目录
[3.1 RRT](#3.1 RRT)
[3.2 APF人工势场](#3.2 APF人工势场)
[3.3 DS动态系统调制方法](#3.3 DS动态系统调制方法)
[3.4 强化学习](#3.4 强化学习)
在这篇文章里准备捋一下所有有关路径规划相关的内容和知识,并且针对每个算法会单独写一篇文章详细讲解,包括原理和代码。
!!!!!这篇博客里的算法都可以点开学习,希望大家多多点赞收藏,会持续更新,目的就是希望能够为大家提供一个全面的路径规划算法检索界面!!!!!
下面的表格列举了主流的路径规划算法,可以直接点进去跳转到相关的文章学习,里面包含了原理,伪代码,英文期刊论文和相关代码。
| RRT | 基本RRT | RRT-Connect(单项随机+单项定向) | RRT*(路径重连) |
| | Bi-RRT(双向随机探索) | | |
| APF | APF-DWA(动态窗口) | APF-RRT* | 速度APF(速度斥力场) |
| 强化学习 | MADDPG(多智能体) | RRT+RL | APF+RL |
| | DWA-RL(动态) | | |
| 其他 | A* | PRM | |
一、区分路径规划和轨迹规划
简单来说,路径规划是不包含时间和运动状态 ,轨迹规划是包含时间和运动状态 。两者是机器人运动控制的前后衔接环节(先路径规划,后轨迹规划)
- **路径规划:**是从起点到目标点的空间无碰撞路径(仅需满足位置约束,不涉及时间或运动状态)
- 轨迹规划:是在路径规划的基础上,生成包含时间、速度、加速度的运动指令(需满足机器人动力学约束,如硬件加速度上限)
| 对比维度 | 路径规划(Path Planning) | 轨迹规划(Trajectory Planning) |
| 输出结果 | 空间坐标序列 / 几何曲线(如离散点、折线、贝塞尔曲线),无时间信息 | 随时间变化的「状态序列」(位置、速度、加速度、角速度、力矩等),包含时间维度 |
| 常见方法 | 1. 传统搜索类:Dijkstra 算法、A算法、BFS(广度优先搜索)、DFS(深度优先搜索) 2. 概率采样类:RRT 算法、RRT 算法(RRT 改进版,更优路径)、PRM(概率路标法) 3. 势场类:人工势场法 4. 其他:Voronoi 图法、可见性图法 | 1. 关节空间规划(直接对关节角度规划,避免笛卡尔空间奇点):三次多项式插值、五次多项式插值、梯形速度曲线 2. 笛卡尔空间规划(对末端执行器位置 / 姿态规划):直线插补(如 G01)、圆弧插补(如 G02/G03)、贝塞尔曲线、B 样条曲线(平滑性更优) 3. 动力学约束规划(考虑实时动态性能):LQR 控制(线性二次调节器)、模型预测控制(MPC)、轨迹优化(如通过凸优化求解约束问题) |
| 示例 | 从客厅沙发到门口,规划出 "绕开茶几的折线 / 平滑曲线"(仅标注空间坐标点) | 基于上述绕开茶几的路径,规划 "0-2 秒从静止加速到 0.5m/s,2-8 秒匀速行驶,8-10 秒减速至静止" 的完整运动过程(每 0.1 秒对应一个位置 + 速度值) |
|---|
所以我们一般提到的RRT,人工势场法等都是路径规划算法。
二、区分全局规划和局部规划
路径规划算法可以分为全局规划算法和局部规划算法,他俩的核心区别就一点:是否实时获取障碍物信息并实时规划。
- 全局规划: 是提前知道全部的静态地图信息,然后直接规划出一条起点到终点的路径,之后机器人就啥也不管一股脑按照这条规划好的路径从起点走到终点,如果中途碰到动态障碍物撞过来他也不管。所以全局规划适用于静态、已知环境
- 局部规划:机器人依赖传感器实时获取局部的动态信息(也就是机器人周围小范围内的障碍物信息),然后实时的规划出下一步该怎么走,看上去比全局规划更智能一点。所以局部规划适用于动态、未知环境。
2.1 全局规划算法
| 算法类别 | 具体算法名称 | 核心特点 | 适用场景 |
| 图搜索类 | Dijkstra 算法 | - 基于 "加权图" 搜索,按路径代价(如距离、时间)递增扩展节点; - 保证全局最优,但未利用目标方向信息,效率较低。 | 简单静态环境,或作为其他优化算法(如 A*)的基础;不适合大规模复杂地图。 |
| | A* 算法 | - 在 Dijkstra 基础上引入启发函数 (如曼哈顿距离、欧氏距离),优先扩展向目标方向的节点; - 兼顾效率与全局最优,是最经典的全局规划算法之一。 | 室内静态环境(如 AGV、扫地机器人)、网格地图场景;对启发函数设计敏感(需适配地图类型)。 |
| | 改进 A* 算法(如JPS) | - 对 A * 的 "节点扩展" 剪枝,仅在 "跳跃点"(能影响路径最优性的关键节点)处计算,大幅提升效率; - 保持全局最优,适合大规模网格地图。 | 大尺寸静态地图(如仓库 AGV 全局路径、游戏地图寻路);需网格地图结构支持。 |
| | D* 算法(Dynamic A*) | - 针对 "静态地图局部动态变化"(如临时出现小障碍)优化,无需重新计算全局路径,仅更新受影响的局部路径; - 动态适应性优于 A*,仍保证全局最优。 | 基本静态但偶有局部临时障碍的环境(如工厂 AGV 应对临时堆放的物料)。 |
| 采样类 | 概率路线图(Probabilistic Roadmap, PRM) | - 分两步:① 随机采样环境中的可行节点,连接成 "路线图";② 在路线图中搜索起点→终点的路径; - 适合高维空间(如机械臂关节空间),但预处理耗时。 | 高维静态环境(如机械臂路径规划、无人机三维空间规划);需提前构建路线图。 |
| | 改进 PRM (如 PRM*、 Lazy PRM) | - PRM*:优化采样策略,保证路径渐进最优(采样越多,路径越优); - Lazy PRM:延迟验证节点连接的可行性,减少预处理时间。 | 对路径最优性要求高的高维静态环境(如精密机械臂操作)。 |
| | 快速探索随机树(Rapidly-exploring Random Tree, RRT) | - 从起点出发,随机采样节点并扩展 "树状结构",快速探索未知空间; - 无需预处理,适合动态 / 高维环境,但路径随机性强(非最优)。 | 高维静态 / 半动态环境(如无人机避障、机械臂快速规划);追求 "快速找到可行路径" 而非最优。 |
| | 改进 RRT(如 RRT*、RRT-Connect、Informed RRT*) | - RRT*:对扩展的树节点进行 "重连优化",保证路径渐进最优; - RRT-Connect:同时从起点和终点扩展两棵树,提升探索效率; - Informed RRT*:在 RRT * 基础上加入 "椭圆约束",聚焦目标方向,加速最优路径收敛。 | RRT*:对路径最优性有要求的静态环境; RRT-Connect:需快速规划的高维环境; Informed RRT*:需兼顾效率与最优性的场景(如自动驾驶全局路径)。 |
| 智能优化类 | 遗传算法(Genetic Algorithm, GA) | - 模拟生物进化(选择、交叉、变异),通过种群迭代优化路径; - 能处理复杂约束(如路径平滑性、能耗),但易陷入局部最优,收敛慢。 | 多约束静态环境(如机器人路径的能耗优化、复杂地形无人机规划)。 |
| | 蚁群算法(Ant Colony Optimization, ACO) | - 模拟蚂蚁觅食(信息素引导路径选择),适合离散空间路径搜索; - 鲁棒性强,但收敛速度慢,参数调优复杂。 | 网格地图、多机器人协同路径规划(静态环境)。 |
| | 粒子群优化(Particle Swarm Optimization, PSO) | - 模拟粒子群运动(个体最优 + 全局最优引导),连续空间优化能力强; - 实现简单,但高维空间效率低。 | 连续空间静态路径优化(如平滑路径的参数调整)。 |
| 几何曲线类 | 贝塞尔曲线(Bézier Curve)/ B 样条曲线(B-Spline Curve) | - 基于控制点生成平滑连续的曲线,可拟合离散路径点; - 保证路径平滑性(一阶 / 二阶连续),但需先通过其他算法(如 A*)生成离散路径点。 | 对路径平滑性要求高的场景(如自动驾驶车道保持、机械臂运动轨迹预处理)。 |
| 多项式曲线(Polynomial Curve) | - 通过多项式插值(如五次多项式)连接路径点,保证位置、速度、加速度连续; - 平滑性好,但计算复杂度随多项式阶数增加。 | 高精度运动控制场景(如无人机精准悬停、工业机器人装配路径)。 | |
|---|---|---|---|
| [全局规划算法汇总表] |
2.2 局部规划算法
| 算法类别 | 具体算法名称 | 核心特点 | 适用场景 |
| 势场类 | 人工势场法(Artificial Potential Field, APF) | - 构建 "引力场(指向短期目标)+ 斥力场(远离实时障碍)",机器人沿势场梯度运动; - 实现简单、响应快,但易陷入局部极小值(如 U 型障碍)。 | 低动态环境局部避障(如室内机器人绕开临时障碍物、低速 AGV)。 |
| | 改进 APF(如 Elastic Band APF、APF-PSO) | - Elastic Band APF:将路径视为 "弹性带",通过障碍斥力调整路径,避免局部极小; - APF-PSO:结合粒子群优化,跳出局部极小值。 | 需解决局部极小值的场景(如机器人避开凹形障碍、复杂室内环境)。 |
| 窗口采样类 | 动态窗口法(Dynamic Window Approach, DWA) | - 在 "速度 - 角速度" 空间采样可行运动指令,预测短期轨迹,评估轨迹代价(如距离障碍、朝向目标); - 实时性强,能兼顾动力学约束,但采样范围有限。 | 移动机器人实时避障(如扫地机器人避开突发障碍、室内 AGV 动态调整方向)。 |
| | 时间弹性带(Time Elastic Band, TEB) | - 将 "路径 + 时间" 视为 "弹性带",同时优化路径几何和时间分配,保证速度、加速度连续; - 兼顾路径平滑性与动态避障,计算复杂度高于 DWA。 | 对运动平滑性和动态响应要求高的场景(如自动驾驶低速避障、无人机自主导航)。 |
| 传感器数据驱动类 | 向量场直方图(Vector Field Histogram, VFH) | - 将激光雷达数据转化为 "极坐标直方图",统计各方向的障碍密度,选择 "无障且朝向目标" 的方向; - 抗噪声能力强,但对动态障碍响应较慢。 | 基于激光雷达的室外机器人避障(如轮式机器人在园区避开静态障碍物)。 |
| | 障碍规避切线法(Obstacle Avoidance Tangent Bug) | - 沿障碍物边界的切线运动,同时持续朝向目标方向,直到无障路径出现; - 适合绕开大型障碍物,但易因障碍形状复杂导致路径冗余。 | 室外大型静态障碍避障(如机器人绕开树木、墙体)。 |
| 模型预测控制类 | 模型预测控制(Model Predictive Control, MPC) | - 基于机器人动力学模型,预测未来一段时间内的轨迹,通过优化目标函数(如跟踪误差、避障代价)选择最优控制量; - 动态适应性强,但计算复杂度高,依赖精准模型。 | 高动态环境(如自动驾驶高速避障、无人机规避快速移动的障碍物)。 |
|---|---|---|---|
| [局部规划算法汇总表] |
三、核心主流算法介绍
3.1 RRT
下面按照RRT改进的思路进行罗列
| 算法名称 | 核心改进 | 适用场景 |
| RRT* | - 重选父节点:在新节点邻域内选择代价最小的父节点,而非仅最近节点; - 节点重连:优化已有节点的父节点,缩短路径长度; - 保证渐进最优性(采样越多,路径越优)。 | 静态环境中对路径最优性要求高的场景(如机械臂精密操作、自动驾驶全局路径规划)。 |
| Informed RRT* | - 在 RRT * 基础上,将采样限制在以起点、终点为焦点,当前最优路径长度为长轴的椭圆区域内; - 显著加速收敛速度,减少无效采样。 | 对路径优化效率要求高的场景(如无人机三维路径规划、复杂地形机器人导航)。 |
| RRT-Extend | - 动态调整扩展方向,优先向目标点延伸,减少随机探索的盲目性。 | 目标明确但存在狭窄通道的环境(如机器人通过门缝、工业机械臂避障)。 |
| RRT-Smooth | - 对 RRT 生成的离散路径点进行曲线拟合(如三次 B 样条),消除冗余拐点,提升路径平滑性。 | 对运动平滑性要求高的场景(如自动驾驶车道保持、工业机器人装配路径)。 |
|---|---|---|
| [#### 3.1.1 路径优化与渐进最优性] |
3.1.2探索效率提升
| 算法名称 | 核心改进 | 适用场景 |
| RRT-Connect | - 双向扩展:同时从起点和终点生成两棵树,相遇时快速连接路径; - 效率比单向 RRT 提升 1-2 个数量级。 | 长距离路径规划或高维空间(如无人机跨区域导航、机械臂关节空间规划)。 |
| Bi-RRT | - 双向树相互拓展而非随机采样,更易通过狭窄通道; - 与 RRT-Connect 的区别在于拓展方式更主动。 | 狭窄环境(如迷宫、机器人穿过密集障碍物)。 |
| Lazy RRT | - 延迟验证节点连接的可行性,仅在必要时进行碰撞检测,减少计算开销。 | 计算资源受限的场景(如微型无人机、低功耗移动机器人)。 |
| Bias-RRT | - 以概率 p 将目标点作为随机采样点,增加目标导向性; - p 随环境复杂度动态调整(如复杂环境降低 p 以避免局部搜索)。 | 简单到中等复杂度的静态环境(如室内机器人导航、游戏 AI 寻路)。 |
|---|
3.1.3动态环境适应性
| 算法名称 | 核心改进 | 适用场景 |
| D-RRT(Dynamic RRT) | - 实时重采样:检测到环境变化时,重新从当前位置扩展树,快速响应动态障碍物。 | 半动态环境(如工厂 AGV 应对临时堆放的物料、室内机器人避开来回走动的人)。 |
| Anytime RRT* | - 在机器人移动过程中,持续将当前位置作为根节点更新树,实现路径的在线优化。 | 动态变化频繁的环境(如自动驾驶车辆在拥堵路段实时调整路径)。 |
| DWA-RRT | - 引入时间滑动窗口,结合时序一致性约束过滤传感器噪声,提升动态障碍物检测准确性。 | 传感器噪声较大的动态环境(如室外机器人在雨天或粉尘环境中导航)。 |
|---|
3.1.4运动学 / 动力学约束处理
| 算法名称 | 核心改进 | 适用场景 |
| Kinodynamic RRT* | - 改进 Steer 函数,使用曲线(如五次多项式)连接节点,满足速度、加速度连续约束。 | 对运动平滑性和动力学限制严格的场景(如无人机精准悬停、人形机器人步态规划)。 |
| RRT-Kinodynamic | - 直接在状态空间中采样速度、加速度等动力学参数,确保路径的可执行性。 | 具有非完整约束的机器人(如轮式移动机器人、无人车)。 |
|---|
3.1.5参数自适应与采样优化
| 算法名称 | 核心改进 | 适用场景 |
| Adaptive Step-Size RRT | - 动态调整步长:空旷区域增大步长加快探索,狭窄区域减小步长避免碰撞。 | 环境复杂度变化大的场景(如机器人从开阔场地进入密集货架区)。 |
| RRT with Goal Biasing | - 以固定概率强制选择目标点作为采样点,平衡随机性与目标导向性。 | 目标明确但存在局部障碍的环境(如机器人绕过茶几到达门口)。 |
| RRT with Local Path Pruning | - 双向剪枝:从起点和终点回溯路径,删除冗余节点,缩短路径长度。 | 路径拐点多、冗余度高的场景(如 RRT 生成的初始路径优化)。 |
|---|
3.1.6 RRT与其他算法融合
| 算法名称 | 融合策略 | 核心优势 |
|---|---|---|
| RRT-A Hybrid* | - 先用 RRT 生成初始路径框架,再用 A算法对路径分段进行精细化优化。 - 结合 RRT 的高维探索能力与 A的启发式搜索优势。 | 路径长度显著缩短(较 RRT 减少 30% 以上),同时保持 RRT 在复杂环境中的高效性。 |
| RRT-D Fusion* | - RRT 生成全局路径,D * 算法处理动态障碍物导致的局部路径失效。 - 动态重规划时仅更新受影响区域,减少计算量。 | 动态环境适应性强,重规划时间比纯 RRT 快 50% 以上。 |
| APF-RRT | - 人工势场(APF)的目标引力引导 RRT 采样方向,RRT 的随机扩展避免 APF 陷入局部极小值。 | 路径平滑性提升(曲率波动减少 40%),狭窄通道通过率提高至 95% 以上。 |
| RRT-DWA | - RRT 生成全局路径作为参考,动态窗口法(DWA)实时调整速度和转向,实现动态避障。 | 动态障碍物避让成功率达 98%,路径跟踪误差小于 0.2 米。 |
| RRT-DSM | - RRT 提供全局路径,动态系统调制(DSM)通过微分方程实时调整局部运动指令。 - 例如,结合时间弹性带(TEB)优化轨迹连续性。 | 运动平滑性与动态适应性平衡,加速度波动减少 30%。 |
| RRT-PRM 串联 | - 离线阶段用 PRM 构建自由空间路网,在线阶段用 RRT 在路网基础上快速扩展。 | 在线查询时间缩短至毫秒级,离线预处理后重复规划效率提升 10 倍以上。 |
| RRT-PRM 并联 | - PRM 生成稀疏路径骨架,RRT 在骨架节点间填充详细路径。 - 例如,PRM 确定关键点,RRT 连接关键点形成平滑轨迹。 | 路径节点数量减少 60%,路径长度接近 PRM 最优解。 |
| RRT-PSO | - 粒子群优化(PSO)动态调整 RRT 采样分布,优先向高价值区域扩展。 - 例如,粒子位置对应采样点,速度对应扩展方向。 | 采样效率提升 50%,路径规划成功率提高至 99%。 |
| RRT-GA | - 遗传算法(GA)优化 RRT 树结构,通过交叉和变异操作生成更优路径。 - 例如,染色体编码路径节点序列,适应度函数评估路径质量。 | 路径长度比 RRT * 缩短 15%,收敛速度提升 30%。 |
| RRT-CNN | - 卷积神经网络(CNN)分析环境图像特征,指导 RRT 采样区域选择。 - 例如,CNN 预测障碍物分布,RRT 优先在自由空间扩展。 | 采样无效区域减少 70%,复杂环境下规划时间缩短至 1 秒内。 |
| RRT-PPO | - 近端策略优化(PPO)学习 RRT 采样策略,通过强化学习最大化路径质量奖励。 | 动态环境下路径长度比传统 RRT 减少 25%,学习收敛速度提升 40%。 |
| RRT - 帕累托最优 | - 多智能体独立运行 RRT 生成路径,通过帕累托协商消解冲突。 - 例如,冲突双方调整路径,确保至少一方受益且无人受损。 | 多机器人协作任务成功率达 95%,冲突消解时间小于 0.5 秒。 |
| RRT - 分布式搜索 | - 多智能体共享 RRT 树信息,分布式扩展路径。 - 例如,每个智能体维护局部树,定期同步全局连接点。 | 路径规划速度比单智能体提升 3 倍,资源利用率提高 60%。 |
3.2 APF人工势场
以下是经典的人工势场法(APF)改进方法汇总,表格中包含改进方向、核心思想、关键公式(LaTeX 格式)及解决的核心问题,覆盖了针对 APF 传统缺陷(局部极小值、目标不可达、障碍物振荡、动态环境适应性差等)的主流优化方案:
| 算法名称 | 核心改进 | 适用场景 |
|---|---|---|
| 涡旋人工势场(VAPF) | - 引入切向涡旋力 ,使机器人在接近障碍物时产生环绕运动趋势,打破引力与斥力的平衡。 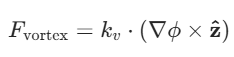 - - |
密集障碍物或凹形结构环境(如迷宫、工厂车间)。 |
| 虚拟目标点法 | - 在障碍物外生成临时目标点,引导机器人绕过局部极小区域; - 结合梯度下降修正,当合力为零时随机扰动方向。 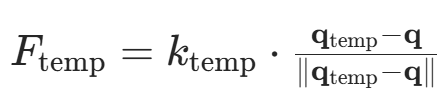 - - |
目标点被障碍物包围或路径存在狭窄通道的场景(如机器人绕过书架取物)。 |
| 斥力场函数重构 | - 改进斥力计算方式,引入目标距离因子 削弱远场斥力; - 设计分段函数:当机器人接近目标时,斥力随目标距离衰减。 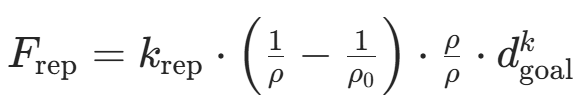 - - |
目标点与障碍物距离过近导致震荡的场景(如机器人在目标点附近避障)。 |
| [#### 3.2.1局部极小值与目标不可达问题解决方案] |
3.2.2动态环境适应性改进
| 算法名称 | 核心改进 | 适用场景 |
| 安全人工势场(SAPF) | - 引入动态安全距离 ,根据机器人速度和障碍物速度实时调整斥力范围; - 采用指数型斥力函数: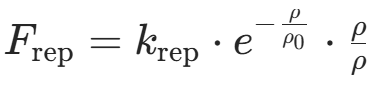 - 指数型斥力函数,动态调整斥力范围 - 速度相关安全距离:
- 指数型斥力函数,动态调整斥力范围 - 速度相关安全距离:(v为机器人速度,
为安全时间) | 高速移动或高风险环境(如自动驾驶车辆避障、无人机穿越动态人群)。 |
| 动态势场因子 | - 加入时间因子 ,根据障碍物运动轨迹预测未来位置; - 设计速度势场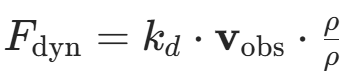 -
- :障碍物速度向量 - 时间因子:
(预测障碍物到达时间) | 障碍物线性或非线性运动的场景(如工厂 AGV 避障临时搬运车)。 |
| 预测模型结合 | - 采用神经网络或卡尔曼滤波预测动态障碍物轨迹,提前调整斥力方向。  |
障碍物运动模式复杂且难以建模的场景(如室外机器人避开来回走动的行人)。 |
|---|
3.2.3路径平滑与运动约束处理
| 算法名称 | 核心改进 | 适用场景 |
| 三次 B 样条优化 | - 对 APF 生成的离散路径点进行曲线拟合,消除冗余拐点;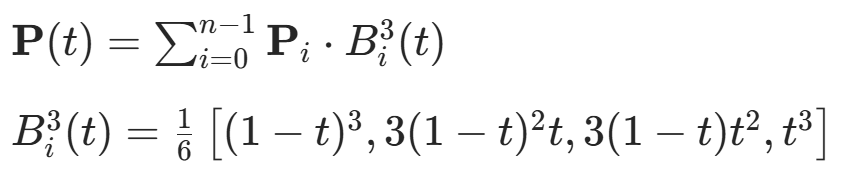 -
- :控制点坐标 -
:三次 B 样条基函数 - 曲率计算:
| 对运动平滑性要求高的场景(如工业机械臂装配路径、无人机编队飞行)。 |
| 贝塞尔曲线插值 | - 用贝塞尔曲线连接路径点,通过调整控制点优化路径曲率; - 结合运动学约束(如最大速度、加速度)。 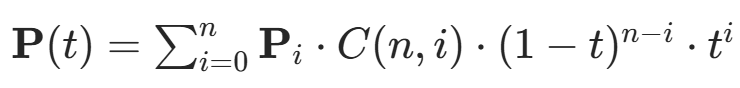 -
-:组合数 - 递归计算:
| 轮式机器人或无人车等非完整约束系统的路径规划。 |
| 动态窗口法(DWA)融合 | - APF 生成全局参考路径,DWA 在局部实时调整速度和转向; - 评价函数包含路径距离 、避障安全性 和运动平滑性。 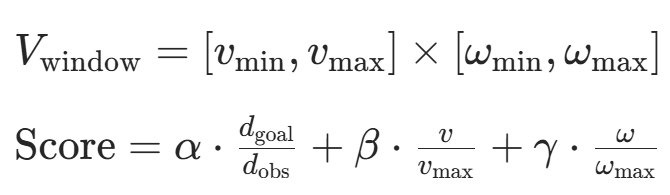 - - |
动态障碍物密集且需实时响应的场景(如无人船在港口避障)。 |
|---|
3.2.4混合算法与协同控制
| 算法名称 | 核心改进 | 适用场景 |
| RRT-APF | - RRT 生成全局路径框架,APF 进行局部精细化避障; - 动态调整 RRT 采样方向,优先向 APF 引导的低势场区域扩展。 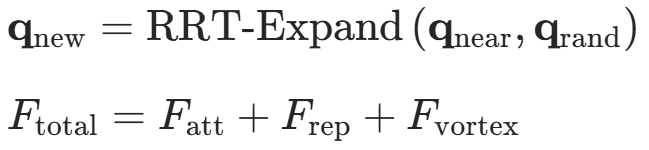 | 高维空间或复杂环境中的全局路径规划(如机械臂关节空间避障)。 |
| 高维空间或复杂环境中的全局路径规划(如机械臂关节空间避障)。 |
| A*-APF | - A算法提供全局最优路径,APF 处理局部障碍物; - 引入启发式势场加速 A搜索。 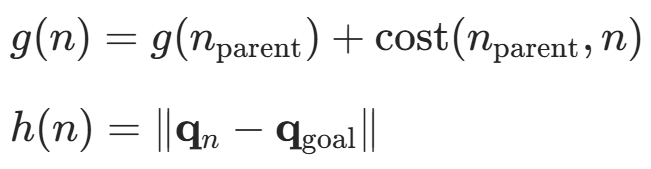 - A * 算法的启发式函数:
- A * 算法的启发式函数: - APF 提供局部障碍物信息 | 静态环境中对路径长度和安全性均有要求的场景(如室内机器人导航)。 |
| 多智能体协同 APF | - 构建多智能体斥力场 ,协调个体间距离; - 采用匈牙利算法分配虚拟目标点,形成紧密围捕阵型。 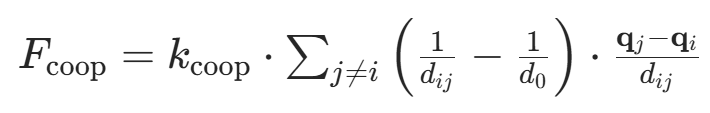 - - |
无人机蜂群协同攻击、仓储机器人集群搬运等多智能体任务。 |
|---|
3.2.5参数自适应与智能优化
| 算法名称 | 核心改进 | 适用场景 |
| 模糊自适应 APF | - 设计模糊规则动态调整引力 / 斥力系数; - 输入为障碍物距离和目标距离,输出为系数调整量。 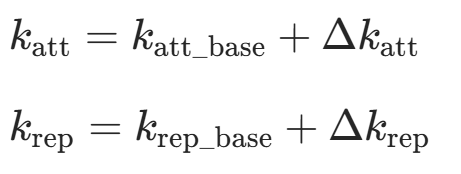 -
- :模糊规则输出的系数调整量 - 输入:障碍物距离、目标距离 | 环境复杂度变化大的场景(如机器人从开阔场地进入狭窄走廊)。 |
| 强化学习优化 | - 基于 ** 深度强化学习(DDPG)** 动态调整势场参数; - 奖励函数包含路径长度、避障成功率和震荡次数。 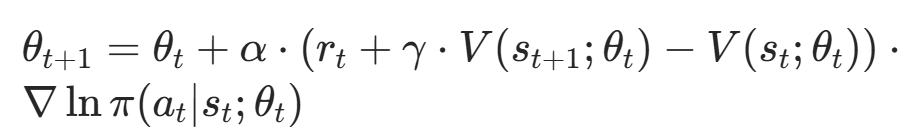 - 基于 DDPG 的势场参数优化 -
- 基于 DDPG 的势场参数优化 -:奖励函数(路径长度、避障成功率) | 未知环境或动态环境下的自主学习(如自动驾驶车辆在城市道路中优化避障策略)。 |
| 遗传算法改进 | - 用遗传算法优化势场函数参数(如 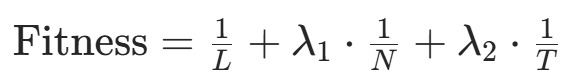 |
多目标优化场景(如路径最短 + 能耗最低的机器人导航)。 |
|---|
3.3 DS动态系统调制方法
DS(动态系统)调制是一种基于动态系统的反应式调制控制策略,通过构建连续的矩阵值调制函数重塑全局动态系统的流场,以实现机器人在含非凸障碍环境中的导航,且需满足不可穿透性、收敛性、实时性等准则。其优点是能处理复杂非凸障碍、支持实时控制(如 1kHz 控制环速率)且具备不可穿透性与收敛性的理论保证。
3.4 强化学习
下面是强化学习的改进算法
| 算法类别 | 代表算法 | 核心改进机制 | 适用场景 |
| 单智能体 | PPO、DDPG、Sarsa、A3C、 | 策略梯度优化、连续动作空间处理、稳定性提升 | 机器人导航、无人机路径规划 |
| 多智能体 | MA-PPO、MA-TRPO、MA-DDPG、MA-DQN、MATD3 | 集中式训练、智能体间协作、通信机制改进 | 无人机编队、机器人协作搬运 |
| 动态环境 | DWA-RL | 运动学约束、动态障碍物预测、多环境并行训练 | 自动驾驶、动态仓储物流 |
| 混合算法 | HOPE | 传统算法与 RL 结合、先验知识引入、动作掩码机制 | 复杂停车、狭窄通道导航 |
| 多目标优化 | HRL | 任务分解、多目标奖励函数设计 | 工业机器人多任务执行、救援场景 |
|---|
以下是专门针对路径规划核心缺点(如稀疏奖励、局部最优、动态冲突等)进行针对性改进的强化学习(RL)算法
| 算法名称 | 针对的路径规划核心缺点 | 核心改进机制(RL 层面的针对性设计) | 适用场景 |
|---|---|---|---|
| HER 增强型路径规划算法 | 稀疏奖励(仅到达终点有奖励,中途无反馈导致学习缓慢) | 采用后见之明经验回放(Hindsight Experience Replay, HER):将未达目标的轨迹,以 "轨迹中某点为虚拟目标" 重新标注奖励,丰富经验池中的有效样本,加速 RL 对 "接近目标" 行为的学习。 | 室内机器人导航、无人机定点飞行、AGV 点对点运输(目标明确且环境静态 / 低动态) |
| A * 启发式引导 DQN | 局部最优(陷入墙角、绕障碍物循环,无法探索全局最优路径) | 在 DQN 的价值函数更新 或动作选择 中融入 A算法的启发式信息(如曼哈顿距离、欧氏距离): 1. 价值函数增加 "与 A 参考路径的偏差惩罚"; 2. 动作选择时优先保留 "向 A * 目标方向" 的候选动作,避免局部陷阱。 | 栅格地图下的移动机器人(如仓储机器人)、静态障碍物环境(如实验室巡检) |
| 动态环境预测 DDPG | 动态环境适应性差(障碍物移动 / 环境变化导致已规划路径失效) | 在 DDPG 的状态输入层 加入障碍物运动预测模块(如基于 LSTM/Transformer 预测障碍物下一步位置),并将预测结果融入 Actor-Critic 网络:使 RL 能 "前瞻性" 规划路径,避免与移动障碍物碰撞。 | 动态交通场景无人车、商场服务机器人(人群移动)、多移动障碍物室内环境 |
| MADDPG 多智能体路径算法 | 多智能体冲突(多机器人 / 无人机碰撞、路径拥堵,缺乏协作机制) | 每个智能体的Critic 网络 同时接收 "自身状态 - 动作" 和 "其他智能体状态 - 动作" 信息,实现 "全局视角" 的价值评估; Actor 网络通过 "最小化群体冲突惩罚" 优化策略,达成协作避碰。 | 多 AGV 协同运输(工厂车间)、多无人机编队飞行、密集人群中服务机器人集群 |
| 安全约束 PPO(CPPO) | 路径安全性低(易碰撞障碍物、违反物理约束,如机器人关节限位 / 速度超限) | 在 PPO 的策略更新 中加入硬安全约束项 (通过拉格朗日乘数法实现): 1. 奖励函数增加 "碰撞惩罚""安全距离不足惩罚"; 2. 策略更新时强制满足 "与障碍物最小距离≥安全阈值",避免突破安全边界。 | 高安全需求场景:手术机器人、核电站巡检机器人、狭窄空间移动(如管道机器人) |
| 分层强化学习:Option-Critic 框架 | 长距离规划不稳定(长路径下信用分配困难、轨迹发散,学习效率低) | 将长距离规划拆分为多层子任务 (如 "起点→中间点 A→中间点 B→终点"),通过 Option-Critic 框架学习: - 高层策略:选择 "当前应执行的子任务"; - 低层策略:执行子任务内的动作(如避障、转向),降低长任务的学习复杂度。 | 大范围室外导航(园区 / 矿区巡检机器人)、自动驾驶长途路径规划、多区域连通场景(机场 / 火车站) |
| DWA-RL | 动态环境中运动学约束与避障决策的冲突(纯 DWA 缺乏全局决策能力,纯 RL 易忽略物理约束导致路径不可行) | 融合动态窗口法(DWA)的运动学约束与 RL 的决策能力: 1. 利用 DWA 生成符合机器人速度 / 加速度限制的候选动作集(速度窗口); 2. RL 基于环境状态(障碍物位置、目标方向)评估候选动作的奖励(如安全距离、目标接近度),选择最优动作; 3. 通过奖励函数强化 "满足运动学约束" 的行为,避免 RL 输出物理不可行的路径。 | 自动驾驶车辆动态避障、室内服务机器人在人群中导航、移动机器人高速运动场景(需兼顾实时性与物理可行性) |
四、OMPL规划库
OMPL(Open Motion Planning Library,开源运动规划库)是机器人运动规划领域的核心开源工具库,由斯坦福大学等机构主导开发,专注于提供高效、灵活的运动规划算法实现,广泛应用于移动机器人、机械臂、无人机、自动驾驶等领域。它的核心定位是 "算法库" 而非 "完整解决方案"------ 不直接包含机器人建模或可视化功能,而是通过模块化设计,方便开发者集成到具体的机器人系统中。
Planner Developer Tools(PDT规划器开发工具)官方网站: https://robotic-esp.com/code/pdt/
OMPL官方网站 :https://ompl.kavrakilab.org/
下面是一些OMPL的教程