环境
用VMware搭建 Ubuntu 18.04 64位虚拟机(方法可见)

Hadoop伪分布式环境
1.安装Java环境
1.下载Linux版Java到文件夹中
注:补充里面有不挂载共享直接将宿主机和虚拟机交互的工具


2.开启宿主机与虚拟环境共享
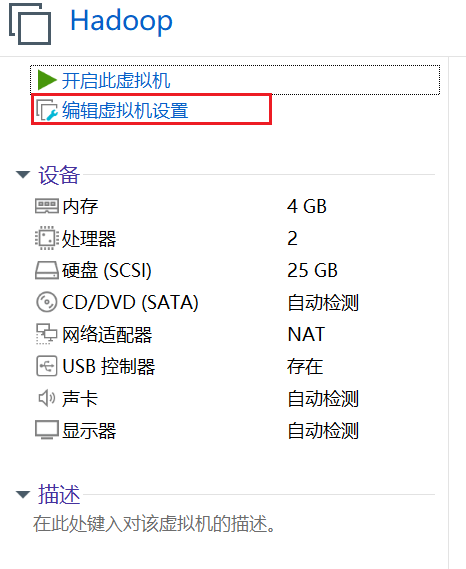

3.挂载共享文件
bash
vmware-hgfsclient
//查看共享文件名称,判断是否共享成功 (查看 VMware 识别的共享文件夹名称)
(查看 VMware 识别的共享文件夹名称)
bash
sudo vmhgfs-fuse .host:/VMware_shared_folder /mnt/shared -o allow_other
//将共享的文件挂载 (挂载文件)
(挂载文件)
 (需要输入用户密码'不会显示')
(需要输入用户密码'不会显示')
4.验证挂载并找到JDK安装包
bash
ls /mnt/shared
//查看共享文件中的文件名称,帮助找到要解压的jdk文件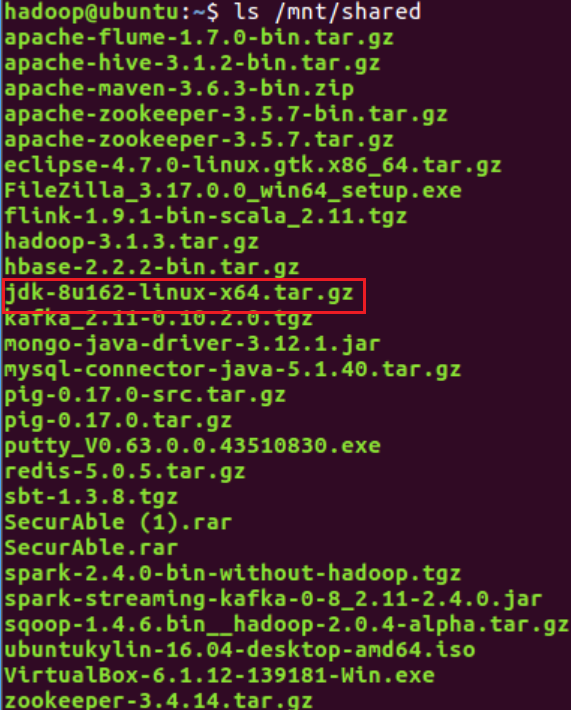
5.解压并安装JDK
bash
cd /mnt/shared
//切换到挂载目录
bash
sudo tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/
//解压jdk-8u162-linux-x64.tar(是你共享文件中的名称,不一定是我这个)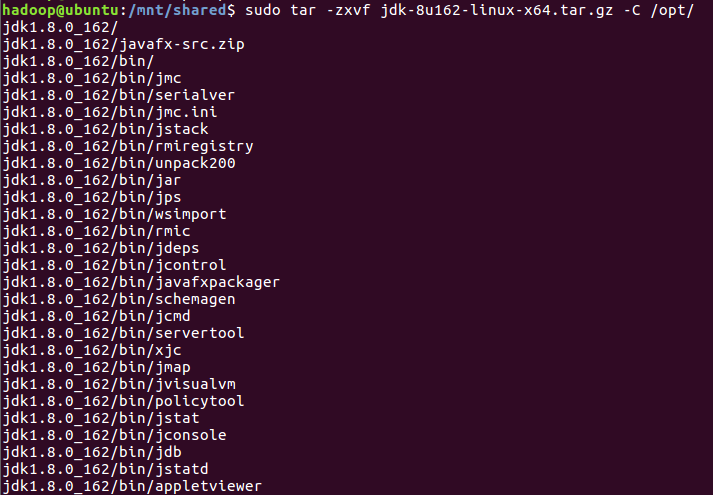
6.配置环境
bash
vim ~/.bashrc
//打开环境配置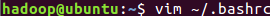
bash
export JAVA_HOME=/opt/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME/jre}
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH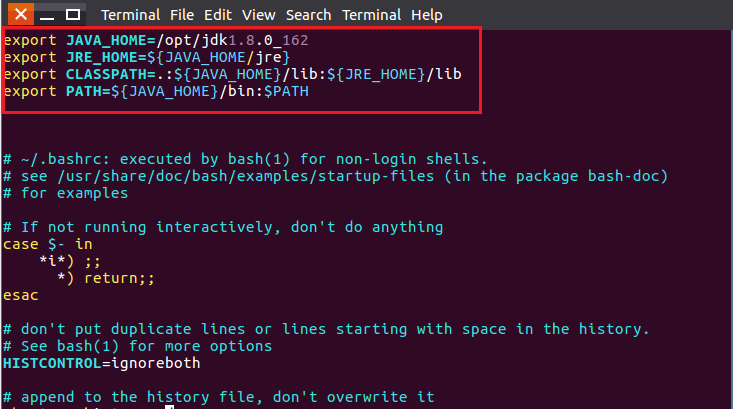
7.使环境变量生效
bash
source ~/.bashrc
//使环境变量生效
8.验证JDK
bash
java -version
//检验安装是否成功
2.安装Hadoop
1.安装Hadoop文件


2.像Java安装一样挂载共享文件夹和查找文件中的压缩包并解压到/opt文件下
3.修改文件权限
bash
cd /opt
sudo chown -R hadoop-3.1.3
//切换到/opt目录
//将文件的所有者改为hadoop用户

4.验证Hadoop是否安装成功
bash
cd /opt/hadoop-3.1.3
./bin/hadoop version
//如果安装成功会跳出Hadoop版本信息
3.Hadoop单机配置(非分布式)
Hadoop非分布式不需要配置
案例(grep操作):
bash
cd /opt/hadoop-3.1.3
//跳转到hadoop的目录
mkdir ./input
//创建一个input文件
cp ./etc/hadoop/*.xml ./input
//将./etc/hadoop/目录下的拓展名为.xml的配置文件复制到刚刚创建的./input目录中,作为grep操作的输入源
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./output 'dfs[a-z.]+'
//./bin/hadoop jar用于执行jar程序
//./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar包含grep示例的jar包路径
//grep是要运行的示例程序名称
//./output是结果存放的目录
//'dfs[a-z.]+'是正则表达式,匹配dfs开头,后面跟一个或多个小写字母或.字符串
cat ./output/*
//查看./output目录下的所有文件内容,也就是grep操作运行后的结果
rm -r ./output
//Hadoop默认不会覆盖文件再次运行实例会出错,需要将./output删除




 (结果)
(结果)

4.Hadoop伪分布式配置
1.用gedit编辑core-site.xml文件
bash
cd /opt/hadoop-3.1.3/etc/hadoop
//跳转到该目录
bash
gedit core-site.xml
//使用gedit编辑器编辑该文件
html
<configuration>
<property>
<name>hadoop.tep.dir</name>
<value>file:/opt/hadoop-3.1.3/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
//将此段代码加入<configuration>,</configuration>之间2.用gedit编辑hdfs-site.xml文件
bash
gedit hdfs-site.xml
//使用gedit编辑器编辑该文件

html
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.1.3/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.1.3/hadoop/tmp/dfs/data</value>
</property>
</configuration>
//将此段代码加入<configuration>,</configuration>之间5.伪分布式下NameNode格式化
bash
cd /opt/hadoop-3.1.3
./bin/hdfs namenode -format
//NameNode格式化命令



6.伪分布式运行实例
1.启动Hadoop相关服务
bash
cd /opt/hadoop-3.1.3
./sbin/start-dfs.sh
//开启服务


2.在HDFS中创建用户目录
bash
./bin/hdfs dfs -mkdir -p /user/hadoop
//-p表示如果父目录不在则递归创建
//以"./bin/hadoop dfs"开头的Shell命令方式有三种
1.hadoop fs 适用于任何不同的文件系统
2.hadoop dfs 只能适用于HDFS文件系统
3.hdfs dfs 只能适用于HDFS文件系统
3.创建input目录并复制指定xml文件到input目录
bash
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
//在HDFS创建中创建input目录
//将指定的xml文件复制到input目录

bash
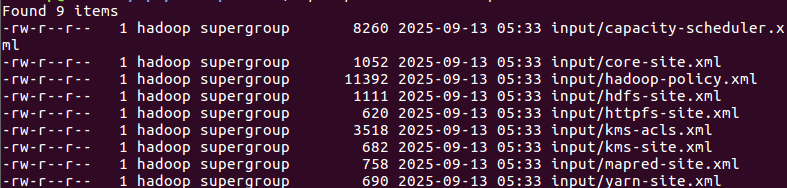
./bin/hdfs/dfs -ls input
//查看input目录
4.运行MapReduce作业
bash
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
//./bin/hadoop jar运行Hadoop中的JAR包------这里指定运行hadoop-mapreduce-examples-3.1.3.jar这个实例JAR包
bash
./bin/hdfs dfs -cat output/*
//查看运行结果

5.删除输出目录(不然下次运行会报错------运行程序时不能存在输出目录)
bash
./bin/hdfs dfs -rm -r output
//删除输出目录
6.关闭Hadoop
bash
./sbin/stop-dfs.sh
//关闭Hadoop运行

7.伪分布式切换回非分布式
删除core-site.xml、hdf-site.xml中的配置项
将Hadoop伪分布式配置中添加的配置项删除
补充
1.安装SSH,配置SSH无密码登录
1.安装SSH
bash
sudo apt-get install openssh-server
//安装SSH server
2.登录本机
bash
ssh localhost
//登录本机
3.生成密钥并授权
bash
exit
//退出本机

bash
cd ~/.ssh/
//进入目录,如果没有该目录,执行一次 ssh localhost
bash
ssh-keygen -t rsa
//回车会有提示
ssh-copy-id localhost
//加入授权

bash
//连续回车两次------不设置密码
2.安装宿主机和虚拟机的交互工具(可以不挂载共享文件直接得到要的安装包)
1.安装工具
bash
sudo apt-get remove open-vm-tools
//删除
sudo apt-get install open-vm-tools
//下载
sudo apt-get install open-vm-tools-desktop
//优化


3.下载编辑器
bash
sudo apt-get install vim
sudo apt-get install gedit
//下载命令
