目录
[16.1 文本模式及其对解析器的影响](#16.1 文本模式及其对解析器的影响)
[16.2 递归下降算法构造模板 AST](#16.2 递归下降算法构造模板 AST)
[16.3 状态机的开启与停止](#16.3 状态机的开启与停止)
解析器本质是一个状态机,正则也是一个状态机,本章使用正则完成一个 html 解析器。
16.1 文本模式及其对解析器的影响
文本模式是解析器工作时的特殊状态。
在这些状态下,解析器的解析行为会有所不同。解析器会根据遇到的特殊标签切换工作模式,从而改变对文本的解析方式:
- 当遇到
<title>标签、<textarea>标签,当解析器遇到这两个标签时,会切换到RCDATA模式。 - 当遇到
<style>、<xmp>、<iframe>、<noembed>、<noframes>、<noscript>等标签,当解析器遇到这些标签时,会切换到RAWTEXT模式。 - 当解析器遇到
<
在上述 HTML 代码中,虽然 <textarea> 标签内存在 <div> 标签,但解析器并不会将 <div> 解析为标签元素,而是作为普通文本处理。
然而,需要注意的是,尽管在 RCDATA 模式下,解析器不能识别标签元素,但它仍然支持 HTML 字符实体。当解析器遇到 & 字符时,会切换到字符引用状态。例如:
<textarea>©</textarea>
浏览器在渲染这段 HTML 代码时,会在文本框内展示字符 ©。
解析器在 RAWTEXT 模式下的工作方式与 RCDATA 模式类似,不同之处在于 RAWTEXT 模式下不再支持 HTML 实体,而是将其作为普通字符处理。
Vue.js的单文件组件的解析器在遇到 <script> 标签时会进入 RAWTEXT 模式,将<script> 标签内的内容作为普通文本处理。
CDATA 模式在 RAWTEXT 模式的基础上更进一步,在 CDATA 模式下,解析器将把任何字符都作为普通字符处理,直到遇到 CDATA 的结束标志为止。
PLAINTEXT 模式与 RAWTEXT 模式类似,但解析器一旦进入 PLAINTEXT 模式,将不会再退出。
不同的模式及各其特性:
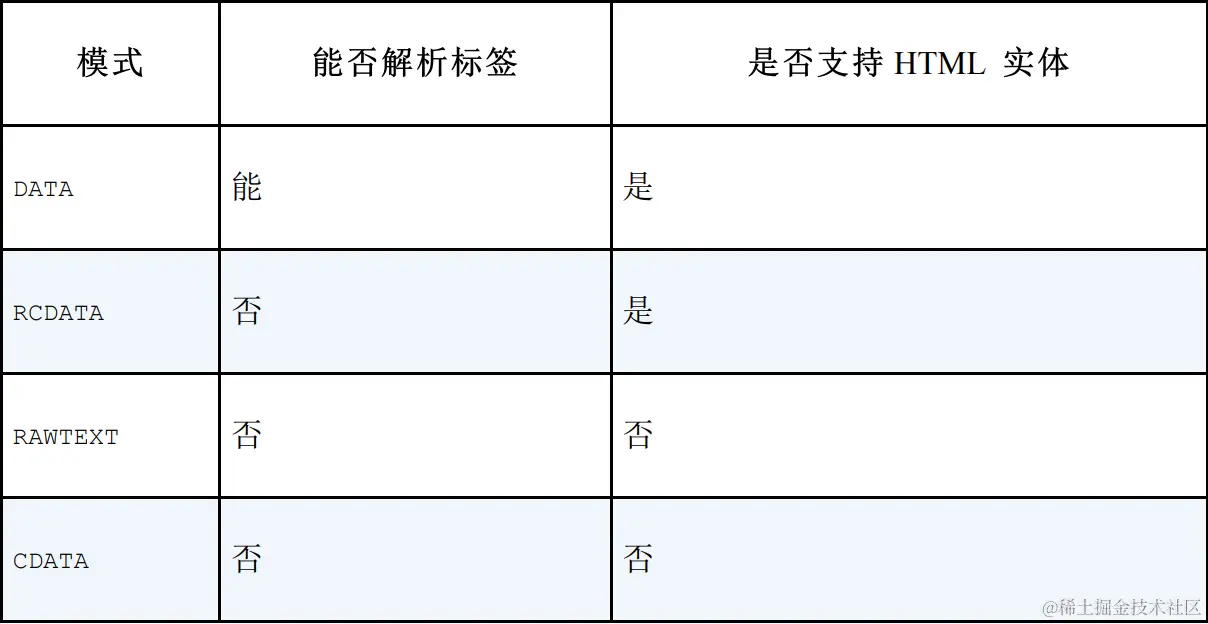
不同解析器,还会影响对终止解析的判断,后文具体讨论,我们先将上述模式定义为状态表:
const TextModes = {
DATA: 'DATA',
RCDATA: 'RCDATA',
RAWTEXT: 'RAWTEXT',
CDATA: 'CDATA',
}16.2 递归下降算法构造模板 AST
这节我们实现一个更完善的模板解析器,基本架构模型如下:
// 定义文本模式,作为一个状态表
const TextModes = {
DATA: 'DATA',
RCDATA: 'RCDATA',
RAWTEXT: 'RAWTEXT',
CDATA: 'CDATA',
}
// 解析器函数,接收模板作为参数
function parse(str) {
// 定义上下文对象
const context = {
// source 是模板内容,用于在解析过程中进行消费
source: str,
// 解析器当前处于文本模式,初始模式为 DATA
mode: TextModes.DATA,
}
// 调用 parseChildren 函数开始进行解析,它返回解析后得到的子节点
// parseChildren 函数接收两个参数:
// 第一个参数是上下文对象 context
// 第二个参数是由父代节点构成的节点栈,初始时栈为空
const nodes = parseChildren(context, [])
// 解析器返回 Root 根节点
return {
type: 'Root',
// 使用 nodes 作为根节点的 children
children: nodes,
}
}上述代码,首先定义 TextModes 描述预定义的文本模式。
然后我们定义 parse 解析函数,其中定义上下文对象 context 用来维护执行程序时产生的各种状态。
接着,调用 parseChildren 函数进解析返回解析后得到的子节点,并使用这些子节点作为 children 来创建 Root 根节点。
这段代码与第 15 章不同,在第 15 章中,我们首先对模板内容进行标记化得到一系列 Token,然后根据这些 Token 构建模板 AST。
实际上,创建 Token 与构造模板 AST 的过程可以同时进行,因为模板和模板 AST 具有同构的特性。
上面代码 parseChildren 函数是核心,后续会不断调用它来消费模板内容,它会返回解析后得到的子节点,举个例子,假如有以下模板:
<p>1</p>
<p>2</p>parseChildren 函数在解析这段模板后,会得到由这两个 <p> 节点组成的数组:
[
{ type: 'Element', tag: 'p', children: [/*...*/] },
{ type: 'Element', tag: 'p', children: [/*...*/] },
]之后,这个数组将作为 Root 根节点的 children。
parseChildren 函数接收两个参数。
- 第一个参数:上下文对象 context。
- 第二个参数:由父代节点构成的栈,用于维护节点间的父子级关系。
parseChildren 函数本质上也是一个状态机,该状态机有多少种状态取决于子节点的类型数量。在模板中,元素的子节点有几种:
- 标签节点,例如
<div>。 - 文本插值节点,例如 {{ val }}。
- 普通文本节点,例如:text。
- 注释节点,例如
<!---->。 - CDATA 节点,例如
<![CDATA[ xxx ]]>。
在标准的 HTML 中,节点的类型将会更多,例如 DOCTYPE 节点等。为了降低复杂度,我们仅考虑上述类型的节点。
parseChildren 函数在解析模板过程中的状态迁移过程:
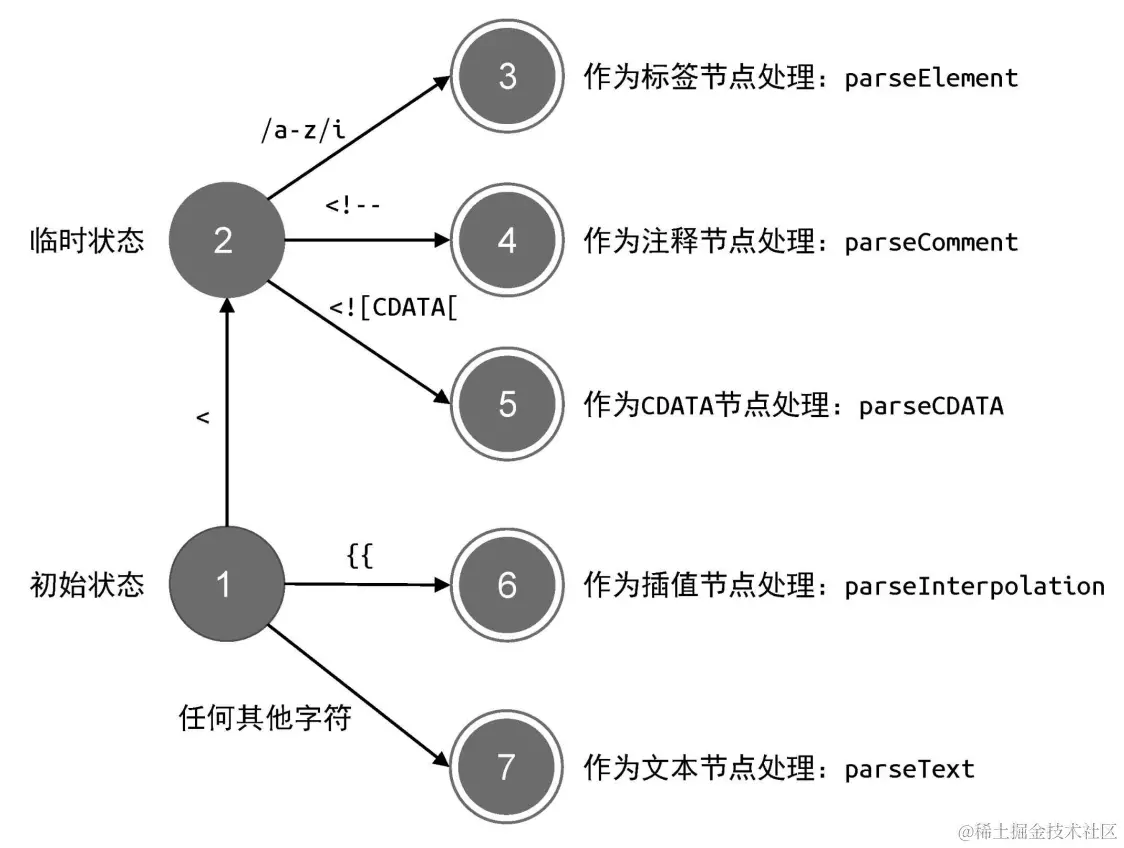
- 当遇到字符
<时,进入临时状态。 - 如果下一个字符匹配正则 /a-z/i,则认为这是一个标签节点,于是调用 parseElement 函数完成标签的解析。注意正则表达式 /a-z/i 中的 i,意思是忽略大小写(case-insensitive)。
- 如果字符串以
<!--开头,则认为这是一个注释节点,于是调用 parseComment 函数完成注释节点的解析。 - 如果字符串以
<![CDATA[开头,则认为这是一个 CDATA 节点,于是调用 parseCDATA 函数完成 CDATA 节点的解析。 - 如果字符串以
{``{开头,则认为这是一个插值节点,于是调用 parseInterpolation 函数完成插值节点的解析。 - 其他情况,都作为普通文本,调用 parseText 函数完成文本节点的解析。
具体代码,我们还需要结合文本模式:
function parseChildren(context, ancestors) {
// 定义 nodes 数组存储子节点,它将作为最终的返回值
let nodes = []
// 从上下文对象中取得当前状态,包括模式 mode 和模板内容 source
const { mode, source } = context
// 开启 while 循环,只要满足条件就会一直对字符串进行解析
// 关于 isEnd() 后文会详细讲解
while (!isEnd(context, ancestors)) {
let node
// 只有 DATA 模式和 RCDATA 模式才支持插值节点的解析
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
// 只有 DATA 模式才支持标签节点的解析
if (mode === TextModes.DATA && source[0] === '<') {
if (source[1] === '!') {
if (source.startsWith('<!--')) {
// 注释
node = parseComment(context)
} else if (source.startsWith('<![CDATA[')) {
// CDATA
node = parseCDATA(context, ancestors)
}
} else if (source[1] === '/') {
// 结束标签,这里需要抛出错误,后文会详细解释原因
} else if (/[a-z]/i.test(source[1])) {
// 标签
node = parseElement(context, ancestors)
}
} else if (source.startsWith('{{')) {
// 解析插值
node = parseInterpolation(context)
}
}
// node 不存在,说明处于其他模式,即非 DATA 模式且非 RCDATA 模式
// 这时一切内容都作为文本处理
if (!node) {
// 解析文本节点
node = parseText(context)
}
// 将节点添加到 nodes 数组中
nodes.push(node)
}
// 当 while 循环停止后,说明子节点解析完毕,返回子节点
return nodes
}- parseChildren 函数的返回值是由子节点组成的数组,每次 while 循环都会解析一个或多个节点,这些节点会被添加到 nodes 数组中,并作为parseChildren 函数的返回值返回。
- 解析过程中需要判断当前的文本模式。根据不同的模式及各其特性表可知,只有处于 DATA 模式或 RCDATA 模式时,解析器才支持插值节点的解析。并且,只有处于 DATA 模式时,解析器才支持标签节点、注释节点和 CDATA 节点的解析。
- 在 16.1 节中我们介绍过,当遇到特定标签时,解析器会切换模式。一旦解析器切换到 DATA 模式和 RCDATA 模式之外的模式时,一切字符都将作为文本节点被解析。当然,即使在 DATA 模式或 RCDATA 模式下,如果无法匹配标签节点、注释节点、CDATA 节点、插值节点,那么也会作为文本节点解析。
除了上述三点,可能会有其他的疑问?
while 循环何时停止?以及 isEnd() 函数的用途是什么?
parseChildren 函数是用来解析子节点的,因此 while 循环一定要遇到父级节点的结束标签才会停止,这是正常的思路。但这个思路存在一些问题,后文讲。
我们通过一个例子更加直观地了解 parseChildren 函数:
const template = `<div>
<p>Text1</p>
<p>Text2</p>
</div>`在解析模板时,我们不能忽略空白字符。
这些空白字符包括:换行符(\n)、回车符(\r)、空格(' ')、制表符(\t)以及换页符(\f)。如果我们用加号(+)代表换行符,用减号(-)代表空格字符。那么上面的模板可以表示为:
const template = `<div>+--<p>Text1</p>+--<p>Text2</p>+</div>`接下来,我们以这段模板作为输入来执行解析过程。
解析器一开始处于 DATA 模式。开始执行解析后,解析器遇到的第一个字符为 <,并且第二个字符能够匹配正则表达式 /a-z/i,所以解析器会进入标签节点状态,并调用 parseElement 函数进行解析。
parseElement 函数会做三件事:解析开始标签,解析子节点,解析结束标签。可以用下面的伪代码来表达 parseElement 函数所做的事情:
function parseElement() {
// 解析开始标签
const element = parseTag()
// 这里递归地调用 parseChildren 函数进行 <div> 标签子节点的解析
element.children = parseChildren()
// 解析结束标签
parseEndTag()
return element
}如果一个标签不是自闭合标签,则可以认为,一个完整的标签元素是由开始标签、子节点和结束标签这三部分构成的。
因此,在 parseElement 函数内,我们分别调用三个解析函数来处理这三部分内容。以上述模板为例。
parseTag 函数用于解析开始标签,包括开始标签上的属性和指令。因此,在 parseTag 解析函数执行完毕后,会消费字符串中的内容 <div>,处理后的模板内容将变为:
const template = `+--<p>Text1</p>+--<p>Text2</p>+</div>`递归地调用 parseChildren 函数解析子节点。parseElement 函数在解析开始标签时,会产生一个标签节点 element。
在 parseElement 函数执行完毕后,剩下的模板内容应该作为 element 的子节点被解析,即 element.children。
因此,我们要递归地调用 parseChildren 函数。在这个过程中,parseChildren 函数会消费字符串的内容:+--<p>Text1</p>+--<p>Text2</p>+。
处理后的模板内容将变为:
const template = `</div>可以看到,在经过 parseChildren 函数处理后,模板内容只剩下一个结束标签了。
因此,只需要调用 parseEndTag 解析函数来消费它即可。
经过上述三个步骤的处理后,这段模板就被解析完毕了,最终得到了模板AST。
但这里值得注意的是,为了解析标签的子节点,我们递归地调用了 parseChildren 函数。这意味着,一个新的状态机开始运行了,我们称其为"状态机 2"。"状态机 2"所处理的模板内容为:
const template = `+--<p>Text1</p>+--<p>Text2</p>+`我们来分析"状态机 2"的状态迁移流程:
在"状态机 2"开始运行时,模板的第一个字符是换行符(字符 + 代表换行符)。因此,解析器会进入文本节点状态,并调用 parseText 函数完成文本节点的解析。
parseText 函数会将下一个 < 字符之前的所有字符都视作文本节点的内容。换句话说,parseText 函数会消费模板内容 +--,并产生一个文本节点。
在 parseText解析函数执行完毕后,剩下的模板内容为:
const template = `<p>Text1</p>+--<p>Text2</p>+`接着,parseChildren 函数继续执行。此时模板的第一个字符为 <,并且下一个字符能够匹配正则 /a-z/i。
于是解析器再次进入 parseElement 解析函数的执行阶段,这会消费模板内容 <p>Text1</p>。
在这一步过后,剩下的模板内容为:
const template = `+--<p>Text2</p>+`可以看到,此时模板的第一个字符是换行符,于是调用 parseText 函数消费模板内容 +--。现在,模板中剩下的内容是:
const template = `<p>Text2</p>+`解析器会再次调用 parseElement 函数处理标签节点。在这之后,剩下的模板内容为:
const template = `+`可以看到,现在模板内容只剩下一个换行符了。
parseChildren 函数会继续执行并调用 parseText 函数消费剩下的内容,并产生一个文本节点。最终,模板被解析完毕,"状态机 2"停止运行。
在"状态机 2"运行期间,为了处理标签节点,我们又调用了两次 parseElement 函数。第一次调用用于处理内容 <p>Text1</p>,第二次调用用于处理内容 <p>Text2</p>。
我们知道,parseElement 函数会递归地调用 parseChildren 函数完成子节点的解析,这就意味着解析器会再开启了两个新的状态机。
通过上面我们认识到,parseChildren 解析函数是整个状态机的核心,状态迁移操作都在该函数内完成。
在 parseChildren 函数运行过程中,为了处理标签节点,会调用 parseElement 解析函数,这会间接地调用 parseChildren 函数,并产生一个新的状态机。
随着标签嵌套层次的增加,新的状态机会随着 parseChildren 函数被递归地调用而不断创建,这就是"递归下降"中"递归"二字的含义。
而上级 parseChildren 函数的调用用于构造上级模板 AST 节点,被递归调用的下级 parseChildren 函数则用于构造下级模板 AST 节点。
最终,会构造出一棵树型结构的模板 AST,这就是"递归下降"中"下降"二字的含义。
16.3 状态机的开启与停止
上节我们知道,parseChildren 函数本质上是一个状态机,它会开启一个 while 循环使得状态机自动运行,如下代码所示:
function parseChildren(context, ancestors) {
let nodes = []
const { mode } = context
// 运行状态机
while (!isEnd(context, ancestors)) {
// 省略部分代码
}
return nodes
}这个 while 什么时候停止运行呢?涉及到 isEnd() 逻辑,为了搞清楚,我们模拟下状态机运行过程:
我们知道,在调用 parseElement 函数解析标签节点时,会递归地调用 parseChildren 函数,从而开启新的状态机:

为了便于描述,我们将上图称为"状态机 1"。
"状态机 1"开始运行,继续解析模板,直到遇到下一个 <p> 标签:
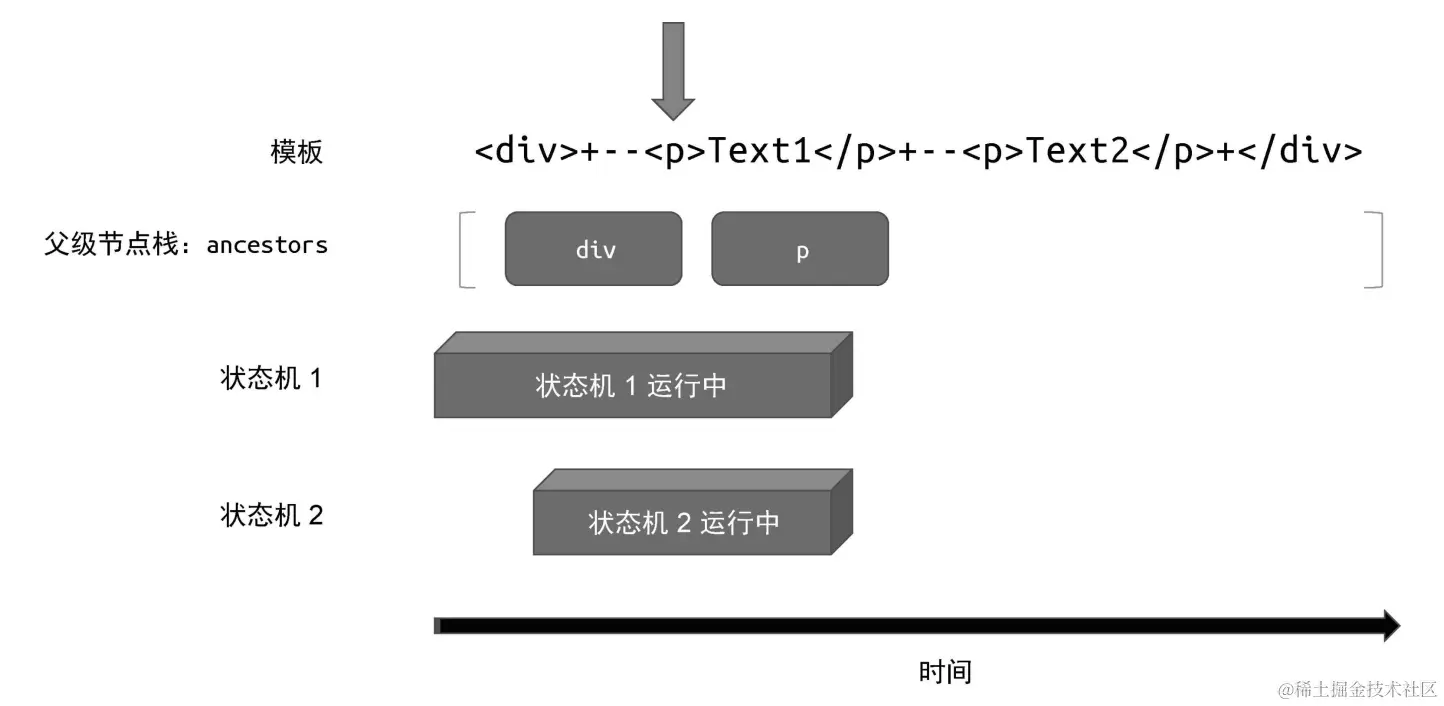
因为遇到了 <p> 标签,所以"状态机 1"也会调用 parseElement 函数进行解析。
于是又重复了上述过程,即把当前解析的标签节点压入父级节点栈,然后递归地调用 parseChildren 函数开启新的状态机,即"状态机 2"。
可以看到,此时有两个状态机在同时运行。
此时"状态机 2"拥有程序的执行权,它持续解析模板直到遇到结束标签 </p>。
因为这是一个结束标签,并且在父级节点栈中存在与该结束标签同名的标签节点,所以"状态机 2"会停止运行,并弹出父级节点栈中处于栈顶的节点,如图所示:
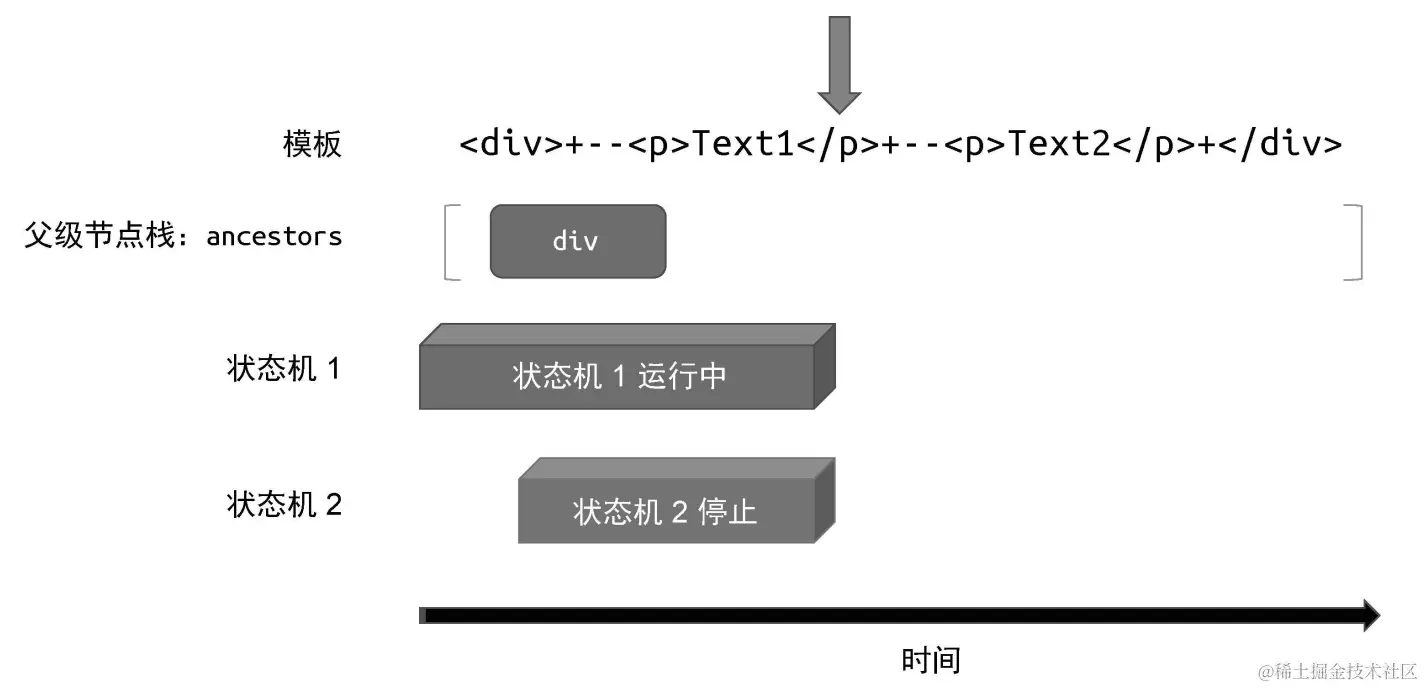
此时"状态机 2"已经停止运行了,但"状态机 1"仍在运行中,于是会继续解析模板,直到遇到下一个 <p> 标签。
这时"状态机 1"会再次调用 parseElement 函数解析标签节点,因此又会执行压栈并开启新的"状态机 3",如图所示:
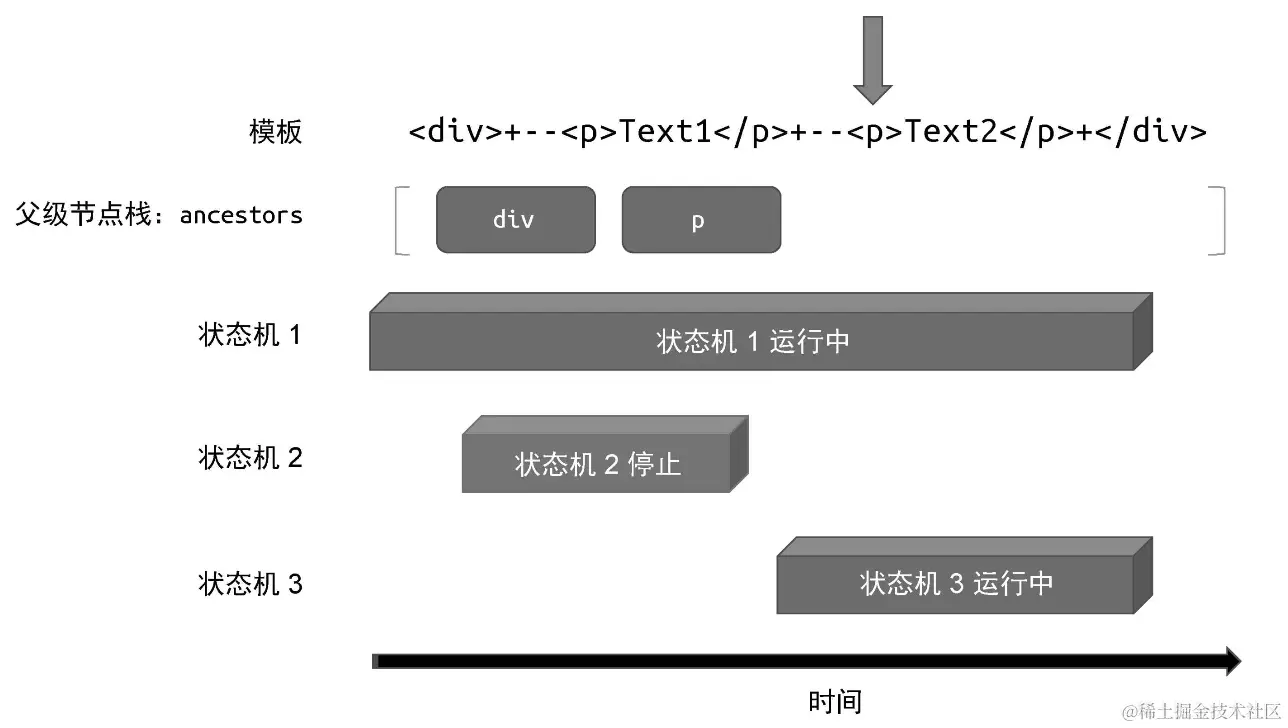
此时"状态机 3"拥有程序的执行权,它会继续解析模板,直到遇到结束标签</p>。
因为这是一个结束标签,并且在父级节点栈中存在与该结束标签同名的标签节点,所以"状态机 3"会停止运行,并弹出父级节点栈中处于栈顶的节点,如图所示:
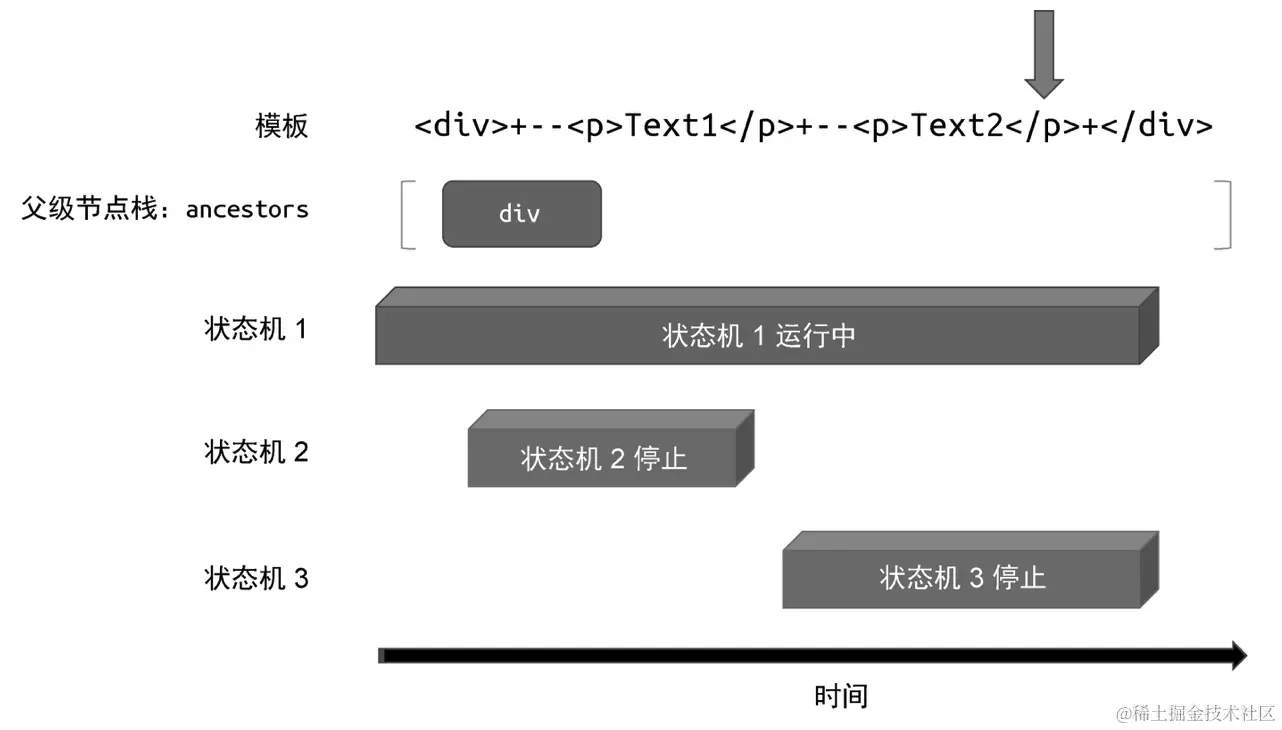
当"状态机 3"停止运行后,程序的执行权交还给"状态机 1"。
"状态机 1"会继续解析模板,直到遇到最后的 </div> 结束标签。这时"状态机 1"发现父级节点栈中存在与结束标签同名的标签节点,于是将该节点弹出父级节点栈,并停止运行,如图所示:
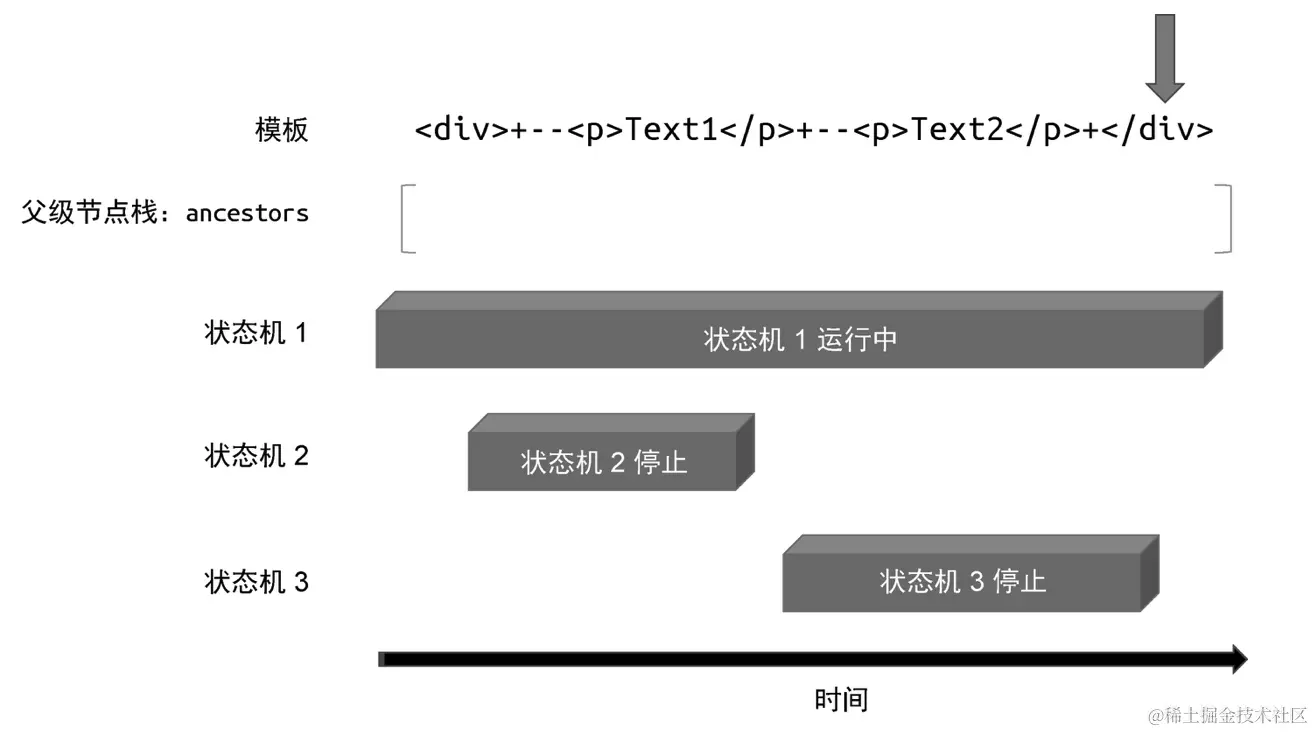
这时父级节点栈为空,状态机全部停止运行,模板解析完毕。
通过上面我们能知道解析器会在何时开启新的状态机,以及状态机会在何时停止。
结论是:
当解析器遇到开始标签时,会将该标签压入父级节点栈,同时开启新的状态机。
当解析器遇到结束标签,并且父级节点栈中存在与该标签同名的开始标签节点时,会停止当前正在运行的状态机 。
根据上述规则,我们可以给出 isEnd 函数的逻辑,如下面的代码所示:
function isEnd(context, ancestors) {
// 当模板内容解析完毕后,停止
if (!context.source) return true
// 获取父级标签节点
const parent = ancestors[ancestors.length - 1]
// 如果遇到结束标签,并且该标签与父级标签节点同名,则停止
if (parent && context.source.startsWith(`</${parent.tag}`)) {
return true
}
}上面这段代码展示了状态机的停止时机,具体如下:
- 第一个停止时机是当模板内容被解析完毕时;
- 第二个停止时机则是在遇到结束标签时,这时解析器会取得父级节点栈栈顶的节点作为父节点,检查该结束标签是否与父节点的标签同名,如果相同,则状态机停止运行。
这里需要注意的是,在第二个停止时机中,我们直接比较结束标签的名称与栈顶节点的标签名称。这么做的确可行,但严格来讲是有瑕疵的。例如下面的模板所示:
<div><span></div></span>上面模板其实存在两种解释方式:
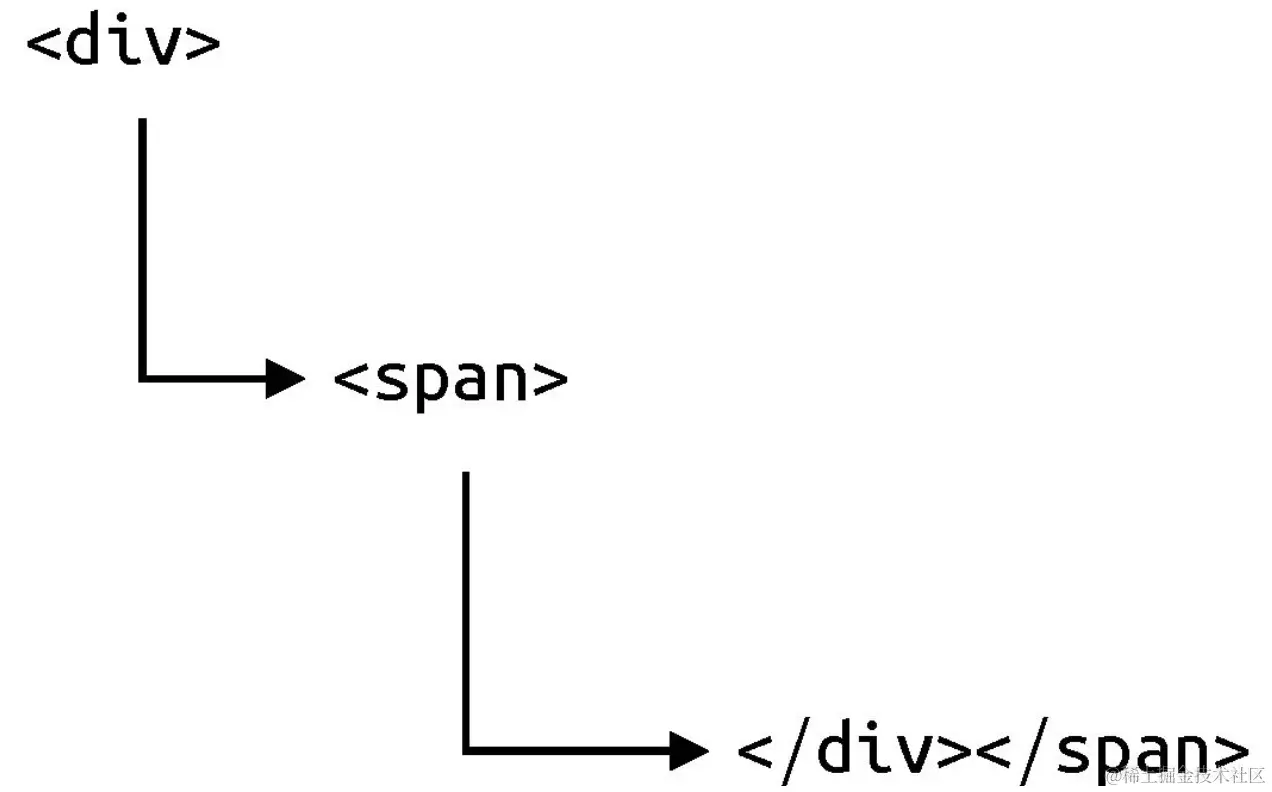
第一种解释流程:
- "状态机 1"遇到
<div>开始标签,调用 parseElement 解析函数,这会开启"状态机 2"来完成子节点的解析。 - "状态机 2"遇到
<span>开始标签,调用 parseElement 解析函数,这会开启"状态机 3"来完成子节点的解析。 - "状态机 3"遇到
</div>结束标签。由于此时父级节点栈栈顶的节点名称是 span,并不是 div,所以"状态机 3"不会停止运行。这时,"状态机 3"遭遇了不符合预期的状态,因为结束标签</div>缺少与之对应的开始标签,所以这时"状态机 3"会抛出错误:"无效的结束标签"。
上述流程的思路与我们当前的实现相符,下面 parseChildren 函数会体现状态机会遭遇不符合预期的状态:
function parseChildren(context, ancestors) {
let nodes = []
const { mode } = context
while (!isEnd(context, ancestors)) {
let node
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
if (mode === TextModes.DATA && context.source[0] === '<') {
if (context.source[1] === '!') {
// 省略部分代码
} else if (context.source[1] === '/') {
// 状态机遭遇了闭合标签,此时应该抛出错误,因为它缺少与之对应的开始标签
console.error('无效的结束标签')
continue
} else if (/[a-z]/i.test(context.source[1])) {
// 省略部分代码
}
} else if (context.source.startsWith('{{')) {
// 省略部分代码
}
}
// 省略部分代码
}
return nodes
}所以按照我们当前的实现思路来解析上述例子中的模板,最终得到的错误信息是:"无效的结束标签"。但其实还有另外一种更好的解析方式。
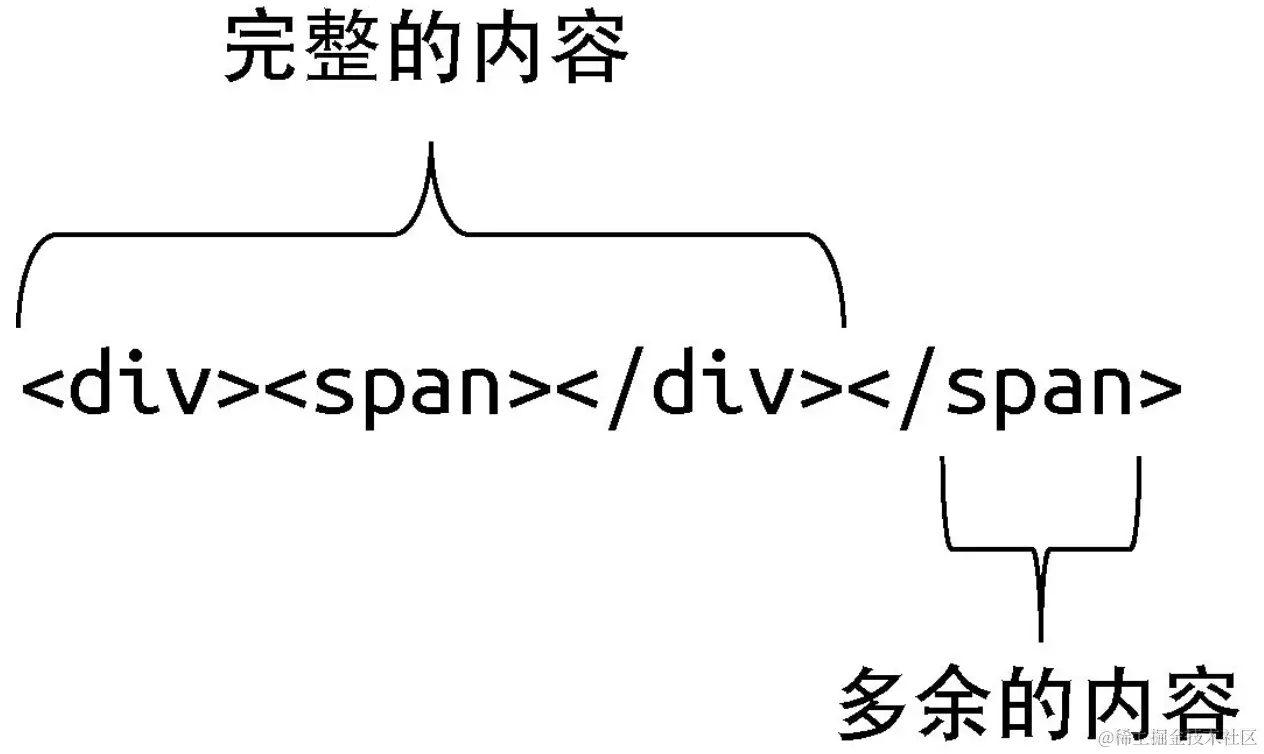
第二种模板解释方式,模板中存在一段完整的内容,我们希望解析器可以正常对其进行解析,这很可能也是符合用户意图的。
但实际上,无论哪一种解释方式,对程序的影响都不大。两者的区别体现在错误处理上。
对于第一种解释方式,我们得到的错误信息是:"无效的结束标签"。
而对于第二种解释方式,在"完整的内容"部分被解析完毕后,解析器就会打印错误信息:"<span>标签缺少闭合标签"。很显然,第二种解释方式更加合理。
为了实现第二种解释方式,我们需要调整 isEnd 函数的逻辑:
当判断状态机是否应该停止时,我们不应该总是与栈顶的父级节点做比较,而是应该与整个父级节点栈中的所有节点做比较。
只要父级节点栈中存在与当前遇到的结束标签同名的节点,就停止状态机,如下代码所示:
function isEnd(context, ancestors) {
if (!context.source) return true
// 与父级节点栈内所有节点做比较
for (let i = ancestors.length - 1; i >= 0; --i) {
// 只要栈中存在与当前结束标签同名的节点,就停止状态机
if (context.source.startsWith(`</${ancestors[i].tag}`)) {
return true
}
}
}按照新的思路再次对如下模板执行解析:
<div><span></div></span>其流程如下。
- "状态机 1"遇到
<div>开始标签,调用 parseElement 解析函数,并开启"状态机 2"解析子节点。 - "状态机 2"遇到
<span>开始标签,调用 parseElement 解析函数,并开启"状态机 3"解析子节点。 - "状态机 3"遇到
</div>结束标签,由于节点栈中存在名为 div 的标签节点,于是"状态机 3"停止了。
在这个过程中,"状态机 2"在调用 parseElement 解析函数时,parseElement 函数能够发现 <span> 缺少闭合标签,于是会打印错误信息"<span> 标签缺少闭合标签",如下面的代码所示:
function parseElement(context, ancestors) {
const element = parseTag(context)
if (element.isSelfClosing) return element
ancestors.push(element)
element.children = parseChildren(context, ancestors)
ancestors.pop()
if (context.source.startsWith(`</${element.tag}`)) {
parseTag(context, 'end')
} else {
// 缺少闭合标签
console.error(`${element.tag} 标签缺少闭合标签`)
}
return element
}