"好的架构都能在生活中找到原型"。ConcurrentHashMap(简称 CHM)作为 Java 并发容器的 "扛把子",其设计思想本质就是解决 "多个人同时用一个东西还不乱" 的问题 ------ 这和社区超市处理 "多顾客同时购物" 的逻辑如出一辙。今天咱们就用 "小 A 的社区超市" 故事,结合代码和时序图,把 CHM 的原理扒得明明白白。
一、故事开篇:为什么需要 CHM?(并发容器的痛点)
小 A 开了家社区超市,初期只有 1 个收银台(对应HashMap):
-
平时人少的时候,顾客拿东西、结账都很快;
-
一到下班高峰期,所有顾客都挤在一个收银台(多线程竞争同一把锁),后面的人全堵着(线程阻塞),甚至有人抢着付钱导致账单算错(数据不一致)。
小 A 试过把收银台换成 "全店锁"(对应Hashtable):只要有人在结账,全店其他人都不能动 ------ 虽然账单不会错,但效率低到顾客投诉,显然不行。
这时小 A 悟了:问题的核心是 "锁的粒度太粗" 。要让多个人同时操作,又不冲突,就得把 "大锁" 拆成 "小锁",让不同区域的操作互不干扰。这就是 CHM 的核心设计思想: "分而治之" 的并发控制。
二、CHM 的两代进化:从 "分区收银" 到 "智能货架"
CHM 的设计分两个关键版本(JDK1.7 和 JDK1.8),就像超市的两次重大升级,咱们逐个拆解。
1. JDK1.7:分区收银模式(Segment 分段锁)
小 A 的第一次升级:把超市分成 3 个独立区域(零食区、生鲜区、日用品区),每个区域配 1 个收银台(对应Segment)。规则是:
-
顾客买零食,只去零食区收银台,不影响生鲜区的人结账;
-
同一区域的顾客还是要排队(同一 Segment 内的线程竞争锁),但不同区域可并行。
这就是 JDK1.7 CHM 的核心 ------Segment 分段锁。
1.1 结构类比:超市分区 = CHM 的 Segment 数组
先看 JDK1.7 CHM 的核心结构(代码简化版):
java
public class ConcurrentHashMap<K, V> {
// 核心:Segment数组(每个Segment就是一个"分区收银台")
private final Segment<K, V>[] segments;
// Segment本质是个"小HashMap",且自带锁(继承ReentrantLock)
static final class Segment<K, V> extends ReentrantLock implements Serializable {
// 每个Segment内部有自己的HashEntry数组(对应分区内的货架)
transient volatile HashEntry<K, V>[] table;
// 分区内的元素数量
transient int count;
}
// 每个HashEntry就是货架上的"商品格子"(存储key-value)
static final class HashEntry<K, V> {
final int hash;
final K key;
// value用volatile修饰:保证多线程可见性(不用锁也能读对)
volatile V value;
// 链表:解决哈希冲突(同一货架摆多件商品)
volatile HashEntry<K, V> next;
}
}结构对应关系:
| CHM 组件 | 超市场景 | 作用 |
|---|---|---|
segments数组 |
3 个购物区域 | 拆分锁的粒度,实现分区并行 |
Segment |
区域收银台 + 货架 | 自带锁,控制区域内并发 |
HashEntry[] |
区域内的货架 | 存储具体数据(商品) |
HashEntry |
货架上的商品格子 | 存 key-value,链表解决冲突 |
1.2 核心操作:put(顾客结账)的流程
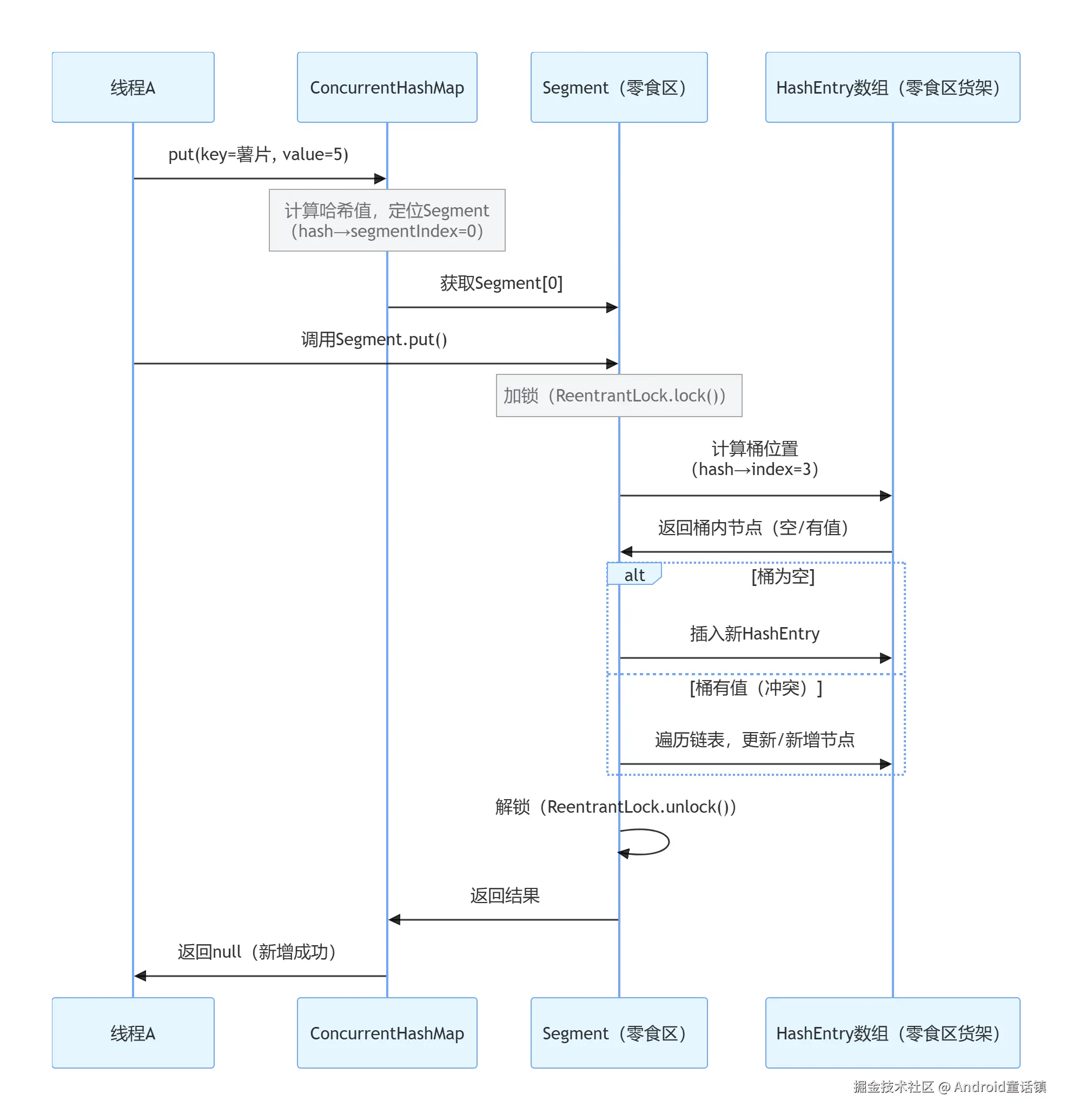
顾客买了一袋薯片(key = 薯片,value=5 元),结账流程对应 CHM 的put方法:
java
public V put(K key, V value) {
// 1. 计算key的哈希值,确定要去哪个Segment(比如哈希=1→零食区)
int hash = hash(key);
int segmentIndex = (hash >>> segmentShift) & segmentMask;
// 2. 拿到目标Segment,加锁(顾客去零食区收银台,锁住收银台)
Segment<K, V> s = segments[segmentIndex];
s.lock(); // 继承ReentrantLock的锁方法
try {
// 3. 在Segment内部的HashEntry数组中找位置(货架找格子)
HashEntry<K, V>[] tab = s.table;
int index = (hash >>> tabShift) & tabMask;
HashEntry<K, V> e = tab[index];
// 4. 处理冲突:如果格子已有商品,遍历链表(同一货架摆多件)
if (e == null) {
// 格子空,直接放新商品
tab[index] = new HashEntry<>(hash, key, value, null);
} else {
V oldValue;
// 遍历链表,找到相同key就更新value,否则加在链表末尾
for (;;) {
if (e.hash == hash && e.key.equals(key)) {
oldValue = e.value;
e.value = value; // 更新价格
break;
}
if (e.next == null) {
e.next = new HashEntry<>(hash, key, value, null); // 新增商品
break;
}
e = e.next;
}
}
// 5. 更新分区内的商品数量
s.count++;
return null;
} finally {
// 6. 解锁(结账完成,释放收银台)
s.unlock();
}
}关键亮点:
- 锁只加在
Segment上,其他Segment不受影响(零食区锁了,生鲜区照样用); HashEntry.value用volatile修饰:get方法不用锁就能读到最新值(顾客拿商品看价格,不用等收银台解锁)。
1.3 JDK1.7 的痛点:分区还是不够细
随着超市生意变好,每个区域的货架越来越长(HashEntry链表变长):
-
顾客找商品要遍历长链表(查询效率 O (n));
-
同一区域的顾客还是要排队(比如零食区人多,收银台依然拥堵)。
小 A 意识到:锁的粒度还能再细 ------ 从 "区域锁" 降到 "货架锁" 。这就催生了 JDK1.8 的升级。
2. JDK1.8:智能货架模式(CAS+synchronized + 红黑树)
小 A 的第二次升级:
-
去掉分区收银台,改成 "自助结账"(无锁 / CAS);
-
每个货架配一个 "临时锁"(
synchronized):只有人在这个货架拿东西时,才锁这个货架,其他货架正常用; -
把超过 8 件商品的长货架,换成 "智能旋转货架"(红黑树):找商品从 "逐个翻" 变成 "按编号定位"(查询效率从 O (n)→O (logn))。
这就是 JDK1.8 CHM 的核心:锁粒度降到桶级(货架)+ CAS 无锁操作 + 红黑树优化。
2.1 结构类比:智能货架 = CHM 的 Node 数组
JDK1.8 彻底抛弃了Segment,核心结构简化为 "Node 数组"(对应货架数组),冲突时用链表 + 红黑树存储:
java
public class ConcurrentHashMap<K, V> {
// 核心:Node数组(每个Node就是一个"货架")
transient volatile Node<K, V>[] table;
// 扩容时用的临时数组(相当于临时货架)
private transient volatile Node<K, V>[] nextTable;
// 基本节点:对应货架上的"商品格子"
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;
final K key;
// value和next都用volatile修饰:保证可见性
volatile V value;
volatile Node<K, V> next;
}
// 红黑树节点:长链表(>8)转红黑树时用
static final class TreeNode<K, V> extends Node<K, V> {
TreeNode<K, V> parent; // 父节点
TreeNode<K, V> left; // 左子树
TreeNode<K, V> right; // 右子树
boolean red; // 红黑树颜色标记
}
// 扩容标记节点:表示当前货架正在扩容
static final class MoveableNode<K, V> extends Node<K, V> {
Node<K, V>[] nextTable;
MoveableNode(Node<K, V>[] tab) {
super(-1, null, null, null); // hash=-1标记为MOVED
this.nextTable = tab;
}
}
}结构对应关系:
| CHM 组件 | 超市场景 | 作用 |
|---|---|---|
table(Node\[\]) |
智能货架数组 | 每个货架独立锁,粒度更细 |
Node |
货架格子 | 存 key-value,链表解决冲突 |
TreeNode |
智能旋转货架 | 长链表优化,提升查询效率 |
MoveableNode |
货架扩容标记 | 通知其他顾客帮忙扩容 |
2.2 核心操作:put(顾客自助结账)的流程
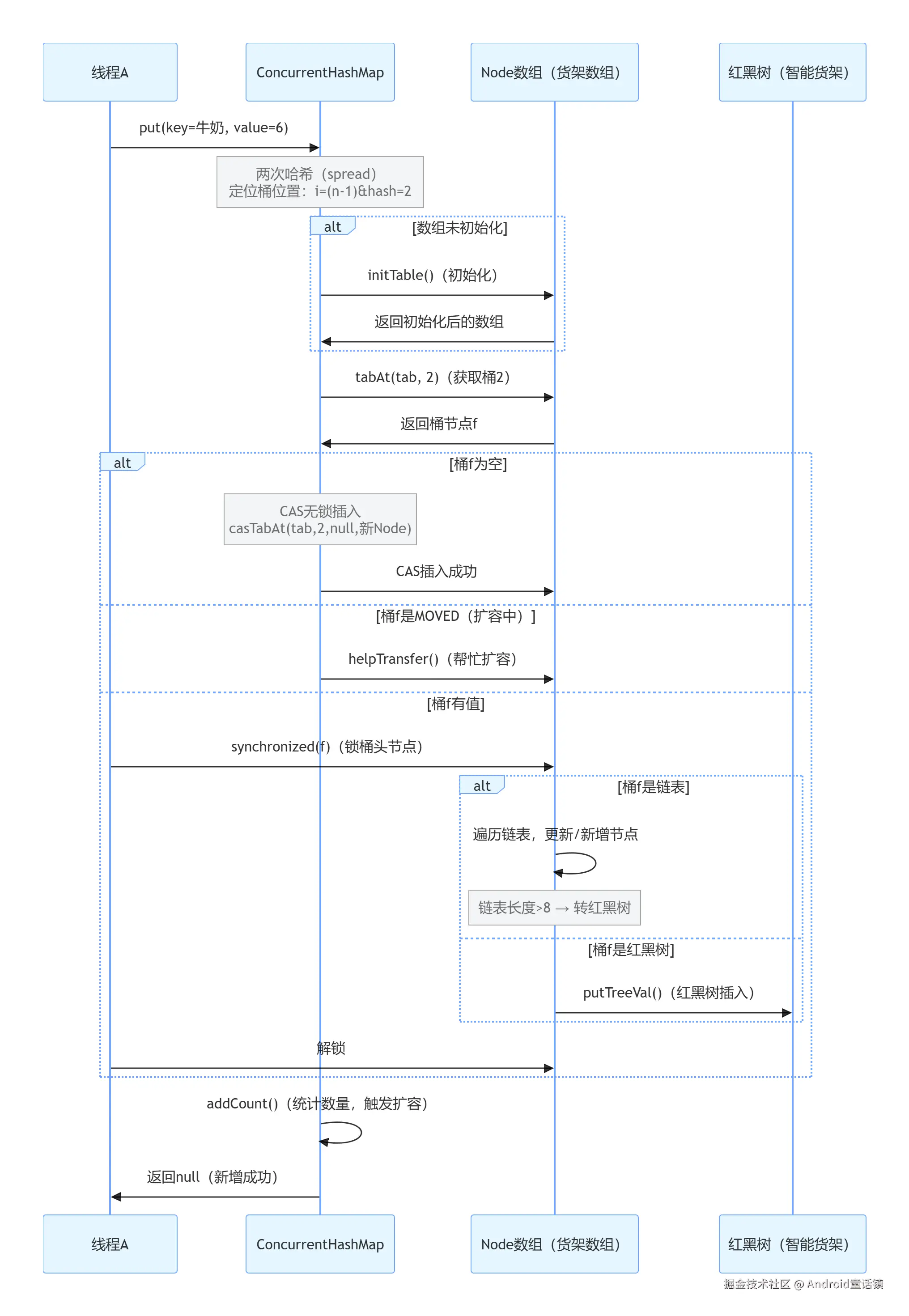
顾客买了一盒牛奶(key = 牛奶,value=6 元),自助结账流程对应 JDK1.8 CHM 的put方法(代码简化版):
java
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 1. 两次哈希:减少哈希冲突(相当于给商品编一个更唯一的货架号)
int hash = spread(key.hashCode());
int binCount = 0;
// 遍历Node数组(货架数组),自旋处理(没成功就重试)
for (Node<K, V>[] tab = table;;) {
Node<K, V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) {
// 2. 货架数组没初始化,先初始化(懒加载:顾客来才摆货架)
tab = initTable();
}
// 3. 定位到目标货架(i = 货架编号),如果货架为空
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 用CAS无锁插入:先看货架是不是空的,是空就放进去(不用等锁)
if (casTabAt(tab, i, null, new Node<>(hash, key, value, null))) {
break; // 插入成功,退出循环
}
}
// 4. 如果货架上有"扩容标记"(MoveableNode),帮忙扩容
else if ((fh = f.hash) == MOVED) {
tab = helpTransfer(tab, f); // 顾客帮忙搬货架,加速扩容
}
// 5. 货架有商品,加锁(只锁当前货架的头节点)
else {
V oldValue = null;
synchronized (f) { // 锁货架头节点,其他货架不受影响
// 再次确认货架没被修改(防止并发修改)
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 货架是链表结构
binCount = 1;
// 遍历链表,找key或插新节点
for (Node<K, V> e = f;; ++binCount) {
K ek;
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value; // 更新value
}
break;
}
Node<K, V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<>(hash, key, value, null); // 插链表末尾
break;
}
}
}
else if (f instanceof TreeNode) { // 货架是红黑树结构
// 红黑树插入(按红黑树规则旋转,保证平衡)
Node<K, V> p = ((TreeNode<K, V>)f).putTreeVal(this, tab, hash, key, value);
if (p != null) {
oldValue = p.value;
if (!onlyIfAbsent) {
p.value = value;
}
}
}
}
}
// 6. 检查链表长度,超过8就转红黑树(长货架换智能货架)
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) {
treeifyBin(tab, i);
}
if (oldValue != null) {
return oldValue;
}
break;
}
}
}
// 7. 统计元素数量,触发扩容(商品太多,加货架)
addCount(1L, binCount);
return null;
}JDK1.8 的核心优化点:
- 锁粒度最小化:从 "分区锁"→"货架锁"(只锁单个桶的头节点),多线程操作不同桶完全并行;
- CAS 无锁操作:空桶插入用 CAS(不用加锁),减少锁竞争;
- 红黑树优化:链表长度 > 8 转红黑树,查询效率从 O (n)→O (logn);
- 多线程扩容 :看到
MOVED节点的线程会帮忙扩容,加速过程; - 懒加载 :数组初始化延迟到第一次
put,节省内存。
三、时序图:直观看懂 CHM 的调用流程
用时序图(Mermaid 语法)展示 JDK1.7 和 JDK1.8 的put流程,更清晰看到差异。
1. JDK1.7 ConcurrentHashMap put 时序图
2. JDK1.8 ConcurrentHashMap put 时序图
四、总结:CHM 的设计思想精髓
从 "超市故事" 到代码实现,CHM 的设计始终围绕 **"并发安全" 与 "性能高效" 的平衡 **,核心思想可归纳为 3 点:
-
分而治之:锁粒度的持续细化
从
Hashtable的 "全局锁"→JDK1.7 的 "分段锁"→JDK1.8 的 "桶级锁",每一次细化都让并行度更高,冲突更少。 -
无锁 + 有锁:灵活的并发控制
用 CAS 处理 "无冲突场景"(空桶插入),用
synchronized处理 "有冲突场景"(桶内节点操作),既避免了锁的开销,又保证了冲突时的安全。 -
数据结构优化:为性能兜底
用 "链表 + 红黑树" 解决哈希冲突的效率问题,让查询从 "线性遍历" 变成 "对数查找",即使数据量大也不卡顿。
在 Android 开发中,CHM 常用于多线程缓存(如内存缓存LruCache的线程安全改造)、线程池参数存储等场景。理解它的设计思想,不仅能用好这个容器,更能学会 "如何在高并发场景下平衡安全与性能" 的架构思维。