置结构体
func InitConfig() *Config {
once.Do(func(){
instance = &Config{}
})
return instance
}只有在第一次调用InitConfig()获取Config 指针的时候才会执行once.Do(func(){instance = &Config{} })语句,执行完之后instance就驻留在内存中,后面再次执行InitConfig()的时候,就直接返回内存中的instance。
与init()的区别
有时候我们使用init()方法进行初始化,init()方法是在其所在的package首次加载时执行的,而sync.Once可以在代码的任意位置初始化和调用,是在第一次用的它的时候才会初始化。
• init 函数:适用于程序启动时的初始化 ,确保在主函数执行前完成初始化任务。比如:日志配置初始化 ,在程序启动时配置日志文件和输出。
• sync.Once:适用于延迟初始化且需确保在并发环境下只执行一次的初始化任务 。比如:数据库连接池初始化 ,确保数据库连接池在第一次使用时初始化,并在并发环境下只初始化一次。
sync.Lock
说到并发编程,就不得不谈一个老生常谈的问题,那就是资源竞争,也就是我们要讲的并发安全。因为一旦开启了多个goroutine去处理问题,那么这些goroutine就有可能在同一时间操作同一个系统资源,比如同一个变量,同一份文件等等,这里我们如果不加控制的话,可能会出现并发安全问题,在go语言中,有两种方式来控制并发安全,锁和原子操作
举个例子,看下面代码
go
package main
import (
"fmt"
"sync"
)
var (
num int
wg = sync.WaitGroup{}
)
func add() {
defer wg.Done()
num += 1
}
func main() {
var n = 10 * 10 * 10 * 10
wg.Add(n)
for i := 0; i < n; i++ {
// 启动n个goroutine去累加num
go add()
}
// 等待所有goroutine执行完毕
wg.Wait()
// 不出意外的话,num应该等于n,但是,但是,但是实际上不一致!
fmt.Println(num == n)
}运行结果:
go
false我们用n(这里是10000,可以自行修改,尽量数字大一点)个goroutine去给num做累加,最后并num并不等于n,这就是并发问题,同时有多个goroutine都在对num做+1操作,但是后一个并不是在前一次执行完的基础之上运行的,可能两次运行num的初始相同,这样前一个num+1的结果就被后一个覆盖了,看起来好像只做了一个加法。为了避免类似的并发安全问题,我们一般会采用下面两种方式处理,在go语言中并发相关的都在sync包下面。
锁
互斥锁 Mutex
互斥锁是一种最常用的控制并发安全的方式,它在同一时间只允许一个goroutine对共享资源进行访问。
互斥锁的声明方式如下:
go
var lock sync.Mutex互斥锁有两个方法
go
func (m *Mutex) Lock() // 加锁
func (m *Mutex) Unlock() // 解锁一个互斥锁只能同时被一个goroutine锁定,其它goroutine将阻塞直到互斥锁被解锁才能加锁成功
sync.Mutex在使用的时候要注意:对一个未锁定的互斥锁解锁会产生运行时错误
对上面的例子稍作修改,加上互斥锁:
go
package main
import (
"fmt"
"sync"
)
var (
num int
wg = sync.WaitGroup{}
// 我们用锁来保证num的并发安全
mu = sync.Mutex{}
)
func add() {
mu.Lock()
defer wg.Done()
num += 1
mu.Unlock()
}
func main() {
var n = 10 * 10 * 10 * 10
wg.Add(n)
for i := 0; i < n; i++ {
// 启动n个goroutine去累加num
go add()
}
// 等待所有goroutine执行完毕
wg.Wait()
fmt.Println(num == n)
}运行结果:
go
true我们可以自行修改n的值,在我们能开启足够多的goroutine的情况下,他结果一定会是true
本例使用了前面介绍的sync.WaitGroup来等待所有协程执行结束并且在add函数里使用了互斥锁来保证num += 1操作的并发安全,但是注意不要忘了用mu.Unlock来进行解锁,否则其他goroutine将一直等待加锁造成阻塞。
读写锁 RWMutex
顾名思义,读写锁就是将读操作和写操作分开,可以分别对读和写进行加锁,一般用在大量读操作,少量写操作的情况
方法如下:
go
func (rw *RWMutex) Lock() // 对写锁加锁
func (rw *RWMutex) Unlock() // 对写锁解锁
func (rw *RWMutex) RLock() // 对读锁加锁
func (rw *RWMutex) RUnlock() // 对读锁解锁读写锁的使用遵循以下几个法则:
- 同时只能有一个 goroutine 能够获得写锁定。
- 同时可以有任意多个 goroutine 获得读锁定。
- 同时只能存在写锁定或读锁定(读和写互斥)。
通俗理解就是可以多个goroutine同时读,但是只有一个goroutine能写,共享资源要么在被一个或多个goroutine读取,要么在被一个goroutine写入 ,读写不能同时进行
有了RWMutex,我们什么情况下还使用Mutex呢
答案是:当我们所有的操作几乎是写的时候,就可以选择使用Mutex
读写锁示例:
go
package main
import (
"fmt"
"sync"
"time"
)
var cnt = 0
func main() {
var mr sync.RWMutex
for i := 1; i <= 3; i++ {
go write(&mr, i)
}
for i := 1; i <= 3; i++ {
go read(&mr, i)
}
time.Sleep(time.Second)
fmt.Println("final count:", cnt)
}
func read(mr *sync.RWMutex, i int) {
fmt.Printf("goroutine%d reader start\n", i)
mr.RLock()
fmt.Printf("goroutine%d reading count:%d\n", i, cnt)
time.Sleep(time.Millisecond)
fmt.Printf("goroutine%d reader over\n", i)
mr.RUnlock()
}
func write(mr *sync.RWMutex, i int) {
fmt.Printf("goroutine%d writer start\n", i)
mr.Lock()
cnt++
fmt.Printf("goroutine%d writing count:%d\n", i, cnt)
time.Sleep(time.Millisecond)
fmt.Printf("goroutine%d writer over\n", i)
mr.Unlock()
}运行结果:
bash
root@GoLang:~/proj/goforjob# go run main.go
goroutine3 reader start
goroutine3 reading count:0
goroutine1 writer start
goroutine2 writer start
goroutine3 writer start
goroutine1 reader start
goroutine2 reader start
goroutine3 reader over
goroutine1 writing count:1
goroutine1 writer over
goroutine1 reading count:1
goroutine2 reading count:1
goroutine2 reader over
goroutine1 reader over
goroutine2 writing count:2
goroutine2 writer over
goroutine3 writing count:3
goroutine3 writer over
final count: 3简单分析:首先goroutine3开始加了读锁,开始读取,读到count的值为0,然后goroutine1尝试写入,goroutine2尝试写入,但是都被阻塞,因为goroutine3加了读锁,不能再加写锁,在第8行goroutine3读取完毕之后,goroutine1拿抢到了锁,加了写锁,写完释放写锁之后,goroutine1和goroutine2同时加了读锁,读到count的值为1。可以看到读写锁是互斥的 ,写与锁是互斥的 ,读锁锁可以一起加。
死锁
提到锁,就有一个绕不开的话题:死锁。死锁就是一种状态,当两个或以上的goroutine在执行过程中,因争夺共享资源处在互相等待的状态,如果没有外部干涉将会一直处于这种阻塞状态,我们称这时的系统发生了死锁
死锁场景
Lock/Unlock不成对
这类情况最常见的场景就是对锁进行拷贝使用
go
package main
import (
"fmt"
"sync"
)
func main() {
var mu sync.Mutex
mu.Lock()
defer mu.Unlock()
copyMutex(mu)
}
func copyMutex(mu sync.Mutex) {
mu.Lock()
defer mu.Unlock()
fmt.Println("ok")
}运行结果:
go
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0x414db7?, 0x88?, 0x56eaa0?)
/usr/local/go/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc000088020)
/usr/local/go/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/usr/local/go/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/usr/local/go/src/sync/mutex.go:46
main.copyMutex({{}, {0x1, 0x0}})
/root/proj/goforjob/main.go:16 +0x5e
main.main()
/root/proj/goforjob/main.go:12 +0x85
exit status 2会报死锁,为什么呢?这里mu sync.Mutex当作参数传入到函数copyMutex,锁进行了拷贝,不是原来的锁变量了,那么一把新的锁,在执行mu.Lock()的时候应该没问题。这就是要注意的地方,如果将带有锁结构的变量赋值给其他变量,锁的状态会复制 。所以多复制后的新的锁拥有了原来的锁状态,那么在copyMutex函数内执行mu.Lock()的时候会一直阻塞,因为外层的main函数已经Lock()了一次,但是并没有机会Unlock(),导致内层函数会一直等待Lock(),而外层函数一直等待Unlock(),这样就造成了死锁
这个例子,不管是值传递,还是地址传递,都会发生死锁。指针传递就是继续加锁,值拷贝也是在对有锁的状态,进行重复加锁
所以在使用锁的时候,我们应当尽量避免锁拷贝,并且保证Lock()和Unlock()成对出现,没有成对出现容易会出现死锁的情况,或者是Unlock一个未加锁的Mutex而导致产生运行时错误。
尽量养成如下使用习惯
go
mu.Lock()
defer mu.Unlock()循环等待
另一个容易造成死锁的场景就是循环等待,A等B,B等C,C等A,循环等待
go
package main
import (
"sync"
"time"
)
func main() {
var mu1, mu2 sync.Mutex
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
mu1.Lock()
defer mu1.Unlock()
// time.Sleep就是避免就是避免一个协程先把两个锁都拿了
time.Sleep(1 * time.Second)
mu2.Lock()
defer mu2.Unlock()
}()
go func() {
defer wg.Done()
mu2.Lock()
defer mu2.Unlock()
time.Sleep(1 * time.Second)
mu1.Lock()
defer mu1.Unlock()
}()
wg.Wait()
}运行结果:
go
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [sync.WaitGroup.Wait]:
sync.runtime_SemacquireWaitGroup(0xc000068040?, 0x80?)
/usr/local/go/src/runtime/sema.go:114 +0x2e
sync.(*WaitGroup).Wait(0xc0000120c0)
/usr/local/go/src/sync/waitgroup.go:206 +0x85
main.main()
/root/proj/goforjob/main.go:31 +0x10f
goroutine 6 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0x0?, 0x1?, 0xc000046740?)
/usr/local/go/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0000120b8)
/usr/local/go/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/usr/local/go/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/usr/local/go/src/sync/mutex.go:46
main.main.func1()
/root/proj/goforjob/main.go:19 +0xc7
created by main.main in goroutine 1
/root/proj/goforjob/main.go:13 +0xa5
goroutine 7 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0x0?, 0x0?, 0x0?)
/usr/local/go/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0000120b0)
/usr/local/go/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/usr/local/go/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/usr/local/go/src/sync/mutex.go:46
main.main.func2()
/root/proj/goforjob/main.go:28 +0xc7
created by main.main in goroutine 1
/root/proj/goforjob/main.go:23 +0x105
exit status 2死锁了,代码很简单,两个goroutine,一个goroutine先锁mu1,再锁mu2,另一个goroutine先锁mu2,再锁mu1 ,但是在它们进行第二次加锁操作的时候,彼此等待对方释放锁,这样就造成了循环等待,一直阻塞,形成死锁。
sync.Map
go语言内置的Map并不是并发安全的,在多个goroutine同时操作map的时候,会有并发问题
具体看下面例子
go
package main
import (
"fmt"
"strconv"
"sync"
)
var m = make(map[string]int)
func getVal(key string) int {
return m[key]
}
func setVal(key string, value int) {
m[key] = value
}
func main() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func(num int) {
defer wg.Done()
key := strconv.Itoa(num)
setVal(key, num)
fmt.Printf("key=:%v,val=:%v\n", key, getVal(key))
}(i)
}
wg.Wait()
}运行结果:
go
root@GoLang:~/proj/goforjob# go run main.go
key=:9,val=:9
fatal error: concurrent map writes
key=:3,val=:3
key=:0,val=:0
key=:1,val=:1
key=:4,val=:4
key=:2,val=:2
key=:5,val=:5
key=:7,val=:7
key=:8,val=:8
goroutine 13 [running]:
internal/runtime/maps.fatal({0x4c18ad?, 0x0?})
/usr/local/go/src/runtime/panic.go:1046 +0x18
main.setVal(...)
/root/proj/goforjob/main.go:16
main.main.func1(0x6)
/root/proj/goforjob/main.go:26 +0x8d
created by main.main in goroutine 1
/root/proj/goforjob/main.go:23 +0x45
goroutine 1 [sync.WaitGroup.Wait]:
sync.runtime_SemacquireWaitGroup(0xc000010120?, 0x80?)
/usr/local/go/src/runtime/sema.go:114 +0x2e
sync.(*WaitGroup).Wait(0xc0000120b0)
/usr/local/go/src/sync/waitgroup.go:206 +0x85
main.main()
/root/proj/goforjob/main.go:30 +0xe5
exit status 2
root@GoLang:~/proj/goforjob# 程序报错了,说明map不能同时被多个goroutine读写
这里并不是每次执行都会遇到程序报错的,只有当两个goroutine刚好同时对原生map进行读写操作时才会遇到,属于偶现的情况,只有当并发量大的时候才会频繁出现。
要解决map的并发写问题一种方式使用我们前面学到的对map加锁,这样就可以了
go
package main
import (
"fmt"
"strconv"
"sync"
)
var m = make(map[string]int)
var mu sync.Mutex
func getVal(key string) int {
return m[key]
}
func setVal(key string, value int) {
m[key] = value
}
func main() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func(num int) {
defer func() {
wg.Done()
mu.Unlock()
}()
key := strconv.Itoa(num)
mu.Lock()
setVal(key, num)
fmt.Printf("key=:%v,val=:%v\n", key, getVal(key))
}(i)
}
wg.Wait()
}运行结果:
go
key=:9,val=:9
key=:4,val=:4
key=:0,val=:0
key=:1,val=:1
key=:2,val=:2
key=:3,val=:3
key=:6,val=:6
key=:7,val=:7
key=:5,val=:5
key=:8,val=:8另外一种方式是使用sync包中提供的一个开箱即用的并发安全版map-sync.Map,在 Go 1.9 引入。
sync.Map 不用初始化就可以使用,同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
具体使用方法看示例:
go
package main
import (
"fmt"
"sync"
)
func main() {
// 零值可直接使用(不需要 make),这和内置 map 不同:内置 map 不 make 就会 panic
var m sync.Map
// 1. 写入
m.Store("name", "zhangsan")
m.Store("age", 18)
// 2. 读取
// Load返回的是接口,所以下面要使用接口断言 age.(int)
age, _ := m.Load("age")
fmt.Println(age.(int))
// 3. 遍历
// Range(f) 会对 map 中的每个键值对调用一次回调函数 f(key, value)
// 回调函数返回 bool:true:继续遍历下一个 ;false:停止遍历
m.Range(func(key, value any) bool {
fmt.Printf("key is:%v, val is:%v\n", key, value)
return true
})
// 4. 删除
m.Delete("age")
age, ok := m.Load("age")
fmt.Println(age, ok)
// 5. 读取或写入
// LoadOrStore(key, value) 的行为是:
// 如果 key 已存在:返回"已有的值",并且不会覆盖;同时 loaded == true
// 如果 key 不存在:把你给的 value 写进去,再返回这个新写入的值;同时 loaded == false
m.LoadOrStore("name", "zhangsan")
name, _ := m.Load("name")
fmt.Println(name)
}运行结果:
go
18
key is:name, val is:zhangsan
key is:age, val is:18
<nil> false
zhangsan这段代码使用了 sync.Map 的 Range 方法来遍历 sync.Map 中的所有键值对。Range 方法接受一个函数作为参数,该函数会被调用多次,每次传入一个键值对。
在这个例子中,传入的函数为:
go
func(key, value any) bool {
fmt.Printf("key is:%v, val is:%v\n", key, value)
return true
}这个函数接受两个参数:key 和 value,分别表示当前遍历到的键和值。它会输出当前遍历到的键值对,并返回 true 表示继续遍历。
当调用 m.Range(...) 时,Range 方法会遍历 sync.Map 中的所有键值对,并对每个键值对调用传入的函数。在这个例子中,它会输出所有键值对。
- 通过store方法写入两个键值对
- 读取key为age的值,读出来age为18
- 通过range方法遍历map的key和value
- 删除key为age的键值对,删除完之后,再次读取age,age为空,ok为false表示map里没有这个key
- LoadOrStore尝试读取key为name的值,读取不到就写入键值对name-zhangsan,能读取到就返回原来map里的name对应的值
注意:sync.Map 没有提供获取 map 数量的方法,需要我们在对sync.Map进行遍历时自行计算,sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能
sync/Atomic
除了前面介绍的锁mutex以外,还有一种解决并发安全的策略,就是原子操作。所谓原子操作就是这一系列的操作在cpu上执行是一个不可分割的整体 ,显然要么全部执行,要么全部不执行,不会受到其他操作的影响,也就不会存在并发问题。
atomic和mutex的区别
使用方式:通常mutex用于保护一段执行逻辑 ,而atomic主要是对变量进行操作
atomic只能保护操作某个变量的原子性
而mutex是保护一段临界区代码,各有用处
底层实现:Go 的 sync.Mutex 主要是由 Go runtime 实现的,不是直接"由操作系统调度器实现",而atomic操作有底层硬件指令支持,保证在cpu上执行不中断。所以atomic的性能也能随cpu的个数增加线性提升
atomic提供的方法:
go
func AddT(addr *T, delta T)(new T)
func StoreT(addr *T, val T)
func LoadT(addr *T) (val T)
func SwapT(addr *T, new T) (old T)
func CompareAndSwapT(addr *T, old, new T) (swapped bool)T的类型是 int32、int64、uint32、uint64 和 uintptr 中的任意一种
这里就不一一演示各个方法了,以AddT方法为例简单看一个例子
go
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var sum int32 = 0
var wg sync.WaitGroup
for range 100 {
wg.Add(1)
go func() {
defer wg.Done()
atomic.AddInt32(&sum, 1)
}()
}
wg.Wait()
fmt.Printf("sum is %d\n", sum)
}100个goroutine,每个goroutine都对sum+1,最后结果为100。
atomic.value
上面展示的AddT、StoreT等方法都是针对的基本数据类型做的操作,假设想对多个变量进行同步保护,即假设想对一个struct这样的复合类型用原子操作,也是支持的吗?也可以做支持,go语言里的atomic.value支持任意一种接口类型进行原子操作,且提供了 Load、Store、Swap 和 CompareAndSwap 四种方法:
- Load:func (v *Value) Load() (val any),从value读出数据
- Store:func (v *Value) Store (val any),向value写入数据
- Swap:func (v *Value) Swap(new any) (old any),用new交换value中存储的数据,返回value原来存储的旧数据
- CompareAndSwap:func (v *Value) CompareAndSwap(old, new any) (swapped bool),比较value中存储的数据和old是否相同,相同的话,将value中的数据替换为new
代码示例
go
package main
import (
"fmt"
"sync/atomic"
)
type Student struct {
Name string
Age int
}
func main() {
st1 := Student{
Name: "zhangsan",
Age: 18,
}
st2 := Student{
Name: "lisi",
Age: 19,
}
st3 := Student{
Name: "wangwu",
Age: 20,
}
var v atomic.Value
v.Store(st1)
fmt.Println(v.Load().(Student))
old := v.Swap(st2)
fmt.Printf("after swap: v=%v\n", v.Load().(Student))
fmt.Printf("after swap: old=%v\n", old)
swapped := v.CompareAndSwap(st1, st3) // v中存储的和st1不同,交换失败
fmt.Println("compare st1 and v\n", swapped, v)
swapped = v.CompareAndSwap(st2, st3) // v中存储的和st2相同,交换成功,v中变为st3
fmt.Println("compare st2 and v\n", swapped, v)
}运行结果:
go
{zhangsan 18}
after swap: v={lisi 19}
after swap: old={zhangsan 18}
compare st1 and v
false {{lisi 19}}
compare st2 and v
true {{wangwu 20}}sync.pool
sync.Pool是在sync包下的一个内存池组件 ,用来实现对象的复用,避免重复创建相同的对象,造成频繁的内存分配和gc ,以达到提升程序性能的目的。虽然池子中的对象可以被复用,但是sync.Pool并不会永久保存这个对象,池子中的对象会在一定时间后被gc回收 ,这个时间是随机的。所以,用sync.Pool来持久化存储对象是不可取的。
另外,sync.Pool本身是并发安全的,支持多个goroutine并发的往sync.Pool存取数据
sync.pool使用方法
关于sync.Pool的使用,一般是通过三个方法来完成的

下面通过例子看一下sync.Pool的使用方式
go
package main
import (
"fmt"
"sync"
)
type Student struct {
Name string
Age int
}
func main() {
pool := sync.Pool{
New: func() interface{} {
return &Student{
Name: "zhangsan",
Age: 18,
}
},
}
st := pool.Get().(*Student)
println(st.Name, st.Age)
fmt.Printf("addr is %p\n", st)
pool.Put(st)
st1 := pool.Get().(*Student)
println(st1.Name, st1.Age)
fmt.Printf("addr1 is %p\n", st1)
}程序输出:
go
zhangsan 18
addr is 0x140000a0018
zhangsan 18
addr1 is 0x140000a0018在程序中,首先初始化一个sync.Pool对象,初始化里面的New方法,用于创建对象,这里是返回一个Student类型的指针 。第一次调用 pool.Get().(*Student) 的时候,由于池子内没有对象,所以会通过New方法创建一个,注意 pool.Get() 返回的是一个any,所以我们需要断言成 *Student 类型,在我们使用完,打印出Name和Age之后,再调用Put方法,将这个对象放回到池子内 ,后面我们紧接着又调用 pool.Get() 取对象,可以看到两次取出的对象地址是同一个,说明是同一个对象,表明sync.Pool有缓存对象的功能。
Get 方法从 Pool 中选择一个任意元素,将其从 Pool 中移除,并返回给调用者
注意(Reset)
我们在第一次 pool.Get() 取出 *Student 对象打印完地址之后,put进池子的时候没有进行一个Reset的过程,这里是因为我们取出 *Student 对象之后,仅仅是读取里面的字段,并没有修改操作,假设我们有修改操作,那么这里就需要在 pool.Put(st) 之前执行Reset,将对象的值复原 ,如果不这样做,那么下一次 pool.Get() 取出的 *Student 对象就不是我们希望复用的初始对象
假设我们对 *Student 做修改
go
package main
import (
"fmt"
"sync"
)
type Student struct {
Name string
Age int
}
func main() {
pool := sync.Pool{
New: func() any {
return &Student{
Name: "zhangsan",
Age: 18,
}
},
}
st := pool.Get().(*Student)
println(st.Name, st.Age)
fmt.Printf("addr is %p\n", st)
// 修改
st.Name = "lisi"
st.Age = 20
// 回收
pool.Put(st)
st1 := pool.Get().(*Student)
println(st1.Name, st1.Age)
fmt.Printf("addr1 is %p\n", st1)
}程序输出:
go
zhangsan 18
addr is 0x1400000c030
lisi 20
addr1 is 0x1400000c030可以看到,我们第二次取出的对象虽然和第一次是同一个,地址相同,但是对象的字段却发生了变化,不是我们初始化的对象了,我们想要一直复用一个相同的对象的话,显然这里有问题。所以,我们需要在 pool.Put(st) 回收对象之前,进行对象的Reset操作,将对象值复原 ,同时在每次我们 pool.Get() 取出完对象使用完毕之后,也不要忘了调用 pool.Put 方法把对象再次放入对象池,以便对象能够复用。
sync.pool使用场景
- sync.pool主要是通过对象复用来降低gc带来的性能损耗,所以在高并发场景下,由于每个goroutine都可能过于频繁的创建一些大对象,造成gc压力很大。所以在高并发业务场景下出现 GC 问题时,可以使用sync.Pool减少 GC 负担
- sync.pool不适合存储带状态的对象,比如socket连接、数据库连接等,因为里面的对象随时可能会被gc回收释放掉
- 不适合需要控制缓存对象个数的场景,因为Pool池里面的对象个数是随机变化的,因为池子里的对象是会被gc的,且释放时机是随机的
select是什么
select是go语言层面提供的一种多路复用机制 ,用于检测当前goroutine连接的多个channel是否有数据准备完毕 ,可用于读或写
select 用于在多个 channel 发送/接收操作之间进行选择:若有 case 就绪则执行其中一个;若多个 case 同时就绪则任选一个执行 ;若都未就绪且没有 default 则阻塞,否则执行 default。
IO多路复用
看到select,很自然的会联想到linux提供的io多路复用模型,select、poll、epoll,IO复用主要用于提升程序处理io事件的性能。go语言中的select与linux中的select有一定得区别。
操作系统中的IO多路复用简单理解就就是用一个或者是少量线程处理多个IO事件。
简单对比一下传统的阻塞IO与IO多路复用
传统阻塞IO:
对于每一个网络IO事件,操作系统都会起一个线程去处理,在IO事件没准备好的时候,当前线程就会一直阻塞。
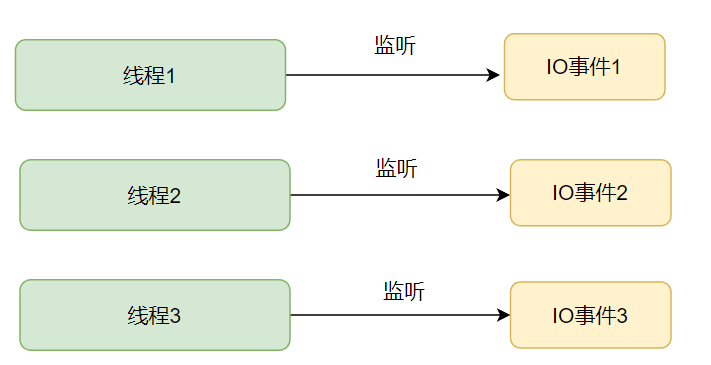
- 优点:逻辑简单,在阻塞等待期间线程会挂起,不会占用 CPU 资源。
- 缺点:每个连接需要独立的线程单独处理 ,当并发请求量大时为了维护程序,内存、线程切换开销较大
IO多路复用的基本原理如下图所示:
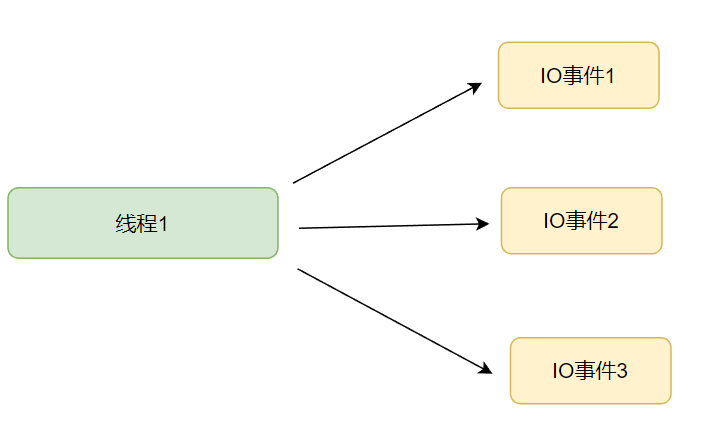
- 优点:通过复用一个线程处理了多个IO事件,无需对额外过多的线程维护管理,资源和效率上都获得了提升
- 缺点:当连接数较小时效率相比多线程+阻塞 I/O 模型效率较低
Go语言的select语句,是用来起一个goroutine监听多个Channel的读写事件,提高从多个Channel获取信息的效率,相当于也是单线程处理多个IO事件,其思想基本相同。
I/O 多路复用的优势在于高效地处理大量连接,因为它避免了为每个连接创建线程的高成本 。当连接数较少时,这种优势不明显,反而因其复杂性导致效率低于简单的多线程+阻塞 I/O 模型 。比如多路复用模型需要维护事件循环,解析事件并分发到具体的处理逻辑都很复杂,而多线程模型可以充分利用系统线程调度机制,每个线程独占一个连接,系统资源利用率在连接数少时基本保持低负载状态
select用法
select的基本使用模式如下:
go
select {
case <- channel1: // 如果从channel1读取数据成功,执行case语句
do ...
case channel2 <- 1: // 如果向channel2写入数据成功,执行case语句
do ...
default: // 如果上面都没有成功,进入default处理流程
do ...
}可以看到,select的用法形式类似于switch,但是区别于switch的是,select每个case的表达式必须都是channel的读写操作 ,select通过多个case语句监听多个channel的读写操作是否准备好,可以执行,其中任何一个case可以执行了则选择该case语句执行,如果没有可以执行的case,则执行default语句,如果没有default,则当前goroutine会阻塞。
空select永久阻塞
当一个select中什么语句都没有,没有任何case,将会永久阻塞
go
package main
func main() {
select {
}
}运行结果
go
fatal error: all goroutines are asleep - deadlock!程序因为select语句导致永久阻塞 ,当前goroutine阻塞之后,由于go语言自带死锁检测机制,发现当前goroutine永远不会被唤醒,会报上述死锁错误
没有default且case无法执行的select永久阻塞
看下面示例
go
package main
import (
"fmt"
)
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
select {
case <-ch1:
fmt.Printf("received from ch1")
case num := <-ch2:
fmt.Printf("num is: %d", num)
}
}运行结果:
go
fatal error: all goroutines are asleep - deadlock!程序中select从两个channel,ch1和ch2中读取数据,但是两个channel都没有数据,且没有goroutine往里面写数据,所以不可能读到数据,这两个case永远无法执行到,select也没有default,所以会出现永久阻塞,报死锁。
有单一case和default的select
go
package main
import (
"fmt"
)
func main() {
ch := make(chan int, 1)
select {
case <-ch:
fmt.Println("received from ch")
default:
fmt.Println("default!!!")
}
}运行结果:
go
default!!!执行到select语句的时候,由于ch中没有数据,且没有goroutine往channel中写数据,所以不可能执行到,就会执行default语句,打印出default!!!
有多个case和default的select
go
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
go func() {
time.Sleep(time.Second)
for i := 0; i < 3; i++ {
select {
case v := <-ch1:
fmt.Printf("Received from ch1, val = %d\n", v)
case v := <-ch2:
fmt.Printf("Received from ch2, val = %d\n", v)
default:
fmt.Println("default!!!")
}
time.Sleep(time.Second)
}
}()
ch1 <- 1
time.Sleep(time.Second)
ch2 <- 2
time.Sleep(4 * time.Second)
}运行结果:
go
Received from ch1, val = 1
Received from ch2, val = 2
default!!!主goroutine中向后往管道ch1和ch2中发送数据,在子goroutine中执行两个select,可以看到,在执行select的时候,那个case准备好了就会执行当下case的语句,最后没有数据可接收了,没有case可以执行,则执行default语句。
这里注意:当多个case都准备好了的时候,会随机选择一个执行
go
package main
import (
"fmt"
)
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
ch1 <- 5
ch2 <- 6
select {
case v := <-ch1:
fmt.Printf("Received from ch1, val = %d\n", v)
case v := <-ch2:
fmt.Printf("Received from ch2, val = %d\n", v)
default:
fmt.Println("default!!!")
}
}运行结果:
go
Received from ch2, val = 6多次执行,2个case都有可能打印,这就是select选择的随机性。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!