目录
[一. 读取](#一. 读取)
[二. 搜索](#二. 搜索)
[三. 修改](#三. 修改)
[四. 排序](#四. 排序)
大家可以去官网看看:list --- CMake 4.1.1 Documentation
list
对分号分隔的列表进行操作。
概要
读取
list(LENGTH <列表> <输出变量>)
list(GET <列表> <元素索引> [<索引> ...] <输出变量>)
list(JOIN <列表> <连接符> <输出变量>)
list(SUBLIST <列表> <起始位置> <长度> <输出变量>)
搜索
list(FIND <列表> <值> <输出变量>)
修改
list(APPEND <列表> [<元素>...])
list(FILTER <列表> {INCLUDE | EXCLUDE} REGEX <正则表达式>)
list(INSERT <列表> <索引> [<元素>...])
list(POP_BACK <列表> [<输出变量>...])
list(POP_FRONT <列表> [<输出变量>...])
list(PREPEND <列表> [<元素>...])
list(REMOVE_ITEM <列表> <值>...)
list(REMOVE_AT <列表> <索引>...)
list(REMOVE_DUPLICATES <列表>)
list(TRANSFORM <列表> <动作> [...])
排序
list(REVERSE <列表>)
list(SORT <列表> [...])
简介
列表子命令 APPEND, INSERT, FILTER, PREPEND, POP_BACK, POP_FRONT, REMOVE_AT, REMOVE_ITEM, REMOVE_DUPLICATES, REVERSE 和 SORT 可能会在当前 CMake 变量作用域内为列表创建新值。与 set() 命令类似,即使列表本身实际上是在父作用域中定义的,list 命令也会在当前作用域中创建新的变量值。要将这些操作的结果向上传播,请使用带 PARENT_SCOPE 的 set()、带 CACHE INTERNAL 的 set() 或其他值传播方法。
注意:CMake 中的列表是一个由分号分隔的字符串组。可以使用 set() 命令创建列表。例如,set(var a b c d e) 创建一个包含 a;b;c;d;e 的列表,而 set(var "a b c d e") 创建一个字符串或一个只包含一个项的列表。(请注意,宏参数不是变量,因此不能在 LIST 命令中使用。)
单个元素不能包含不等数量的 [ 和 ] 字符,并且不能以反斜杠 (\) 结尾。有关详细信息,请参阅分号分隔的列表。
注意:指定索引值时,如果 <元素索引> 是 0 或更大,则从列表的开头开始索引,0 表示第一个列表元素。如果 <元素索引> 是 -1 或更小,则从列表的末尾开始索引,-1 表示最后一个列表元素。使用负索引计数时要小心:它们不是从 0 开始的。-0 等价于 0,即第一个列表元素。
一. 读取
list(LENGTH <列表> <输出变量>)
返回列表的长度。
list(GET <列表> <元素索引> [<元素索引> ...] <输出变量>)
返回列表中指定索引的元素(列表)。
list(JOIN <列表> <连接符> <输出变量>)
(版本 3.12 新增)
返回一个字符串,该字符串使用连接符字符串连接列表的所有元素。要连接多个不属于列表的字符串,请使用 string(JOIN)。
list(SUBLIST <列表> <起始位置> <长度> <输出变量>)
(版本 3.12 新增)
返回给定列表的一个子列表。如果 <长度> 为 0,将返回一个空列表。如果 <长度> 为 -1 或者列表小于 <起始位置>+<长度>,则返回从 <起始位置> 开始的列表剩余元素。
话不多说,我们来细讲
list(LENGTH <list> <output_variable>)
功能 :获取列表的长度(即列表中元素的数量)。
参数:
-
<list>:需要计算长度的列表变量名。 -
<output_variable>:用于存储计算出的长度结果的变量名。这个结果是一个整数。
例子:
bash
set(MyList apple banana orange)
list(LENGTH MyList ListLength)
message("列表 MyList 的长度是: ${ListLength}")输出:
bash
列表 MyList 的长度是: 3解释 :列表 MyList 包含 apple, banana, orange 三个元素,所以长度为 3。
list(GET <list> <index> [<index> ...] <output_variable>)
功能 :从列表中获取一个或多个指定索引处的元素,并将结果以列表形式返回。
参数:
-
<list>:源列表变量名。 -
<index>:要获取的元素的索引。索引从 0 开始(0 是第一个元素),负数表示从列表末尾开始计数(-1 是最后一个元素)。 -
<output_variable>:用于存储获取到的元素的新列表的变量名。
例子 1:获取单个元素
bash
set(MyList apple banana orange)
list(GET MyList 1 SecondItem) # 获取索引为 1(第二个)的元素
message("第二个水果是: ${SecondItem}")输出:
bash
第二个水果是: banana例子 2:获取多个元素(形成新列表)
bash
set(MyList a b c d e f)
list(GET MyList 1 3 5 NewList) # 获取索引为 1, 3, 5 的元素
message("新列表是: ${NewList}")输出:
bash
新列表是: b;d;f解释 :NewList 现在是一个包含 b, d, f 三个元素的新列表。
例子 3:使用负索引
bash
set(MyList a b c d e f)
list(GET MyList -1 LastItem) # 获取最后一个元素
list(GET MyList -2 SecondLastItem) # 获取倒数第二个元素
message("最后一个元素: ${LastItem}, 倒数第二个: ${SecondLastItem}")输出:
bash
最后一个元素: f, 倒数第二个: e
list(JOIN <list> <glue> <output_variable>)
功能 :将列表中的所有元素用一个指定的连接符(glue) 拼接成一个单一的字符串。
参数:
-
<list>:源列表变量名。 -
<glue>:用于连接各个元素的字符串。 -
<output_variable>:用于存储最终拼接成的字符串的变量名。
例子 1:用空格连接
bash
set(MyList Hello World How Are You)
list(JOIN MyList " " ResultString)
message("拼接结果: '${ResultString}'")输出:
bash
拼接结果: 'Hello World How Are You'例子 2:用特殊字符连接
bash
set(PathList usr local bin)
list(JOIN PathList "/" UnixPath) # 类似路径拼接
message("路径是: ${UnixPath}")输出:
bash
路径是: usr/local/bin
list(SUBLIST <list> <begin> <length> <output_variable>)
功能 :获取列表的一个子列表(切片)。
参数:
-
<list>:源列表变量名。 -
<begin>:子列表的起始索引(从 0 开始)。也支持负索引,表示从末尾开始计算。 -
<length>:要提取的子列表的长度。-
如果
<length>为0,结果是一个空列表。 -
如果
<length>为-1,或者起始索引 + 长度超过了列表末尾,则会提取从起始索引开始到列表末尾的所有剩余元素。
-
-
<output_variable>:用于存储提取出的子列表的变量名。
例子 1:基本用法
bash
set(MyList a b c d e f g)
list(SUBLIST MyList 2 3 SubList) # 从索引2开始,取3个元素 (c, d, e)
message("子列表是: ${SubList}")输出:
bash
子列表是: c;d;e例子 2:使用负索引作为起始位置
bash
set(MyList a b c d e f g)
list(SUBLIST MyList -3 2 SubList) # 从倒数第3个(e)开始,取2个元素 (e, f)
message("子列表是: ${SubList}")输出:
bash
子列表是: e;f注意 :这里起始索引 -3 指向的是第 5 个元素 e (a(0), b(1), c(2), d(3), e(4), f(5), g(6))。
例子 3:长度参数为 -1
bash
set(MyList a b c d e f g)
list(SUBLIST MyList 3 -1 SubList) # 从索引3(d)开始,取到末尾的所有元素
message("子列表是: ${SubList}")输出:
bash
子列表是: d;e;f;g例子 4:长度参数为 0
bash
set(MyList a b c d e f g)
list(SUBLIST MyList 3 0 SubList) # 从索引3开始,取0个元素 -> 空列表
message("子列表是: '${SubList}' (长度: ${SubList})")输出:
bash
子列表是: '' (长度: 0)例子 5:请求的长度超出列表范围
bash
set(MyList a b c d)
list(SUBLIST MyList 2 10 SubList) # 从索引2(c)开始,请求10个元素,但后面只有d了
message("子列表是: ${SubList}") # 所以只返回 c 和 d输出:
bash
子列表是: c;d示例
📂 项目目录结构
bash
demo/
└── CMakeLists.txt🔹 demo/CMakeLists.txt
bash
cmake_minimum_required(VERSION 3.20)
project(ListDemo)
set(my_list apple banana cherry date elderberry)
# 1. LENGTH
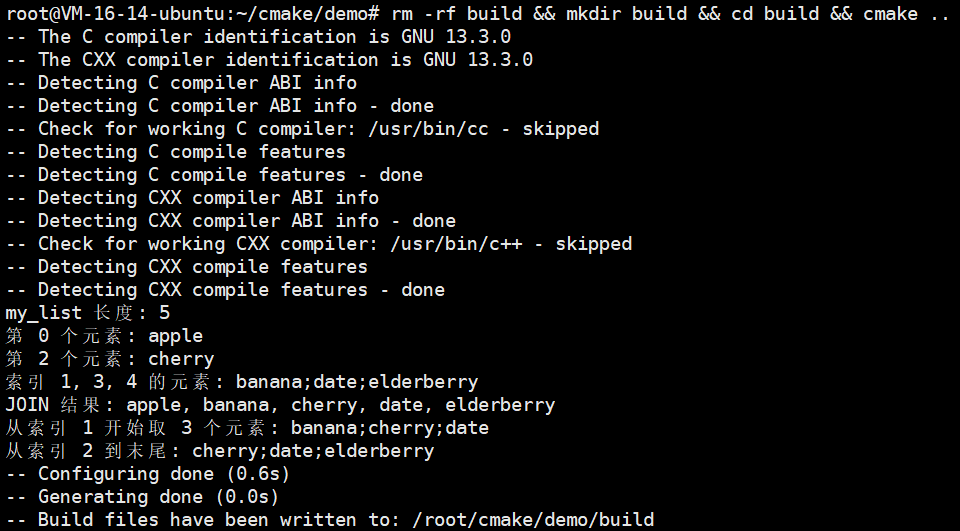
list(LENGTH my_list list_len)
message("my_list 长度: ${list_len}")
# 2. GET (单个索引)
list(GET my_list 0 first_elem)
list(GET my_list 2 third_elem)
message("第 0 个元素: ${first_elem}")
message("第 2 个元素: ${third_elem}")
# 2. GET (多个索引)
list(GET my_list 1 3 4 some_elems)
message("索引 1, 3, 4 的元素: ${some_elems}")
# 3. JOIN
list(JOIN my_list ", " joined_str)
message("JOIN 结果: ${joined_str}")
# 4. SUBLIST
list(SUBLIST my_list 1 3 sub_list)
message("从索引 1 开始取 3 个元素: ${sub_list}")
list(SUBLIST my_list 2 -1 sub_list_to_end)
message("从索引 2 到末尾: ${sub_list_to_end}")接下来我们就来搭建我们的项目
bash
rm -rf build && mkdir build && cd build && cmake ..运行结果
二. 搜索
list(FIND <列表> <值> <输出变量>)
返回指定元素在列表中的索引,如果未找到则返回 -1。
示例1
📂 项目目录结构
bash
demo/
└── CMakeLists.txt🔹 demo/CMakeLists.txt
bash
cmake_minimum_required(VERSION 3.20)
project(ListFindDemo)
set(my_list apple banana cherry date elderberry)
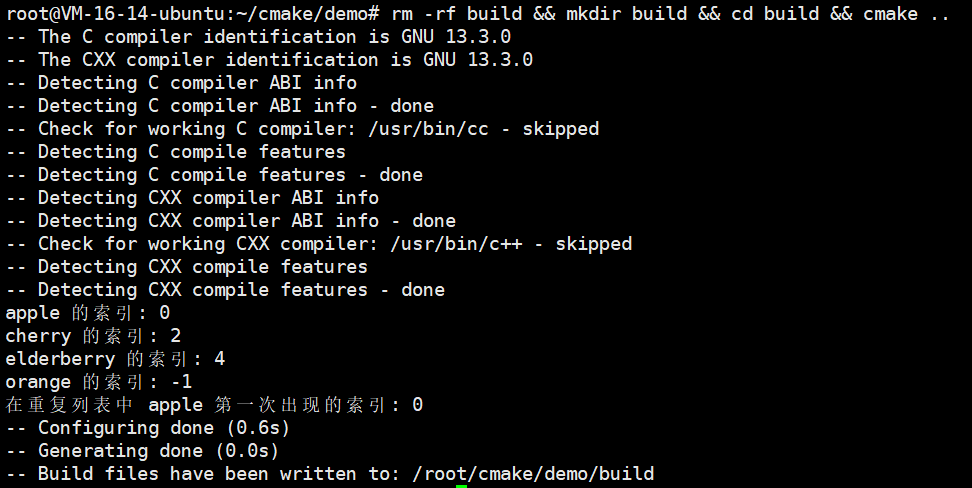
# 1. 找到元素(apple 在索引 0)
list(FIND my_list apple idx_apple)
message("apple 的索引: ${idx_apple}")
# 2. 找到元素(cherry 在索引 2)
list(FIND my_list cherry idx_cherry)
message("cherry 的索引: ${idx_cherry}")
# 3. 找到元素(elderberry 在索引 4)
list(FIND my_list elderberry idx_elderberry)
message("elderberry 的索引: ${idx_elderberry}")
# 4. 找不到元素(orange 不在列表中,返回 -1)
list(FIND my_list orange idx_orange)
message("orange 的索引: ${idx_orange}")
# 5. 如果有重复元素,只返回第一个位置
set(my_list_dup apple banana apple cherry)
list(FIND my_list_dup apple idx_first_apple)
message("在重复列表中 apple 第一次出现的索引: ${idx_first_apple}")接下来我们就来搭建我们的项目
bash
rm -rf build && mkdir build && cd build && cmake ..运行结果
三. 修改
list(APPEND <列表> [<元素> ...])
将元素追加到列表。如果当前作用域中不存在名为 <列表> 的变量,则其值被视为空,元素将被追加到该空列表。
list(FILTER <列表> <INCLUDE|EXCLUDE> REGEX <正则表达式>)
(版本 3.6 新增)
根据模式(INCLUDE 或 EXCLUDE)包含或移除列表中匹配正则表达式的项。在 REGEX 模式下,项将与给定的正则表达式进行匹配。
有关正则表达式的更多信息,请参阅 string(REGEX)。
list(INSERT <列表> <元素索引> <元素> [<元素> ...])
将元素插入到列表的指定索引处。指定超出范围的索引是错误的。有效的索引范围是 0 到 N(N 是列表的长度),包括 0 和 N。空列表的长度为 0。如果当前作用域中不存在名为 <列表> 的变量,则其值被视为空,元素将被插入到该空列表中。
list(POP_BACK <列表> [<输出变量>...])
(版本 3.15 新增)
如果未给出变量名,则恰好移除一个元素。否则,如果提供了 N 个变量名,则将最后 N 个元素的值赋给给定的变量,然后从 <列表> 中移除最后 N 个值。
list(POP_FRONT <列表> [<输出变量>...])
(版本 3.15 新增)
如果未给出变量名,则恰好移除一个元素。否则,如果提供了 N 个变量名,则将前 N 个元素的值赋给给定的变量,然后从 <列表> 中移除前 N 个值。
list(PREPEND <列表> [<元素> ...])
(版本 3.15 新增)
将元素插入到列表的第 0 个位置。如果当前作用域中不存在名为 <列表> 的变量,则其值被视为空,元素将被预置到该空列表中。
list(REMOVE_ITEM <列表> <值> [<值> ...])
从列表中移除所有给定的项(所有匹配的值)。
list(REMOVE_AT <列表> <索引> [<索引> ...])
从列表中移除指定索引处的项。
list(REMOVE_DUPLICATES <列表>)
移除列表中的重复项。项的相对顺序被保留,但如果遇到重复项,则只保留第一个实例。
list(TRANSFORM <列表> <动作> [<选择器>] [OUTPUT_VARIABLE <输出变量>])
(版本 3.12 新增)
通过对列表的所有元素或者通过指定 <选择器> 对选定的元素应用 <动作> 来转换列表,将结果就地存储或存储在指定的输出变量中。
注意:TRANSFORM 子命令不会改变列表中元素的数量。如果指定了 <选择器>,则只有部分元素会被更改,其他元素将保持转换前的状态。
<动作> 指定应用于列表元素的操作。这些操作与 string() 命令的子命令具有完全相同的语义。<动作> 必须是以下之一:
APPEND, PREPEND
将指定值追加或预置到列表的每个元素。
list(TRANSFORM <列表> (APPEND|PREPEND) <值> ...)
TOLOWER, TOUPPER
将列表的每个元素转换为小写或大写字符。
list(TRANSFORM <列表> (TOLOWER|TOUPPER) ...)
STRIP
移除列表每个元素的首尾空格。
list(TRANSFORM <列表> STRIP ...)
GENEX_STRIP
从列表的每个元素中剥离任何生成器表达式。
list(TRANSFORM <列表> GENEX_STRIP ...)
REPLACE
尽可能多地匹配正则表达式,并为列表的每个元素将匹配项替换为替换表达式(与 string(REGEX REPLACE) 语义相同)。
list(TRANSFORM <列表> REPLACE <正则表达式> <替换表达式> ...)
(版本 4.1 变更:^ 锚点现在只匹配输入元素的开头,而不是每次重复搜索的开头。参见策略 CMP0186。)
<选择器> 决定将转换列表中的哪些元素。一次只能指定一种类型的选择器。如果给出,<选择器> 必须是以下之一:
AT
指定一个索引列表。
list(TRANSFORM <列表> <动作> AT <索引> [<索引> ...] ...)
FOR
指定一个范围,并可选择指定一个用于遍历该范围的增量。
list(TRANSFORM <列表> <动作> FOR <起始> <结束> [<步进>] ...)
REGEX
指定一个正则表达式。只有匹配正则表达式的元素才会被转换。
list(TRANSFORM <列表> <动作> REGEX <正则表达式> ...)
四. 排序
list(REVERSE <列表>)
就地反转列表的内容。
list(SORT <列表> [COMPARE <比较方式>] [CASE <大小写敏感度>] [ORDER <排序顺序>])
按字母顺序对列表进行就地排序。
(版本 3.13 新增:增加了 COMPARE, CASE, 和 ORDER 选项。)
(版本 3.18 新增:增加了 COMPARE NATURAL 选项。)
使用 COMPARE 关键字选择排序的比较方法。<比较方式> 选项应为以下之一:
STRING
按字母顺序对字符串列表进行排序。如果未给出 COMPARE 选项,这是默认行为。
FILE_BASENAME
按文件的基名对文件路径名列表进行排序。
NATURAL
使用自然顺序(参见 strverscmp(3) 手册)对字符串列表进行排序,即连续的数字作为整数进行比较。例如:使用 NATURAL 比较时,列表 10.0 1.1 2.1 8.0 2.0 3.1 将被排序为 1.1 2.0 2.1 3.1 8.0 10.0;而使用 STRING 比较时,它将被排序为 1.1 10.0 2.0 2.1 3.1 8.0。
使用 CASE 关键字选择区分大小写或不区分大小写的排序模式。<大小写敏感度> 选项应为以下之一:
SENSITIVE
以区分大小写的方式对列表项进行排序。如果未给出 CASE 选项,这是默认行为。
INSENSITIVE
以不区分大小写的方式对列表项进行排序。仅大小写不同的项的顺序未指定。
要控制排序顺序,可以给出 ORDER 关键字。<排序顺序> 选项应为以下之一:
ASCENDING
按升序对列表进行排序。如果未给出 ORDER 选项,这是默认行为。
DESCENDING
按降序对列表进行排序。
list(REVERSE <list>)
功能 :就地 反转列表中元素的顺序。这意味着它会直接修改原始列表变量。
参数:
<list>:需要被反转的列表变量名。
例子:
bash
set(MyList a b c d e)
message("原始列表: ${MyList}")
list(REVERSE MyList) # 就地反转,直接修改了 MyList
message("反转后的列表: ${MyList}")输出:
bash
原始列表: a;b;c;d;e
反转后的列表: e;d;c;b;a关键点:
-
REVERSE操作是 "就地 (in-place)" 的,它直接改变了MyList变量本身的值。 -
它不返回一个新列表,而是修改原始列表。
list(SORT <list> [options...])
功能 :就地对列表中的元素进行排序。它提供了多个选项来控制排序的行为。
核心选项:
a) COMPARE - 选择比较方法
-
STRING(默认): 标准的字母顺序(按字符的ASCII码排序)。bashset(MyList 10.0 1.1 2.1 8.0 2.0 3.1) list(SORT MyList COMPARE STRING) message("STRING 排序: ${MyList}") # 输出: STRING 排序: 1.1;10.0;2.0;2.1;3.1;8.0 # 解释: '1.1' 和 '10.0','1' 的ASCII码小于 '2',所以 '1.1' 和 '10.0' 都排在 '2.0' 前面。 -
NATURAL(CMake 3.18+): 自然顺序排序,数字部分会按数值大小进行比较。bashset(MyList 10.0 1.1 2.1 8.0 2.0 3.1) list(SORT MyList COMPARE NATURAL) message("NATURAL 排序: ${MyList}") # 输出: NATURAL 排序: 1.1;2.0;2.1;3.1;8.0;10.0 # 解释: 数字 1.1 < 2.0 < 2.1 < 3.1 < 8.0 < 10.0,符合数值大小的直觉。这是处理版本号或带数字文件名时非常有用的选项。
-
FILE_BASENAME: 按文件路径的基名(最后一部分) 进行排序。bashset(MyList "/usr/bin/zcat" "/etc/config" "/tmp/a_file.txt" "/home/user/.bashrc") list(SORT MyList COMPARE FILE_BASENAME) message("按基名排序: ${MyList}") # 输出: 按基名排序: /etc/config;/tmp/a_file.txt;/home/user/.bashrc;/usr/bin/zcat # 解释: 比较的是 'config', 'a_file.txt', '.bashrc', 'zcat'。
b) CASE - 选择大小写敏感度
-
SENSITIVE(默认): 区分大小写。大写字母排在小写字母之前(因为ASCII码中如此)。bashset(MyList Apple banana Orange Dog cat) list(SORT MyList COMPARE STRING CASE SENSITIVE) message("区分大小写排序: ${MyList}") # 输出: 区分大小写排序: Apple;Dog;Orange;banana;cat # 解释: 'A'(65), 'D'(68), 'O'(79) 的ASCII码都小于 'a'(97), 'c'(99),所以大写开头的单词排在前面。 -
INSENSITIVE: 不区分大小写。bashset(MyList Apple banana Orange Dog cat) list(SORT MyList COMPARE STRING CASE INSENSITIVE) message("不区分大小写排序: ${MyList}") # 输出: 不区分大小写排序: Apple;banana;cat;Dog;Orange # 解释: 排序时忽略大小写,相当于比较 'apple', 'banana', 'cat', 'dog', 'orange'。 # 注意: 'Dog' 和 'Orange' 的相对顺序可能因实现而异,但 'A/a', 'B/b' 等分组是正确的。
c) ORDER - 选择排序顺序
-
ASCENDING(默认): 升序排序(A-Z, 0-9)。bashset(MyList 5 3 9 1 4) list(SORT MyList COMPARE STRING ORDER ASCENDING) # COMPARE STRING 可省略 message("升序排序: ${MyList}") # 输出: 升序排序: 1;3;4;5;9 -
DESCENDING: 降序排序(Z-A, 9-0)。bashset(MyList 5 3 9 1 4) list(SORT MyList ORDER DESCENDING) # COMPARE STRING 是默认值,可省略 message("降序排序: ${MyList}") # 输出: 降序排序: 9;5;4;3;1
示例
📂 项目目录结构
bash
demo/
└── CMakeLists.txt🔹 demo/CMakeLists.txt
bash
cmake_minimum_required(VERSION 3.18)
project(ListSortDemo)
# 示例列表
set(VERSIONS 10.0 1.1 2.1 8.0 2.0 3.1)
set(FILES /path/to/C.txt /path/to/a.txt /path/to/B.txt)
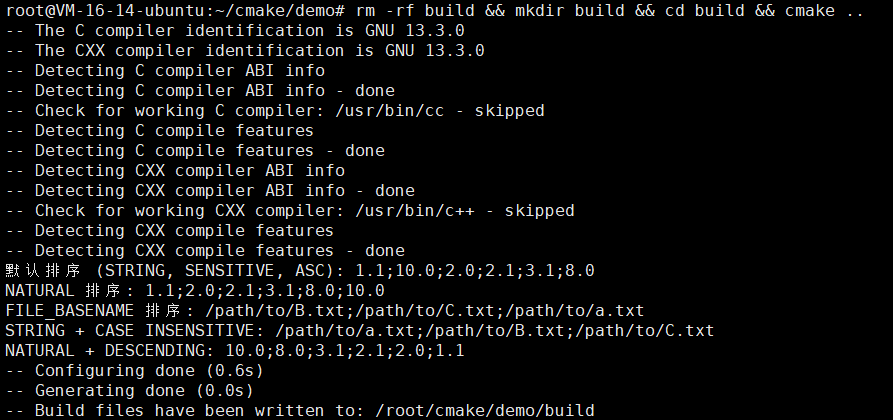
# 1. 默认排序 (STRING, SENSITIVE, ASCENDING)
set(LIST1 ${VERSIONS})
list(SORT LIST1)
message("默认排序 (STRING, SENSITIVE, ASC): ${LIST1}")
# 2. 使用 NATURAL 排序(数字会按数值比较)
set(LIST2 ${VERSIONS})
list(SORT LIST2 COMPARE NATURAL)
message("NATURAL 排序: ${LIST2}")
# 3. 按文件名排序 (FILE_BASENAME)
set(LIST3 ${FILES})
list(SORT LIST3 COMPARE FILE_BASENAME)
message("FILE_BASENAME 排序: ${LIST3}")
# 4. 忽略大小写排序 (CASE INSENSITIVE)
set(LIST4 ${FILES})
list(SORT LIST4 COMPARE STRING CASE INSENSITIVE)
message("STRING + CASE INSENSITIVE: ${LIST4}")
# 5. 降序排序 (ORDER DESCENDING)
set(LIST5 ${VERSIONS})
list(SORT LIST5 COMPARE NATURAL ORDER DESCENDING)
message("NATURAL + DESCENDING: ${LIST5}")接下来我们就来搭建我们的项目
bash
rm -rf build && mkdir build && cd build && cmake ..运行结果