Pandas数据类型
从数据类型来说,pandas主要数据结构有四种,Series,DataFrame, Arrays, Panel. 目前主要用的是前面两种数据框DataFrame 和序列Series。DataFrame是二维数据,有行有列,DataFrame默认会自动创建行索引。 Series是一维数据,默认有索引。
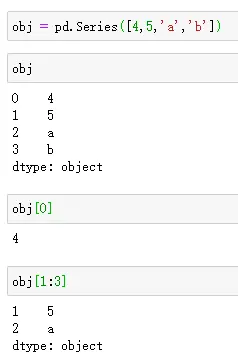
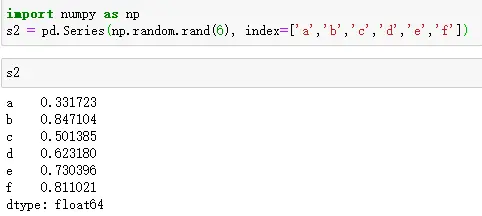
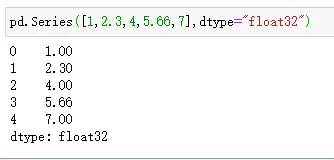
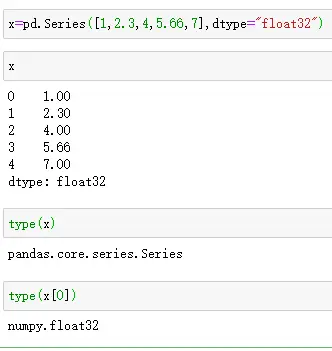
- Series定义访问如下:
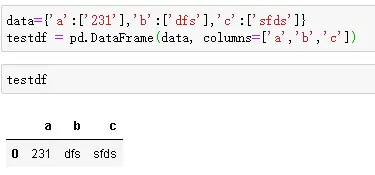
- DataFrame定义访问如下,可以从文件读也可以自己定义
数据类型主要支持下面几种:
字符串类型:object
整数类型:Int64,Int32,Int16, Int8
无符号整数:UInt64,UInt32,UInt16, UInt8
浮点数类型:float64,float32
日期和时间类型:datetime64ns、datetime64ns, tz、timedeltans
布尔类型:bool
Pandas应用
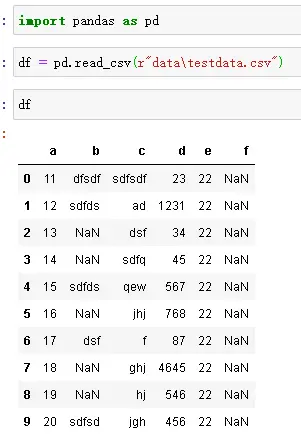
Pandas可以读取多种类型文件,如excel, txt, csv等, 这里小结下读取csv文件。
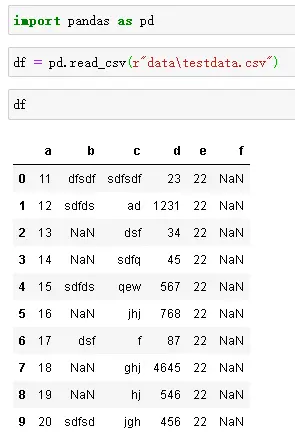
文件读取
默认分割符是",", 可以不用指定,如果是其他分割符需要指定seq参数。在路径前面加上r, 是防止被转义。
1.路径前加r
2.指定分隔符
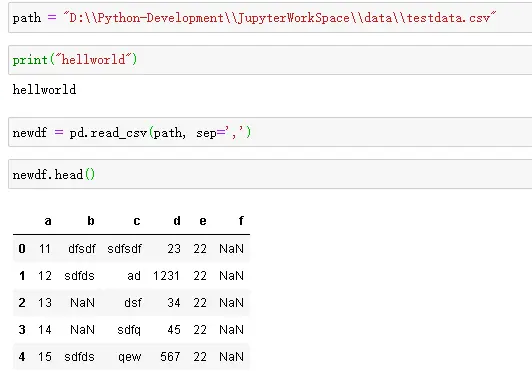
文件解析
1.查看文件内容,通过newdf.head(),查看前100行,可以用newdf.head(100), 也可以直接输入变量名df查看全部内容,如上图
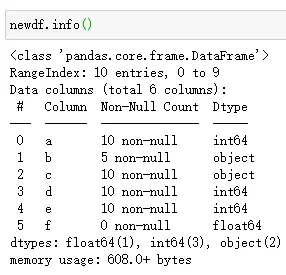
2.查看DataFrames数据类型及文件大小, 用newdf.info()
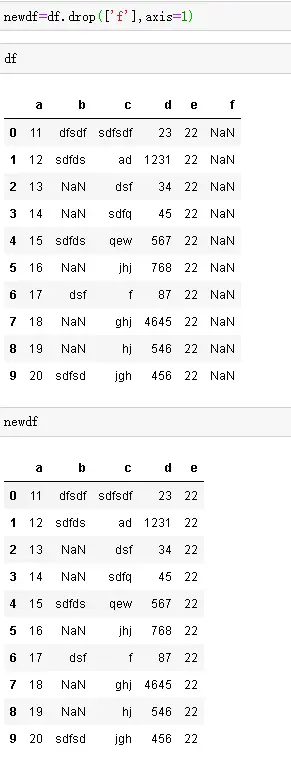
- 处理数据,删除可以用drop或del, drop会将删除后的数据生成副本,原先的数据不做修改,如下图。
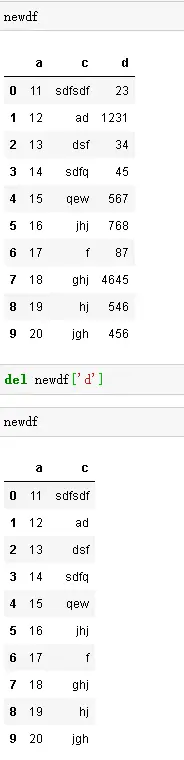
- del 删除,是直接删除
- drop时,默认axis=0,不设置时是按行删除,设置axis=1时是按列删除。DataFrame默认生成行索引,可通过index指定索引值去删除行。删除列时,可用columns指定列名,也可直接用列名指定。


- 读取数据
iloc方法为默认,可通过行索引取值,可以读取切片数据,如下:

列读取可以直接用列名读取

- 设置列索引,可以手动定义列索引,一旦定义列索引后,行索引自动消失,也就不能用iloc访问数据。如下图a列被定义为索引
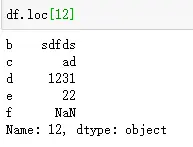
可以用loc来访问列为索引列, 当然索引列是不能访问的。用索引列访问会报错,该列为索引列 df'a',其他列依然可以用列名访问数据。
下图是用loc来访问列索引来得到数据。
8.数据填充或处理
填充空白值(NaN),最简单的可以直接替换,设置指定列替换为指定值,指定列的空值就会被替换为目标数据,如newdf2=df.fillna({'b':3,'f':7})
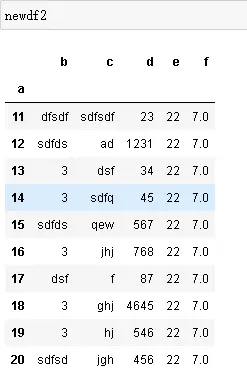
数据处理,如将d列都设置为两位数据,取值可以根据需求用正则表达式设定,如这里取d里最前2位数为d列的值。
