官方博客:https://zhuanlan.zhihu.com/p/1949631642294522105
源码:https://github.com/huggingface/transformers/tree/main/src/transformers/models/qwen3_next
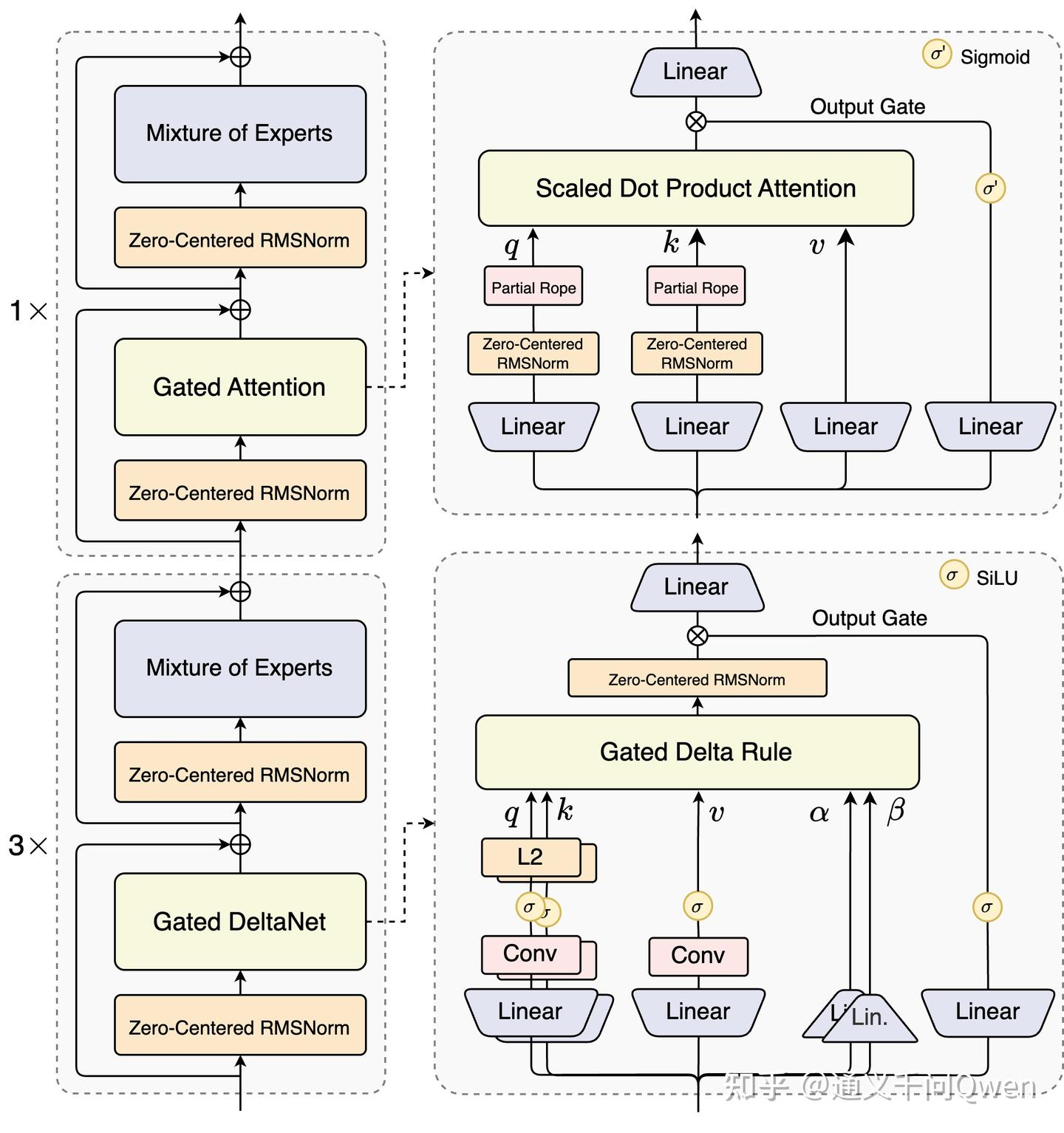
总览:
依然是transformer的decoder形式。pre-norm,attention,norm,FFN。
最特别的是,有75%的层采用Gated DeltaNet,其余仍然是标注注意力。所以下面是3,上面是1.
下面从下到上看看有什么变化。
1.zero-centered RMSNorm
原论文
RMSNorm是均方根归一化,移除了层归一化中的均值的计算部分。
实现公式:
x ^ i = x i 1 n ∑ i = 1 n x i 2 + ϵ \hat{x}i = \frac{x_i}{\sqrt{\frac{1}{n}\sum{i=1}^n x_i^2 + \epsilon}} x^i=n1∑i=1nxi2+ϵ xi
标准的、真正意义上的zero-centered RMSNorm应该是减去均值,如下:
python
def _norm(self, x):
mu = x.mean(-1, keepdim=True)
x_centered = x - mu
variance = x_centered.pow(2).mean(-1, keepdim=True)
return x_centered / torch.sqrt(variance + self.eps)但是qwen3-next的实现仍然是标准的RMSNorm,不过初始化偏置为0,而不是像标准实现一样初始化为ones。所以训练开始缩放因子为1,是一种参数初始化策略。设计重点在于 训练稳定性 与 数值精度控制。
代码如下:
python
class Qwen3NextRMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.zeros(dim)) # 这里
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float())
output = output * (1.0 + self.weight.float())
return output.type_as(x)2.Gated DeltaNet
源论文:https://arxiv.org/pdf/2412.06464
公式:
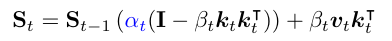
解释:
S:记忆,t是时间步;α是门控衰减系数,值域在0-1之间,β是更新强度系数,值域同上,控制新信息的写入程度。
优化点:
Gated DeltaNet吸收了Manba2和DeltaNet的优点,前者是一刀切所有的记忆,后者无法快速清理大量记忆。


与标准注意力和其他线性注意力的区别:
| 对比维度 | 标准注意力(Transformer) | 线性注意力(Mamba2/DeltaNet) | Gated DeltaNet 注意力 |
|---|---|---|---|
| 计算复杂度 | O(L\^2 \\cdot d_k) (二次,慢) | O(L \\cdot d_k d_v) (线性,快) | O(L \\cdot d_k d_v) (线性,快) |
| 记忆清理 | 无主动清理,靠 softmax 权重筛选 | Mamba2:全局衰减(乱删);DeltaNet:精准删除(慢清) | 门控 + 精准(又快又准) |
| 长文本能力 | 弱( L 大时算不动) | 强( L 大也能算)但效果有短板 | 强( L 大且效果优) |
| 并行训练效率 | 中等(块内并行) | 中等(分块并行 + 数学分解) | 优(分块并行 + 简化计算) |
| 适用场景 | 短文本、高精度任务(如翻译、摘要) | 长文本、效率优先任务(如日志分析) | 长文本 + 高精度任务(如长报告问答、代码理解) |
网络结构
python
GatedDeltaNet(
(silu): SiLU()
(q_proj): Linear(in_features=512, out_features=1024, bias=False)
(k_proj): Linear(in_features=512, out_features=1024, bias=False)
(v_proj): Linear(in_features=512, out_features=2048, bias=False)
(b_proj): Linear(in_features=512, out_features=4, bias=False)
(a_proj): Linear(in_features=512, out_features=4, bias=False)
(q_conv1d): ShortConvolution(1024, 1024, kernel_size=(4,), stride=(1,), padding=(3,), groups=1024, bias=False, activation=silu)
(k_conv1d): ShortConvolution(1024, 1024, kernel_size=(4,), stride=(1,), padding=(3,), groups=1024, bias=False, activation=silu)
(v_conv1d): ShortConvolution(2048, 2048, kernel_size=(4,), stride=(1,), padding=(3,), groups=2048, bias=False, activation=silu)
(g_proj): Linear(in_features=512, out_features=2048, bias=False)
(o_norm): FusedRMSNormSwishGate(512, eps=1e-05)
(o_proj): Linear(in_features=2048, out_features=512, bias=False)
)代码实现
代码解读:https://www.doubao.com/thread/w7e2fecc6eebc2029
python
class Qwen3NextGatedDeltaNet(nn.Module):
def __init__(self, config: Qwen3NextConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.num_v_heads = config.linear_num_value_heads
self.num_k_heads = config.linear_num_key_heads
self.head_k_dim = config.linear_key_head_dim
self.head_v_dim = config.linear_value_head_dim
self.key_dim = self.head_k_dim * self.num_k_heads
self.value_dim = self.head_v_dim * self.num_v_heads
self.conv_kernel_size = config.linear_conv_kernel_dim
self.layer_idx = layer_idx
self.activation = config.hidden_act
self.act = ACT2FN[config.hidden_act]
self.layer_norm_epsilon = config.rms_norm_eps
# QKV
self.conv_dim = self.key_dim * 2 + self.value_dim
self.conv1d = nn.Conv1d(
in_channels=self.conv_dim,
out_channels=self.conv_dim,
bias=False,
kernel_size=self.conv_kernel_size,
groups=self.conv_dim,
padding=self.conv_kernel_size - 1,
)
# projection of the input hidden states
projection_size_qkvz = self.key_dim * 2 + self.value_dim * 2
projection_size_ba = self.num_v_heads * 2
self.in_proj_qkvz = nn.Linear(self.hidden_size, projection_size_qkvz, bias=False)
self.in_proj_ba = nn.Linear(self.hidden_size, projection_size_ba, bias=False)
# time step projection (discretization)
# instantiate once and copy inv_dt in init_weights of PretrainedModel
self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads))
A = torch.empty(self.num_v_heads).uniform_(0, 16)
self.A_log = nn.Parameter(torch.log(A))
self.norm = (
Qwen3NextRMSNormGated(self.head_v_dim, eps=self.layer_norm_epsilon)
if FusedRMSNormGated is None
else FusedRMSNormGated(
self.head_v_dim,
eps=self.layer_norm_epsilon,
activation=self.activation,
device=torch.cuda.current_device(),
dtype=config.dtype if config.dtype is not None else torch.get_current_dtype(),
)
)
self.out_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)
self.causal_conv1d_fn = causal_conv1d_fn
self.causal_conv1d_update = causal_conv1d_update or torch_causal_conv1d_update
self.chunk_gated_delta_rule = chunk_gated_delta_rule or torch_chunk_gated_delta_rule
self.recurrent_gated_delta_rule = fused_recurrent_gated_delta_rule or torch_recurrent_gated_delta_rule
if not is_fast_path_available:
logger.warning_once(
"The fast path is not available because one of the required library is not installed. Falling back to "
"torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and"
" https://github.com/Dao-AILab/causal-conv1d"
)
def fix_query_key_value_ordering(self, mixed_qkvz, mixed_ba):
"""
Derives `query`, `key` and `value` tensors from `mixed_qkvz` and `mixed_ba`.
"""
new_tensor_shape_qkvz = mixed_qkvz.size()[:-1] + (
self.num_k_heads,
2 * self.head_k_dim + 2 * self.head_v_dim * self.num_v_heads // self.num_k_heads,
)
new_tensor_shape_ba = mixed_ba.size()[:-1] + (self.num_k_heads, 2 * self.num_v_heads // self.num_k_heads)
mixed_qkvz = mixed_qkvz.view(*new_tensor_shape_qkvz)
mixed_ba = mixed_ba.view(*new_tensor_shape_ba)
split_arg_list_qkvz = [
self.head_k_dim,
self.head_k_dim,
(self.num_v_heads // self.num_k_heads * self.head_v_dim),
(self.num_v_heads // self.num_k_heads * self.head_v_dim),
]
split_arg_list_ba = [self.num_v_heads // self.num_k_heads, self.num_v_heads // self.num_k_heads]
query, key, value, z = torch.split(mixed_qkvz, split_arg_list_qkvz, dim=3)
b, a = torch.split(mixed_ba, split_arg_list_ba, dim=3)
# [b, sq, ng, np/ng * hn] -> [b, sq, np, hn]
value = value.reshape(value.size(0), value.size(1), -1, self.head_v_dim)
z = z.reshape(z.size(0), z.size(1), -1, self.head_v_dim)
b = b.reshape(b.size(0), b.size(1), self.num_v_heads)
a = a.reshape(a.size(0), a.size(1), self.num_v_heads)
return query, key, value, z, b, a
def forward(
self,
hidden_states: torch.Tensor,
cache_params: Optional[Qwen3NextDynamicCache] = None,
cache_position: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
):
hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)
# Set up dimensions for reshapes later
batch_size, seq_len, _ = hidden_states.shape
use_precomputed_states = (
cache_params is not None
and cache_params.has_previous_state
and seq_len == 1
and cache_position is not None
)
# getting projected states from cache if it exists
if cache_params is not None:
conv_state = cache_params.conv_states[self.layer_idx]
recurrent_state = cache_params.recurrent_states[self.layer_idx]
projected_states_qkvz = self.in_proj_qkvz(hidden_states)
projected_states_ba = self.in_proj_ba(hidden_states)
query, key, value, z, b, a = self.fix_query_key_value_ordering(projected_states_qkvz, projected_states_ba)
query, key, value = (x.reshape(x.shape[0], x.shape[1], -1) for x in (query, key, value))
mixed_qkv = torch.cat((query, key, value), dim=-1)
mixed_qkv = mixed_qkv.transpose(1, 2)
if use_precomputed_states:
# 2. Convolution sequence transformation
# NOTE: the conv state is updated in `causal_conv1d_update`
mixed_qkv = self.causal_conv1d_update(
mixed_qkv,
conv_state,
self.conv1d.weight.squeeze(1),
self.conv1d.bias,
self.activation,
)
else:
if cache_params is not None:
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
cache_params.conv_states[self.layer_idx] = conv_state
if self.causal_conv1d_fn is not None:
mixed_qkv = self.causal_conv1d_fn(
x=mixed_qkv,
weight=self.conv1d.weight.squeeze(1),
bias=self.conv1d.bias,
activation=self.activation,
seq_idx=None,
)
else:
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])
mixed_qkv = mixed_qkv.transpose(1, 2)
query, key, value = torch.split(
mixed_qkv,
[
self.key_dim,
self.key_dim,
self.value_dim,
],
dim=-1,
)
query = query.reshape(query.shape[0], query.shape[1], -1, self.head_k_dim)
key = key.reshape(key.shape[0], key.shape[1], -1, self.head_k_dim)
value = value.reshape(value.shape[0], value.shape[1], -1, self.head_v_dim)
beta = b.sigmoid()
# If the model is loaded in fp16, without the .float() here, A might be -inf
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias)
if self.num_v_heads // self.num_k_heads > 1:
query = query.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
key = key.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
if not use_precomputed_states:
core_attn_out, last_recurrent_state = self.chunk_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=None,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
else:
core_attn_out, last_recurrent_state = self.recurrent_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=recurrent_state,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
# Update cache
if cache_params is not None:
cache_params.recurrent_states[self.layer_idx] = last_recurrent_state
z_shape_og = z.shape
# reshape input data into 2D tensor
core_attn_out = core_attn_out.reshape(-1, core_attn_out.shape[-1])
z = z.reshape(-1, z.shape[-1])
core_attn_out = self.norm(core_attn_out, z)
core_attn_out = core_attn_out.reshape(z_shape_og)
core_attn_out = core_attn_out.reshape(core_attn_out.shape[0], core_attn_out.shape[1], -1)
output = self.out_proj(core_attn_out)
return output3. Gated Attention
特点:
在MHA上加了一个sigmoid激活函数,用于门控;
每个 head 内部的 q/k 向量做归一化,即QKnorm;
支持GQA。
代码实现:
python
class Qwen3NextAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: Qwen3NextConfig, layer_idx: int):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.scaling = self.head_dim**-0.5
self.attention_dropout = config.attention_dropout
self.is_causal = True
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim * 2, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
)
self.q_norm = Qwen3NextRMSNorm(self.head_dim, eps=config.rms_norm_eps) # unlike olmo, only on the head dim!
self.k_norm = Qwen3NextRMSNorm(
self.head_dim, eps=config.rms_norm_eps
) # thus post q_norm does not need reshape
@deprecate_kwarg("past_key_value", new_name="past_key_values", version="4.58")
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_values: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states, gate = torch.chunk(
self.q_proj(hidden_states).view(*input_shape, -1, self.head_dim * 2), 2, dim=-1
)
gate = gate.reshape(*input_shape, -1)
query_states = self.q_norm(query_states.view(hidden_shape)).transpose(1, 2)
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_values is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = attn_output * torch.sigmoid(gate)
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights4.MTP
deepseek开始大规模采用。一次输入,预测多步。
https://zhuanlan.zhihu.com/p/15037286337
https://medium.com/@bingqian/understanding-multi-token-prediction-mtp-in-deepseek-v3-ed634810c290