本专栏文章持续更新,新增内容使用蓝色表示。
一、什么是 HDFS?
HDFS(Hadoop Distributed File System)是 Hadoop 分布式文件系统 ,专为大规模数据存储而设计。它具有高度可扩展性,能够运行在大量普通低成本机器上,并通过内置的容错机制为用户提供高性能的文件存储服务。
1.1 HDFS 的核心优势
高容错性
数据自动保存多个副本,当某个副本丢失时系统能够自动恢复,确保数据持久性和可用性。
适合批量处理
HDFS 遵循"移动计算而非数据"的理念,将数据位置信息暴露给计算框架,有效减少数据传输开销。
支持超大规模数据
可处理 TB 甚至 PB 级别数据,支持百万规模以上的文件数量,并能部署在10K+ 节点的集群上。
流式文件访问
采用"一次写入、多次读取"模型,保证数据一致性,非常适合数据批量写入和顺序读取的场景。
低成本高可靠
通过多副本机制在廉价硬件上实现高可靠性,具备完善的容错和恢复机制。
1.2 HDFS 的局限性
不适合低延迟访问
为达到高吞吐率而牺牲了低延迟特性,无法满足毫秒级访问需求。
小文件存储效率低
大量小文件会占用 NameNode 大量内存(因为每个文件的元数据占用空间基本固定),并且磁盘寻道时间远超过数据传输时间。建议在数据入库前尽量合并小文件为大文件。
不支持并发写入和随机修改
一个文件同时只能有一个写入器,且仅支持追加写入,不支持随机修改。
二、HDFS 的设计思想
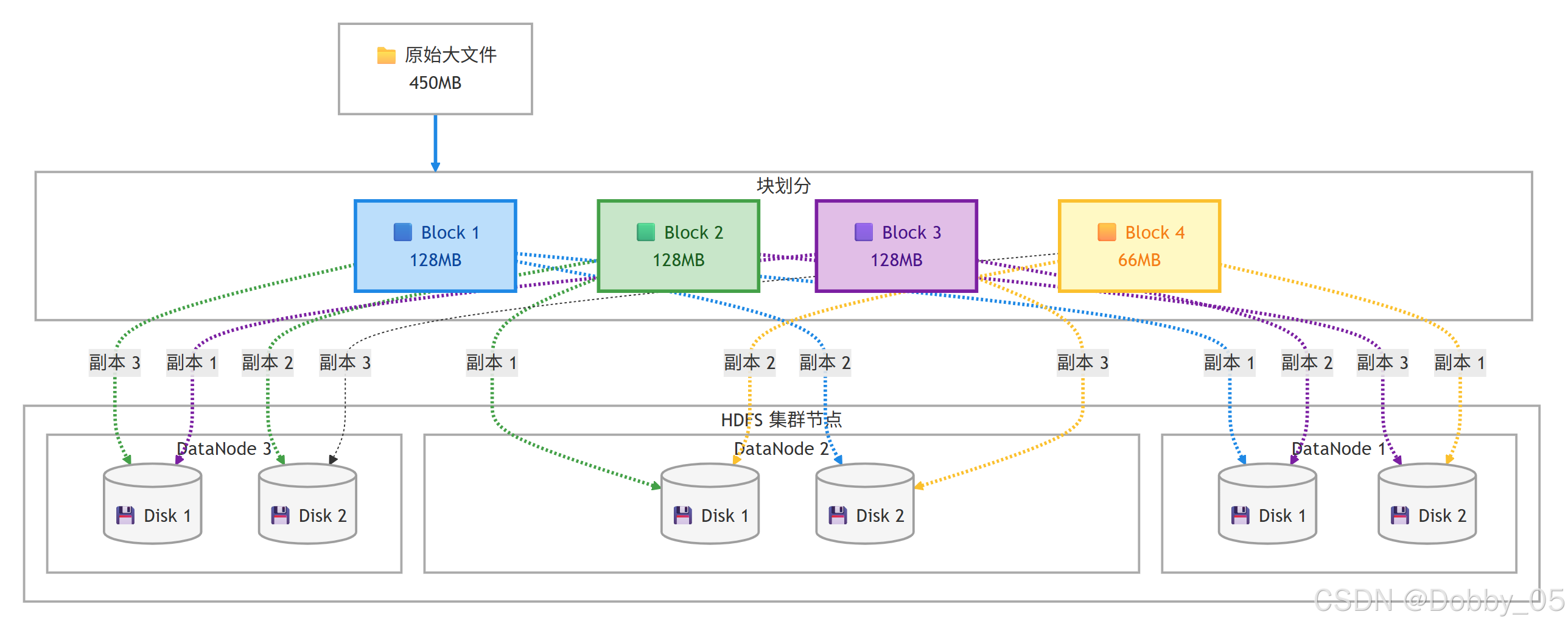
HDFS 将文件切 分为固定大小的数据块 (默认 128MB)并在分布式集群中打散存储。这种设计与 RAID 的条带化理念相似,通过多磁盘并行操作提升整体 I/O 性能。
注意事项
在大数据开发中,系统默认参数通常经过官方团队基于大量实验和硬件特性优化,与底层文件系统紧密耦合。除非有明确特殊需求并经过充分测试,否则不建议随意修改默认配置。
2.1【工程思维】应对磁盘性能瓶颈
当前大数据场景下面临磁盘 I/O 性能瓶颈,HDFS 的解决方案是:采用条带化策略,配置多个硬盘,将数据切块并分布存储 across 多个磁盘,显著提升读写效率。
2.2 副本放置策略
-
第一副本:写入客户端所在节点(如果适用)
-
第二副本:不同机架中的节点
-
第三副本:与第二副本同一机架的另一个节点
-
其他副本:集群中随机选择节点
这种策略平衡了数据可靠性、读取性能和网络带宽利用率。
三、HDFS 架构解析
3.1 基础架构
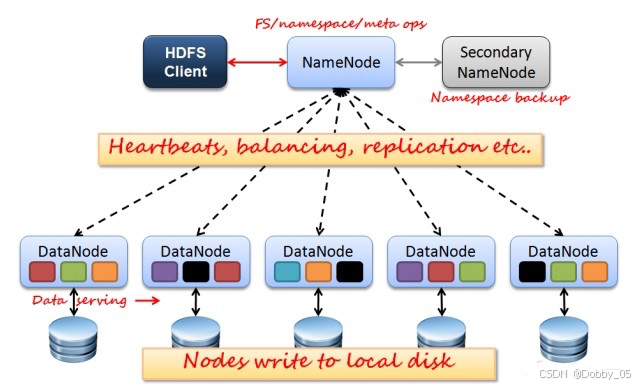
3.1.1 NameNode (NN)
NameNode 作为核心控制单元(类似于 Kubernetes 的 API Server),管理文件系统的元数据(文件名、目录结构、文件块列表等)。为了追求高性能,所有元数据更改首先追加到 Editlog 文件,而不是直接修改 FsImage 元数据镜像文件。
-
FsImage 是某一时间点的完整元数据快照
-
EditLog 记录自快照后的所有更改操作
长期运行会导致 EditLog 过大,使得 NameNode 重启变慢并增加文件损坏风险。
3.1.2 Secondary NameNode (SNN)
SNN 是 NameNode 的辅助节点,通过定期检查点机制进行容灾。其核心工作是合并编辑日志,生成新的元数据快照,防止 EditLog 过大并加速 NameNode 重启。
3.2 SNN 工作机制(检查点过程)
-
定期触发(默认每小时)或基于 EditLog 大小达到阈值
-
请求 NameNode 执行检查点操作
-
NameNode 滚动编辑日志,创建新 EditLog
-
SNN 通过 HTTP 获取最新 FsImage 和旧 EditLog
-
在内存中合并生成新元数据镜像
-
将新 FsImage 送回 NameNode
-
NameNode 替换旧镜像文件
重要提示:SNN 不是热备份节点,无法在 NameNode 故障时立即接管,其主要作用是优化元数据管理。
3.3 高可用架构
真正的热备份功能由高可用(HA)架构中的 Standby NameNode 实现。在 HA 模式下,两个 NameNode(Active 和 Standby)通过共享 EditLog(通常使用 JournalNodes)实时同步状态,实现故障自动切换。启用 HA 后不再需要 Secondary NameNode。
四、HDFS 读写流程详解
4.1 写入流程
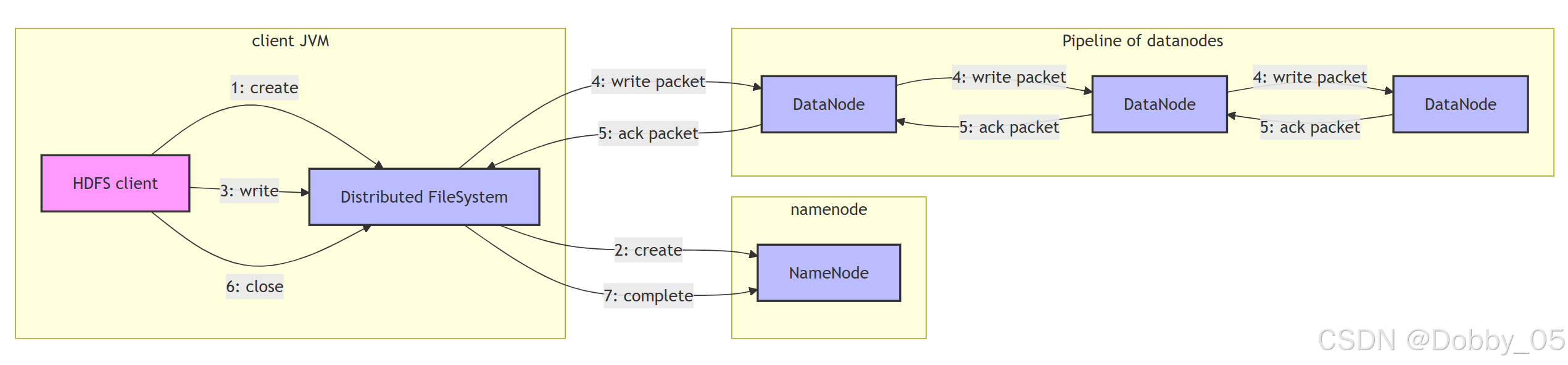
以上传 300MB 文件(块大小 128MB)为例:
-
客户端请求写入:向 NameNode 申请写入权限
-
创建数据管道:NameNode 根据机架感知策略返回 DataNode 列表
-
建立连接:客户端与 DataNode 管道建立连接(DN1→DN2→DN3)
-
流水线复制:数据以包(默认64KB)为单位流式传输,每个节点存储后立即转发
-
确认回执:通过反向管道发送成功确认
-
完成写入:所有块写入后,客户端通知 NameNode 提交元数据
核心特点:流水线复制实现并行写入,大幅提高效率。
4.2 读取流程
-
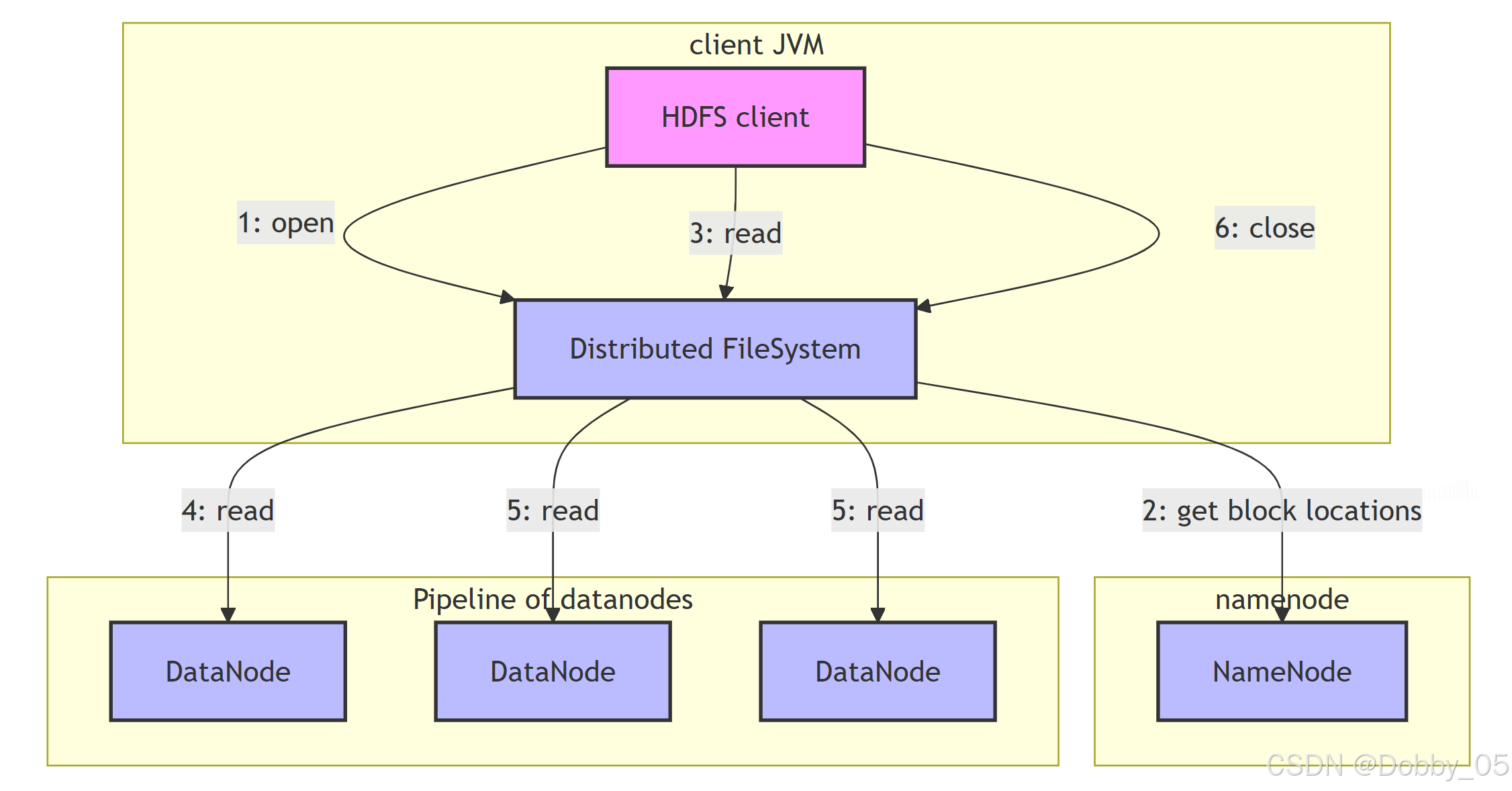
客户端请求读取:从 NameNode 获取文件块信息和位置
-
直接连接 DataNode:客户端选择最近节点建立直接连接
-
流式读取:以数据包形式持续读取数据
-
故障转移:如遇连接中断,自动切换至其他副本
-
顺序读取:依次读取所有数据块
-
关闭连接:完成读取后关闭所有连接
核心特点:客户端直接与 DataNode 交互,避免 NameNode 瓶颈,支持故障自动切换。
预告后续内容
Yarn、Hive、ZooKeeper、HBase
如有问题或建议,欢迎在评论区中留言~