Github Copilot刚推出时,我就有开始使用,目前已是Cursor重度用户,最近也开始尝试使用Claude Code(200美元订阅计划直接拉满)。
从我的实践来看,要实现好的AICoding效果,需要满足四个要素:
- 强力的底座模型【需求理解能力】
- 丝滑的人机协同体验【对AI辅助编程交互的理解】
- 优秀的上下文工程【有效信息组织能力】
- 准确的需求描述【问题抽象和表述能力】
前三个要素,基本是由模型和编程工具侧来保障,当然上下文工程我们需要做一部分,比如将项目背景知识、团队协作规范等梳理成CursorRules(在Claude Code中是CLAUDE.md),约束大模型每次生成代码时遵守。
我个人认为目前最好用且性价比最高 (数据飞轮带来的护城河)的还是Cursor【优秀的上下文工程 + 丝滑的人机协同体验】 + claude-4-sonnect【强力的模型底座】。
随着工具和模型能力的增强,Vibe Coding 一度变得盛行。这就非常考验我们对于需求的准确表述能力,也是影响每个人使用AI编程效果好坏的一个关键因素,例如:
- 你是否擅长将一个带有复杂背景的问题进行抽象后精确表达,又不遗漏关键信息?
- 你是否擅长将一个复杂的需求一步步稳定地指导AI来完成?
那时候,我常采用的一种方法是:问题澄清。
因为,AI的表达能力绝大部分情况下比我们要强,让其理解清楚后再执行,往往比执行后反复纠错要高效得多。
所以,对于稍微复杂的,我个人没有信心表达清晰的问题,我会先和Cursor进行几轮交流,第一轮先输入我对问题或需求的表达,让其理解,我来审查是否理解到位,如果有偏差,指出问题,继续交流,直到它输出的理解符合预期再执行。
对于一些有复杂上下文背景,很难一次性表达完整的问题,我会先抽象出最简单本质的问题,再逐步添加上下文进行多轮交流,直到它完全理解整个问题,再开始执行。
如今看来,那时候我所采用的问题澄清 的方式,其实就是如今流行的Spec Coding(规范驱动编程) 的雏形。
可以看出,纯粹的Vibe Coding效果非常不可控,最终效果的好坏完全取决于个人驾驭AI的能力,在一些生产级项目上滥用很可能留下巨大的技术债务,将成本从开发阶段转移到了调试、测试和部署等后续环节。
延展一下思维
那是否能设计一套标准的工作流,任何开发同学使用都能尽量保障AI生成稳定且可控的生产级代码呢?
我们再来看前看面提到的"澄清"这个概念,将其贯穿我们的研发环节,如果用AI来辅助编码,哪些事项可能需要被澄清呢?
- 需求的完整性和准确性需要被澄清
- 需求方案的设计合理性需要被澄清
- 开发任务的拆解合理性需要被澄清
- 开发任务的表述准确性需要被澄清
- Bug的现场细节需要被澄清
去年,我们在尝试用AI开发小游戏时,就开始使用这一理念来贯穿工作流:
创意策划 -> 需求完善 -> 方案设计 -> 任务拆分 -> 任务执行 -> Debug (ai → 人),每一步由AI完成,但需要人来充分审查,确认没问题再进入下一步,human in the loop。具体详见去年的文章【从创意到上线:用ChatGPT + Winsurf 快速开发HTML5小游戏的实战指南】。
那时候,没有MCP,Cursor也没有压倒性优势,我们通过多个模型,多个工具来整合任务,比如在ChatGPT上来完成任务执行之前的工作,Winsurf专注任务执行和Debug。
如今,随着Cursor越来越强大,我们通过MCP和CursorRules协同,就能将这个工作流丝滑嵌入在Cursor中。我之前的文章《Vibe coding 最后一公里: 打造一套通用的AI任务拆分和管理系统》就是尝试的雏形,只是现在的整个工作流已经打磨得更加成熟稳定。
逐渐变成正规军 - Spec Coding
越来越多的工具使用这一理念,例如OpenAI的Codex,Devin.ai,亚马逊的Kiro Spec和阿里的Qoder甚至直接将这一流程集成到它们的AI IDE中,包括最近腾讯出的CodeBuddy也是一样,说明这是一个当前或者未来较长一段时间内正确的方向。
逐渐地,这一理念开始进化成一套标准规范:规范驱动开发(Specification-Driven Development, SDD),简称为"Spec Coding" 。
Spec Coding将开发过程组织成一系列清晰的、人与AI强协同的阶段,例如规范、规划、任务、实现,其中一条至关重要的规则是:在当前阶段未被完全验证之前,绝不进入下一阶段。这种机制强制引入了纪律性,确保了每个步骤的质量。
从大的层次划分,Spec Coding主要分成三个阶段。
阶段1:需求文档的规范化
在一家公司的工业级项目中,需求文档一般由产品同学编写,而需求质量又直接决定了最终产出的质量,是整个流程中价值最高的部分。大家应该也遇到过一句话需求的问题。
一种方式是定义一套标准的PRD规范,强制要求产品同学遵循。但在实践中,这类硬性约束往往难以长期维持,容易流于形式。
一种更好的解法是:AI辅助澄清与结构化。
我们可以让AI扮演一个经验丰富的产品专家角色。产品同学可以先按照原有的工作方式完成第一版需求文档,然后AI会基于预设的需求背景知识进行追问和引导,通过交互式的方式辅助产品同学逐步澄清、细化需求,并最终自动生成一份结构清晰、要素完整的需求文档。
在以上的步骤中,很明显,需求背景知识非常重要,它能帮助AI充分了解这个需求所属的功能模块原有的逻辑细节,进而能够有效洞察还缺哪些关键信息。
"
需求背景知识比较适合持续迭代的需求,因为需要了解历史功能细节,对于一些完全独立的、新的功能模块,重要性就没有那么高。
需求背景知识往往和项目功能逻辑细节强相关,我们之前采用人工梳理,每次功能迭代后,背景知识也要变更,效率极低。
现在,有了更高效的方式。
如果你的项目托管在github上,可以试试devin.ai出品的DeepWiki(deepwiki.org/),它能自动索引你的代...
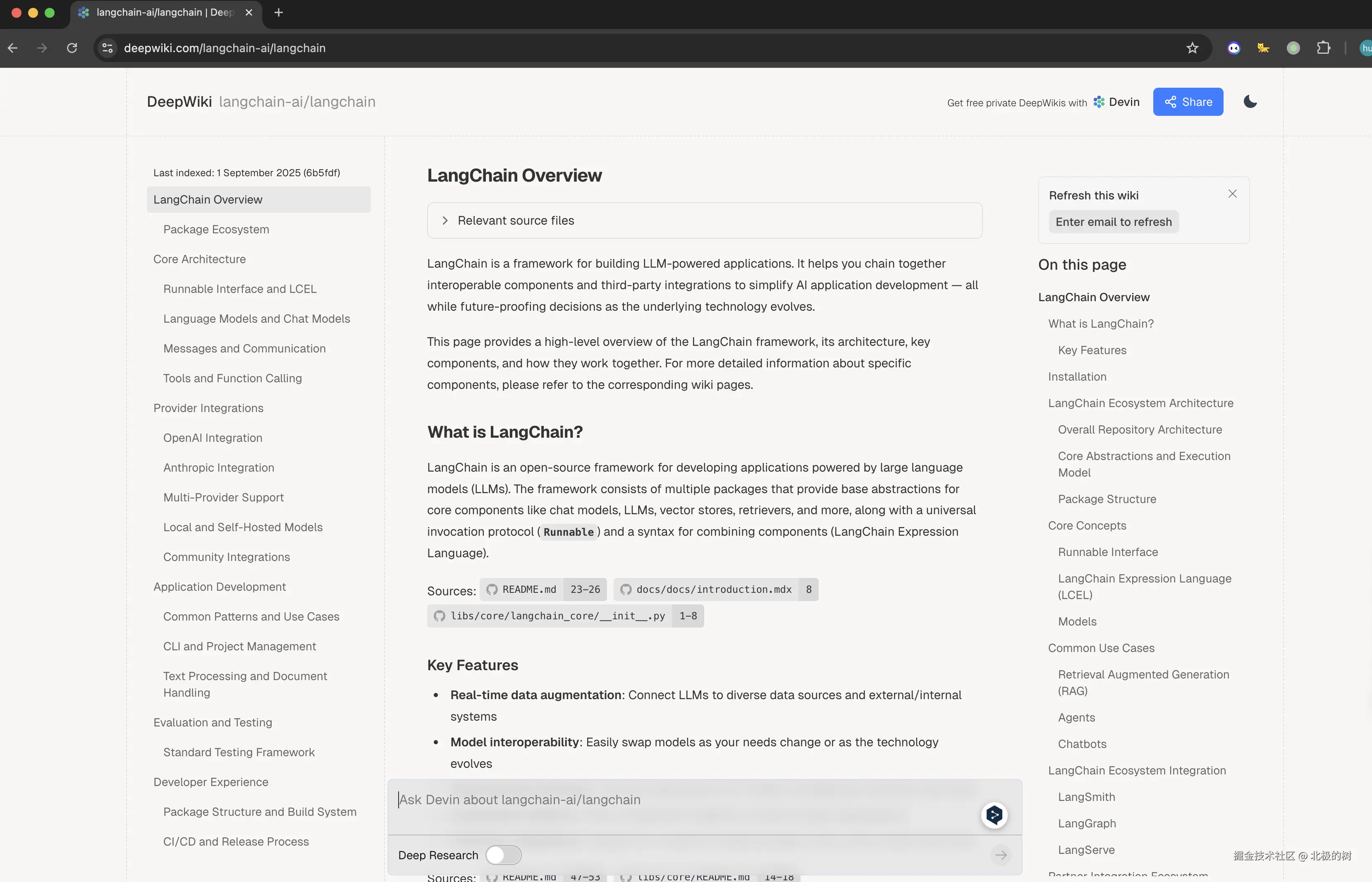
可以看图中文档的链接,其实就是将你的github仓库地址链接中的github单词修改成deepwiki,非常的方便使用。官方还直接提供了一套MCP Server支持知识库的问答。

这样,我们实现一个MCP Client(或直接用现成的),就可以结合产品第一版的需求文档,先从项目知识库中提取出所需的需求背景知识,接着进入下一步的AI辅助澄清与结构化流程。
那如果我们的项目无法托管在github上呢,要如何高效生成类似于DeepWiki的项目知识库?
github上有人研究DeepWiki的机制并实现了一个开源版本deepwiki-open(github.com/AsyncFuncAI...
还有一种方式是可以利用阿里近期发布的AI编程工具Qoder ,它内置的一个比较实用的功能就是RepoWiki,可以将你导入的项目仓库生成一份非常详细的知识库。

比较麻烦的是,Qoder生成的知识库只能在工具内部查看,无法导出,我看官方论坛上也有不少人吐槽。
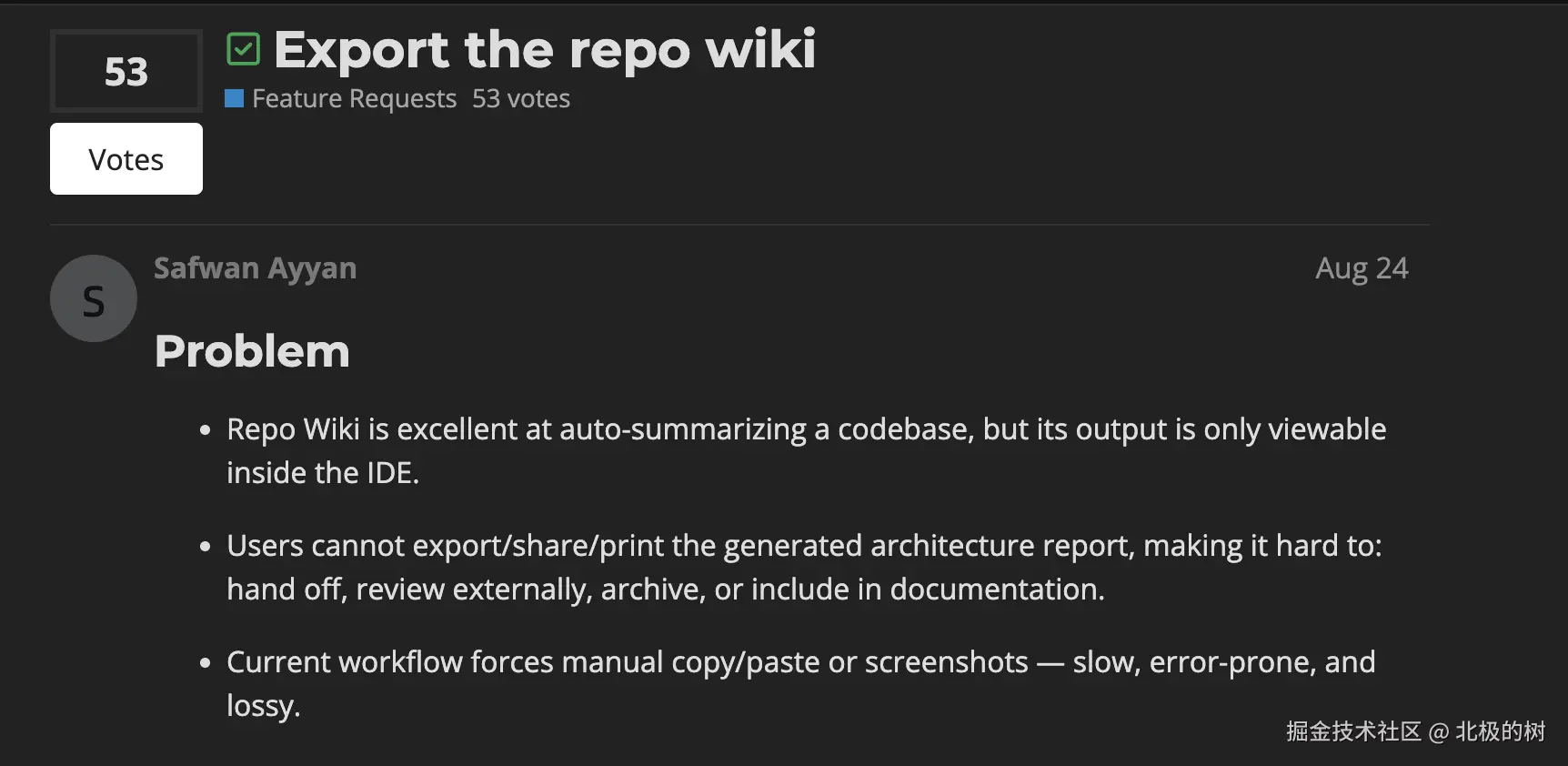
不过上有政策,下有对策,有哥们就逆向了相关的功能,写了一个支持导出的插件并开源了出来:github.com/AndreiTelte...
有了比较详细的知识库后,我们还需要结合产品的需求文档从知识库中提取出相关联的背景知识,再进入下一步的AI辅助澄清与结构化流程。
背景知识提取这一步可以使用Google开源的LangExtract ,它通过智能分块、多遍提取与智能合并、精确溯源等策略,支持了可以通过用户的指令让大模型从非结构化的长文本中,挖掘出精确、可靠的结构化信息,对于它的原理我在旧文中有详细分析:【从源码看Google LangExtract如何应对长文本数据挖掘的挑战】,这里就不再展开。
阶段二:技术方案的规范化
有了上一步输出的高质量需求文档后,就进入了技术实现阶段。直接把整份文档丢给AI说"帮我实现它",这还是Vibe Coding的思路,结果必然不可控。
在Spec Coding中,第二阶段的核心是技术规划。
我们可以将第一阶段产出的需求给到AI,让其结合我们的代码库(比如在Cursor中或者Claude Code中,尽量选择更好的模型)生成一份技术实现方案,这份方案并非代码,而是一份高层次的蓝图,可能包含:
- 架构影响分析:需要新增、修改、抽象哪些模块?
- 核心组件设计:关键的类、函数、或模块的的职责定义。
- 数据模型变更:涉及的数据库表结构设计或修改。
- 协议设计: 需要设计的通信协议细节(
注:如果已经有通信协议了,那么可以设计业务层的实体对象)。 - 依赖与风险:指出潜在的技术难点、外部依赖或风险。
以上只是我认为在技术方案设计过程中比较重要的一些点,大家实际过程中可以结合自己的项目按需定制。
有了设计的技术方案后,我们要做的就是认真审查、修订并最终确认这份由AI生成的规划。在这个过程中,可以和AI一起迭代优化、直至方案收敛到一个理想状态。
这个阶段需要确保的是在正确的方向上做事,避免在错误的技术路线上执行接下来的工作。
阶段三:分解并执行任务
当技术方案确认后,我们就拥有了一份清晰的"施工图"。这一阶段的核心任务,便是将这份"施工图"拆解成一系列可以独立执行的原子任务。这与敏捷开发原则相契合,可以尽量保障由AI完成的每一步编码工作更容易被调试和确认。
传统开发中,这一步依赖于负责的开发同学手动拆分,而在Spec Coding流程中,我们可以让AI根据第二阶段的规划,自动生成一份详细的有明确前后依赖关系的任务清单(相当于在实际开发时,先做A、再做B)。
例如,一个"实现用户个人资料页"的规划,可能会被AI拆解成:
- Task 1: 创建 GET /api/v1/users/{id} 的后端API路由
- Task 2: 实现 UserService 中的 getUserProfile(userId) 方法,包含数据库查询逻辑
- Task 3: 编写 Task 2 的单元测试
- Task 4: 创建前端 ProfilePageComponent 组件的骨架
- Task 5: 在组件中调用API获取数据并渲染页面
- ...
这些任务力度较小,目标明确,上下文清晰。此时,开发同学只需在AI IDE中逐一指令AI:"执行任务1"、"执行任务2"、.....。
由于每个任务足够简单且已被前面的阶段充分定义,AI生成代码的准确性会指数级提升(要用较好的模型)。开发同学只需进行少量审查和微调,就可以快速完成功能。这个过程将复杂的系统开发,降维成了一系列"连连看"式的操作,有效提升了编码效率和代码质量的稳定性。
还有一个细节点 ,Spec Coding非常适合测试驱动开发的工作模式(TDD),在拆解开发任务的过程中,我们可以要求AI为每个任务生成一个测试用例(纯逻辑场景)。AI 的核心工作就是编写代码,使得这个预先定义的测试能够通过。
没有万金油的开发流程,只有最合适的方式
虽然Spec Coding很好用,但从日常开发过的形形色色的项目来看,并没有一个万金油的AI开发流程,如果希望能借助AI极致提升自己的效率,需要的是我们持续提升对不同AI模型能力边界、和AI协作的模式、以及不断进化的AI编程生态的认知。
拿Spec Coding来说,它比较适合复杂的,并且相对独立的功能模块。对于一些错误修复或局部改动、以及一些重UI的场景,就不太适合。
同时,由于Spec Coding是文档优先的模式,那如何有效管理文档也是有一定的成本,我们一定要活学活用,用最合适的方式来为自己的工作提效。
举个简单的例子,假设我们的产品有三端:Android、iOS和鸿蒙。现在产品规划了一个新的功能,由于一些特殊情况我们的产品无法使用跨平台开发方案,那就需要分别在这三端在实现产品功能,如何实现效率更高呢?
如果是我,可能采取的方式是:先在Android上用AI辅助快速实现这个功能。接着让Cursor帮我生成一份该功能的方案文档,包括架构设计、对外接口标准、使用示例等所有细节。接着,我利用Cursor 5.0新增加的multi-root workspaces能力,在一个工作区同时打开Android、IOS、鸿蒙三端项目,共享上下文,让AI使用刚生成的功能文档,同时充分参考Android的接口实现,快速在iOS和鸿蒙上准确实现了相关功能。并且三端架构设计一致、接口一致,后续查问题也方便。
结语
说到底,Spec Coding 并非要取代我们已经习惯的 Vibe Coding,它更像是在我们的工具箱里,为处理复杂任务增加了一套更可靠的章法。
面对简单的 bug 修复或功能微调,Vibe Coding 的直接和随性依然是最高效的。但当我们需要构建一个稳定、可维护的复杂功能时,Spec Coding 这种"先想清楚再动手"的模式,能有效避免返工,确保产出质量。
AI 工具在变,但软件工程追求清晰、严谨的本质没变。希望总结的这些实践,能帮大家更好地将 AI 融入日常工作,让它真正成为我们手上的一把利器。