
在关系数据库这个世界里,所有东西(包括你要记录的人、物、事,以及它们之间的联系)都用一种叫做"关系"的结构来表示。而这种"关系"的灵魂,就是"码"(Key)。
1. 核心思想:万物皆"关系"
"实体及实体之间的联系均用单一的数据结构---"关系"来表示。"
- 通俗解释 :
- 实体 (Entity) :就是你要描述的独立事物。比如,"学生"、"课程"、"老师"都是实体。
- 联系 (Relationship) :就是实体之间的关联。比如,"学生"和"课程"之间有"选课"这个联系。
- 核心思想 :在老式的数据模型里,"实体"和"联系"可能是用不同的方式来存储和表示的,很麻烦。关系模型的革命性之处在于,它说:"别搞那么复杂了!不管是'学生'这种实体,还是'学生选了什么课'这种联系,我们全都用一种统一的、规整的二维表格(也就是'关系')来表示。"
这就像乐高积木,不管你要搭城堡、飞船还是汽车,你用的都是同一种基本积木块。这种"单一"和"统一"带来了极大的简洁性和理论上的严谨性。
2. 基本概念回顾
"关系、域、n目关系、元组、属性。"
- 关系 (Relation) :就是一张二维表。
- 元组 (Tuple) :就是表里的一行数据。
- 属性 (Attribute) :就是表里的一列,比如"姓名"列、"学号"列。
- 域 (Domain) :属性的取值范围,比如"性别"属性的域是
{男, 女}。 - n目关系:就是有n列的关系(表)。
3. 灵魂概念:"码" (Key)
"码"是用来唯一标识一行数据 的,就像你的身份证号,它能把你和全世界几十亿人精确地区分开。没有"码",数据就会乱套。
候选码 (Candidate Key)
"关系中的某一属性组,若它的值唯一地标识了一个元组,并具有最小性,则称该属性组为候选码。"
这个定义有两个关键点,我们用一个"学生表"来解释:
学生表 (学号, 身份证号, 姓名, 性别)
-
关键点1:唯一性 (Uniqueness)
学号在这个表里是不是唯一的?是的,每个学生的学号都不同。身份证号是不是唯一的?是的,每个人的身份证号也不同。姓名是不是唯一的?不一定,可能有同名同姓的人。- 所以,
{学号}和{身份证号}都满足唯一性。
-
关键点2:最小性 (Minimality)
- 定义 :"最小性"指的是,组成这个码的属性一个都不能少。如果去掉任何一个属性,它就不唯一了。
- 我们来看
{学号},它本身只有一个属性,没法再少了,所以它满足最小性。 - 同样,
{身份证号}也满足最小性。 - 再看一个组合
{学号, 姓名}。这个组合肯定是唯一的(因为学号就唯一了)。但是,它满足最小性吗?不满足! 因为你把姓名去掉,只剩下{学号},它照样是唯一的。所以{学号, 姓名}这个组合是冗余的,不满足最小性。
-
结论 :在这个学生表中,同时满足"唯一性"和"最小性"的属性组有两个:
{学号}和{身份证号}。这两个都是候选码。它们都是成为"官方ID"的有力候选人。
主码 (Primary Key)
"若一个关系有多个候选码,则选定其中一个为主码。"
- 通俗解释 :这完全是一个人为选择的过程。
- 上面我们找到了两个候选码:
{学号}和{身份证号}。现在,数据库的设计者需要从中挑选一个作为这张表的"官方指定ID"。 - 比如,我们决定用
{学号}作为主码。那么学号就是这张表的主码。身份证号虽然也是候选码,但它"落选"了,它被称为备用码 (Alternate Key)。
为什么要选一个主码? 为了方便。当别的表需要引用这张表的某一行数据时,大家有一个统一的标准,都知道用 学号 来关联,避免混乱。
主属性 (Prime Attribute) 与 非主属性 (Non-prime Attribute)
"码中的诸属性称为主属性,不包含在任何候选码中的属性称为非主属性。"
- 通俗解释 :这是一个对列(属性)的分类。
- 主属性 :只要一个属性是任何一个候选码的一部分 ,它就是主属性。
- 在我们的例子中,候选码是
{学号}和{身份证号}。 - 所以,
学号和身份证号这两个属性都是主属性。
- 在我们的例子中,候选码是
- 非主属性 :不包含在任何 候选码中的属性。
- 在我们的例子中,
姓名和性别这两个属性,它们既不是{学号}的一部分,也不是{身份证号}的一部分。 - 所以,
姓名和性别都是非主属性。
- 在我们的例子中,
这个区分非常重要,它是后续进行数据库设计规范化(比如判断是否满足第二范式、第三范式)的基础。
总结一下
- 关系:就是一张表,用来统一表示所有数据。
- 候选码:能唯一标识一行、且不含多余信息的"候选ID"(可能有多个)。
- 主码:从所有"候选ID"中,人为指定的那个"官方ID"(只有一个)。
- 主属性/非主属性 :对表里所有列的一个分类,凡是构成"候选ID"的列都是"主属性",其余都是"非主属性"。
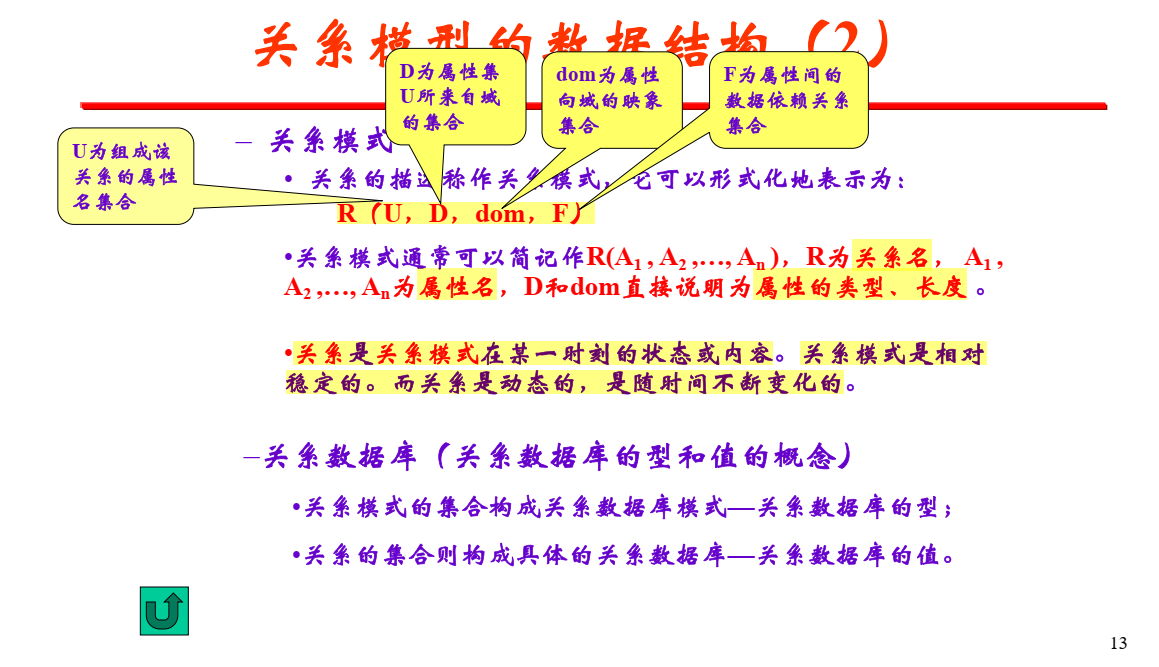
核心比喻:关系模式 vs. 关系
- 关系模式 (Schema) :这是设计蓝图 。它定义了你的"房子"(也就是你的数据表)应该长什么样:有几个房间(列)、每个房间叫什么名字(属性名)、墙壁是什么材质的(数据类型)、承重墙在哪里(主码和约束)。蓝图是静态的、稳定的。
- 关系 (Relation) :这是建好的房子里实际住进去的人和家具 。它是在某个时间点,你的数据表里真实存在的数据行。房子里的内容是动态的、随时变化的。
这张PPT就是在详细解释"设计蓝-图"(关系模式)到底由哪些部分构成。
关系模式的"精装修"设计蓝图:R(U, D, dom, F)
这个公式看起来吓人,但它只是把一张表的设计蓝图拆分成了四个组成部分。我们用一个学生表作为例子来解释:
学生 (学号, 姓名, 专业, 班主任, 班主任电话)
1. R: 关系名 (Relation Name)
- 含义:就是这张表的名字。
- 例子 :
学生
2. U: 属性名集合 (Set of Attributes)
- 含义 :这张表里所有列的名字的集合。
- 例子 :
U = {学号, 姓名, 专业, 班主任, 班主任电话}
3. D: 域的集合 (Set of Domains)
- 含义 :这是所有属性可能取值的"类型池"的集合。比如,"整数池"、"字符串池"、"日期池"等等。
- 例子 :我们的学生表需要整数(用于学号)和字符串(用于其他所有列)。所以
D = {整数域, 字符串域}。它只是一个原材料仓库,列出了这张表会用到哪些类型的"原材料"。
重点解释:dom 和 F
4. dom: 属性到域的"映象" (Mapping) - 【你的第一个困惑点】
-
学术定义 :"映象" (Mapping) 是一个数学术语,意思就是建立"一对一"或"多对一"的对应关系。
-
通俗解释 :
dom就是一份**"接线图"或"分配表"。它详细规定了,U集合里的 每一个属性(列名),应该从D集合里的哪一个"类型池"(域)**去取值。 -
例子:
dom规定了:学号→整数域(学号这一列必须是整数)姓名→字符串域(姓名这一列必须是字符串)专业→字符串域(专业这一列必须是字符串)- ...以此类推
-
它在实践中是什么?
当你在用SQL创建表的时候,
dom就体现在你的数据类型定义中:sqlCREATE TABLE 学生 ( 学号 INT, -- 这就是一条 dom 规则 姓名 VARCHAR(50), -- 这也是一条 dom 规则 专业 VARCHAR(50) -- 这还是一条 dom 规则 ... );所以,
dom就是定义每一列数据类型的规则集合。
5. F: 数据依赖关系集合 (Set of Data Dependencies) - 【你的第二个困惑点】
-
学术定义 :"数据依赖"描述了属性之间存在的约束关系。
-
通俗解释 :
F是这张表的"内在业务逻辑 "或"隐藏规则 "的集合。它说明了数据之间是如何相互关联和制约的。最常见的依赖就是函数依赖。 -
例子:在我们的学生表中,存在以下这些"隐藏规则":
- 只要
学号确定了,那么姓名、专业、班主任也就唯一确定了。- 这个规则在数学上记为:
学号 -> {姓名, 专业, 班主任}。 - 这个规则正是"
学号可以作为主码"的根本原因!
- 这个规则在数学上记为:
- 只要
班主任确定了,班主任电话也就唯一确定了。- 这个规则在数学上记为:
班主任 -> 班主任电话。 - 这个规则就是我们之前讨论的"传递依赖",它违反了第三范式(3NF)。
- 这个规则在数学上记为:
- 只要
-
它在实践中是什么?
F是数据库主码、外码约束以及范式理论的数学基础。我们设计数据库时,通过分析业务逻辑,找出这些数据依赖(F),然后根据这些依赖来决定如何设置主码、如何拆分表以满足2NF、3NF等范式要求,从而设计出结构优良的数据库。
从"精装修"蓝图到"简装"蓝图
关系模式通常可以简记作
R(A1, A2, ..., An)
- 解释 :上面那个
R(U, D, dom, F)是给理论家看的"精装修"蓝图,太复杂了。在日常工作中,我们用的是"简装"蓝图,也就是学生(学号, 姓名, 专业)这种形式。 - 为什么可以简化?
因为D(类型池) 和dom(接线图) 的信息,已经包含在我们给每一列定义的数据类型 里了(比如INT,VARCHAR)。而F(内在规则) 则体现在我们设置的主码、外码和我们遵循的范式里。所以,简化版已经足够我们使用了。
总结一下
| 抽象概念 | 通俗解释 | 实际对应 |
|---|---|---|
| 关系模式 (Schema) | 数据表的"设计蓝图" | CREATE TABLE 语句 |
| 关系 (Relation) | 表里某一时刻的真实数据 | SELECT * FROM ... 的结果 |
U |
所有列的名字 | 学号, 姓名, ... |
D |
用到的所有数据类型"池" | INT, VARCHAR, DATE 等 |
dom |
"接线图",规定哪一列用哪种数据类型 | 学号 INT; 姓名 VARCHAR(50); |
F |
"内在业务规则",列与列之间的约束 | 主码、外码、函数依赖(范式的基础) |
希望这个"蓝图"的比喻能帮你彻底理解 dom 和 F 的作用!它们一个是规定了"数据的静态类型 ",另一个是规定了"数据的动态约束"。