在关系型数据库中,主键(Primary Key)不仅是数据唯一性的保障,更是索引优化、外键关联和分布式系统同步的基础。MySQL 中最常用的主键策略是 AUTO_INCREMENT 自增 ID。然而,当这张看似"无限"的序列走到尽头时,系统将面临严重故障。
一、MySQL 自增主键的底层机制
1. 自增 ID 的实现原理
MySQL 的 AUTO_INCREMENT 值由存储引擎负责管理(InnoDB 为当前主流)。其核心机制如下:
- 每张表独立维护一个自增值计数器,该计数器在内存中由 InnoDB 的数据字典(data dictionary)持有;
- 插入记录时,若未显式指定主键值,系统将自动分配当前计数器值,并将其递增;
- 默认起始值为 1,步长为 1(可通过
auto_increment_offset和auto_increment_increment参数调整); - 持久化机制 :自增值并非存储在用户可见的系统表(如
innodb_table_stats)中,而是在以下位置协同保障一致性:- 内存:运行时缓存于 InnoDB 表对象的元数据中;
- Redo Log:在事务提交时,自增值的变更会写入 redo log,确保崩溃恢复后能重建正确状态;
- 数据字典表空间 (
mysql.ibd):从 MySQL 8.0 起,自增值作为表元数据的一部分,持久化在内部数据字典(DD, Data Dictionary)中,不再依赖.frm文件或information_schema的临时缓存。
注意 :
information_schema.TABLES中AUTO_INCREMENT字段可查询当前自增值,但其来源是 InnoDB 内存中的最新状态。
2. 数据类型决定上限
| 数据类型 | 有符号最大值 | 无符号最大值 |
|---|---|---|
TINYINT |
127 | 255 |
SMALLINT |
32,767 | 65,535 |
MEDIUMINT |
8,388,607 | 16,777,215 |
INT |
2,147,483,647 | 4,294,967,295 |
BIGINT |
9,223,372,036,854,775,807 | 18,446,744,073,709,551,615 |
最佳实践 :生产环境务必使用
BIGINT UNSIGNED作为自增主键类型,以避免过早耗尽。
二、自增 ID 耗尽会发生什么?
1. 具体现象
当插入新记录时,若当前自增值已达到列类型的上限,MySQL 将抛出错误:
sql
ERROR 1467 (HY000): Failed to read auto-increment value from storage engine或(取决于版本和配置):
sql
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range此时,所有依赖该自增主键的新写入操作将失败,导致服务中断。
2. 常见误区澄清
- ❌ "删除记录会回收 ID" → 不会。自增值只增不减。
- ❌ "重启 MySQL 会重置自增值" → 不会。InnoDB 会在启动时从最大现有 ID + 1 初始化。
- ✅ 手动
INSERT INTO ... VALUES (MAX_ID)会导致自增值跳变,但不会回退。
三、检测与预防策略
1. 监控自增值使用率
可通过以下 SQL 查询当前使用比例(以 BIGINT UNSIGNED 为例):
sql
SELECT
table_name,
auto_increment AS current_value,
ROUND((auto_increment / 18446744073709551615.0) * 100, 4) AS usage_percent
FROM information_schema.tables
WHERE table_schema = 'your_db_name'
AND auto_increment IS NOT NULL;建议设置告警阈值(如 >80%)。
2. Mermaid 流程图:自增 ID 生命周期与风险点
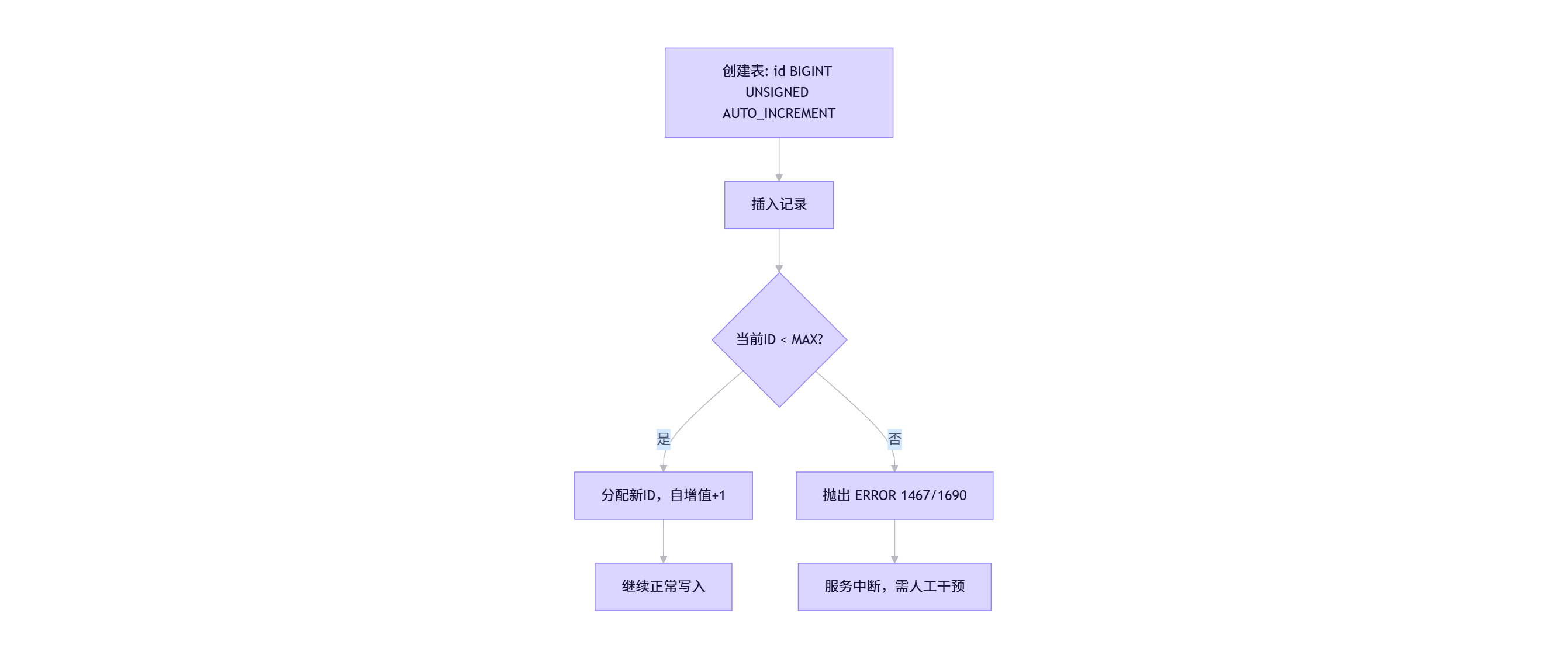
四、替代方案:雪花算法(Snowflake ID)
1. 什么是雪花算法?
由 Twitter 于 2010 年提出,是一种分布式唯一 ID 生成算法,结构如下(64 位):
| 位段 | 长度(bit) | 说明 |
|---|---|---|
| 符号位 | 1 | 始终为 0(正数) |
| 时间戳 | 41 | 毫秒级时间,约可用 69 年 |
| 机器 ID | 10 | 支持最多 1024 个节点 |
| 序列号 | 12 | 每毫秒最多 4096 个 ID |
总计:1 + 41 + 10 + 12 = 64 bits → 可存入 BIGINT(MySQL 中为 8 字节)
2.深度拆解:从一个 Snowflake ID 看透其内部结构
示例:
1729382256910270465
第一步:将十进制 ID 转为二进制
text
ID = 1729382256910270465将其转换为 64 位二进制(高位补零):
0110000001010111101101111111111111111111111111111111000000000001为便于阅读,按字段分组:
[0] [1100000010101111011011111111111111111111] [1111111111] [000000000001]
↑ ↑←──────────── 41 位 ────────────→↑ ←─10位─→ ↑←──12位──→↑
符号 时间戳(毫秒偏移) 机器ID 序列号第二步:提取各字段(使用位运算原理)
需理解位移与掩码的数学本质。
1. 提取时间戳(高 41 位)
时间戳占据高 41 位,相当于将原数右移 22 位(因为低位有 10 + 12 = 22 位):
timestamp_offset=⌊1729382256910270465222⌋timestamp_offset=⌊2221729382256910270465⌋
计算:
- 222=4,194,304222=4,194,304
- 1729382256910270465÷4,194,304≈412,236,7221729382256910270465÷4,194,304≈412,236,722
时间戳偏移 = 412,236,722 毫秒
这表示从系统设定的"纪元"(epoch)起,已过去约 412236.7 秒(≈4.77 天)。
2. 提取机器 ID(中间 10 位)
先右移 12 位(去掉序列号),再对 210=1024210=1024 取模:
machine_id=⌊1729382256910270465212⌋ 1024machine_id=⌊2121729382256910270465⌋mod1024
计算:
- 212=4096212=4096
- 1729382256910270465÷4096=4222124699487961729382256910270465÷4096=422212469948796
- 422212469948796 1024=1023422212469948796mod1024=1023
✅ 机器 ID = 1023
10 位最大值为 210−1=1023210−1=1023 ,说明使用了全 1 编码(
1111111111₂)。
3. 提取序列号(低 12 位)
直接对 212=4096212=4096 取模:
sequence=1729382256910270465 4096=1sequence=1729382256910270465mod4096=1
✅ 序列号 = 1
表示这是该毫秒内生成的第 2 个 ID(从 0 开始计数)。
第三步:还原真实生成时间
Snowflake 的时间戳是相对于自定义 epoch 的毫秒数 。假设系统采用 2020-01-01 00:00:00 UTC 作为 epoch(Unix 毫秒时间戳为 1577836800000),则:
绝对时间戳=1577836800000+412236722=1990073522722绝对时间戳=1577836800000+412236722=1990073522722
转换为可读时间(UTC):
- 1990073522722 毫秒 = 2033-01-15 12:12:02.722 UTC
🔍 若系统使用 Twitter 默认 epoch(2010-11-04 01:42:54 UTC =
1288834974657),则时间为:1288834974657+412236722=17010716967791288834974657+412236722=1701071696779 → 2023-11-27 左右 。因此,准确还原时间必须知道部署时的 epoch 设置。
第四步:汇总解析结果
| 字段 | 值 | 说明 |
|---|---|---|
| 原始 ID | 1729382256910270465 | --- |
| 时间戳偏移 | 412,236,722 ms | 自定义 epoch 起经过的时间 |
| 机器 ID | 1023 | 集群中编号最大的节点(10 位全 1) |
| 序列号 | 1 | 该毫秒内第 2 个生成的 ID |
| 推测生成时间(epoch=2020-01-01) | 2033-01-15 12:12:02 UTC | --- |
小结
通过纯数学推导,我们无需任何工具即可"透视"一个 Snowflake ID 的全部信息。这种能力对于以下场景尤为关键:
- 故障排查:快速定位 ID 来源节点与生成时刻;
- 容量评估:通过序列号判断单节点是否达到每毫秒 4096 ID 的上限;
- 架构审计:验证机器 ID 分配是否唯一,避免冲突风险。
Snowflake ID 不仅是主键,更是一份自描述的元数据载体。
3. 与自增 ID 对比
| 维度 | 自增 ID(MySQL) | 雪花 ID(Snowflake) |
|---|---|---|
| 唯一性 | 单表内唯一 | 全局唯一 |
| 分布式支持 | ❌ 需分库分表协调 | ✅ 天然支持 |
| 可排序性 | ✅ 严格递增 | ✅ 时间有序(近似递增) |
| 存储空间 | 8 字节(BIGINT) | 8 字节(BIGINT) |
| 生成性能 | 依赖数据库写锁 | 本地生成,无 DB 依赖 |
| 可读性 | 简单连续 | 不直观,含时间/机器信息 |
| ID 耗尽风险 | 有(依赖数据类型) | 几乎无(41 位时间戳 ≈ 2036 年后需调整) |
4. 雪花算法的挑战
- 时钟回拨问题 :系统时间被调回会导致 ID 重复。解决方案包括:
- 缓存最后时间戳并拒绝回拨请求;
- 使用 NTP 严格同步;
- 引入"等待"机制直至时间追上。
- 部署复杂度:需管理机器 ID 分配(可结合 ZooKeeper、etcd 或配置中心)。
五、解决方案与最佳实践
1. 短期应急措施(自增 ID 已耗尽)
-
扩大字段类型 (如
INT→BIGINT):sqlALTER TABLE your_table MODIFY id BIGINT UNSIGNED AUTO_INCREMENT; -
重置自增值 (仅适用于无业务依赖的测试环境):
sqlALTER TABLE your_table AUTO_INCREMENT = 1;生产环境慎用!可能造成主键冲突。
2. 长期架构建议
| 场景 | 推荐方案 |
|---|---|
| 单体应用,低并发 | BIGINT UNSIGNED AUTO_INCREMENT |
| 微服务/分库分表架构 | 雪花 ID 或 UUID(带索引优化) |
| 高吞吐写入 + 全局唯一需求 | Snowflake / ULID / NanoID |
注意 :UUID 虽全局唯一,但随机性导致 InnoDB 聚簇索引频繁分裂,性能较差。若使用,建议采用
UUID_TO_BIN(uuid(), true)(MySQL 8.0+)进行时间局部性优化。
六、常见面试题
-
问 :MySQL 自增主键用完后会发生什么?如何避免?
答 :插入失败并报错;应使用BIGINT UNSIGNED,并监控使用率。 -
问 :雪花 ID 为什么能保证全局唯一?它的组成部分是什么?
答:由时间戳 + 机器 ID + 序列号组成,三者组合确保唯一性。 -
问 :自增 ID 和雪花 ID 在 InnoDB 中对索引性能有何影响?
答:自增 ID 连续写入,B+ 树高效;雪花 ID 近似有序,性能略低但可接受;UUID 随机性差,应避免直接使用。 -
问 :如何解决雪花算法的时钟回拨问题?
答:可缓存最后时间戳,拒绝回拨期间的 ID 生成,或等待系统时间追上。 -
问 :能否在 MySQL 中实现雪花 ID 生成?
答 :不推荐。应由应用层生成(如 Java 的@GeneratedValue(strategy = GenerationType.IDENTITY)替换为@GenericGenerator),避免数据库成为瓶颈。