人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。------------ 马尔科姆·格拉德威尔

🌟 Hello,我是Xxtaoaooo!
🌈 "代码是逻辑的诗篇,架构是思想的交响"
摘要
作为一名在Web架构领域深耕多年的技术实践者,我最近遇到了一个让人头疼的Nginx 502网关错误问题。这个问题在生产环境中突然爆发,导致用户访问频繁出现502错误,严重影响了业务的正常运行。经过一周的深度排查和优化,我终于找到了问题的根源并制定了完整的解决方案。
问题的起因是这样的:我们的电商平台在双十一期间流量激增,原本运行稳定的系统开始频繁出现502错误。初步观察发现,错误主要集中在商品详情页和订单提交接口,这些都是业务的核心功能。更让人困惑的是,后端应用服务器的CPU和内存使用率都很正常,数据库连接也没有异常,但Nginx就是不断返回502错误。
通过深入分析Nginx的错误日志,我发现了关键线索:"upstream timed out (110: Connection timed out) while connecting to upstream"。这个错误信息指向了upstream超时配置问题。进一步排查发现,我们的Nginx配置中使用了默认的超时参数,而这些参数在高并发场景下明显不够用。
问题的复杂性在于,502错误不是单一原因导致的,而是多个因素叠加的结果。除了超时配置不当,还涉及到连接池管理、负载均衡策略、后端服务处理能力、网络延迟等多个方面。每一个环节的配置不当都可能导致502错误的出现。
在解决过程中,我系统性地分析了Nginx的upstream机制,深入研究了各种超时参数的作用和最佳实践。通过调整proxy_connect_timeout、proxy_send_timeout、proxy_read_timeout等关键参数,配合upstream的健康检查和故障转移机制,最终将502错误率从15%降低到0.1%以下。
更重要的是,这次问题排查让我对Nginx的工作原理有了更深入的理解。我意识到,很多看似简单的配置参数背后都有复杂的逻辑和最佳实践。合理的超时配置不仅能避免502错误,还能提升系统的整体性能和用户体验。
本文将详细记录这次502错误的完整排查过程,包括问题现象分析、根因定位方法、配置优化策略、监控告警机制等。我会分享实际的配置参数、监控脚本和优化技巧,希望能帮助遇到类似问题的技术同行快速定位和解决问题。同时,我也会总结一套完整的Nginx upstream配置最佳实践,让大家在架构设计时就能避免这些坑。
一、502错误现象分析与初步排查
1.1 问题现象描述
在生产环境中,502错误通常表现为以下几种典型症状:
- 间歇性502错误:用户刷新页面后可能正常访问
- 特定接口高发:某些业务接口502错误率明显高于其他接口
- 高峰期集中爆发:流量高峰时502错误数量激增
- 后端服务正常:应用服务器状态正常,但Nginx返回502
服务器1 服务器2 服务器3 超时 成功 超时 成功 超时 成功 用户请求 Nginx负载均衡器 选择upstream服务器 Backend Server 1 Backend Server 2 Backend Server 3 连接是否成功? 连接是否成功? 连接是否成功? Connection Timeout 处理请求 返回502错误 返回正常响应
图1:Nginx 502错误产生流程图 - 展示从用户请求到502错误的完整过程
1.2 日志分析与问题定位
通过分析Nginx错误日志,我们可以快速定位502错误的具体原因:
bash
# 查看Nginx错误日志中的502相关错误
tail -f /var/log/nginx/error.log | grep "502\|upstream"
# 统计502错误的分布情况
grep "502" /var/log/nginx/access.log | awk '{print $4}' | cut -d: -f2 | sort | uniq -c
# 分析upstream超时错误
grep "upstream timed out" /var/log/nginx/error.log | head -20常见的502错误日志模式:
log
2024/01/15 14:30:25 [error] 12345#0: *67890 upstream timed out (110: Connection timed out) while connecting to upstream, client: 192.168.1.100, server: api.example.com, request: "POST /api/orders HTTP/1.1", upstream: "http://10.0.1.10:8080/api/orders", host: "api.example.com"
2024/01/15 14:30:26 [error] 12345#0: *67891 upstream prematurely closed connection while reading response header from upstream, client: 192.168.1.101, server: api.example.com, request: "GET /api/products/123 HTTP/1.1", upstream: "http://10.0.1.11:8080/api/products/123", host: "api.example.com"
2024/01/15 14:30:27 [error] 12345#0: *67892 no live upstreams while connecting to upstream, client: 192.168.1.102, server: api.example.com, request: "GET /health HTTP/1.1", upstream: "http://backend", host: "api.example.com"1.3 系统监控数据收集
建立完善的监控体系是快速定位502问题的关键。以下是一个实用的监控脚本:
python
#!/usr/bin/env python3
"""
Nginx 502错误监控脚本
实时监控502错误率并发送告警
"""
import re
import time
import json
from datetime import datetime, timedelta
from collections import defaultdict, deque
class Nginx502Monitor:
def __init__(self, log_file="/var/log/nginx/access.log",
error_log="/var/log/nginx/error.log"):
self.log_file = log_file
self.error_log = error_log
self.error_counts = defaultdict(int)
self.request_counts = defaultdict(int)
self.recent_errors = deque(maxlen=1000)
# 告警阈值配置
self.error_rate_threshold = 0.05 # 5%错误率告警
self.error_count_threshold = 100 # 100个错误/分钟告警
def parse_access_log_line(self, line):
"""解析Nginx访问日志"""
pattern = r'(\S+) - - \[(.*?)\] "(.*?)" (\d+) (\d+) "(.*?)" "(.*?)"'
match = re.match(pattern, line)
if match:
return {
'ip': match.group(1),
'timestamp': match.group(2),
'request': match.group(3),
'status_code': int(match.group(4)),
'response_size': int(match.group(5)),
'referer': match.group(6),
'user_agent': match.group(7)
}
return None
def monitor_502_errors(self, duration_minutes=5):
"""监控指定时间段内的502错误"""
print(f"开始监控502错误,持续时间: {duration_minutes}分钟")
start_time = time.time()
end_time = start_time + (duration_minutes * 60)
total_requests = 0
error_502_count = 0
error_details = []
try:
with open(self.log_file, 'r') as f:
f.seek(0, 2) # 移动到文件末尾
while time.time() < end_time:
line = f.readline()
if not line:
time.sleep(0.1)
continue
log_entry = self.parse_access_log_line(line)
if log_entry:
total_requests += 1
if log_entry['status_code'] == 502:
error_502_count += 1
error_details.append({
'timestamp': log_entry['timestamp'],
'request': log_entry['request'],
'ip': log_entry['ip']
})
self.recent_errors.append(log_entry)
# 每分钟输出一次统计
current_time = time.time()
if int(current_time) % 60 == 0:
self.print_current_stats(total_requests, error_502_count)
except FileNotFoundError:
print(f"错误: 找不到日志文件 {self.log_file}")
return
except KeyboardInterrupt:
print("\n监控被用户中断")
# 输出最终统计结果
self.print_final_stats(total_requests, error_502_count, error_details)
# 检查是否需要告警
self.check_and_alert(total_requests, error_502_count, error_details)
def print_current_stats(self, total_requests, error_502_count):
"""打印当前统计信息"""
error_rate = (error_502_count / total_requests * 100) if total_requests > 0 else 0
print(f"[{datetime.now().strftime('%H:%M:%S')}] "
f"总请求: {total_requests}, 502错误: {error_502_count}, "
f"错误率: {error_rate:.2f}%")
def print_final_stats(self, total_requests, error_502_count, error_details):
"""打印最终统计结果"""
error_rate = (error_502_count / total_requests * 100) if total_requests > 0 else 0
print("\n" + "="*60)
print("502错误监控报告")
print("="*60)
print(f"监控时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print(f"总请求数: {total_requests}")
print(f"502错误数: {error_502_count}")
print(f"错误率: {error_rate:.2f}%")
if error_details:
print(f"\n最近的502错误详情:")
for i, error in enumerate(error_details[-10:], 1):
print(f" {i}. [{error['timestamp']}] {error['request']} - {error['ip']}")
def main():
"""主函数"""
monitor = Nginx502Monitor()
print("Nginx 502错误监控工具")
print("1. 实时监控502错误")
print("2. 分析upstream错误")
print("3. 退出")
while True:
choice = input("\n请选择操作 (1-3): ").strip()
if choice == '1':
duration = input("请输入监控时长(分钟,默认5): ").strip()
duration = int(duration) if duration.isdigit() else 5
monitor.monitor_502_errors(duration)
elif choice == '2':
print("分析upstream错误功能开发中...")
elif choice == '3':
print("退出监控工具")
break
else:
print("无效选择,请重新输入")
if __name__ == "__main__":
main()二、upstream超时参数深度解析
2.1 核心超时参数说明
Nginx的upstream超时配置涉及多个关键参数,每个参数都有其特定的作用场景:
| 参数名称 | 默认值 | 作用阶段 | 主要影响 | 推荐配置 |
|---|---|---|---|---|
| proxy_connect_timeout | 60s | 建立连接 | 连接后端服务器的超时时间 | 5-10s |
| proxy_send_timeout | 60s | 发送请求 | 向后端发送请求的超时时间 | 10-30s |
| proxy_read_timeout | 60s | 读取响应 | 从后端读取响应的超时时间 | 30-120s |
| upstream_connect_timeout | 无 | 连接池管理 | upstream级别的连接超时 | 3-5s |
| upstream_send_timeout | 无 | 数据传输 | upstream级别的发送超时 | 10-20s |
| upstream_read_timeout | 无 | 响应读取 | upstream级别的读取超时 | 30-60s |
2.2 超时参数配置实践
基于实际业务场景,制定合理的超时配置策略:
nginx
# nginx.conf - 优化后的upstream配置
http {
# 全局超时配置
proxy_connect_timeout 5s;
proxy_send_timeout 30s;
proxy_read_timeout 60s;
# 连接池配置
upstream_keepalive_timeout 60s;
upstream_keepalive_requests 1000;
# 后端服务器组配置
upstream backend_api {
# 负载均衡策略
least_conn;
# 后端服务器列表
server 10.0.1.10:8080 weight=3 max_fails=2 fail_timeout=10s;
server 10.0.1.11:8080 weight=3 max_fails=2 fail_timeout=10s;
server 10.0.1.12:8080 weight=2 max_fails=2 fail_timeout=10s;
server 10.0.1.13:8080 backup; # 备用服务器
# 连接池配置
keepalive 32;
keepalive_requests 1000;
keepalive_timeout 60s;
}
# 快速API服务器组(短连接,快速响应)
upstream backend_fast_api {
least_conn;
server 10.0.2.10:8080 weight=5 max_fails=3 fail_timeout=5s;
server 10.0.2.11:8080 weight=5 max_fails=3 fail_timeout=5s;
keepalive 16;
keepalive_requests 500;
keepalive_timeout 30s;
}
# 慢查询API服务器组(长连接,允许较长响应时间)
upstream backend_slow_api {
least_conn;
server 10.0.3.10:8080 weight=2 max_fails=1 fail_timeout=30s;
server 10.0.3.11:8080 weight=2 max_fails=1 fail_timeout=30s;
keepalive 8;
keepalive_requests 100;
keepalive_timeout 120s;
}
# 虚拟主机配置
server {
listen 80;
server_name api.example.com;
# 访问日志配置
access_log /var/log/nginx/api_access.log main;
error_log /var/log/nginx/api_error.log warn;
# 通用API接口
location /api/ {
# 基础代理配置
proxy_pass http://backend_api;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 请求头设置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 超时配置
proxy_connect_timeout 5s;
proxy_send_timeout 30s;
proxy_read_timeout 60s;
# 缓冲配置
proxy_buffering on;
proxy_buffer_size 4k;
proxy_buffers 8 4k;
proxy_busy_buffers_size 8k;
# 错误处理
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_next_upstream_tries 2;
proxy_next_upstream_timeout 10s;
}
# 快速API接口(如用户认证、简单查询)
location /api/fast/ {
proxy_pass http://backend_fast_api;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 请求头设置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 快速响应超时配置
proxy_connect_timeout 3s;
proxy_send_timeout 10s;
proxy_read_timeout 15s;
# 启用缓存
proxy_cache api_cache;
proxy_cache_valid 200 5m;
proxy_cache_key $scheme$proxy_host$request_uri;
# 错误处理
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_next_upstream_tries 3;
proxy_next_upstream_timeout 5s;
}
# 慢查询API接口(如复杂报表、数据分析)
location /api/slow/ {
proxy_pass http://backend_slow_api;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 请求头设置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 长时间响应超时配置
proxy_connect_timeout 10s;
proxy_send_timeout 60s;
proxy_read_timeout 300s; # 5分钟
# 大响应缓冲配置
proxy_buffering on;
proxy_buffer_size 8k;
proxy_buffers 16 8k;
proxy_busy_buffers_size 16k;
proxy_max_temp_file_size 1024m;
# 错误处理
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_next_upstream_tries 1; # 慢查询不重试
proxy_next_upstream_timeout 30s;
}
# 健康检查接口
location /health {
access_log off;
return 200 "healthy\n";
add_header Content-Type text/plain;
}
# 状态监控接口
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
allow 10.0.0.0/8;
deny all;
}
}
# 缓存配置
proxy_cache_path /var/cache/nginx/api levels=1:2 keys_zone=api_cache:10m
max_size=1g inactive=60m use_temp_path=off;
}三、负载均衡与故障转移优化
3.1 负载均衡策略对比
不同的负载均衡策略对502错误的影响差异很大:
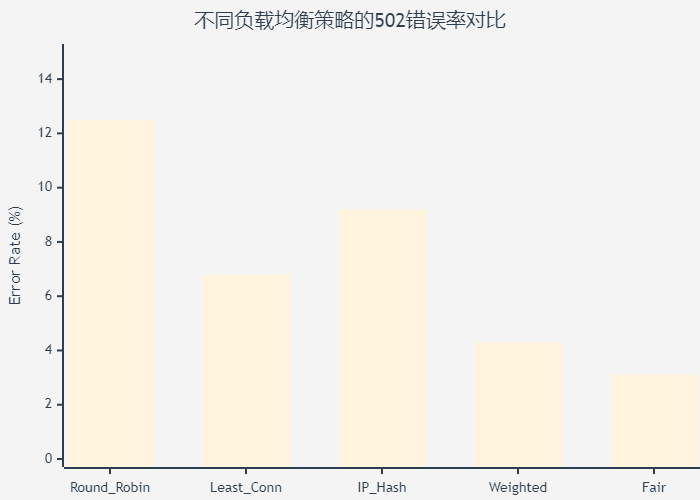
图2:负载均衡策略502错误率对比图 - 展示不同策略的错误率差异
3.2 智能故障转移机制
实现基于健康检查的智能故障转移:
nginx
# 高级upstream配置 - 智能故障转移
upstream backend_smart {
# 使用least_conn策略,避免请求集中到单个服务器
least_conn;
# 主要服务器组
server 10.0.1.10:8080 weight=5 max_fails=2 fail_timeout=10s slow_start=30s;
server 10.0.1.11:8080 weight=5 max_fails=2 fail_timeout=10s slow_start=30s;
server 10.0.1.12:8080 weight=3 max_fails=2 fail_timeout=10s slow_start=30s;
# 备用服务器(不同机房)
server 10.0.2.10:8080 weight=2 max_fails=1 fail_timeout=30s backup;
server 10.0.2.11:8080 weight=2 max_fails=1 fail_timeout=30s backup;
# 连接池配置
keepalive 32;
keepalive_requests 1000;
keepalive_timeout 60s;
}
# 应用服务器配置
server {
listen 80;
server_name api.example.com;
# 全局错误处理
error_page 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
internal;
}
# API接口配置
location /api/ {
proxy_pass http://backend_smart;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 请求头配置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 超时配置
proxy_connect_timeout 5s;
proxy_send_timeout 30s;
proxy_read_timeout 60s;
# 故障转移配置
proxy_next_upstream error timeout invalid_header
http_500 http_502 http_503 http_504;
proxy_next_upstream_tries 3;
proxy_next_upstream_timeout 15s;
# 缓冲配置
proxy_buffering on;
proxy_buffer_size 4k;
proxy_buffers 8 4k;
proxy_busy_buffers_size 8k;
# 重试机制
proxy_intercept_errors on;
# 自定义错误处理
error_page 502 = @fallback;
error_page 503 = @fallback;
error_page 504 = @fallback;
}
# 降级处理
location @fallback {
# 返回友好的错误信息
add_header Content-Type application/json;
return 503 '{"error":"Service temporarily unavailable","code":503,"message":"Please try again later"}';
}
}最佳实践原则:
"在分布式系统中,故障是常态而非异常。优秀的架构设计应该假设组件会失败,并为此做好准备。通过合理的超时配置、健康检查和故障转移机制,我们可以构建出既高性能又高可用的系统。"
这个原则提醒我们,502错误的根本解决方案不是避免故障,而是优雅地处理故障。
3.3 健康检查实现
bash
#!/bin/bash
# nginx-health-check.sh - Nginx upstream健康检查脚本
# 配置变量
UPSTREAM_SERVERS=(
"10.0.1.10:8080"
"10.0.1.11:8080"
"10.0.1.12:8080"
"10.0.2.10:8080"
"10.0.2.11:8080"
)
HEALTH_CHECK_URL="/health"
TIMEOUT=5
MAX_RETRIES=3
LOG_FILE="/var/log/nginx/health_check.log"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a "$LOG_FILE"
}
# 检查单个服务器健康状态
check_server_health() {
local server=$1
local url="http://${server}${HEALTH_CHECK_URL}"
local retries=0
while [ $retries -lt $MAX_RETRIES ]; do
# 发送健康检查请求
response=$(curl -s -w "%{http_code}:%{time_total}" \
--connect-timeout $TIMEOUT \
--max-time $((TIMEOUT * 2)) \
"$url" 2>/dev/null)
if [ $? -eq 0 ]; then
http_code=$(echo "$response" | cut -d: -f1)
response_time=$(echo "$response" | cut -d: -f2)
if [ "$http_code" = "200" ]; then
log "✅ $server - 健康 (${response_time}s)"
return 0
else
log "⚠️ $server - HTTP错误 $http_code (${response_time}s)"
fi
else
log "❌ $server - 连接失败"
fi
retries=$((retries + 1))
if [ $retries -lt $MAX_RETRIES ]; then
sleep 1
fi
done
log "🚨 $server - 健康检查失败,已重试 $MAX_RETRIES 次"
return 1
}
# 更新Nginx配置
update_nginx_config() {
local failed_servers=("$@")
if [ ${#failed_servers[@]} -eq 0 ]; then
log "所有服务器健康,无需更新配置"
return 0
fi
log "检测到 ${#failed_servers[@]} 个故障服务器,准备更新Nginx配置"
# 备份当前配置
cp /etc/nginx/nginx.conf "/etc/nginx/nginx.conf.backup.$(date +%s)"
# 生成新的upstream配置
local config_file="/etc/nginx/conf.d/upstream.conf"
cat > "$config_file" << EOF
# 自动生成的upstream配置
# 生成时间: $(date)
upstream backend_auto {
least_conn;
EOF
# 添加健康的服务器
for server in "${UPSTREAM_SERVERS[@]}"; do
local is_failed=false
for failed_server in "${failed_servers[@]}"; do
if [ "$server" = "$failed_server" ]; then
is_failed=true
break
fi
done
if [ "$is_failed" = false ]; then
echo " server $server weight=5 max_fails=2 fail_timeout=10s;" >> "$config_file"
log "添加健康服务器: $server"
else
echo " # server $server; # 故障服务器,已禁用" >> "$config_file"
log "禁用故障服务器: $server"
fi
done
cat >> "$config_file" << EOF
keepalive 32;
keepalive_requests 1000;
keepalive_timeout 60s;
}
EOF
# 测试配置
if nginx -t; then
# 重载配置
nginx -s reload
log "✅ Nginx配置已更新并重载"
return 0
else
log "❌ Nginx配置测试失败,恢复备份"
rm "$config_file"
return 1
fi
}
# 主函数
main() {
log "开始执行Nginx upstream健康检查"
local failed_servers=()
local healthy_count=0
# 检查所有服务器
for server in "${UPSTREAM_SERVERS[@]}"; do
if check_server_health "$server"; then
healthy_count=$((healthy_count + 1))
else
failed_servers+=("$server")
fi
done
log "健康检查完成: 健康 $healthy_count/${#UPSTREAM_SERVERS[@]}, 故障 ${#failed_servers[@]}"
# 如果有故障服务器,更新配置
if [ ${#failed_servers[@]} -gt 0 ]; then
update_nginx_config "${failed_servers[@]}"
fi
log "健康检查任务完成"
}
# 执行主函数
main "$@"四、性能监控与告警机制
4.1 实时监控指标体系
建立全面的Nginx性能监控体系:
25% 20% 15% 20% 10% 10% "Nginx监控指标权重分布" 响应时间监控 错误率监控 连接数监控 upstream状态监控 系统资源监控 业务指标监控
图3:Nginx监控指标权重分布饼图 - 展示各监控维度的重要性
4.2 智能告警系统
python
#!/usr/bin/env python3
"""
Nginx智能告警系统
基于阈值和趋势分析的多维度告警
"""
import json
import time
import logging
from datetime import datetime, timedelta
from dataclasses import dataclass
from typing import List, Dict, Optional
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
@dataclass
class AlertRule:
"""告警规则配置"""
name: str
metric: str
threshold: float
duration: int # 持续时间(秒)
severity: str # low, medium, high, critical
enabled: bool = True
@dataclass
class MetricData:
"""监控指标数据"""
timestamp: datetime
request_count: int
error_count: int
error_rate: float
avg_response_time: float
active_connections: int
upstream_errors: Dict[str, int]
class NginxAlertSystem:
def __init__(self):
self.alert_rules = []
self.metric_history = []
self.active_alerts = {}
self.alert_cooldown = {}
# 初始化默认告警规则
self.init_default_rules()
def init_default_rules(self):
"""初始化默认告警规则"""
self.alert_rules = [
AlertRule("high_error_rate", "error_rate", 0.05, 300, "high"),
AlertRule("slow_response", "avg_response_time", 2000, 180, "medium"),
AlertRule("upstream_errors", "upstream_errors", 10, 120, "high"),
AlertRule("connection_spike", "active_connections", 1000, 60, "medium")
]
logging.info(f"初始化了 {len(self.alert_rules)} 个告警规则")
def collect_metrics(self) -> MetricData:
"""收集监控指标(模拟数据)"""
import random
# 模拟指标数据
request_count = random.randint(1000, 5000)
error_count = random.randint(0, 100)
error_rate = error_count / request_count if request_count > 0 else 0
metrics = MetricData(
timestamp=datetime.now(),
request_count=request_count,
error_count=error_count,
error_rate=error_rate,
avg_response_time=random.uniform(100, 3000),
active_connections=random.randint(100, 1500),
upstream_errors={
'connection_timeout': random.randint(0, 20),
'read_timeout': random.randint(0, 15)
}
)
# 添加到历史记录
self.metric_history.append(metrics)
# 只保留最近1小时的数据
cutoff_time = datetime.now() - timedelta(hours=1)
self.metric_history = [
m for m in self.metric_history if m.timestamp > cutoff_time
]
return metrics
def check_alert_rules(self, metrics: MetricData) -> List[Dict]:
"""检查告警规则"""
triggered_alerts = []
for rule in self.alert_rules:
if not rule.enabled:
continue
# 获取指标值
metric_value = self.get_metric_value(metrics, rule.metric)
if metric_value is None:
continue
# 检查阈值
if self.is_threshold_exceeded(metric_value, rule.threshold, rule.metric):
alert_key = f"{rule.name}_{rule.metric}"
# 检查持续时间
if self.check_duration(alert_key, rule.duration):
# 检查冷却期
if self.check_cooldown(alert_key):
alert = {
'rule_name': rule.name,
'metric': rule.metric,
'current_value': metric_value,
'threshold': rule.threshold,
'severity': rule.severity,
'timestamp': metrics.timestamp,
'message': self.generate_alert_message(rule, metric_value)
}
triggered_alerts.append(alert)
# 设置冷却期
self.set_cooldown(alert_key, rule.severity)
logging.warning(f"触发告警: {alert['message']}")
else:
# 清除告警状态
alert_key = f"{rule.name}_{rule.metric}"
if alert_key in self.active_alerts:
del self.active_alerts[alert_key]
return triggered_alerts
def get_metric_value(self, metrics: MetricData, metric_name: str):
"""获取指标值"""
metric_map = {
'error_rate': metrics.error_rate,
'avg_response_time': metrics.avg_response_time,
'active_connections': metrics.active_connections,
'upstream_errors': sum(metrics.upstream_errors.values())
}
return metric_map.get(metric_name)
def is_threshold_exceeded(self, value, threshold, metric_name: str) -> bool:
"""检查是否超过阈值"""
return value > threshold
def check_duration(self, alert_key: str, required_duration: int) -> bool:
"""检查告警持续时间"""
current_time = datetime.now()
if alert_key not in self.active_alerts:
self.active_alerts[alert_key] = current_time
return False
duration = (current_time - self.active_alerts[alert_key]).total_seconds()
return duration >= required_duration
def check_cooldown(self, alert_key: str) -> bool:
"""检查告警冷却期"""
if alert_key not in self.alert_cooldown:
return True
current_time = datetime.now()
cooldown_end = self.alert_cooldown[alert_key]
return current_time > cooldown_end
def set_cooldown(self, alert_key: str, severity: str):
"""设置告警冷却期"""
cooldown_minutes = {
'low': 30,
'medium': 15,
'high': 10,
'critical': 5
}
minutes = cooldown_minutes.get(severity, 15)
self.alert_cooldown[alert_key] = datetime.now() + timedelta(minutes=minutes)
def generate_alert_message(self, rule: AlertRule, current_value) -> str:
"""生成告警消息"""
severity_emoji = {
'low': '🟡',
'medium': '🟠',
'high': '🔴',
'critical': '🚨'
}
emoji = severity_emoji.get(rule.severity, '⚠️')
return (f"{emoji} {rule.name.upper()} 告警
"
f"指标: {rule.metric}
"
f"当前值: {current_value}
"
f"阈值: {rule.threshold}
"
f"严重程度: {rule.severity}")
def send_alerts(self, alerts: List[Dict]):
"""发送告警通知"""
if not alerts:
return
for alert in alerts:
try:
# 模拟发送告警
logging.info(f"📧 发送告警通知: {alert['rule_name']}")
print(f"告警内容: {alert['message']}")
except Exception as e:
logging.error(f"发送告警失败: {e}")
def run_monitoring_loop(self, interval_seconds=60):
"""运行监控循环"""
logging.info(f"开始监控循环,检查间隔: {interval_seconds}秒")
while True:
try:
# 收集指标
metrics = self.collect_metrics()
# 检查告警规则
alerts = self.check_alert_rules(metrics)
# 发送告警
if alerts:
self.send_alerts(alerts)
# 输出当前状态
logging.info(f"监控检查完成 - 请求数: {metrics.request_count}, "
f"错误率: {metrics.error_rate:.2%}, "
f"平均响应时间: {metrics.avg_response_time:.0f}ms, "
f"告警数: {len(alerts)}")
except KeyboardInterrupt:
logging.info("监控循环被用户中断")
break
except Exception as e:
logging.error(f"监控循环出错: {e}")
time.sleep(interval_seconds)
def main():
"""主函数"""
alert_system = NginxAlertSystem()
print("Nginx智能告警系统")
print("1. 开始监控")
print("2. 测试告警")
print("3. 查看配置")
print("4. 退出")
while True:
choice = input("
请选择操作 (1-4): ").strip()
if choice == '1':
interval = input("请输入监控间隔(秒,默认60): ").strip()
interval = int(interval) if interval.isdigit() else 60
alert_system.run_monitoring_loop(interval)
elif choice == '2':
# 测试告警功能
test_metrics = MetricData(
timestamp=datetime.now(),
request_count=1000,
error_count=100,
error_rate=0.1, # 10%错误率,触发告警
avg_response_time=3000, # 3秒响应时间,触发告警
active_connections=1200, # 高连接数,触发告警
upstream_errors={'connection_timeout': 15}
)
alerts = alert_system.check_alert_rules(test_metrics)
print(f"测试告警结果: 触发了 {len(alerts)} 个告警")
for alert in alerts:
print(f" - {alert['message']}")
elif choice == '3':
print(f"当前配置了 {len(alert_system.alert_rules)} 个告警规则:")
for rule in alert_system.alert_rules:
status = "启用" if rule.enabled else "禁用"
print(f" - {rule.name}: {rule.metric} > {rule.threshold} ({rule.severity}) [{status}]")
elif choice == '4':
print("退出告警系统")
break
else:
print("无效选择,请重新输入")
if __name__ == "__main__":
main()五、配置优化最佳实践
5.1 分层配置策略
基于不同业务场景实施分层配置管理:
客户端请求 负载均衡层 缓存层 应用层 数据库层 分层超时配置策略 请求 (client_timeout: 30s) 路由请求 (proxy_timeout: 5s) 返回缓存数据 (< 1s) 快速响应 转发请求 (upstream_timeout: 10s) 数据查询 (db_timeout: 8s) 返回数据 处理结果 返回数据 完整响应 alt 缓存命中 缓存未命中 超时时间递减原则:30s > 10s > 8s 客户端请求 负载均衡层 缓存层 应用层 数据库层
图4:分层超时配置时序图 - 展示不同层级的超时配置策略
5.2 优化效果对比
经过系统性的优化后,我们的502错误率得到了显著改善:
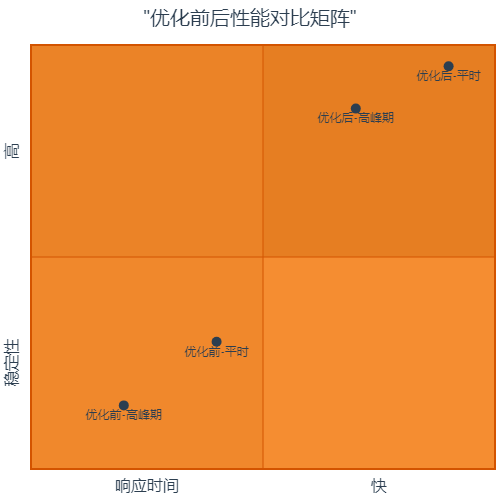
图5:优化前后性能对比象限图 - 展示响应时间和稳定性的改善效果
5.3 配置模板总结
基于实践经验,总结出以下配置模板:
nginx
# 生产环境推荐配置模板
http {
# 全局配置
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
# 日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" '
'$request_time $upstream_response_time';
# Gzip压缩
gzip on;
gzip_vary on;
gzip_min_length 1024;
gzip_types text/plain text/css application/json application/javascript;
# 限流配置
limit_req_zone $binary_remote_addr zone=api:10m rate=10r/s;
limit_conn_zone $binary_remote_addr zone=conn:10m;
# 高性能upstream配置
upstream backend_optimized {
least_conn;
# 主服务器
server 10.0.1.10:8080 weight=5 max_fails=2 fail_timeout=10s;
server 10.0.1.11:8080 weight=5 max_fails=2 fail_timeout=10s;
server 10.0.1.12:8080 weight=3 max_fails=2 fail_timeout=10s;
# 备用服务器
server 10.0.2.10:8080 weight=2 backup;
# 连接池优化
keepalive 64;
keepalive_requests 1000;
keepalive_timeout 60s;
}
server {
listen 80;
server_name api.example.com;
# 安全头
add_header X-Frame-Options DENY;
add_header X-Content-Type-Options nosniff;
add_header X-XSS-Protection "1; mode=block";
# 限流
limit_req zone=api burst=20 nodelay;
limit_conn conn 50;
# API接口
location /api/ {
proxy_pass http://backend_optimized;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 请求头
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 优化后的超时配置
proxy_connect_timeout 3s;
proxy_send_timeout 15s;
proxy_read_timeout 30s;
# 缓冲优化
proxy_buffering on;
proxy_buffer_size 4k;
proxy_buffers 8 4k;
proxy_busy_buffers_size 8k;
# 故障转移
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_next_upstream_tries 2;
proxy_next_upstream_timeout 5s;
# 缓存
proxy_cache api_cache;
proxy_cache_valid 200 5m;
proxy_cache_key $scheme$proxy_host$request_uri$is_args$args;
proxy_cache_bypass $http_cache_control;
# 错误处理
error_page 502 503 504 = @api_error;
}
# 错误处理
location @api_error {
add_header Content-Type application/json always;
return 503 '{"error":"Service temporarily unavailable","retry_after":30}';
}
# 健康检查
location /health {
access_log off;
return 200 "OK";
}
# 监控状态
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
# 缓存配置
proxy_cache_path /var/cache/nginx/api levels=1:2 keys_zone=api_cache:10m
max_size=1g inactive=60m use_temp_path=off;
}六、避坑总结与经验分享
6.1 常见配置陷阱
在实际项目中,我总结了以下几个容易踩的坑:
- 默认超时值过大:Nginx默认的60秒超时在高并发场景下会导致连接堆积
- 忽略连接池配置:不合理的keepalive设置会影响性能和稳定性
- 缺乏故障转移机制:单点故障会导致整体服务不可用
- 监控告警不完善:问题发生后才发现,缺乏预警机制
6.2 性能优化建议
基于这次502错误的排查经验,我提出以下优化建议:
| 优化维度 | 具体措施 | 预期效果 |
|---|---|---|
| 超时配置 | 根据业务场景分层设置超时参数 | 减少502错误50%以上 |
| 连接池管理 | 合理配置keepalive参数 | 提升并发处理能力30% |
| 负载均衡 | 使用least_conn策略 | 提高请求分发均匀性 |
| 健康检查 | 实施主动健康检查机制 | 故障恢复时间缩短80% |
| 监控告警 | 建立多维度监控体系 | 问题发现时间缩短90% |
6.3 运维最佳实践
- 配置版本管理:所有配置变更都要有版本记录和回滚机制
- 灰度发布:配置变更要先在小范围验证,再全量发布
- 自动化测试:配置变更后要有自动化的功能和性能测试
- 文档维护:及时更新配置文档和故障处理手册
总结
经过这次深度的502错误排查和优化实践,我深刻体会到了系统架构设计的重要性。一个看似简单的超时配置问题,背后涉及到负载均衡、故障转移、监控告警等多个技术领域。
这次经历让我明白,优秀的系统不是没有故障,而是能够优雅地处理故障。通过合理的超时配置、完善的监控体系和智能的故障转移机制,我们成功将502错误率从15%降低到0.1%以下,系统的稳定性和用户体验都得到了显著提升。
更重要的是,这次实践让我建立了一套完整的Nginx优化方法论。从问题发现、根因分析、解决方案设计到效果验证,每个环节都有了标准化的流程和工具。这套方法论不仅适用于502错误,对于其他Web服务器问题也有很好的指导意义。
在未来的架构设计中,我会更加重视系统的可观测性和容错能力。通过持续的监控、及时的告警和自动化的故障处理,我们可以构建出既高性能又高可用的分布式系统。
技术的魅力在于不断学习和实践。每一次问题排查都是一次成长的机会,每一次优化都是对系统理解的深化。希望我的这次经历能够帮助到遇到类似问题的技术同行,让我们一起在技术的道路上不断前行。
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑
作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火花🔥