大家好,我是 方圆 。在前文 如何实现百万 QPS 下服务本地缓存的同步 和 百万 QPS 并发下缓存架构的演进 文章中我们谈到了多服务实例本地缓存的刷新和高性能系统架构的演进,本文是在这两篇文章的基础上再谈一谈在百万 QPS 并发下的系统,如何才能更好的满足性能和稳定性要求。
本地缓存的增量刷新
在 如何实现百万 QPS 下服务本地缓存的同步 中介绍了本地缓存的全量刷新,这种刷新机制比较简单但是也存在一些问题,比如:缓存刷新的时效低,在多台实例同时拉取较大的数据时,我们使用了令牌桶来协调,避免对二级缓存造成过大的压力,这也就会导致各个提供缓存的服务实例存在分钟级别的刷新延迟;本地缓存全量刷新会产生大量垃圾对象,触发 GC 造成接口性能的抖动。
第一个问题可以在网关层采用一致性哈希算法来解决多次访问接口请求到不同服务实例导致的结果不一致的问题,这个我们在 百万 QPS 并发下缓存架构的演进 提到过所以不再赘述,但是第二个问题造成的性能损失是无法接受的,因为一旦接口超时,商品数据不能展示会影响用户体验和业务的收益,所以在这一小节我们主要来谈一谈如何解决这个问题:通过本地缓存的增量刷新,避免 GC 对性能的影响。
在阅读开始前,需要了解 如何实现百万 QPS 下服务本地缓存的同步 中的内容。
data_change_event 数据变更记录表的变更
data_change_event 表用于记录各种不同数据变更的事件,为了实现增量刷新,我们需要在这张表上增加两个字段:
process_type: 处理类型 0-全量变更 1-增量变更event_content: 需要变更的内容,如果为全量变更,则该字段为 null;否则为需要增量变更的内容

这样我们便能通过 process_type 字段来判断是全量刷新还是增量刷新,如果是增量刷新,则通过 event_content 字段来获取需要变更的内容,这样直接将变更的内容刷新到本地缓存中即可完成增量缓存同步。
如下图所示,当 data_type_a 和 data_type_b 发生增量变更时,我们将它们记录到表中,注意增量变更也是有批次的概念的,每次处理事件时,需要将同一类型的所有事件全部查询出来一并按顺序处理:
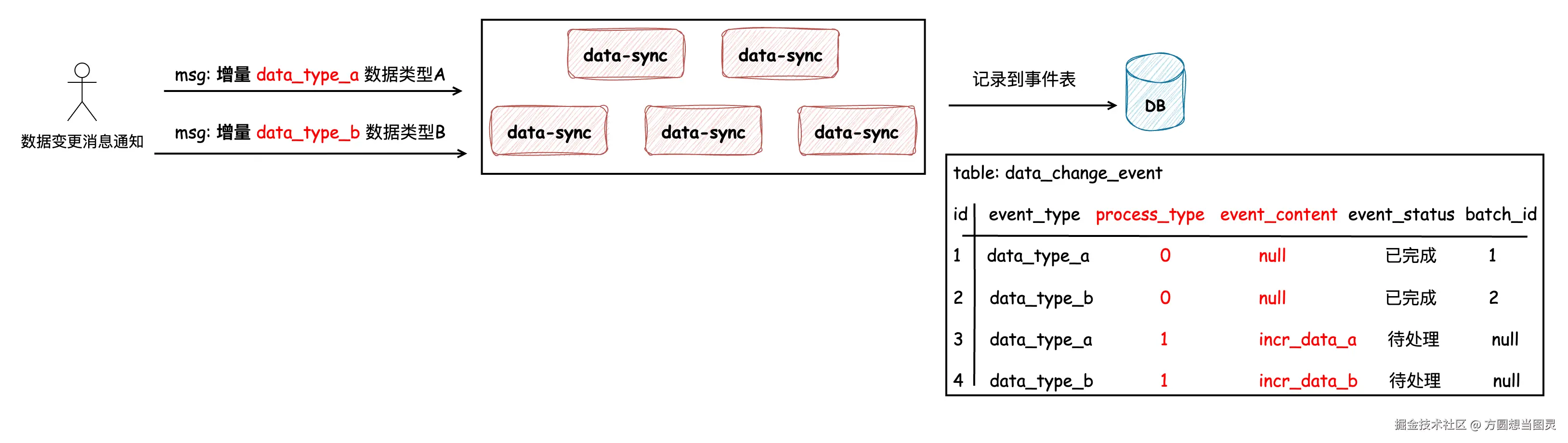
接下来就是处理增量变更的数据,将这些数据先同步到二级缓存中,再由各个 cache-provider 实例拉取到本地缓存。首先我们先看下将增量变更同步到二级缓存的流程,同样地,我们依然采用分布式定时任务处理的方式,定时任务的执行间隔决定了本地缓存刷新的速率 。分布式定时任务每次只处理 "一类" 增量刷新的事件,处理时先将状态变更为 "处理中" 并记录当前批次,将 增量变更的内容以及增量变更的版本 一同写入 "增量变更频道" 中,并且和全量变更一样,记录需要增量变更该版本的所有 cache-provider 的 IP,如下图所示:
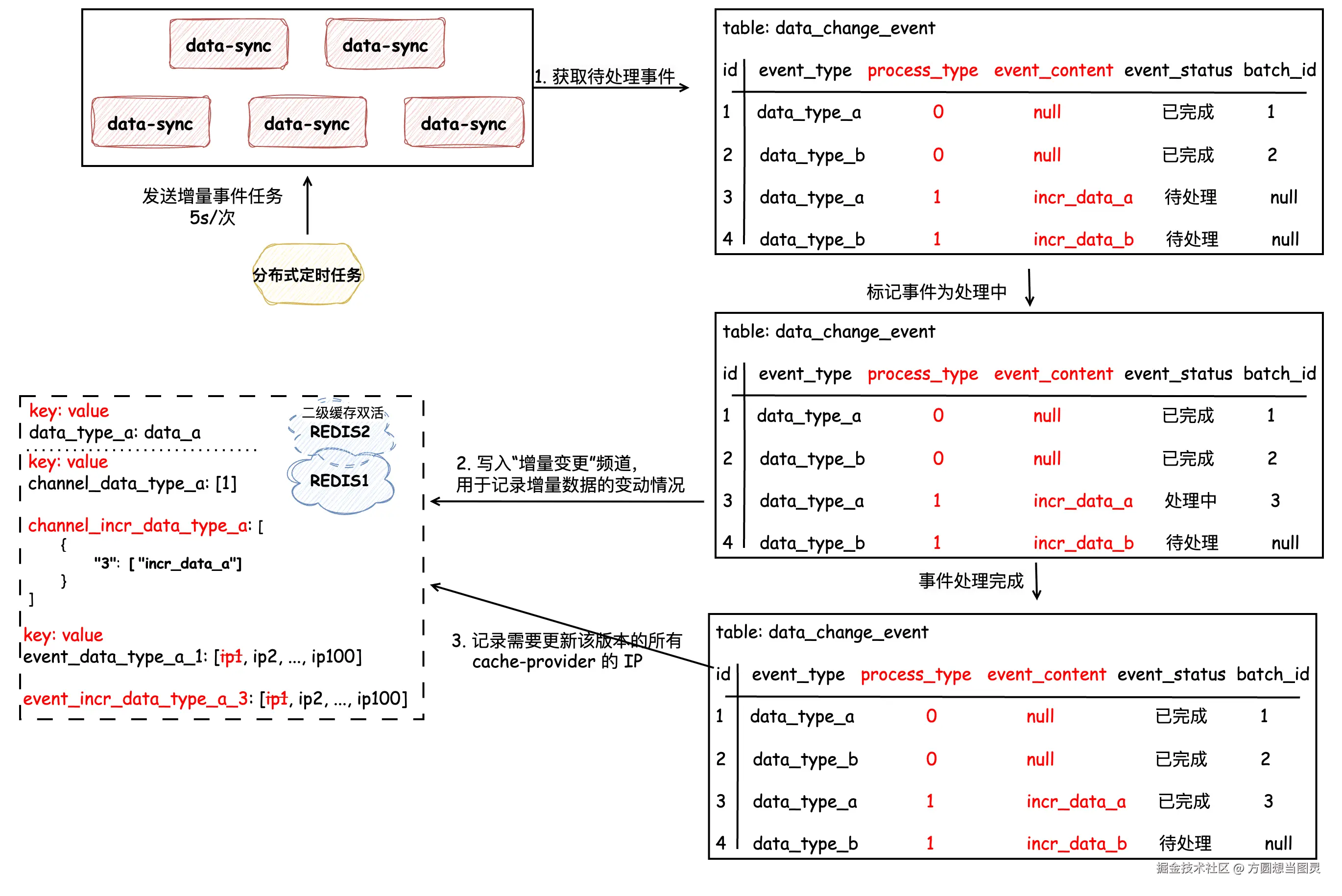
图中所示的二级缓存同时记录了
data_type_a全量变更和增量变更的数据。
这个流程看起来非常简单,但是实际上有很多需要注意的点:
data-sync 增量刷新一定要严格保证顺序刷新
在实际业务中,我们会在二级缓存的增量变更内容(如 incr_data_a)中记录是增加、修改还是删除的增量变更,那么这也就要求了对于 同一类型事件的处理必须严格保证顺序刷新,否则会造成数据不一致的场景,以如下数据为例:
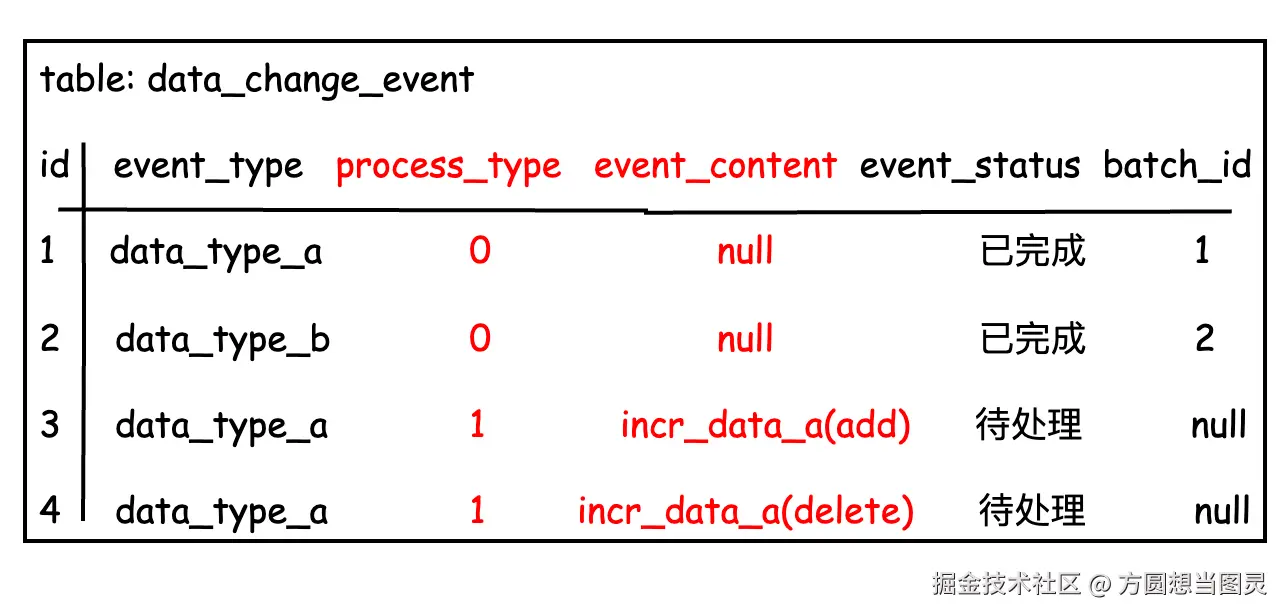
如果在事件表中同时有 incr_data_a 类型的两个事件需要处理,分别都是对同一缓存数据的新增和删除,如果不保证顺序,先刷新删除的缓存变更再刷新新增的缓存变更就会造成数据不一致。我举一个例子为什么会出现这种场景,比如现在表中只有一条 data_type_a 类型的事件需要刷新,此时执行定时任务处理该事件,但是此时又来了新的一条 data_type_a 类型事件,也被定时任务取走了,而如果前者还没有执行完毕,后者先执行完毕就会出现这种情况。因此,也就需要严格按照顺序处理事件,那么该如何做呢?
"当服务拿到某类型的事件后,查询数据库中是否有该类型仍为 处理中 的事件,如果有,证明先前有同类型未处理完的事件,所以本次任务需要直接结束,等待之前的任务处理,这样保证了顺序执行的万无一失"; 如果没有,证明该服务拿到的该类型的事件就是需要处理的那一批次,所以将本次需要处理的同类型事件全部标记为 "处理中" 即可:

两个 data_type_a 事件处理完成后,二级缓存中对应的 channel_incr_data_type_a 数据如下:
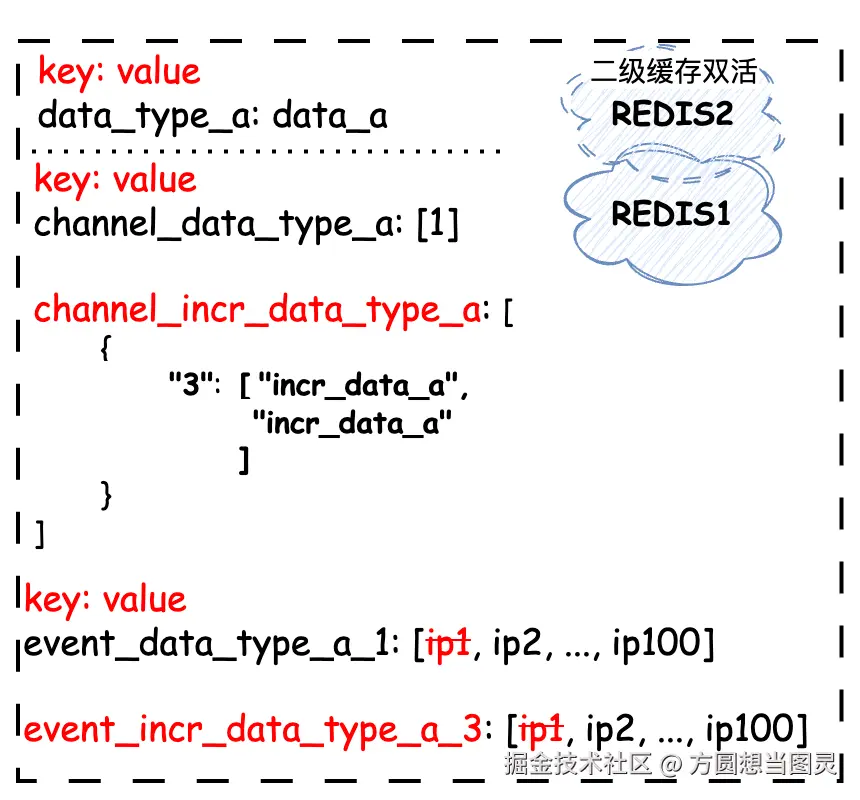
表示 3 批次下共处理了两个事件,两个事件被保存在有序的队列中,遵循 FIFO 原则。
批量更新同一批次中所有事件状态为 "处理中",还能保证能够并行处理其他类型的事件,比如 data_type_a 类型的事件都被标记为处理中了,那么下次任务再被发起时,扫描表中 "待处理" 的事件就不会扫描到 data_type_a 类型的事件,这样便能同时处理其他事件了。
增量变更频道是一个 FIFO 队列
增量变更频道(channel_incr_)与全量变更频道不同,全量变更频道只保存了批次号,数据写入时遵循的是头插法,变更时只需根据头节点进行判断;而增量变更频道是一个 FIFO 队列,数据写入时遵循的是尾插法,并且它不仅仅记录了批次号,而且还记录了这个批次下需要顺序变更的内容,如下图所示,如果新增批次 4 则加入到队列的尾部:

到这里,增量数据的事件处理流程就介绍完了,接下来我们再来看下 cache-provider 拉取增量变更数据并刷新到本地缓存的流程。
cache-provider 拉取增量变更数据并刷新到本地缓存
在 cache-provider 拉取数据时,需要从队列头节点一个个判断是否刷新过这些增量变更的数据,不允许跳过任何一个元素的处理。cache-provider 增量刷新本地缓存的流程相对简单,每台服务实例在本地都会启动一个定时任务,增量刷新的定时任务尽可能调的小一些,这样能保证比较快的刷新速率。每次执行本地刷新时加一把本地锁(借助 AtomicBoolean 来实现),保证同时针对每一类事件都只有一个定时任务在执行,避免重复刷新。刷新本地缓存时,先从二级缓存中获取到对应类型的增量变更频道,然后从队列头节点开始遍历,判断是否已经刷新过,如果已经刷新过,则跳过,否则将增量变更的数据刷新到本地缓存中,缓存更新完成后将本机 IP 在待执行的 IP 中移除,并更新本地记录的缓存版本,防止重复刷新。
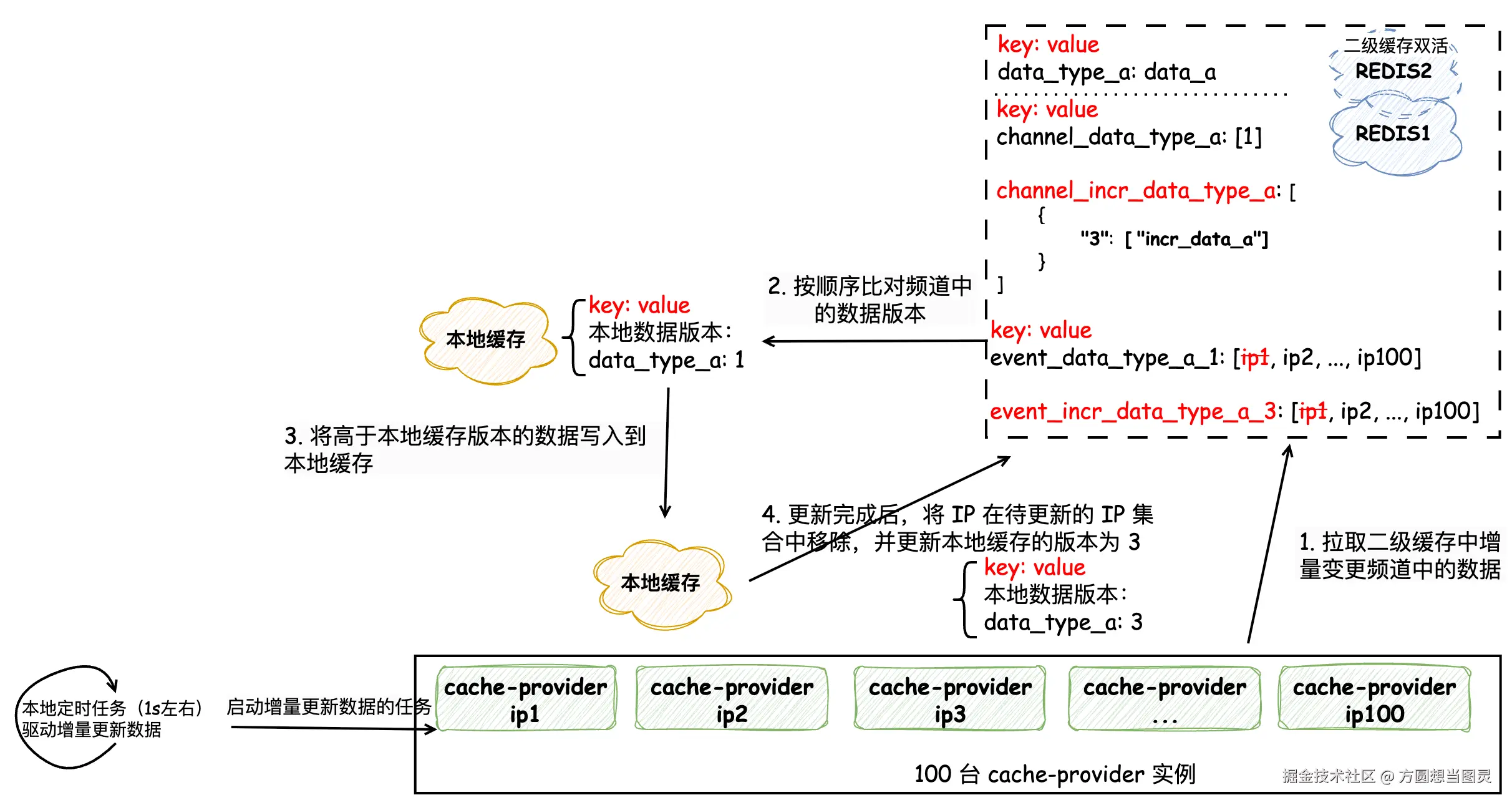
增量缓存变更的同步和刷新流程就介绍完了,其他流程和全量刷新一致,这里不再赘述,接下来我们讨论几个需要注意的细节上的问题。
增量变更频道的无限膨胀问题
增量变更频道是一个 FIFO 队列,随着时间的推移,队列中的数据会越来越多,如果不对它进行清理,那么它就会无限膨胀,最终在二级缓存中形成大 Key。因此,我们需要定期清理增量变更频道中的数据,那么该如何清理呢?
在考虑如何清理前,我们先考虑一个问题:当服务部署或重启时,它该如何才能刷新到此时最新的数据?它需要先同步全量的数据到本地缓存中,然后再将增量变更的缓存按顺序同步到本地缓存中,这样才能保证服务刷新到最新的数据,并记录全量或增量变更中最大的批次号为本地缓存的版本号。
注意,我们在这个过程中既同步了全量数据又同步了增量数据,那么保存在增量变更频道中的元素就不能轻易地被移除,否则就会造成数据不一致的问题。
现在我们再回到第一个问题:该如何安全地缩小增量变更频道呢?其实比较简单,我们可以在每次触发全量数据的刷新后,来将增量变更频道中 已经被刷新完的并且版本号低于全量变更版本号 的所有元素移除,这样既保证了重启的服务能拉到最新的数据,也不会影响正在增量刷新的服务,保证了数据一致性,又不会造成增量变更频道无限膨胀。
如下图所示,当发生 data_type_a 的全量变更时,记录全量变更的批次版本为 5,此时增量变更频道中记录的批次版本为 3,而且 3 这条增量变更已经被所有 IP 刷新完了(event_incr_data_type_a_3 元素为空),那么就能将其在增量变更频道中移除了。

如果迟迟未触发全量缓存的变更,可以考虑在每天的凌晨 4 点触发一次,此时是面向 C 端流量的低峰期,刷新造成的性能抖动对业务影响较小。
无法执行增量变更的缓存
在实际业务中,可能会遇到一些缓存的数据源是由其他团队提供的,它们并不支持增量数据的查询,只提供了压缩后的全量数据的查询接口,这就导致我们无法达成增量刷新的目的,如果这类数据变更比较频繁的话,会经常触发 GC 导致接口性能的抖动。
那么该如何解决这种情况呢?其实也不复杂,可以考虑将这些缓存移到堆外,那么这样就避免了 GC 对性能的影响。堆外内存的选型可以使用 Ehcache3,它能够支持堆外内存,使用起来也比较方便,并且还在活跃更新中,至于 OHC 堆外内存已经停更很久了,其中的一些安全漏洞也没有被再继续维护和修复了,所以不能在生产环境继续使用了。
在使用堆外内存时需要注意以下几点:
- 堆外内存的回收需要手动管理,否则会造成内存泄漏(
java.lang.OutOfMemoryError:Direct buffer memory) - 大量缓存放在堆外时需要计算好需要占据的内存大小,因为 Ehcache3 在初始化时需要划分好内存空间,防止空间不够用
- 保存在堆外缓存的对象都需要进行序列化处理
- 堆外缓存数量的监控需要开发相关的监控上报逻辑,否则遇到问题较难排查
That's all.