在常规APP中,比如抖音视频流、小红书Feed流、剪映等软件,一般只涉及到短连接HTTP(https)请求。所以客户端可以较容易控制HTTP请求的时机,也就可以保证数据的准确性。
在IM软件中,由于长连接推送的存在,被动推送与主动拉取(推拉结合)是必然要配合的。那么推与拉就会产生很多数据一致性问题。
推拉结合
那么思考一个问题:有服务端数据推送的情况下,那就等服务端的推送不就好了,为什么还需要客户端主动获取数据?
举个简单的场景,在用户离线1周左右,冷启动后,客户端会跟服务端有大量数据传输,此时长连接通道因为是单通道的,下行通道一般会被占满,这里面的数据包含会话列表、消息列表等核心数据,也包含一些其他非核心业务的数据,比如日历日程、工作台、文档等。
为了让用户更快地 看到首页会话列表的最新状态,一般在冷启动后,客户端就会通过短连接HTTP直接拉取首页的一些关键信息,如会话列表、消息列表等。
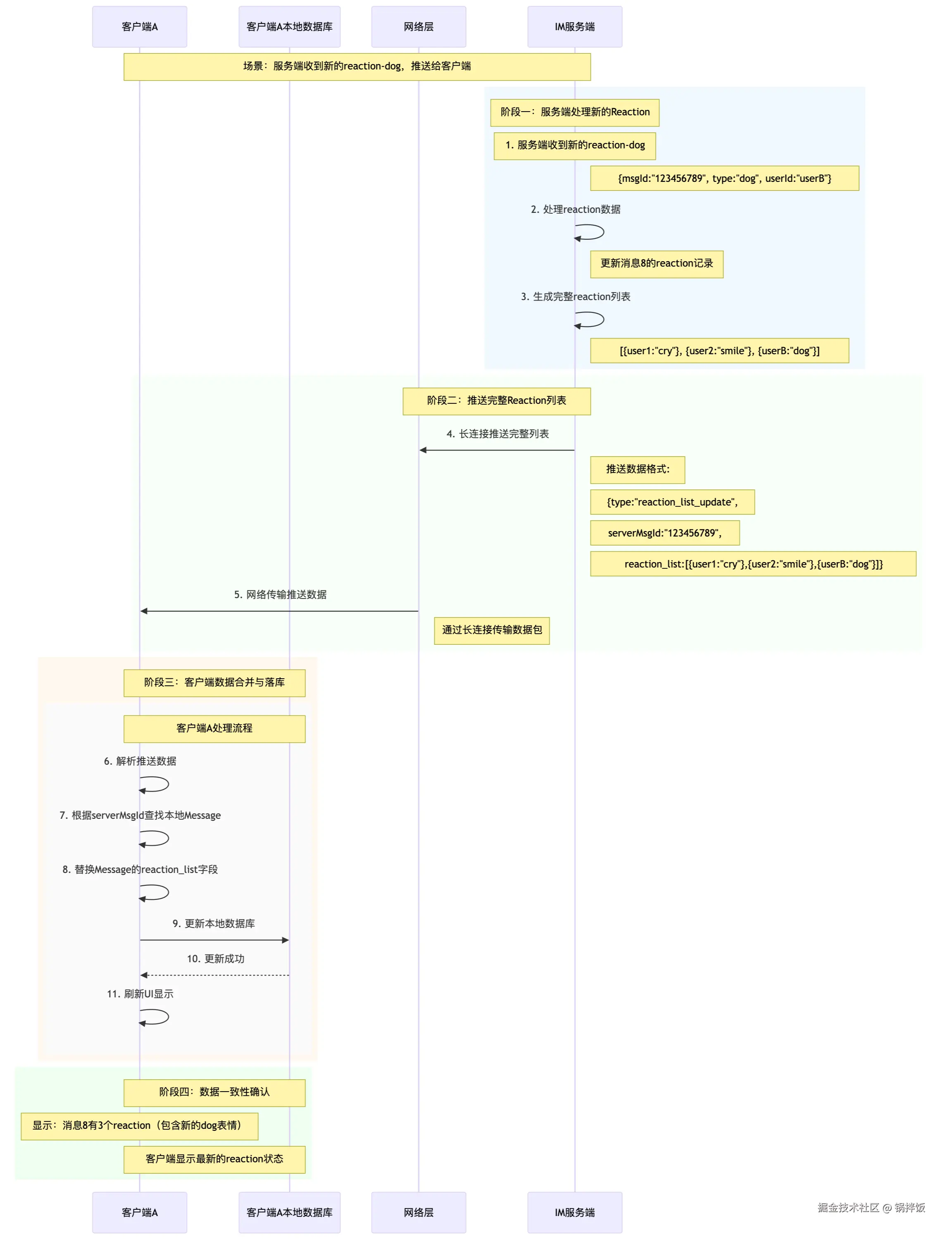
reaction列表的"推"
之前说过,根据数据量的大小,某些数据可以直接通过长连接,从服务端推送到客户端。即服务端直接转发机制
这里以消息Reaction列表为例,reaction列表作为消息的一个附加属性,业务也相对独立,在服务端也是单独数据库存储的。他不会通过消息推送直接带下来,一般会设计为单独的拉取接口与推送接口。
这里需要注意,如果是服务端直接转发机制,推送的时候一般需要将全量数据推送给客户端。

当有人对上图中的消息8进行reaction操作时,服务端会把消息8的所有reaction列表直接推送给客户端。大概数据如下,表示某个消息的最新reaction列表。
json
{
"serverMsgId": "123456789",
"reaction_list": [
{
"user1": "cry"
},
{
"user2": "smile"
}
]
}当用户收到上述数据后,需要把该reaction列表与本地的Message合并,并落库。最终才会展示给用户。
reaction列表的"拉"
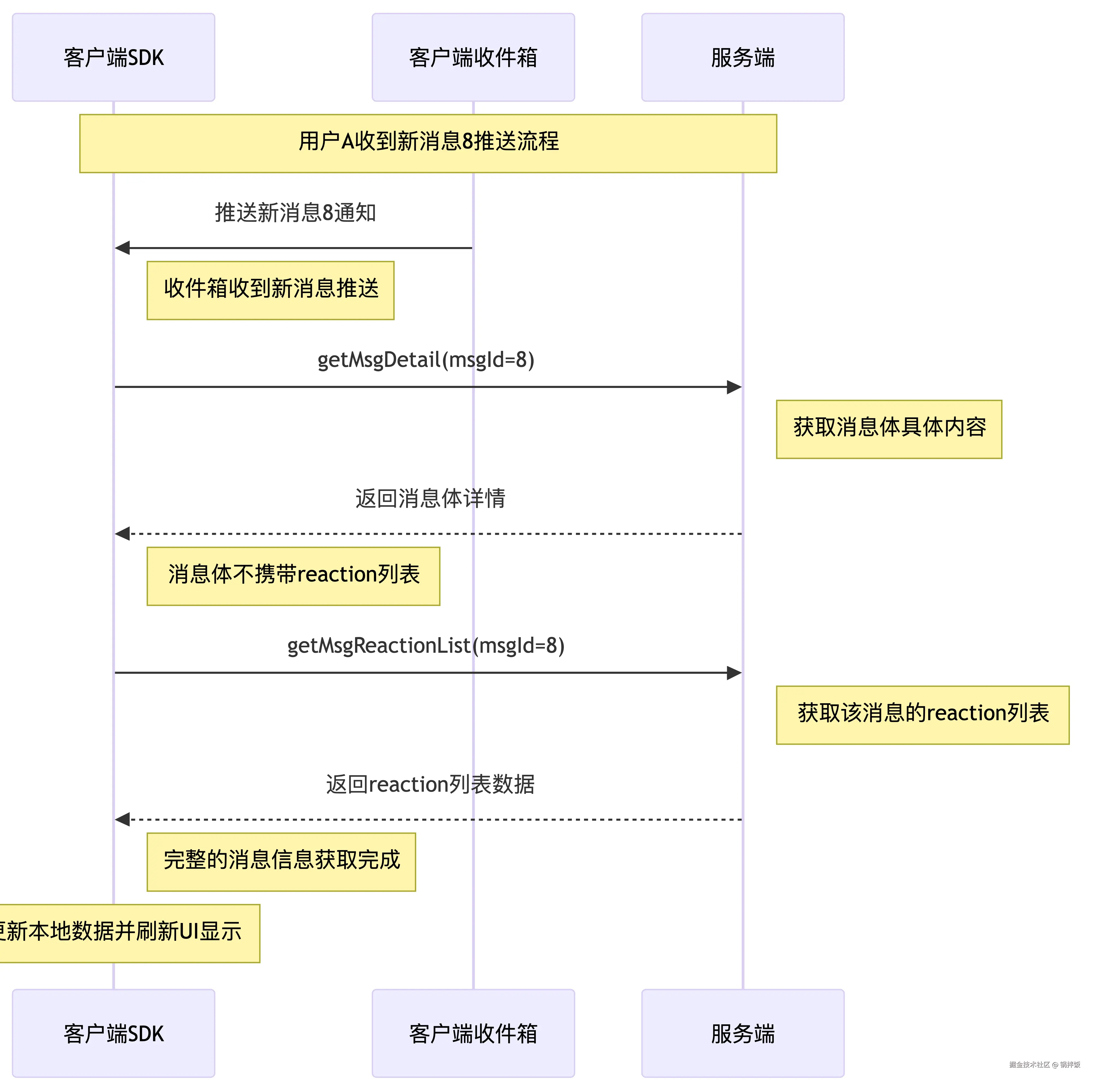
常见的拉的场景是用户在会话A页面,断网重连后,为了让用户尽快看到消息8的Reaction最新列表,会主动通过发请求getMsgReaction()获取。
还有一个场景,当客户端收件箱,收到新消息推送后,首先会调用服务端的getMsgDetail()接口,获取消息体具体内容。此时返回的消息体不携带reaction列表。
然后SDK会调用服务端的getMsgReactionList()接口,获取服务端的reaction列表。
推与拉的冲突
在某些情况下,可能会推拉的冲突。
以reaction列表为例,当服务端主动推送reaction列表,客户端又触发了getMsgReactionList接口。
这样的例子有很多,冷启动/断网重连等情况后,客户端为了快速获取/展示数据,都会主动拉取最新数据,如会话列表/消息列表等数据,然后快速展示。此时就会发生推与拉的冲突。
步骤一: 服务端数据库中,消息8的reaction列表是:`user1: cry`, `user2: smile`
- 客户端发起
getMsgReactionList()接口,请求获取服务端的reaction列表。 - 服务端查询数据库,并准备好数据,将`user1: cry`, `user2: smile`返回给客户端
SDK。由于网络原因,这个数据还在传输中。 - 此时服务端收到新的
reaction-dog后,服务端数据落库。
步骤二: 此时服务端数据库中,消息8的reaction列表是:`user1: cry`, `user2: smile`, `userB: dog`
- 将最新
reaction列表通过长连接,推送给用户A 的收件箱。数据内容:`user1: cry`, `user2: smile`, `userB: dog` - 客户端收到了消息8的
reaction列表,去数据库中查询该消息体,并进行数据合并。SDK回包success给服务端。 - 此时客户端本地数据,消息8的
reaction列表更新为:`user1: cry`, `user2: smile`, `userB: dog`
步骤三: getMsgReactionList()接口结果来到客户端
- 此时
短连接请求完成,reaction列表给到了客户端 - 客户端更新数据库,此时消息8的
reaction列表更新为:`user1: cry`, `user2: smile`
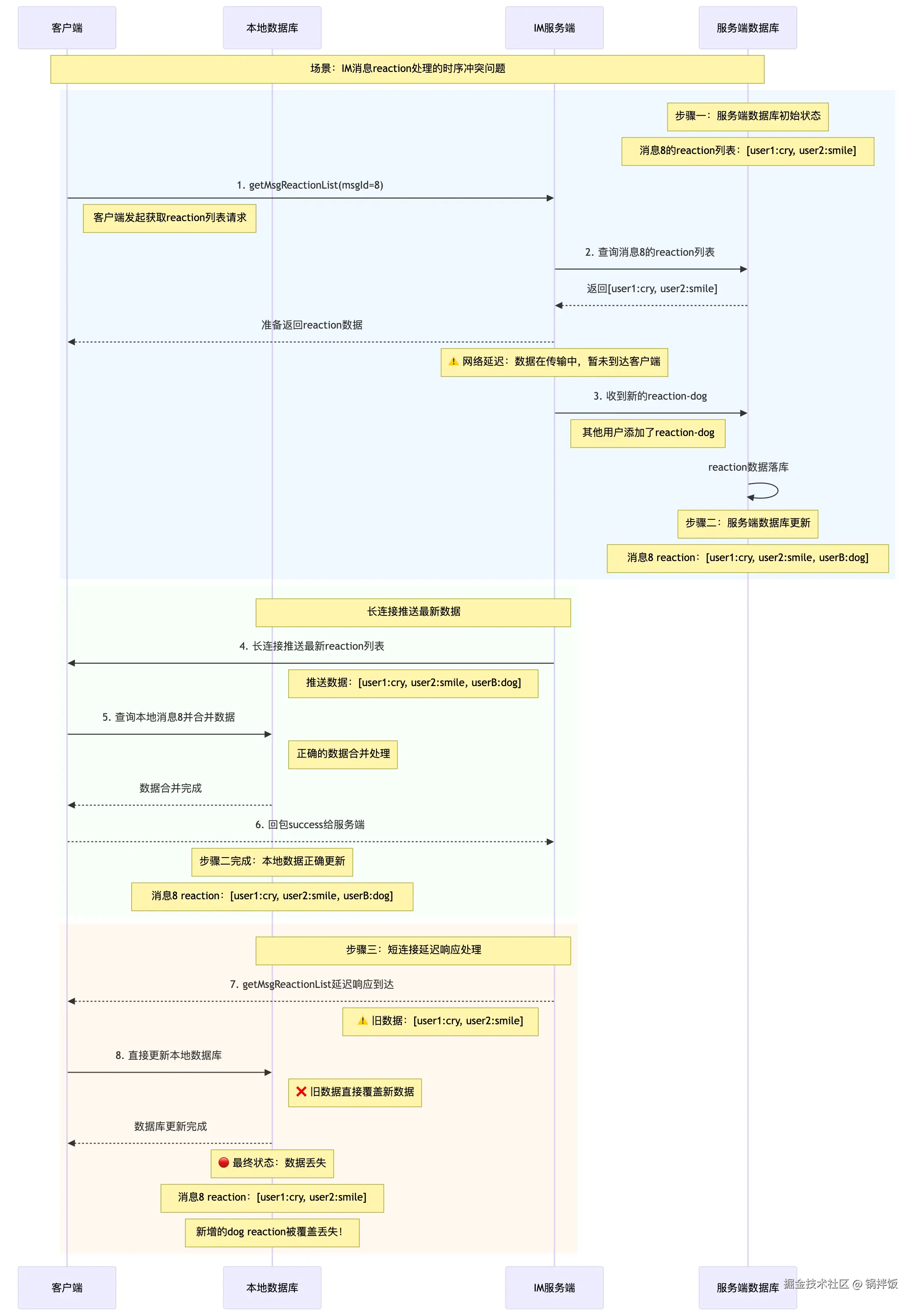
上面整个过程,描述的是由于弱网,导致服务端推送的新数据先落库,SDK拉取的旧数据后落库,导致数据不一致的问题。
其实在实际开发过程中,网络只是其中一个原因,多线程也是一个更大的原因。
在步骤一的第4步中,即使不是弱网,此时数据已经来到了客户端SDK,但是由于线程资源分配+数据处理,此时数据还在处理中,没有完成落库。而推送的新数据先处理完成,先落库了。也导致了数据不一致问题。
冲突场景
| ** | 获取到的是 新数据 user1: cry, user2: smile, userB: dog | 获取到的是 老数据 user1: cry, user2: smile |
|---|---|---|
| 推送的是 新数据 user1: cry, user2: smile, userB: dog | 没问题 | 情况一:获取先到,推送后到--->没问题 情况二:推送先到,获取后到--->有问题 |
| 推送的是 老数据 user1: cry, user2: smile | 情况一:获取先到,推送后到--->有问题 情况二:推送先到,获取后到--->没问题 | 没问题 |
从上面的表格可以看出,有问题的情况,都是老数据比新数据晚到,最终老数据覆盖新数据,导致数据异常。
推与拉的架构设计
在上面的例子中,我们假设了一种场景,就是有些数据量很小的信息,服务端可以直接通过长连接推送下来。但因为同时存在客户端主动拉取的场景,导致了数据不一致问题。
那么为了解决上述数据不一致问题,通常会有这么几种做法。
方案一:推送事件,而不是数据
这种方案,就是与收件箱机制一样,无论数据量大小,服务端给客户端都推送的是事件,真正的数据由客户端控制拉取。
以reaction列表为例,当服务端收到新的reaction后,应当向客户端推送一个reaction列表变更事件。客户端每次主动拉取全量的reaction列表。拉取时机由客户端决定。
这种方式不太推荐,因为会造成资源的浪费,对于简单的数据,应当保持推拉结合。而且即使是没有推送事件,客户端只使用主动拉取,当主动调用getMsgReactionList()接口,不同的getMsgReactionList()接口请求也需要保序,处理数据一致性问题。
方案二:客户端单线程保序
对于某个具体的业务,比如reaction业务,应当使用单线程保序。即reaction列表的被动推送与主动获取的逻辑,都应该放在一个线程中排序处理。
单线程的实现
这里以Android平台为例,解释单线程保序的实现。
单线程保序,其实本质上是一个线程池,这个线程池的核心线程只有一个、无非核心线程,同时等待队列无穷大。线程池就是按照入队顺序,一个一个执行任务。
kotlin
val singleThreadPool = ThreadPoolExecutor(
1,
0,
60L,
TimeUnit.SECONDS,
LinkedBlockingQueue()
)
// 允许超时回收核心线程
singleThreadPool.allowCoreThreadTimneOut(true)在kotlin协程中,有个更优雅的方式,可以复用线程池能力,即单协程保序。
假设我们有个自定义的线程池,核心数10,非核心数0,等待队列无限大。
kotlin
val multiThreadPool = ThreadPoolExecutor(
10,
0,
60L,
TimeUnit.SECONDS,
LinkedBlockingQueue()
)
multiThreadPool.allowCoreThreadTimeOut(true)这里可以使用limitedParallelism方法,将一个线程池分割为不同的协程作用域。
kotlin
val reactionScope = multiThreadPool.asCoroutineDispatcher().limitedParallelism(1)
reactionScope.launch {
runBlocking {
}
}reactionScope就是一个单协程保序作用域,即使在不同场景、不同线程向reactionScope提交任务,因为runBlocking的存在,都会严格按照提交时的顺序执行。
单协程保序的好处是可以复用线程池,不用每个业务都写一个自己的单线程的线程池,有利于线程池治理。
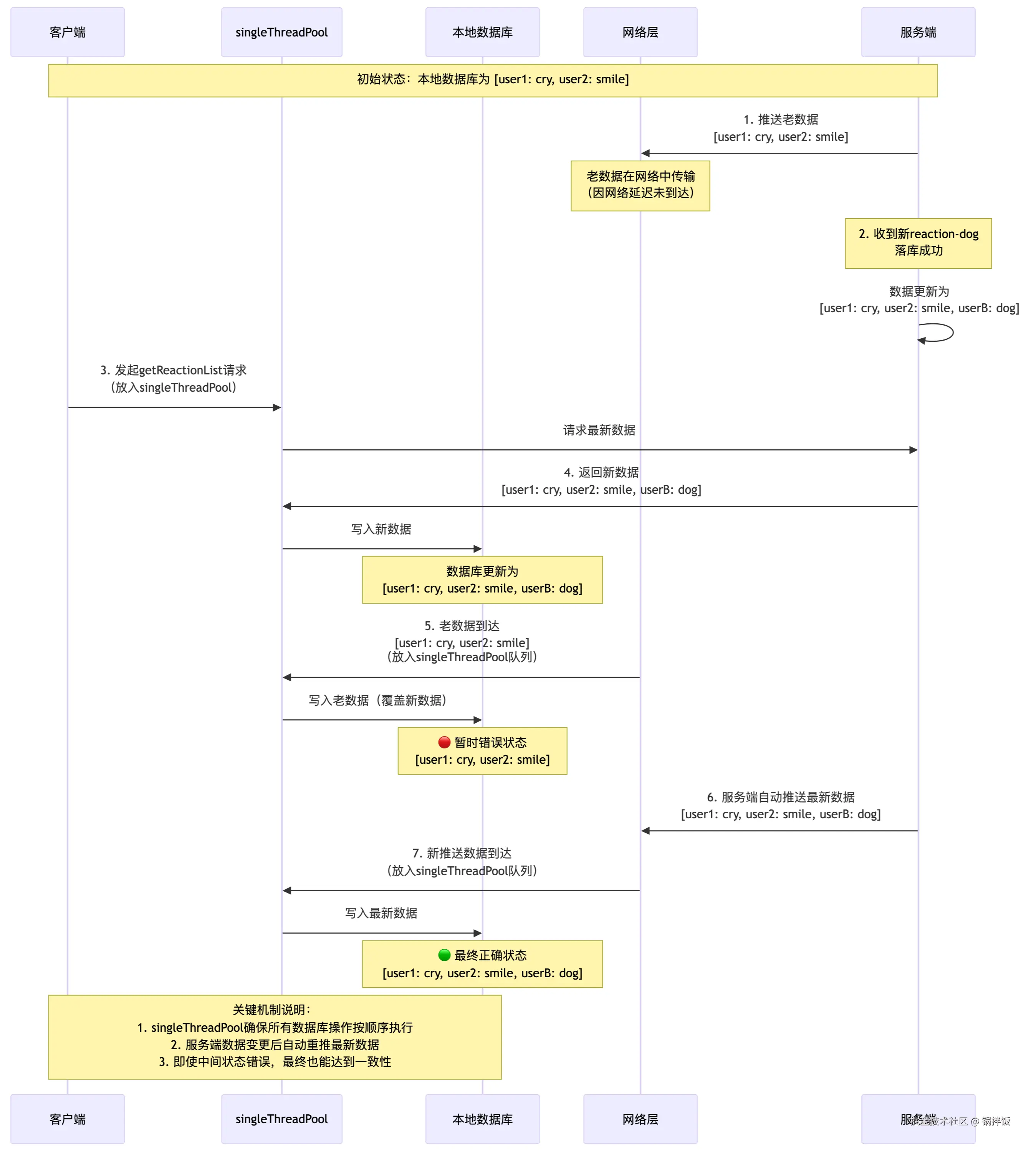
下面解释单线程为什么能够保序。
正常情况
当客户端发起getMsgReactionList请求,该任务被提交到reactionScope执行。服务端接口返回reaction列表`user1: cry`, `user2: smile`,网络畅通,客户端写入本地数据库。
然后服务端推送了新的reaction列表`user1: cry`, `user2: smile`, `userB: dog`,客户端放到reactionScope处理,客户端写入本地数据库。
最终,客户端的本地数据库中,reaction`user1: cry`, `user2: smile`, `userB: dog`,符合预期。
异常情况1:获取老数据+推送新数据
- 获取的是 老数据`user1: cry`, `user2: smile`
- 推送的是 新数据`user1: cry`, `user2: smile`, `userB: dog`
- 推送老数据先到,获取新数据后到
具体流程:
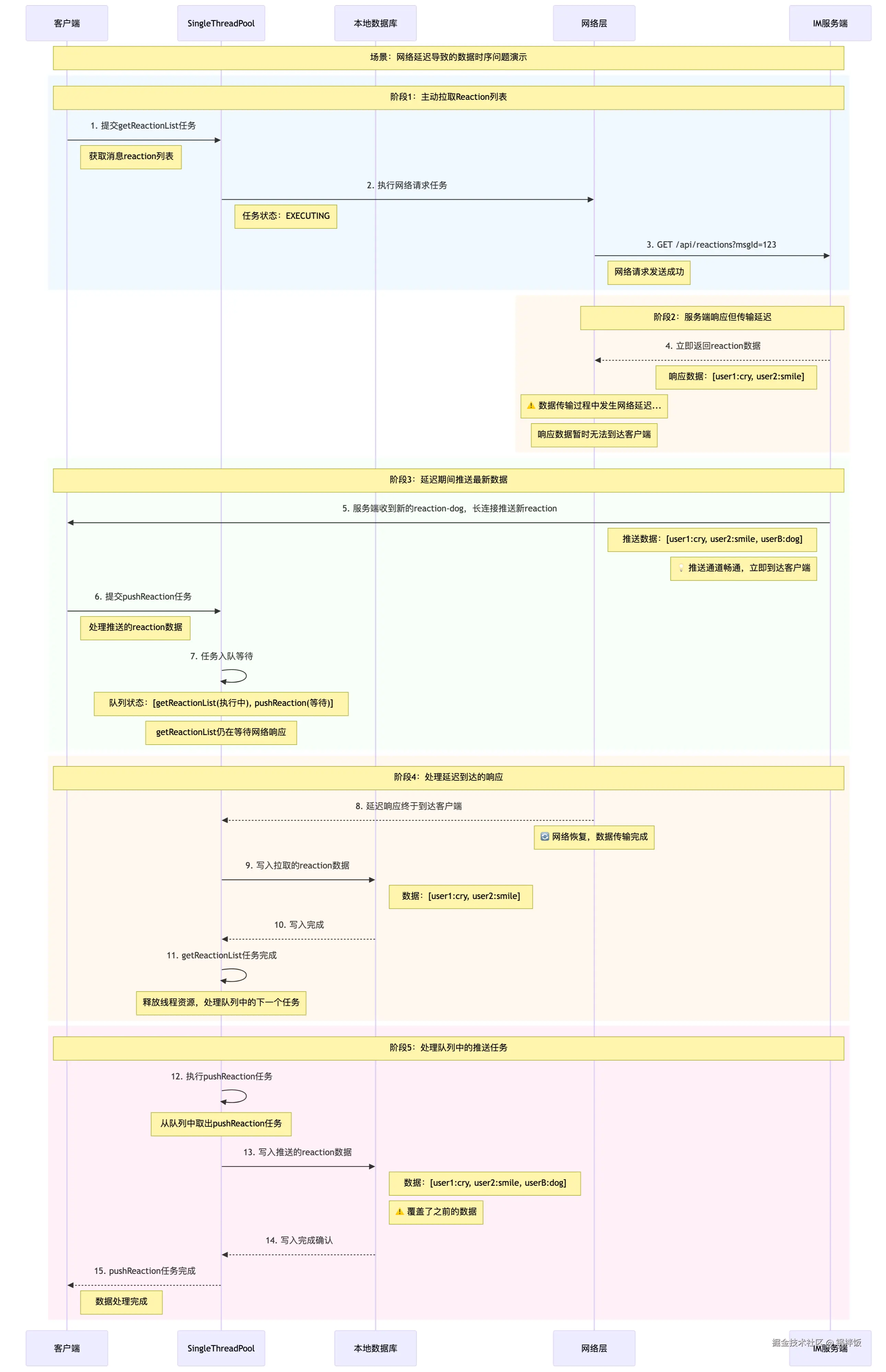
- 当客户端发起
getMsgReactionList请求,该任务被放置到singleThreadPool执行。getMsgReactionList任务包含获取服务端数据、将数据写入本地数据库两个动作。 - 服务端
getMsgReactionList接口返回列表`user1: cry`, `user2: smile`,网络不畅,还未到达客户端。 - 此时服务端推送了新的
reaction列表`user1: cry`, `user2: smile`, `userB: dog`,客户端放到singleThreadPool处理,我们把这个任务叫做pushReaction。pushReaction任务包含写入本地数据库这个动作。 - 由于
getMsgReactionList这个任务还没有完成,所以singleThreadPool没有空闲线程处理,pushReaction任务被存入到线程池的阻塞队列中。 - 当网络畅通后,
getMsgReactionList请求返回`user1: cry`, `user2: smile`,并写入本地数据库。 getMsgReactionList执行完成,释放线程资源。- 阻塞队列中的
pushReaction排队执行,将`user1: cry`, `user2: smile`, `userB: dog`写入本地数据库。
最终本地数据库的数据一致可信。
异常情况2:推送老数据+获取新数据
- 推送的是 老数据`user1: cry`, `user2: smile`
- 获取的是 新数据`user1: cry`, `user2: smile`, `userB: dog`
- 获取新数据先到,推送老数据后到
- 服务端推送了老数据`user1: cry`, `user2: smile`给客户端,由于网络原因,该推送还在网络层中。
- 然后服务端收到了新
reaction-dog,落库成功。 - 客户端发起
getMsgReactionList请求到服务端,getMsgReactionList任务先被放入singleThreadPool, - 服务端返回新数据`user1: cry`, `user2: smile`, `userB: dog`,客户端将该数据写入本地数据库。
- 网络层的老数据`user1: cry`, `user2: smile`随后到来,被放到
singleThreadPool中,客户端将`user1: cry`, `user2: smile`写入本地数据库
到这里,有人可能会有疑惑,虽然有单线程保序,最终本地数据库不还是错误的数据吗?
其实我们忽略了一点,就是第2步,当服务端收到新reaction-dog,落库成功后,还会向客户端推送最新的reaction列表,即新数据`user1: cry`, `user2: smile`, `userB: dog`。
让我们继续上面的流程。
- 服务端推送新数据`user1: cry`, `user2: smile`, `userB: dog`给客户端。
- 经过网络层,到达客户端的
singleThreadPool,对数据处理后落库。 - 最终本地数据库的值为:`user1: cry`, `user2: smile`, `userB: dog`
这样,也就完成了单线程保序的逻辑。
方案三:版本号
版本号可以避免技术 上的复杂设计,在业务 上实现数据一致性。
版本号,即服务端在数据落库时,给数据增加一个递增的版本号。这样无论客户端是否因为网络、时序问题,导致新数据先到、旧数据后到,客户端都可以直接读取版本号,对比本地版本号后,决定是否落库。
以reaction列表为例,推送和主动获取的数据格式会变成下面这样:
json
{
"`serverMsgId`": "123456789",
"`version`": "11",
"`reaction_list`": [
{
"`user1`": "cry"
},
{
"`user2`": "smile"
}
]
}
json
{
"`serverMsgId`": "123456789",
"`version`": "12",
"`reaction_list`": [
{
"`user1`": "cry"
},
{
"`user2`": "smile"
},
{
"`userA`": "dog"
}
]
}那么无论是推与拉之间、还是拉与拉之间,只要有版本号,就可以在最终数据处理的时候,决定保留哪个数据。
总结
数据一致性问题不只存在推拉架构中,在传统的只有HTTP短连接请求的情况下,对于同一接口,比如需要写到本地的用户配置,不同场景触发了多次接口请求,这多次接口请求之间也存在数据一致性问题。
对于推拉的架构设计,技术上的单线程保序方案,业务上的版本号方案,分别对应了道与术。都能解决问题,具体应当结合项目实际情况决定。