在 MySQL 中,EXPLAIN 是一个关键字,用于了解查询执行的相关信息。本文将展示如何利用MySQL EXPLAIN 来解决查询中的性能问题。
虽然执行一个 EXPLAIN 计划相对简单,但其输出结果并不总是直观的。只有了解其功能,才能充分利用它来实现SQL语句的性能提升。
EXPLAIN 与 EXPLAIN ANALYZE 的区别
当在查询的前面添加 EXPLAIN 关键字时,它会解释数据库如何执行该查询以及估算的成本。
示例EXPLAIN语句:

通过利用这个MySQL 内部工具,可以观察到以下内容:
- 查询 ID:列中总包含一个数值,用于标识该行属于哪一个 SELECT。
- SELECT_TYPE :运行 SELECT 时,MySQL 将 SELECT 查询分为简单类型和复杂类型(主要),如下表所示:
- SIMPLE:查询不包含子查询或 UNION;
- PRIMARY(复杂类型):复杂类型分为三大类:简单子查询、派生表(FROM 子句中的子查询)、UNION;
- DELETE:如果EXPLAIN的是 DELETE,select_type 会显示 DELETE;
- 查询运行的表 :显示执行计划中每一步骤所涉及的表。
- 查询访问的分区 :列出访问了哪些表分区(如果表已分区)。
- 所使用的连接类型(如果有):请注意,即使查询中不包含连接,这一列也会填充。
- MySQL 可以选择的索引 :列出所有可能的候选索引。
- MySQL 实际使用的索引 :显示查询选择的索引,并指定索引的使用长度。
- MySQL 选择的索引的长度:当 MySQL 使用复合索引时,length 列是唯一能确定复合索引中的使用了多少列的方法。
- 查询访问的行数:在设计数据库实例中的索引时,需要注意 rows 列。该列显示了 MySQL 为完成请求而访问的行数,这在设计索引时非常实用。查询访问的行越少,查询速度越快。
- 与索引进行比较的列
- 按指定条件过滤的行的百分比:该列显示了满足表上某些条件(如 WHERE 子句或连接条件)的行的悲观估算百分比。将 rows 列的值乘以该百分比,可以看到 MySQL 估计要与查询计划中先前的表连接的行数。
- 与查询相关的任何额外信息
总之,通过使用 EXPLAIN,可以获得查询预期运行的步骤列表。
什么是 EXPLAIN ANALYZE
在 MySQL 8.0.18 中,MySQL 引入了 EXPLAIN ANALYZE,一个在常规 EXPLAIN 查询计划工具之上的新功能。除了列出查询计划和估算的成本,EXPLAIN ANALYZE 还打印了执行计划中各个迭代器的实际成本。
示例EXPLAIN ANALYZE语句:
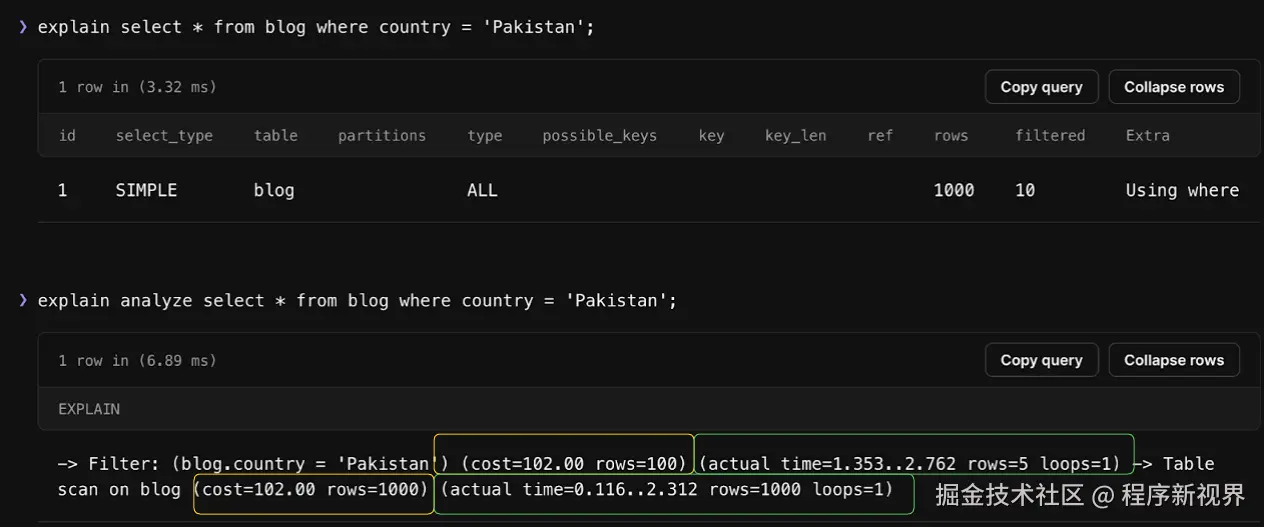
注意事项:EXPLAIN ANALYZE 实际上会运行查询,因此如果你不希望查询在实时数据库上运行,请不要使用 EXPLAIN ANALYZE。
对于每个迭代器,EXPLAIN ANALYZE 提供以下信息:
- 估算的执行成本(一些迭代器未被成本模型纳入,因此在估算中未包含它们)
- 估算的返回行数
- 返回第一行所需的时间
- 执行迭代器所花费的时间(包括子迭代器但不包括父迭代器),单位:毫秒。当有多个循环时,该数据会显示平均每个循环所需的时间。
- 迭代器返回的行数
- 循环的次数
MySQL EXPLAIN ANALYZE 的结果会显示查询运行前规划器的估算数据(如图中黄色突出显示部分)和查询实际运行后的数据(如绿色突出显示部分)。
EXPLAIN ANALYZE 的格式
EXPLAIN ANALYZE 可用于 SELECT 语句、多表 UPDATE 语句、DELETE 语句和 TABLE 语句。它会自动选择 FORMAT=tree 并执行查询(不会向用户显示任何输出)。EXPLAIN ANALYZE 专注于查询执行的关系以及部分查询的执行顺序。
EXPLAIN 输出以节点形式组织。在最低层,节点会扫描表或搜索索引;较高层的节点则操作来自低层节点的结果。
虽然 MySQL CLI 能以表格、制表符、垂直格式,以及漂亮或原始 JSON 格式打印 EXPLAIN 结果,但目前 EXPLAIN ANALYZE 不支持 JSON 格式。
EXPLAIN 和EXPLAIN ANALYZE的使用场景
当你不确定查询是否高效运行时,可以(且应)使用 EXPLAIN 查询。如果你认为已经正确索引并分区了表,但查询依旧运行缓慢,则可能需要使用EXPLAIN ANALYZE了。当查询进行EXPLAIN ANALYZE之后,就需要关注的输出内容以及优化目标了。
索引相关列:keys、possible keys 和 key lengths
在 MySQL 中处理索引时,需关注 possible_keys、key 和 key_len 列。
- possible_keys 列显示了 MySQL 可以选择的索引。
- key 列显示了实际选择的索引。
- key_len 列显示了所选索引的长度。
这些信息对设计索引、为特定任务决定使用何种索引,以及处理相关问题(如选择覆盖索引的适当长度)非常实用。
FULLTEXT 索引与连接
当使用 FULLTEXT 索引确保查询参与 JOIN 操作时,需注意 select_type 列,该列的值应为 fulltext。
分区
如果表已添加分区并希望查询使用这些分区,要观察 partition 列。如果 MySQL 实例正在使用分区,在大多数情况下,MySQL 会自动处理所有查询,而无需额外操作。如果希望查询使用特定分区,可以使用类似 SELECT * FROM TABLE_NAME PARTITION(p1,p2) 的查询。
EXPLAIN 的局限性
EXPLAIN 是一种估算工具。它有时是一个比较准确的估算,但有时可能非常不精确。以下是一些局限性:
- EXPLAIN 不会告诉你触发器、存储函数或 UDF 对查询的影响。
- 它不能分析存储过程。
- 它不会展示 MySQL 在查询执行期间的优化过程。
- 一些统计数据是估算值,可能非常不准确。
- 它不会区分某些具有相同名称的内容。例如,它用
filesort表示内存排序和磁盘排序,用Using temporary表示内存临时表和磁盘临时表。
SHOW WARNINGS 语句
需要注意的一点是:如果你用 EXPLAIN 的查询未正确解析,可以输入 SHOW WARNINGS; 查看最后一个运行的非诊断语句的信息。虽然它无法提供像 EXPLAIN 那样的查询执行计划,但它可能提供关于可处理的查询片段的线索。
SHOW WARNINGS; 包含一些特殊标记,其中信息可能包括:
<index_lookup>(query fragment):表明如果查询正确解析会进行索引查找。<if>(condition, expr1, expr2):表明该查询特定部分有 IF 条件。<primary_index_lookup>(query fragment):表明通过主键进行索引查找。<temporary table>:表明这里会创建内部表以保存临时结果(例如在连接之前的子查询中)。
MySQL EXPLAIN 的连接类型
MySQL 手册提到 type 列显示"连接类型",用以解释表的连接方式。但实际上更准确的说法是"访问类型",即告诉我们 MySQL 决定如何在表中找到行。
以下列出从性能最佳到最差的重要访问方式:
- NULL(较好):表示 MySQL 在优化阶段即可解析查询,不会在执行阶段访问表或索引。
- system(较好):表为空或仅有一行记录。
- const(较好):列值可视为常量(即查询只匹配一行)。注:主键查找、唯一索引查找。
- eq_ref(较好):索引是聚簇索引,被操作使用(索引为主键或 NOT NULL 的唯一索引)。
- ref (较好):使用等值运算符访问索引列。注:
ref_or_null是ref的变种,表示初次查找后需再查找 NULL 条目。 - fulltext(一般):操作(JOIN)使用了表的 FULLTEXT 索引。
- index(一般):扫描整个索引以找到查询匹配项。注:主要优势是无需排序;主要劣势是读取整张表成本高。
- range(一般):范围扫描为受限索引扫描,从索引某点开始返回匹配范围内的记录。注:这比全索引扫描更优。
- all(一般):MySQL 为满足查询而扫描全表。
还有一些其他类型需要了解:
- index_merge:此连接类型表示使用了索引合并优化,即通过多索引联合查询单表。
- unique_subquery :此类型替代某些形式的
eq_ref。通常用于以下形式的子查询:value IN (SELECT primary_key FROM single_table WHERE some_expr)。 - index_subquery :与
unique_subquery类似,但应用于非唯一索引的子查询。
EXPLAIN 的 EXTRA 列
EXTRA 列包含其他列中未涵盖的额外信息。以下是一些重要值及其定义:
- Using index:表示 MySQL 将使用覆盖索引避免访问表。
- Using where:MySQL 服务器将在存储引擎检索行后进行行的后过滤。
- Using temporary:MySQL 会通过临时表保存排序结果。
- Using filesort:MySQL 使用外部排序来排序结果而非按照索引顺序读取行。
- Range checked for each record:(index map:N),表示没有合适索引,并会对连接中的每行重新评估索引。
- Using index condition:表通过访问索引元组并在读取完整表之前进行测试读取。
- Backward index scan:MySQL 使用降序索引完成查询。
- const row not found:表明查询的表为空。
- Using index for group-by:表明 MySQL 能利用某个索引优化 GROUP BY 操作。
EXPLAIN 优化查询的实践示例
下面通过一个实践案例来演示一下使用 MySQL EXPLAIN 优化查询的方法。
运行初始查询
在开始之前,先创建一个数据库,并使用MySQL员工样例数据库进行初始化。
通过使用多列索引和MySQL EXPLAIN,允许数据库引擎联合使用多列加速查询。
例如,优化下列查询:
SQL
SELECT * FROM employees WHERE last_name = 'Puppo' AND first_name = 'Kendra';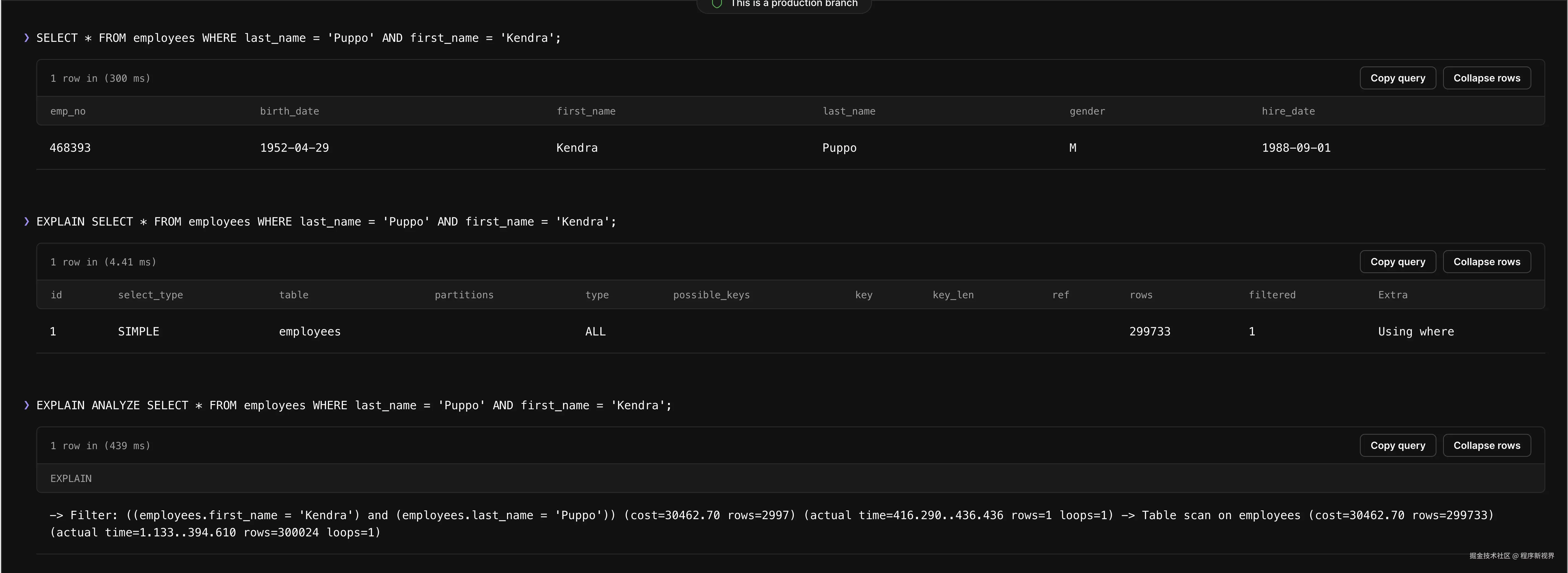
在运行该查询后,EXPLAIN 的结果显示访问了 299,733 行,而这是我们需要优化以提升性能的根本原因。
优化方法 1:创建两个独立索引
一种方法是分别为 last_name 列和 first_name 列创建单独索引,但这种方式有一个问题------MySQL 知道如何找到所有姓 Puppo 的员工,也知道如何找到所有名为 Kendra 的员工,但却无法同时高效找到名为 Kendra Puppo 的员工。
其他需要注意的事项:
- 当面对多个不相关的索引以及包含多个过滤条件的查询时,MySQL 有几种选择可以用来处理这些情况。
- MySQL 支持索引合并优化(Index Merge),可联合使用多个索引来执行查询。然而,这种优化有一定局限性,因此在构建索引时应该将其视为一般规则。MySQL 可能会决定不使用多个索引;即使会使用,在很多情况下,多个索引的联合效果也远远不如一个专门的索引。
优化方法 2:使用多列索引
由于第一种方法的问题,我们知道需要找到一种解决方案来使用能够考虑多列的索引。这里我们可以使用多列索引来实现这一目标。
可以将其想象成一本电话簿嵌套在另一本电话簿中。首先,查阅姓氏 "Puppo",然后进入第二个目录,该目录按名字的字母顺序组织所有名为 "Kendra" 的人,在这个目录中可以快速找到"Kendra Puppo"。
在 MySQL 中,若要为 employees 表中的姓氏和名字创建多列索引,可以执行以下命令:
SQL
CREATE INDEX fullnames ON employees(last_name, first_name);现在,多列索引已成功创建,我们可以执行以下 SELECT 查询来查找名字为 Kendra 且姓氏为 Puppo 的记录。结果将是一行数据,其中包含名为 Kendra Puppo 的员工信息。
使用 EXPLAIN 来检查该查询是否使用了索引:
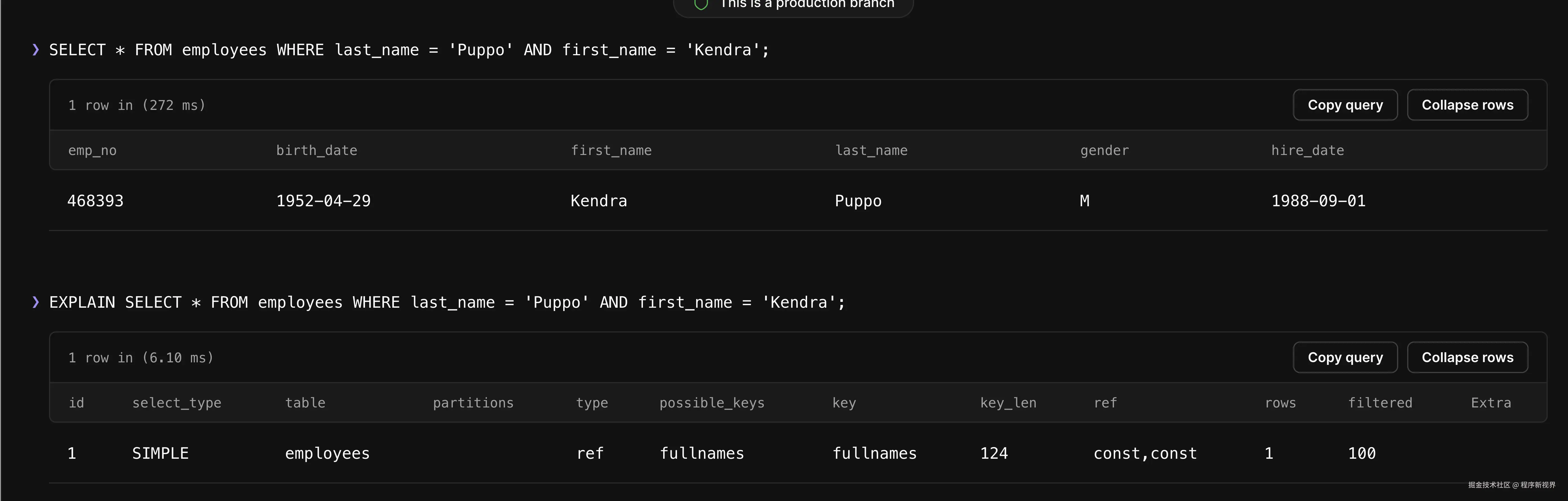
查询优化后的结果显示,索引被使用,并且只访问了一行数据来完成请求。这比优化前必须访问 299,733 行要高效得多。
结论
MySQL 的 EXPLAIN 语句可以用来获取查询执行的信息,在设计架构或索引时非常有价值。利用 MySQL 提供的功能进行优化,可以大幅提升数据库性能。