1. 论文基本信息
标题:Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
作者:Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, Yue Zhang
发表:ICLR 2024(含 arXiv 版本 arXiv:2310.05130)
领域关键词:Large Language Models, Machine-Generated Text Detection, Zero-shot Detection, Probability Curvature, Conditional Probability
论文链接:
2. 前言
这篇论文要解决的核心问题,是如何在零样本(zero-shot)条件下区分"人写的文字"和"大模型写的文字",同时还能跑得又快又准。现有最强的零样本检测器 DetectGPT 虽然效果不错,但代价是要对每一段文本做上百次模型调用,算一次检测就像跑了一个小型 benchmark,一点都不"工程友好"。
作者提出的 Fast-DetectGPT 给出的答案是:利用条件概率曲率(conditional probability curvature)来刻画"这段话在模型眼里是不是一个局部最优的选词结果"。直觉上,机器写的文本更偏向"统计上最优"的用词,而人类写的文本没那么"贪心"。围绕这个直觉,他们设计了一个新的特征,并据此构造了 Fast-DetectGPT 检测器。
在性能上,Fast-DetectGPT 相比 DetectGPT:
- 在五个开源源模型上的 AUROC 从 0.9554 提升到 0.9887;
- 对 ChatGPT / GPT-4 文本的检测 AUROC 从 0.72 左右提升到 0.93 左右;
- 推理速度快了约 340 倍(在 XSum 数据集,Tesla A100 上测试)。
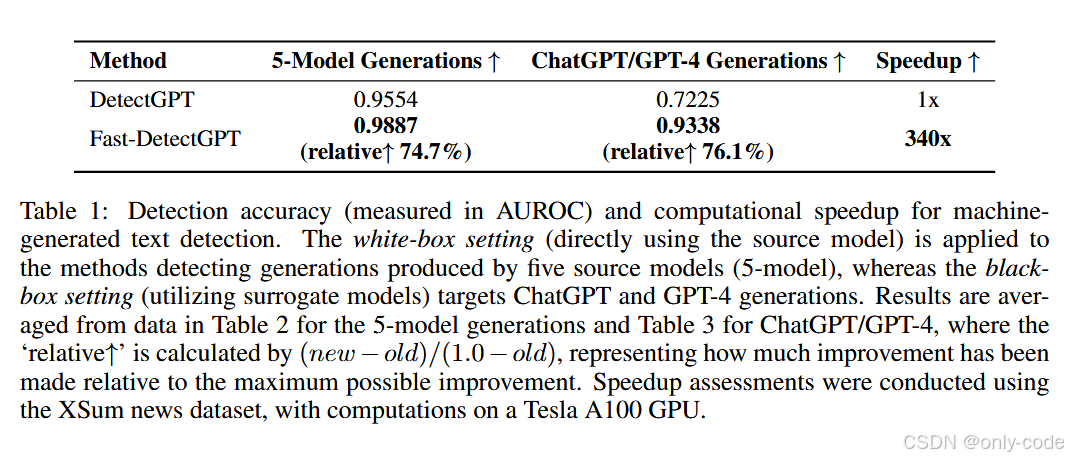
【插图:整体结果与速度对比表,对应论文 Table 1】
从应用视角看,这篇工作意义在于:第一次把"基于概率曲率的零样本检测"做到了既可落地、又在强模型上依然有效 ,而且给出了一个挺有意思的新假设------人和机器在"给定上下文的 token 选择行为"上存在统计上的可检测差异。
3. 历史背景与前置技术:从"平均概率"到"概率曲率"
要理解 Fast-DetectGPT,得先回顾一下这条技术线的演化:
最早大家做机器文本检测,大多走的是监督学习路线:收集一批人类文本和一批模型生成的文本,训练一个分类器(比如 RoBERTa)来预测"human vs. machine"。这类方法在训练分布内表现很好,但一旦换模型、换领域,性能就崩得厉害------典型的过拟合问题。
于是另一条路线兴起:零样本检测(zero-shot detection)。核心思路是:既然语言模型本身就是一个强大的概率模型,那我们直接用它来给文本打分,不额外训练分类器。代表性的统计特征包括:
- Likelihood / Perplexity:直接看平均 log 概率或困惑度;
- Entropy:看预测分布的平均熵;
- LogRank / LRR:看真值 token 在预测分布里的排名及其组合;
- Completion Divergence(DNA-GPT 等):看截断后续写的多样性;
- Probability Curvature(DetectGPT):这是本文的直接前辈。
DetectGPT 的核心设想是:如果一段文本是模型自己生成的,那么围绕它做一些小扰动,再让同一个模型打分,原文的 log 概率往往会高于这些"扰动版本";而人类文本则不一定。因此,它定义了一个"概率曲率":
d DetectGPT ( x ) = log p θ ( x ) − E ∗ x ~ ∼ q ∗ ϕ ( ⋅ ∣ x ) log p θ ( x \~ ) d_{\text{DetectGPT}}(x) = \log p_\theta(x) - \mathbb{E}*{\tilde x\sim q*\phi(\cdot\mid x)}\big\\log p_\\theta(\\tilde x)\\big dDetectGPT(x)=logpθ(x)−E∗x~∼q∗ϕ(⋅∣x)logpθ(x\~)
这里 p θ p_\theta pθ 是打分用的模型, q ϕ q_\phi qϕ 是生成扰动文本的掩码语言模型(比如 T5)。如果 d d d 明显为正,就倾向判定为机器文本。问题在于:要估计这个期望,需要对每段文本生成几十甚至上百个扰动版本,并逐个调用打分模型,计算代价非常高。
同时,已有工作也观察到:机器文本的平均 log 概率通常高于人类文本,但直接用平均 log 概率当特征,在面对更强的源模型、不同解码策略以及跨领域场景时,性能并不稳。DetectGPT 通过曲率把"局部形状"引入进来,是一大进步,但计算成本成了致命弱点。Fast-DetectGPT 正是在这个节点上提出的新方案。
4. 论文核心贡献:把"曲率"搬到 token 级的条件概率上
我自己的理解是,这篇论文的核心贡献可以浓缩成一句话:把 DetectGPT 的"全句概率曲率",重构成了"基于条件概率的局部曲率",并用一个极其高效的采样与打分流程实现出来。
更细一点看,可以拆成几层:
首先,作者提出了一个新的假设:把文本生成看成一个按 token 的序列决策过程时,机器和人类在"给定上下文选择下一个 token"的方式有系统性差异 。机器因为在大规模语料上做过最大似然训练,更倾向于选"统计上最常见"的 token;而人更像是在按语义与意图组织语言,不会始终沿着最高概率的 token 走。这意味着:如果把"原文 token 的 log 概率"放入"同一上下文下所有备选 token 的分布"里,大模型生成的 token 更可能是这个分布中"凸起来"的那部分。
其次,他们围绕这个假设定义了**条件概率曲率(conditional probability curvature)**这一新特征:不再看整条 Markov 链的概率变化,而是把"原文的 log 概率"和"在同一上下文下大量采样 token 的 log 概率分布"做标准化比较。
然后,以这个特征为基础,作者设计了 Fast-DetectGPT 检测器:只需要对原文做一次前向计算、一次大规模采样,就可以同时得到所有 token 的条件分布和样本得分,完全避免了 DetectGPT 中"对每一个扰动文本单独打分"的多次模型调用。
最后,通过一系列实验,他们展示了:在白盒和黑盒设置下,Fast-DetectGPT 在准确率上都显著优于 DetectGPT 和其他零样本方法,同时在 ChatGPT / GPT-4 这样的闭源大模型上也有很强的检测能力。
5. 方法详解:Fast-DetectGPT 是怎么"看曲率"的?
5.1 任务设定:白盒 vs 黑盒
论文仍然把任务定义成一个二分类问题 :给定一段文本 x x x,判断它是人写的还是由某个源模型生成的。
- 白盒设定:可以访问源模型本身(比如要检测 GPT-J 生成的文本,就直接用 GPT-J 打分)。
- 黑盒设定:不知道源模型,或者不能访问,只能选一个"代理模型"(surrogate model)来对文本打分,比如用 Neo-2.7 来检测 ChatGPT / GPT-4 的文本。
无论哪种设定,Fast-DetectGPT 都围绕**采样模型 q ϕ q_\phi qϕ + 打分模型 p θ p_\theta pθ**这对组合展开,只是白盒时两者往往就是同一个源模型,黑盒时则需要额外挑一个合适的 q ϕ q_\phi qϕ。
5.2 先回顾 DetectGPT 的三步走
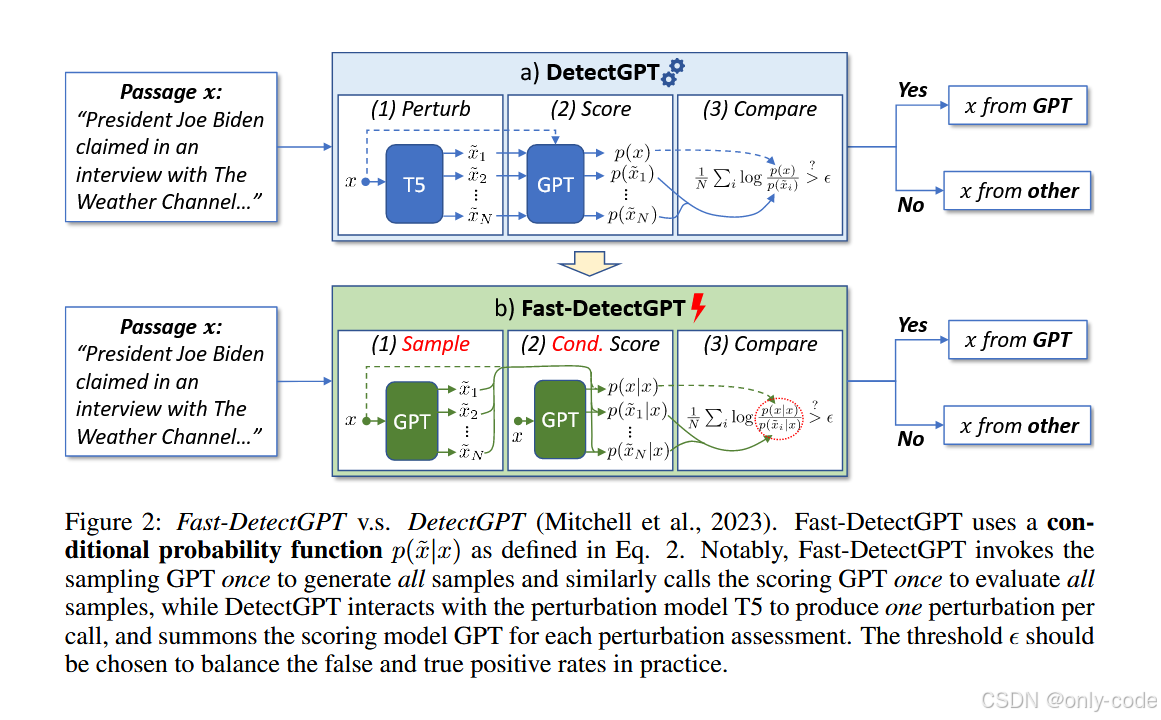
【插图:DetectGPT 流程示意,对应论文 Figure 2(a)】
DetectGPT 的 pipeline 很经典,分三步:
- Perturb :用掩码语言模型(T5)对原文做轻微改写,生成若干个"扰动版本" x ~ \tilde x x~;
- Score:用打分模型(通常就是源 GPT)分别计算原文和每个扰动文本的 log 概率;
- Compare:把原文的 log 概率减去扰动文本 log 概率的平均值,得到一个"概率曲率"分数。
问题出在第二步:哪怕扰动文本只动了 15% 的 token,你仍然得对整句重新计算一次 log 概率,这意味着每个扰动都要一次完整前向;几十上百个扰动就对应几十上百次模型调用,成本极高。
5.3 条件概率曲率:把目光拉近到 token 级
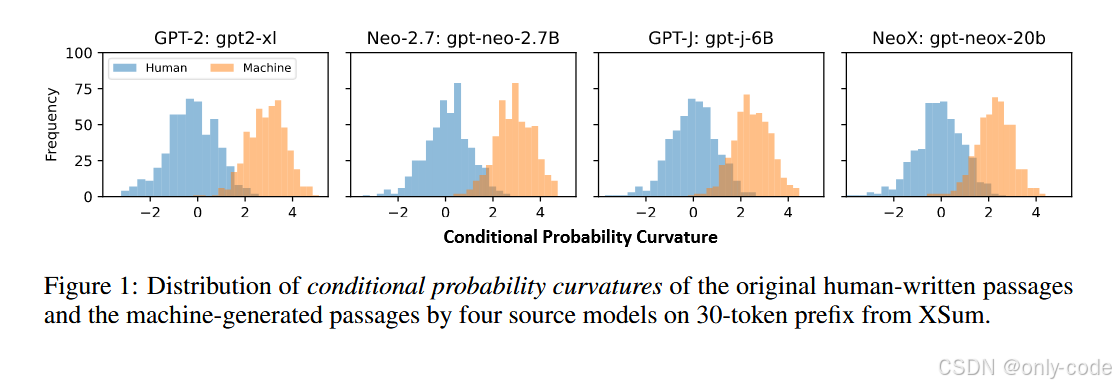
【插图:Conditional Probability Curvature 分布,对应论文 Figure 1】
Fast-DetectGPT 的关键转折是:不再从"整条链的 joint 概率"出发,而是只看"给定原文上下文时,每个位置的条件分布"。
定义一个条件概率函数:
p θ ( x ~ ∣ x ) = ∏ j p θ ( x ~ j ∣ x < j ) p_\theta(\tilde x\mid x) = \prod_j p_\theta(\tilde x_j \mid x_{<j}) pθ(x~∣x)=j∏pθ(x~j∣x<j)
这里 x < j x_{<j} x<j 是原文在位置 j j j 之前的前缀, x ~ j \tilde x_j x~j 是在这个上下文下采样得到的备选 token。注意一个细节:条件是在原文上,而不是在采样序列上 ,这意味着所有位置的采样都是条件独立的,后面会看到这点对效率影响巨大。
当 x ~ = x \tilde x = x x~=x 时,上式就退化成
p θ ( x ∣ x ) = p θ ( x ) p_\theta(x\mid x) = p_\theta(x) pθ(x∣x)=pθ(x)
也就是原文自身的概率。接下来,作者把 DetectGPT 的"概率曲率"改写成基于条件概率的标准化分数:
d Fast ( x ) = log p θ ( x ∣ x ) − μ ~ σ ~ d_{\text{Fast}}(x) = \frac{\log p_\theta(x\mid x) - \tilde\mu}{\tilde\sigma} dFast(x)=σ~logpθ(x∣x)−μ~
其中:
- μ ~ \tilde\mu μ~ 是在同一条件 x x x 下,对大量采样文本 x ~ ∼ q ϕ ( x ~ ∣ x ) \tilde x\sim q_\phi(\tilde x\mid x) x~∼qϕ(x~∣x) 的 log 概率 log p θ ( x ~ ∣ x ) \log p_\theta(\tilde x\mid x) logpθ(x~∣x) 的期望;
- σ ~ 2 \tilde\sigma^2 σ~2 是这些 log 概率的方差。
直觉上,如果原文本身就是模型在这个上下文下"最自然"的输出,那么 log p θ ( x ∣ x ) \log p_\theta(x\mid x) logpθ(x∣x) 在这个采样分布里会明显高于平均值 ,于是 d Fast ( x ) d_{\text{Fast}}(x) dFast(x) 会是一个正且绝对值较大的数;反之,人类文本更像是在这个分布中"既不特别突出,也不特别异常"的区域徘徊,曲率接近 0。
Figure 1 给出了一个非常直观的统计结果:在 XSum 上,四个源模型生成的文本的条件概率曲率大多集中在 3 左右 ,而人类写的文本则大多集中在 0 附近,两者的分布几乎没有重叠,这就为这个特征的有效性提供了强有力的经验支持。
5.4 条件独立采样:用一次前向生成一万条"虚拟候选"
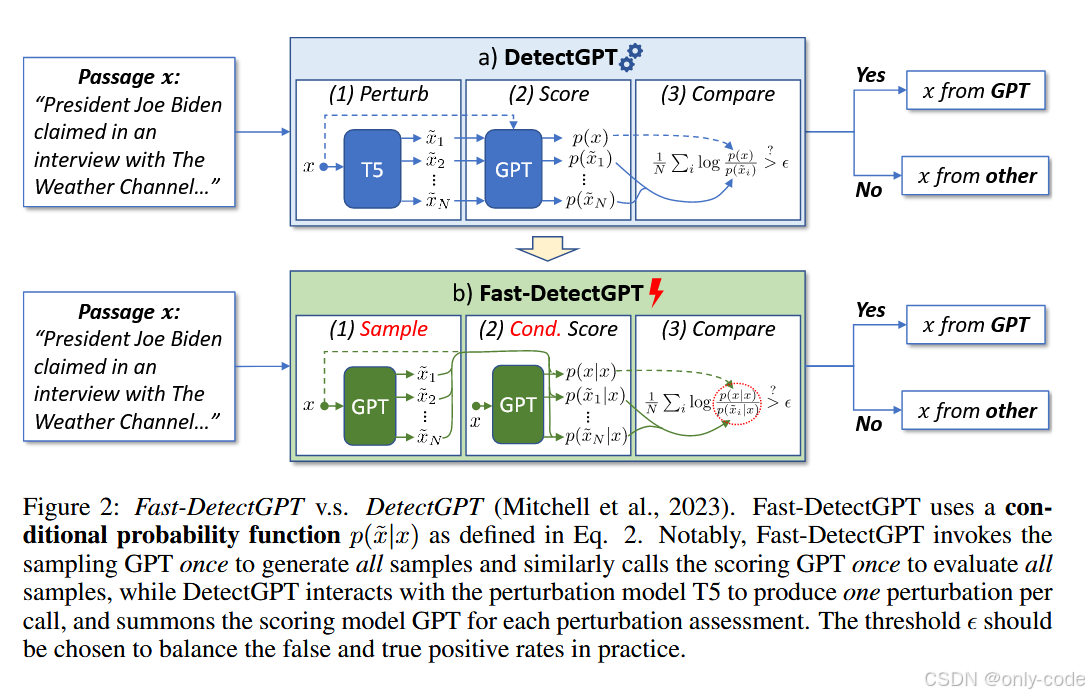
【插图:Fast-DetectGPT vs DetectGPT 框架图,对应论文 Figure 2(b)】
有了条件概率曲率的定义,还差的就是如何高效地估计 μ ~ \tilde\mu μ~ 和 σ ~ \tilde\sigma σ~。这里作者用到了一个非常工程友好的 trick:条件独立采样。
具体来说,对每个位置 j j j,我们从采样模型 q ϕ ( x ~ j ∣ x < j ) q_\phi(\tilde x_j\mid x_{<j}) qϕ(x~j∣x<j) 的预测分布中采样若干个 token。因为所有位置都是基于原文前缀 x < j x_{<j} x<j 独立抽样,我们可以:
- 把整段原文喂给采样模型,拿到每个位置的 logits;
- 然后直接用张量操作在每个位置上批量采样,比如"一口气抽 10,000 次";
- 这一步只需要一次前向传播。
随后,用打分模型 p θ p_\theta pθ 在同样的上下文 x < j x_{<j} x<j 下,对这些采样 token 计算条件 log 概率,同样可以通过一次前向把整个分布算出来,再用索引取出对应 token 的 log 概率。作者在论文中给了一个 PyTorch 示例:用 Categorical(logits=lprobs).sample([10000]) 就能实现"每个位置采一万次"。
Fast-DetectGPT 的完整检测流程在算法 1 中给出,大致是:
- Conditional sampling :在条件 x x x 下,从 q ϕ ( x ~ ∣ x ) q_\phi(\tilde x\mid x) qϕ(x~∣x) 抽样 N N N 个候选 x ~ i \tilde x_i x~i;
- Scoring :用 p θ p_\theta pθ 计算 log p θ ( x ~ i ∣ x ) \log p_\theta(\tilde x_i\mid x) logpθ(x~i∣x) 的平均和方差,得到 μ ~ \tilde\mu μ~ 和 σ ~ \tilde\sigma σ~;
- Curvature :根据定义计算 d Fast ( x ) d_{\text{Fast}}(x) dFast(x);
- Decision :把这个分数与阈值 ϵ \epsilon ϵ 比较,超过则判为"机器文本"。

【插图:Fast-DetectGPT 算法伪代码,对应论文 Algorithm 1】
论文还在附录中给出了一个解析解 :利用条件独立性,可以在词表上直接求和,精确计算 μ ~ \tilde\mu μ~ 和 σ ~ 2 \tilde\sigma^2 σ~2,而不必做蒙特卡洛采样。作者发现这个解析解在精度上几乎和 10,000 次采样一致,推理速度还能再快约 10%。
5.5 与 Likelihood / Entropy 的关系:一个"加一点归一化"的组合
还有一个有趣的点:当采样模型和打分模型相同,即 q ϕ = p θ q_\phi = p_\theta qϕ=pθ 时,条件概率曲率的分子
log p θ ( x ∣ x ) − μ ~ \log p_\theta(x\mid x) - \tilde\mu logpθ(x∣x)−μ~
其实就是两个经典特征的组合:
- log p θ ( x ∣ x ) \log p_\theta(x\mid x) logpθ(x∣x) 可以看作 Likelihood baseline;
- μ ~ \tilde\mu μ~ 对应的是条件分布上的 负 entropy。
也就是说,Fast-DetectGPT 在本质上是把 Likelihood 和 Entropy 两个老特征做了一个标准化的线性组合 ,再加上一个方差归一化 σ ~ \tilde\sigma σ~。作者在消融实验里发现,单独用 Likelihood 或 Entropy 都不够好,组合再标准化之后,检测性能会稳定地提升。
从直觉上看,这也合理:原始 log 概率在不同上下文里的方差很大,直接比较不够稳,而减去"该位置上所有候选 token 的平均 log 概率"相当于给每个位置做了一个动态基准,再除以标准差,则把不同句子、不同模型之间的尺度差异抹平,使得同一个阈值在跨模型、跨数据集时也更好用。
6. 实验结果
6.1 实验设置:数据集、源模型与对比方法
作者沿用了 DetectGPT 的实验框架,用六个数据集覆盖不同领域与语言:新闻(XSum)、Wikipedia 段落(SQuAD)、故事写作(WritingPrompts)、机器翻译基准 WMT16 英德双语,以及生物医学问答(PubMedQA)。每个数据集随机采样 150--500 个人工样本作为负例,再用各个源模型在相同前缀下生成等量的正例。
源模型方面,既包括 GPT-2、OPT-2.7B、GPT-Neo-2.7B、GPT-J、GPT-NeoX 等开源模型,也包括 GPT-3、ChatGPT(gpt-3.5-turbo)和 GPT-4;参数量覆盖 1.3B 到 175B 以上。大多数开源模型在本地 A100 上跑,闭源模型通过 OpenAI API 调用。
对比方法则覆盖了:
- 零样本统计特征:Likelihood、Entropy、LogRank、LRR、DNA-GPT;
- 概率曲率系的 DetectGPT 与 NPR;
- 监督方法:RoBERTa-base / large GPT-2 detector、商用 GPTZero。
评测指标统一用 AUROC,并给出了"相对提升"(在当前分数到 1.0 的区间内提升的比例),方便比较不同基线上的相对收益。
6.2 核心结果:白盒与黑盒的全面胜出
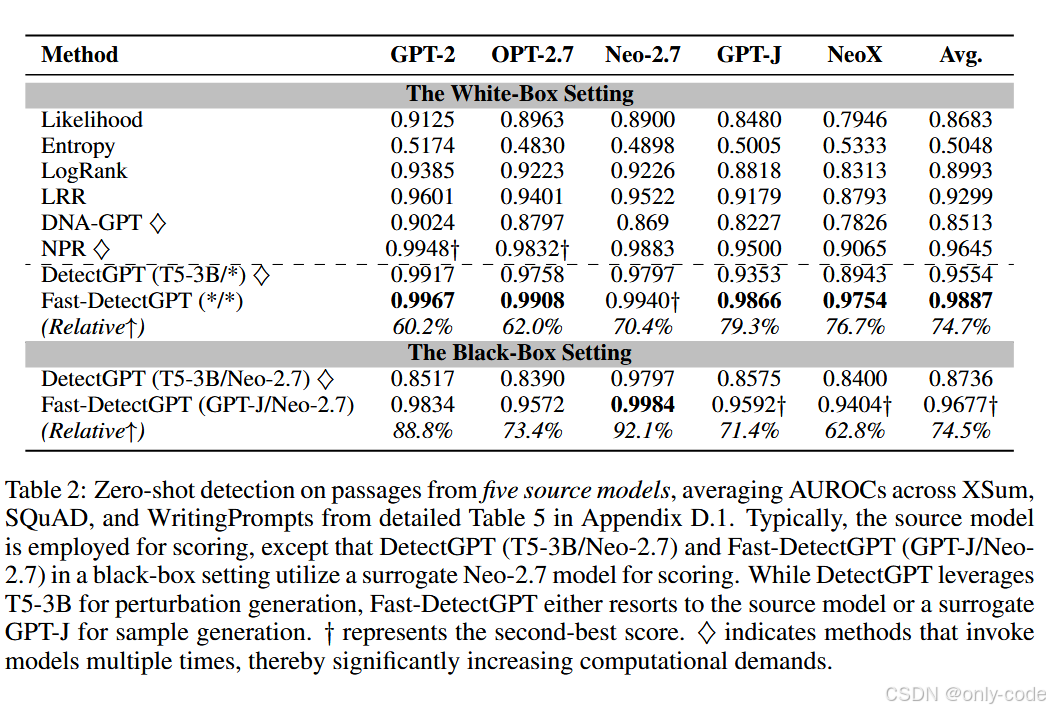
【插图:五个源模型的平均 AUROC,对应论文 Table 2】
在白盒设定下,Fast-DetectGPT 在 XSum、SQuAD、WritingPrompts 三个数据集、五个源模型的平均 AUROC 达到 0.9887 ,相比 DetectGPT 的 0.9554 有明显提升,按论文的"relative↑" 计算约为 74.7% 的相对提升。在很多单模型上,它几乎达到"接近完美"的 0.99+。
在黑盒设定下,作者以 Neo-2.7 作为打分模型,用 GPT-J 作为采样模型来检测其他源模型的文本。即使如此,Fast-DetectGPT 仍然在平均意义上比 DetectGPT 高出 0.09 左右的 AUROC ,对应约 74.5% 的相对提升 。这表明条件概率曲率确实能作为一种跨模型的"普适特征"。
更有意思的是,当检测 GPT-3 / ChatGPT / GPT-4 的生成时,Fast-DetectGPT 在纯黑盒条件下依然走在前面:
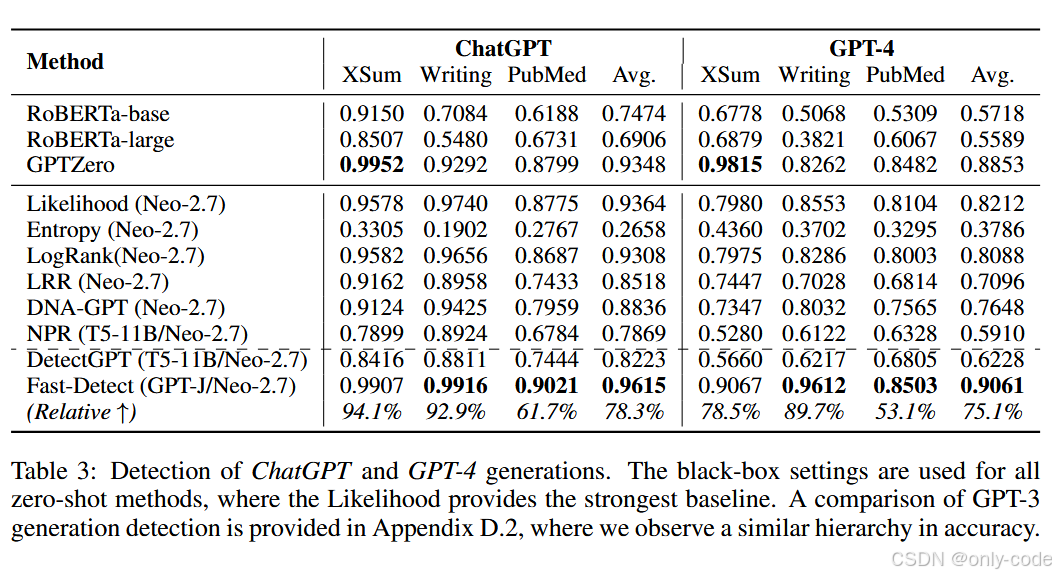
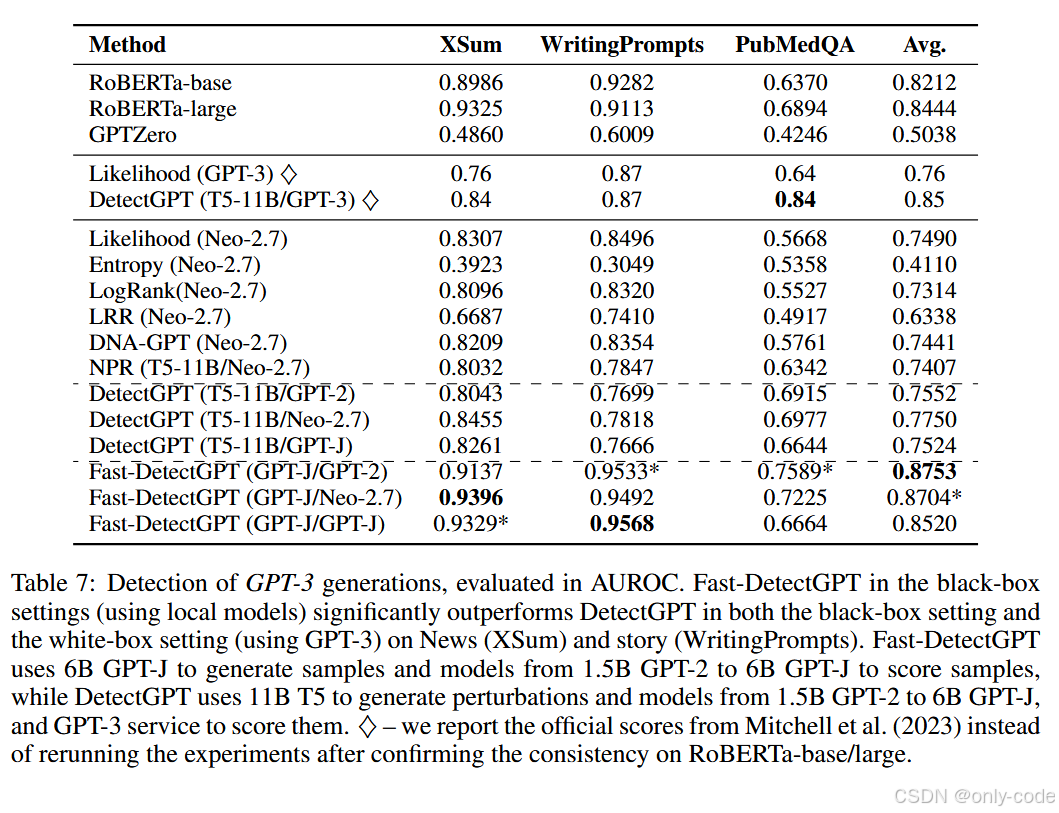
【插图:ChatGPT / GPT-4 检测结果表,对应论文 Table 3 和 Table 7】
- 对 ChatGPT,平均 AUROC 约 0.96 ,比 DetectGPT 高出约 0.14;
- 对 GPT-4,平均 AUROC 约 0.91,同样显著优于 DetectGPT 和各类监督检测器;
- 对 GPT-3,使用本地代理模型打分,也能明显超越 DetectGPT 和 RoBERTa 检测器。
从业务视角看,这意味着:即便你手头只有一个中等规模的开源模型,也能在没有标签数据、没有源模型访问权限的情况下,对主流闭源大模型的输出做出高质量的检测。
6.3 速度:从"夜间批处理"到"实时调用"
作者在 XSum 上对五个源模型做了速度评估:
- DetectGPT:即使使用 GPU 批处理,把 100 个扰动分成 10 个 batch 跑,完整检测一份数据也要 7.9 万秒(约 22 小时);
- Fast-DetectGPT:同样的任务在 233 秒(约 4 分钟) 内完成,约 340 倍提速。
这个数量级的差异,基本把 DetectGPT 从"线上不太现实"变成了"工程上可接受",尤其是考虑到很多场景需要对海量短文本(评论、答案、作文等)做检测。
6.4 可用性分析:ROC 曲线、长度鲁棒性与跨域表现
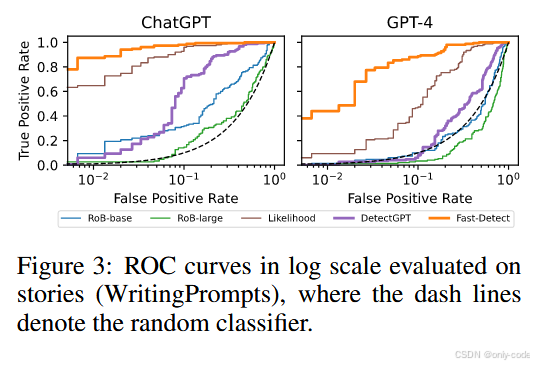
【插图:ROC 曲线,对应论文 Figure 3】
从 ROC 曲线来看,Fast-DetectGPT 在保持极低误报率时仍然有很高的召回:
- 对 ChatGPT 文本,当误把人类文本判成机器文本的比例控制在 1% 时,Fast-DetectGPT 仍然能召回约 87% 的机器文本;
- 同样的假阳性率提高到 10% 时,召回率接近 98%;
- 对 GPT-4,任务更难,但在 10% 假阳性率下仍能保持约 89% 的召回 。

【插图:不同长度的检测性能曲线,对应论文 Figure 4】
文本长度方面,Fast-DetectGPT 的表现也比较"符合直觉":
- 随着文本从几十词增长到 180 词,AUROC 基本单调上升,短文本性能略低,长文本性能更稳定;
- 相比之下,一些监督检测器在 GPT-4 场景下反而出现"文本越长越差"的现象,而 DetectGPT 在长文本时也出现了非单调的波动。
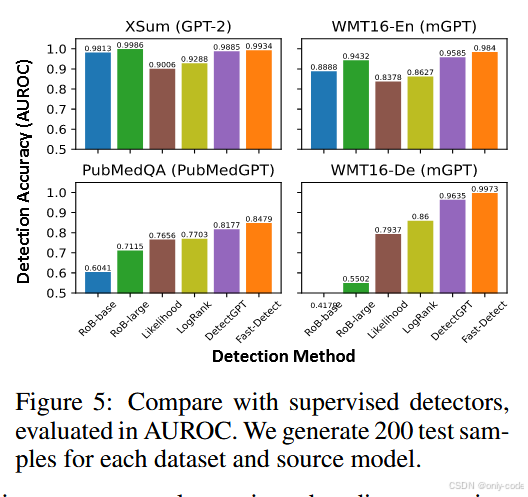
【插图:跨领域与跨语言对比柱状图,对应论文 Figure 5】
在跨领域、跨语言实验中,Fast-DetectGPT 在新闻(XSum)、英语 WMT、德语 WMT、PubMedQA 等多个数据集上:
- 在分布内(新闻)表现与监督检测器相当甚至略优;
- 在分布外(生物医学、德语)则明显领先 RoBERTa 与 GPTZero 等监督方法;
- 同时在所有数据集上都比 DetectGPT 更稳。
结合上面的结果,可以说 Fast-DetectGPT 的"通用性"确实强:它不依赖特定领域、不依赖特定模型家族,更多是利用了"LLM 作为概率模型"的共性。
6.5 消融实验:采样模型、归一化与解码策略
在附录中,作者做了几组有意思的消融:
-
采样模型的选择 :当用 GPT-J 作为通用采样模型,而打分仍然用源模型时,Fast-DetectGPT 的平均 AUROC 还能在原来的基础上再提升一点------约 0.002 的绝对提升,对应约 27% 的相对提升。说明一个更强、覆盖面更广的采样模型能帮助构造更"尖锐"的参考分布。
-
方差归一化 σ ~ \tilde\sigma σ~ 的作用:去掉归一化后,性能明显下降。对 DetectGPT 来说,归一化带来约 36% 的相对提升;对 Fast-DetectGPT 也有约 10% 的相对提升。
-
不同解码策略的鲁棒性:作者用 top-p、top-k 和不同 temperature(包括更"保守"的 p=0.9、k=30、T=0.6)生成文本,Fast-DetectGPT 在这些场景下依然稳定领先 DetectGPT,且在更"确定性"的生成设置下 AUROC 会进一步上升,符合"越像模板化输出越容易检测"的直觉。
-
对抗攻击 :在 paraphrase 攻击和作者提出的 decoherence 攻击(随机交换相邻词)下,所有方法都会掉点,但 Fast-DetectGPT 的性能降幅最小,整体仍优于其他零样本和监督方法。
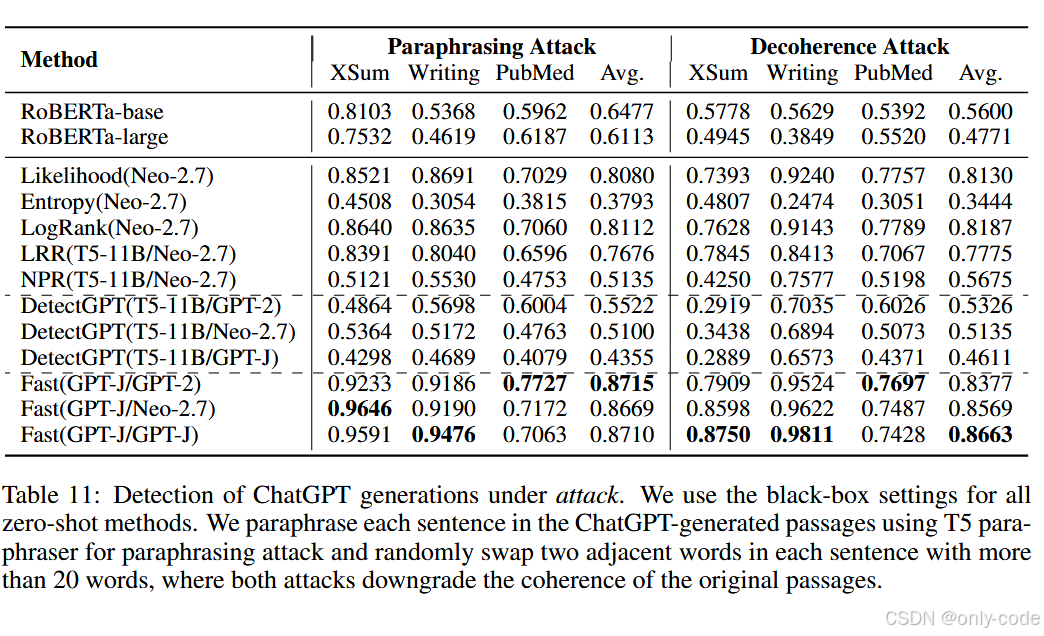
【插图:对抗攻击结果表,对应论文 Table 11】
7. 创新点与不足
从创新性来看,我觉得值得记住的地方主要有三个层次:
第一,从"全句概率曲率"切换到"条件概率曲率",是一个颇具洞察力的视角变化。它把人机差异从"这段话整体是不是模型高概率输出"拉到了"在每一步 token 选择上,机器是否更倾向于局部最优"这一层,这和我们对 LLM 训练目标的理解是高度契合的。
第二,条件独立采样 + 单次前向求分布 这个工程设计把原本难以落地的 DetectGPT 变成了一个真正"可部署"的方案------在保持甚至提升检测性能的前提下,推理成本骤降两个数量级。这对于需要大规模文本审核或学术检测的系统非常关键。
第三,Fast-DetectGPT 在大量实验上表现出较强的跨模型、跨领域、跨语言鲁棒性,尤其是对 ChatGPT / GPT-4 等闭源模型仍然有效,这让它更像是一个"实用工具",而不是只在开源小模型上好看的研究玩具。
当然,论文也非常坦诚地谈到了局限:
- 理论分析还比较初步:条件概率曲率为什么在统计上这么区分人机,其实还缺乏系统的理论证明,目前更多是经验与直觉支撑。作者也把深入的理论推导列为未来工作。
- 黑盒设定下依赖代理模型的覆盖能力:不同语言、不同领域下,很难有一个"万能的代理 LLM",如果代理模型对某个领域的建模能力不足,那么它对条件概率曲率的估计也会打折扣。论文在额外模型(如 BLOOM、Llama、Llama-2)上的结果就展示了这种"训练语料不匹配"带来的性能波动。
- 偏见与公平性问题:和所有 LLM-based detector 一样,它会继承底层模型在训练数据中的偏见(比如对非母语写作者的误报率更高)。作者在伦理章节里也专门提醒了这一点,建议未来用更包容的语料训练底层模型。
8. 总结
回到最开始的问题:怎么在不训练额外分类器的前提下,快速、稳健地检测出大模型写的文本? Fast-DetectGPT 的思路是:把文本生成看作一个按 token 决策的过程,利用机器和人类在"给定上下文时选词行为"上的统计差异,构造一个条件概率曲率特征,然后用高效的条件采样与打分流程,把这件事做成一个可用的检测器。
整体来看,Fast-DetectGPT 带来的观念变化主要有这几条:
- 检测人机文本,不一定要看"整句概率有多高",更重要的是看"在候选空间里有多凸起";
- 概率曲率这类原本昂贵的特征,可以通过条件独立假设和一次性采样被做得非常轻量;
- 一个设计得当的零样本特征,完全有机会在强源模型和现实场景中替代大部分监督检测器;
- 但只要底层 LLM 仍然带着偏见和覆盖不足,这类检测器也无法完全"中立",需要谨慎使用。
如果只看这一节,我会这样概括这篇论文:Fast-DetectGPT 把 DetectGPT 的思路"重构"到 token 级的条件概率空间里,在保持甚至提升检测效果的前提下,把计算代价压到了实际可用的量级,从而让"概率曲率检测"真正有机会走出论文、进入产品。