Writing effective tools for agents --- with agents
摘要
智能体的效能取决于我们交给它的工具。本文分享如何编写高质量的工具和评测方法,并介绍如何让 Claude 参与优化这些工具,从而提升整体表现。
引言
Model Context Protocol(MCP)可以为 LLM 智能体接入数量可达数百的工具,以解决真实世界任务。那么,如何让这些工具的效用最大化?
本文总结了我们在各类智能体系统中提升性能的有效技术。主要包括:
- 构建并测试工具原型
- 使用智能体创建并运行针对工具的综合评测
- 与智能体(如 Claude Code)协同,自动提升工具性能
最后,我们凝练出撰写高质量工具的关键原则:
- 选择该实现、与不该实现的工具
- 通过命名空间(namespacing)为工具功能划定清晰边界
- 让工具返回对智能体有意义的上下文
- 为 token 效率优化工具响应
- 对工具描述与规格做"提示工程(prompt-engineering)"
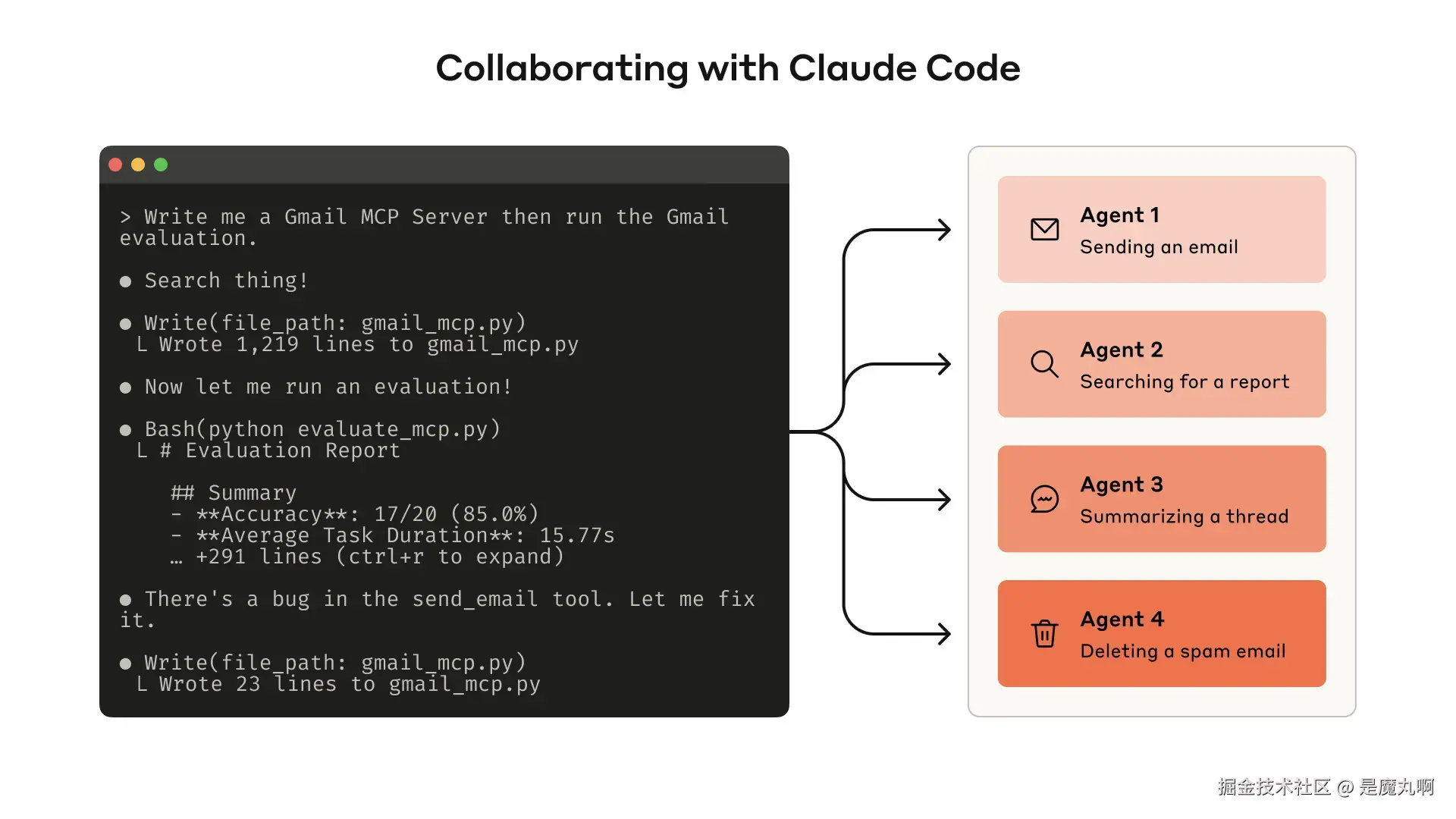
构建评测能系统衡量你的工具表现。你可以用 Claude Code 依据该评测自动优化工具。
什么是「工具」?
在计算中,确定性系统 在相同输入下总是产生相同输出,非确定性系统(如智能体)即使在同样的起点也可能生成不同响应。
我们传统写软件,是在确定性系统间建立契约。比如 getWeather("NYC") 每次都以同样方式获取纽约天气。
工具(tools)是一类新的软件形态:它建立的是确定性系统 与非确定性智能体之间的契约。当用户问"今天要带伞吗?",智能体也许会调用天气工具、也许凭常识回答、也许先追问你的位置,甚至偶尔会幻觉或不会用工具。
这意味着:写给智能体用的工具与我们为开发者/系统写函数或 API 的思路根本不同 ------我们需要为智能体而设计工具与 MCP 服务器。
我们的目标,是扩大智能体可有效发挥的"问题空间表面",让它能通过工具采取多种成功策略。幸运的是,对智能体"手感好"(ergonomic)的工具,也往往对人类直观易懂。
如何编写工具
本节介绍如何与智能体协作来编写与改进工具。先快速搭起原型并本地测试;接着运行综合评测衡量迭代效果;与智能体一同反复评估---改进,直到在真实任务上取得强性能。
构建原型
很难预判哪些工具"手感好"、哪些不好,上手做原型 最直接。若用 Claude Code 来一把梭写工具(甚至 one-shot 生成),建议把工具依赖的库/API/SDK(含 MCP SDK)文档一并喂给 Claude。面向 LLM 的文档常见于官网提供的扁平 llms.txt(例如我们的 API 文档)。
把你的工具包进本地 MCP 服务器 或桌面扩展(DXT) ,即可在 Claude Code 或 Claude Desktop 里连接测试。
- 将本地 MCP 服务器连到 Claude Code:运行
claude mcp add <name> <command> [args...]。 - 将本地 MCP 服务器或 DXT 连接到 Claude Desktop:前往 Settings > Developer (或 Settings > Extensions)。
- 也可以直接把工具作为参数传入 Anthropic API 做程序化测试。
请你自己先测一遍,找出粗糙处;同时收集用户反馈,建立对工具使用场景与提示语的直觉。
运行评测
接下来要测量 Claude 使用你工具的效果。先大量生成评测任务 ,要贴近真实用途。我们建议与智能体协作 来分析结果并决定如何改进工具。完整流程见我们的工具评测手册(cookbook) 。
生成评测任务
使用早期原型时,Claude Code 能很快探索你的工具并产出数十组 "提示---响应"对。提示应受真实用途启发,并基于真实数据源与服务(如内部知识库与微服务)。避免过度简单/表面化的"沙盒环境";强任务往往需要多次工具调用,甚至几十次。
强任务示例:
- "帮我安排下周与 Jane 的会议讨论 Acme Corp 最新项目,附上上次项目规划会的笔记,并预订会议室。"
- "客户 9182 报告一次购买被扣了三次。请找出所有相关日志项,并判断是否有其他客户受影响。"
- "客户 Sarah Chen 刚提交了退订请求。请准备挽留方案,并确定:(1) 她离开的原因;(2) 最有吸引力的挽留方案;(3) 提出报价前需注意的风险因素。"
弱任务示例:
- "与 jane@acme.corp 安排下周会议。"
- "在支付日志中搜索
purchase_complete且customer_id=9182。" - "找到客户 45892 的退订请求。"
每个评测提示都应配可验证的响应/结果。验证器可以很简单(与标准答案做精确字符串比对),也可以更高级(用 Claude 评价)。避免过于严格的验证器因格式、标点或等价表述差异而误判错误。
可选地,你也能为每个样例标注"期望被调用的工具",以衡量智能体是否理解各工具的用途。但务必避免过度指定策略,因为完成任务的路径可能不止一条。
执行评测
我们建议通过直接的 LLM API 调用 以编程方式运行评测。为每个评测任务使用简单的agent 循环 (while 循环在 LLM 调用与工具调用之间交替)。每个评测智能体接收一个任务提示 与你的工具集合。
在评测智能体的系统提示 中,建议指示它们输出结构化响应块 (供验证)以及推理与反馈块 。要求在工具调用前就输出这些内容,常能触发**链式思考(CoT)**行为,提高有效智能。
如果用 Claude 运行评测,你可以开启 interleaved thinking(交错思考) ,获得类似能力。这能帮助你洞察智能体为何(不)调用某些工具,并凸显需改进的工具描述与规格处。
除了总体准确率,还建议采集:单次工具调用与整题运行时长、工具调用总次数、token 用量、工具错误 等。跟踪调用能暴露智能体常走的工作流,从而启发你合并若干工具能力。
分析结果
智能体是发现问题与提供反馈的好伙伴:从互相矛盾的工具描述 、低效实现 到混乱的 schema 。不过要注意,智能体在反馈/回答里没说出来的,往往比说出来的更关键------LLM 并不总能把它"想要表达的"都说清。
观察智能体卡壳/困惑 的地方。阅读评测智能体的推理与反馈(或 CoT),定位粗糙点。回看原始对话记录 (含工具调用与响应),捕捉推理里没写明的行为。读懂弦外之音:评测中的智能体未必知道正确答案与策略。
分析工具调用指标:
- 若冗余调用很多 ,可能需要重设分页或 token 上限参数;
- 若参数无效导致错误很多 ,可能需要更清晰的描述或更好的示例 。
例如我们在发布 Claude 的网页搜索工具 时,发现 Claude 会多余地给查询参数加上"2025" ,导致结果偏置与性能下降;我们通过改进工具描述来纠正。
与智能体协作
你甚至可以让智能体替你分析结果并改工具 。把评测对话的转录 拼接后丢给 Claude Code。Claude 擅长分析大段转录,并批量重构 工具(例如在引入新改动时保持工具实现与描述一致)。
实际上,本文大多数建议都来自我们反复用 Claude Code优化内部工具实现的经验。我们的评测构建在内部工作区之上,尽量映射真实的复杂度(真实项目、文档、消息等)。
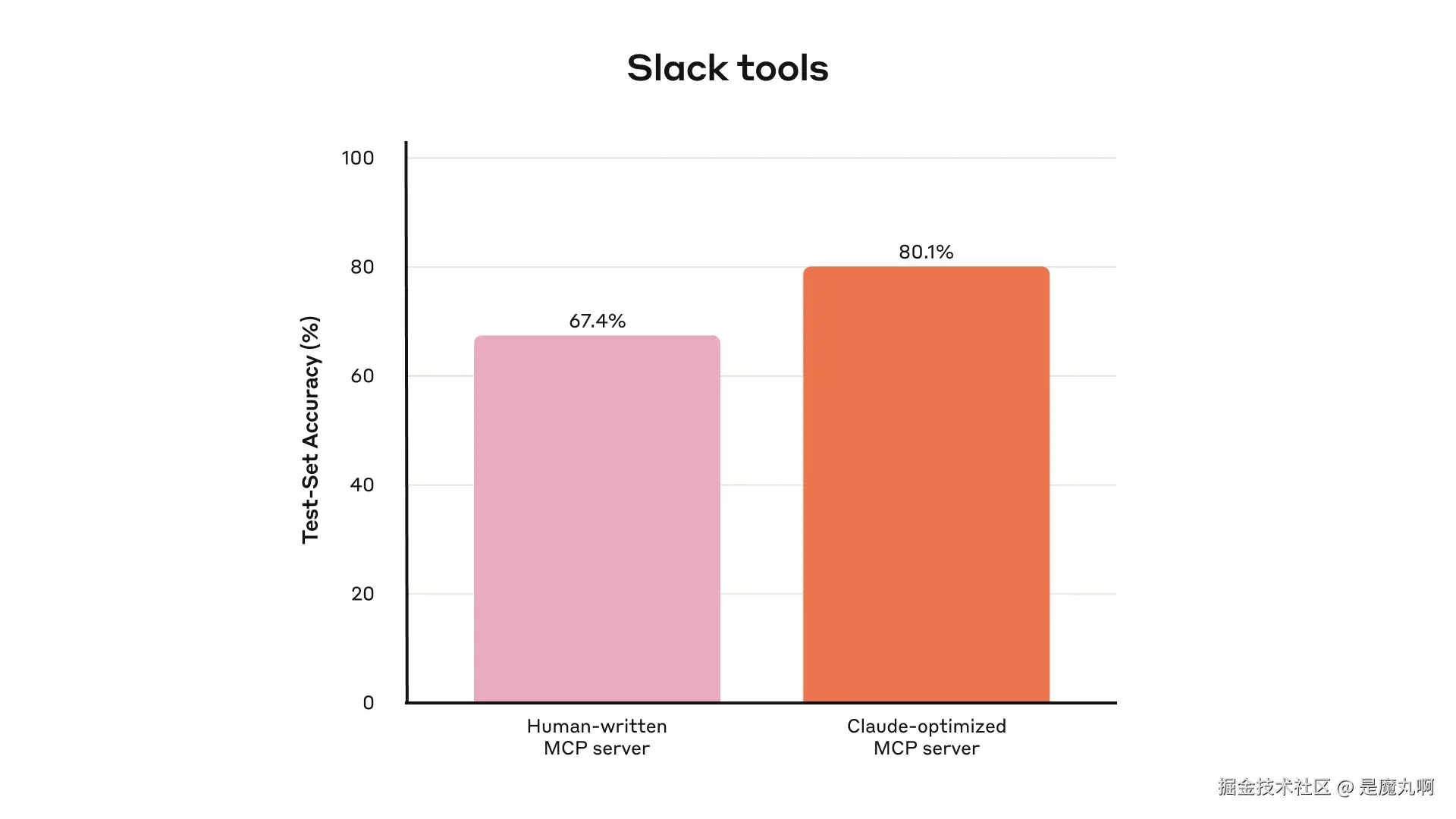
我们使用留出测试集避免对"训练用评测"过拟合。留出集显示:即便与"专家手写"工具比,借助 Claude 也能进一步挖掘性能空间------不论"专家"是研究员手写的,还是 Claude 生成的。
编写高效工具的原则
1) 为智能体选择合适的工具
工具越多不一定越好 。常见误区是:无差别地把现有软件功能或 API 端点包成工具,而不管是否适配智能体。智能体的"可供性"(affordances)不同于传统软件。
LLM 智能体的上下文有限 ,而计算机内存便宜又充足。比如在通讯录里找联系人:传统程序可以逐条高效检索;但若智能体用一个返回所有联系人 的工具,再逐项"读 token",这就非常低效。更自然的方式是先跳到相关页(如按字母索引)。
建议先构建少量但深思熟虑 、并能覆盖高影响工作流 的工具,与评测任务相匹配,再逐步扩展。比如,优先实现 search_contacts 或 message_contact,而不是 list_contacts。
工具可以整合功能 ,在内部串起多次离散操作(或 API 调用)。例如,工具可以在返回中附加关联元数据 ,或把常见的多步链式流程 封装到单次调用里。
示例:
- 不要分别实现
list_users/list_events/create_event,而实现能查找可用时段并创建 的schedule_event。 - 不要实现
read_logs,而实现search_logs,只返回相关日志行与必要上下文。 - 不要拆成
get_customer_by_id、list_transactions、list_notes,而实现get_customer_context,一次性汇总客户近期且相关的信息。
确保每个工具目标清晰、功能明确。工具应帮助智能体像人类一样把任务拆解并解决,同时减少中间产出对上下文的占用。
过多或功能重叠的工具会分散智能体注意力,妨碍其采用高效策略。慎选要做/不做的工具,回报很高。
2) 用命名空间划定边界
你的智能体可能接入数十个 MCP 服务器、上百个工具 ,且包含他人开发的工具。当工具功能重叠或目标模糊时,智能体会不知该用哪个。
命名空间 (将相关工具置于共同前缀/分组)有助于划界;部分 MCP 客户端也会默认这样做。比如按服务 命名(asana_search、jira_search)或按资源 命名(asana_projects_search、asana_users_search),都能帮助智能体在正确时间选对工具。
我们发现,前缀式 vs 后缀式 命名空间方式对工具使用的评测结果有非平凡影响;不同 LLM 差异也很大,建议按你自己的评测选择方案。
通过只实现那些名称能反映任务自然分解 的工具,你既减少了需加载进上下文的工具/描述数量,也把一部分"智能体端的计算"转移回工具调用,从而降低出错风险。
3) 让工具返回有意义的上下文
同理,工具实现应谨慎控制返回,只把高信号信息 交还智能体。优先上下文相关 而非"灵活泛化",避免低层技术标识(如 uuid、256px_image_url、mime_type)。像 name、image_url、file_type 这类字段更能直接推动后续行动与回答。
智能体处理自然语言名称/术语/标识 的能力显著强于处理晦涩 ID 。我们发现,仅仅把任意字母数字 UUID解析为 更有语义、可解释的语言(甚至是从 0 开始的顺序 ID),就能显著降低幻觉、提升检索精准度。
有些场景下,智能体需要既能用自然语言 也能用技术 ID 来驱动后续调用(如 search_user(name="jane") → send_message(id=12345))。你可以通过加一个 response_format 枚举参数来实现,例如让工具支持 "concise" 与 "detailed" 两种返回。需要触发后续工具调用时,智能体可以切到 "detailed" 获取所需 ID。
你也可以提供更多格式以获得更灵活的粒度,类似 GraphQL 的字段选择。示例:
ini
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}举例:
- "详细(detailed)"响应中会包含
thread_ts、channel_id、user_id等,用于后续抓取 Slack 线程回复; - "精简(concise)"则仅返回线程内容,不含 ID。该例中,使用"精简"响应仅用到约三分之一的 token。
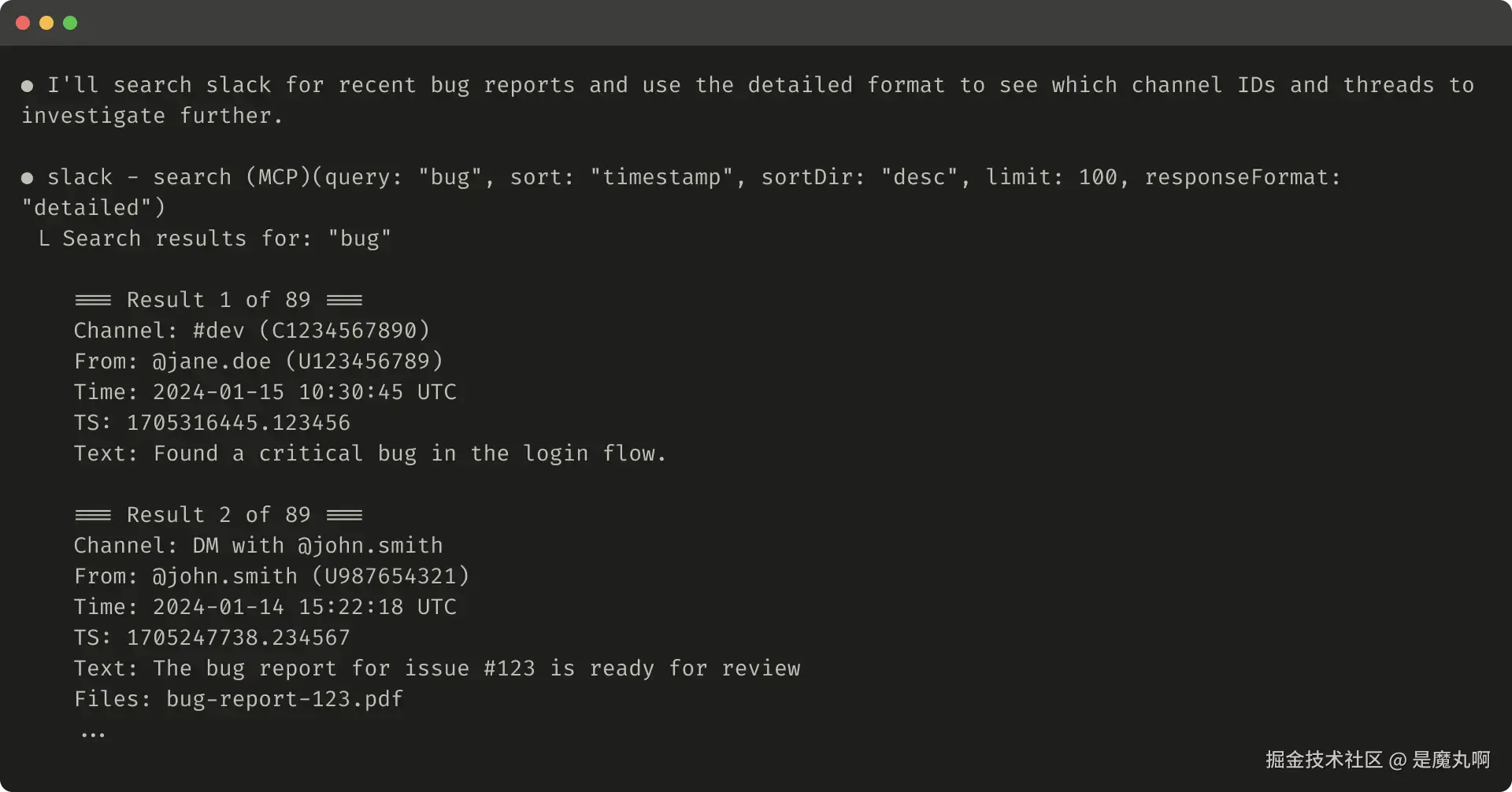
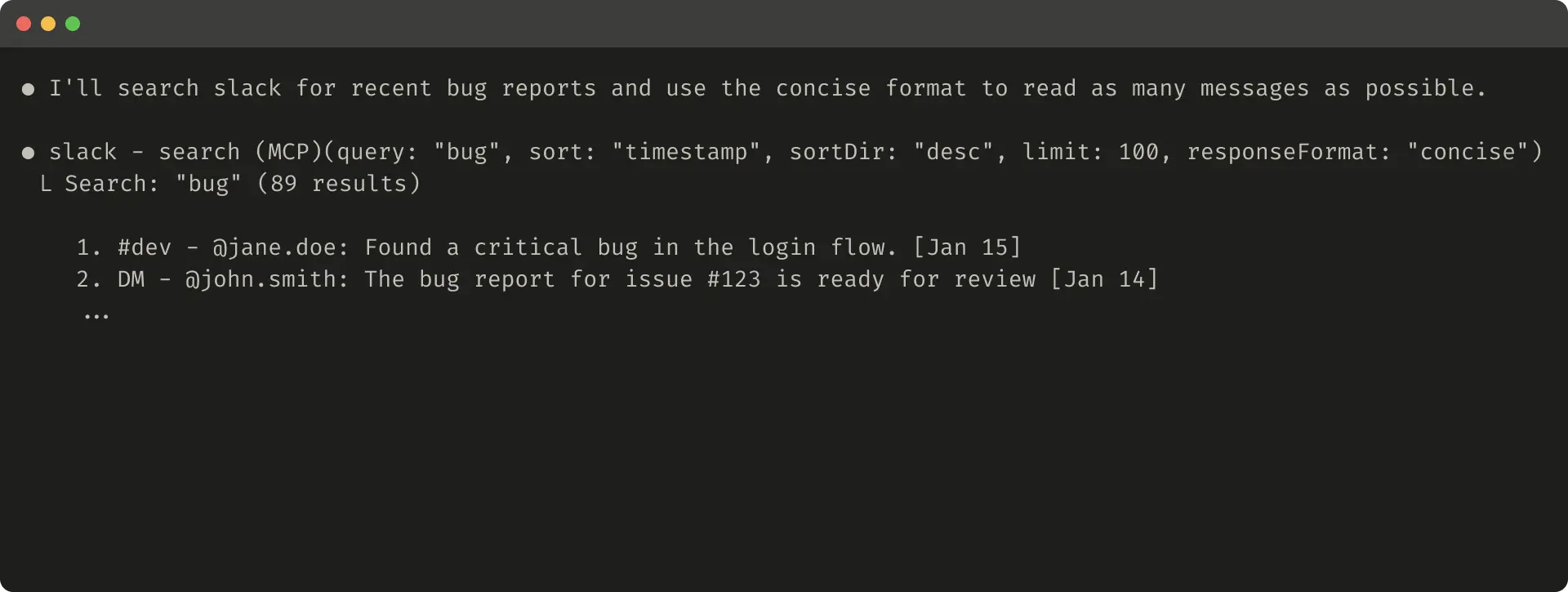
另外,连响应结构 (XML/JSON/Markdown)也会影响性能:LLM 基于下一个 token 预测 进行训练,常对贴合训练分布 的格式表现更好。不存在一招通吃,最佳结构在不同任务与智能体间差异很大,建议根据你的评测选择。
4) 为 token 效率优化工具响应
优化"上下文质量"很重要,"上下文数量"同样关键。
对任何可能消耗大量上下文的工具返回,建议实现分页、区间选择、过滤、截断 中的若干,并设置合理默认值 。在 Claude Code 中,我们默认将工具响应限制为 25,000 tokens 。我们预期智能体的有效上下文会随时间增长,但对上下文高效工具的需求将长期存在。
若选择截断 ,务必在返回中明确指引 :鼓励智能体采用更节省 token 的策略(如多次小范围定向搜索,而非一次大范围检索)。类似地,当工具输入校验报错时,你可以对错误响应做提示工程 ,给出清晰且可操作的修正建议,而不是不透明的错误码或回溯。
5) 对工具描述做"提示工程"
这是提升工具效果最有效 的方法之一:工具的描述与规格 会被加载到智能体的上下文,它们可以整体引导智能体采用更有效的工具调用行为。
撰写工具描述与规格时,想象你在给团队的新同事讲解:把你默认知道 的上下文说清楚------例如专用查询语法、术语定义、资源间关系等;通过严格数据模型 (枚举/正则/必填)避免歧义。尤其是输入参数 必须无歧义命名 :用 user_id 代替 user。
借助你的评测,你可以有把握地 衡量这些提示工程对性能的影响。即便是小改动 也可能带来显著提升 。例如,我们在对工具描述做了精确改进之后,Claude Sonnet 3.5 在 SWE-bench Verified 上达成了最新 SOTA,大幅降低错误率、提升任务完成率。
更多工具定义最佳实践见我们的开发者指南 。如果你在为 Claude 写工具,也建议阅读"工具如何被动态加载进 Claude 的系统提示"。若你在为 MCP 服务器写工具,工具注解 可用于声明哪些工具需要 open-world 访问 或会做破坏性变更。
展望
要为智能体打造高效工具,我们需要把软件开发实践从可预测的确定性模式 ,转向非确定性的世界。
借助本文所述迭代---评测驱动 流程,我们识别出一组稳定的成功模式:有效的工具 定义清晰、有意图,审慎 使用智能体上下文、支持多种工作流组合,并让智能体能够直观地解决真实任务。
未来,智能体与世界交互的具体机制仍会演进------从 MCP 协议更新到底层 LLM 的升级。以系统化、评测驱动 的方法持续改进工具,我们就能保证:随着智能体能力增强,工具也能同步进化。