
#LangGraphAgent开发实战(二) TOC
接入LangSmith
LangSmith: Agent开发的调试、日志和追踪平台,和LangChain、LangGraph原生集成 URL: smith.langchain.com/ 申请APIKey SaaS平台,超过一定用量需付费
简单实践
这里我们把上一章节翻译代码贴过来,然后加上
LangSmith的一些代码,调用试试看。
python
# langgraph 实现 translation agent
# langgraph 简单示例
from typing import TypedDict, Annotated
from langchain_openai import ChatOpenAI
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
import os
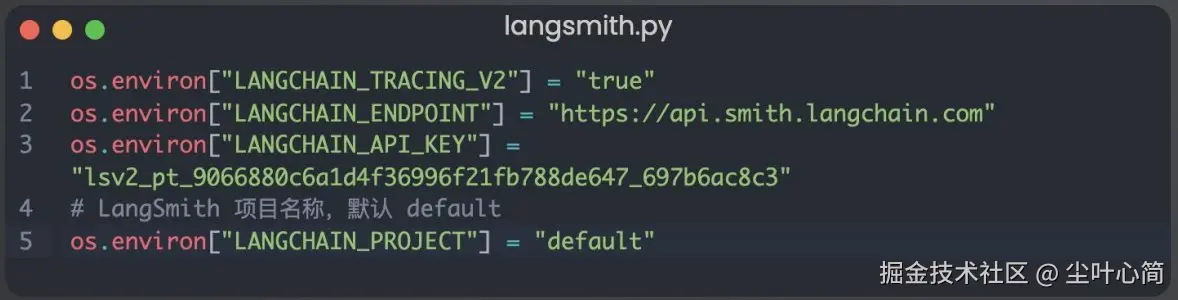
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "你的申请的smith API Key"
# LangSmith 项目名称,默认 default
os.environ["LANGCHAIN_PROJECT"] = "default"
llm = ChatOpenAI(model="gpt-4o",api_key="你的Open API Key")
source_lang = "Chinese"
target_lang = "English"
class State(TypedDict):
messages: Annotated[list, add_messages]
def initial_translation(state: State):
source_text = state["messages"][-1].content
system_prompt = f"You are an expert linguist, specializing in translation from {source_lang} to {target_lang}."
translation_prompt = f"""This is an {source_lang} to {target_lang} translation, please provide the {target_lang} translation for this text. \
Do not provide any explanations or text apart from the translation.
{source_lang}: {source_text}
{target_lang}:"""
messages = [
(
"system",
system_prompt,
),
("human", translation_prompt),
]
return {"messages": [llm.invoke(messages)]}
def reflect_on_translation(state: State):
country = "China"
source_text = state["messages"][-2].content
translation_1 = state["messages"][-1].content
system_message = f"You are an expert linguist specializing in translation from {source_lang} to {target_lang}. \
You will be provided with a source text and its translation and your goal is to improve the translation."
reflection_prompt = f"""Your task is to carefully read a source text and a translation from {source_lang} to {target_lang}, and then give constructive criticism and helpful suggestions to improve the translation. \
The final style and tone of the translation should match the style of {target_lang} colloquially spoken in {country}.
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's \n\
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),\n\
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),\n\
(iii) style (by ensuring the translations reflect the style of the source text and take into account any cultural context),\n\
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {target_lang}).\n\
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else."""
messages = [
(
"system",
system_message,
),
("human", reflection_prompt),
]
return {"messages": [llm.invoke(messages)]}
def improve_translation(state: State):
source_text = state["messages"][-3].content
translation_1 = state["messages"][-2].content
reflection = state["messages"][-1].content
system_message = f"You are an expert linguist, specializing in translation editing from {source_lang} to {target_lang}."
improve_prompt = f"""Your task is to carefully read, then edit, a translation from {source_lang} to {target_lang}, taking into
account a list of expert suggestions and constructive criticisms.
The source text, the initial translation, and the expert linguist suggestions are delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT>, <TRANSLATION></TRANSLATION> and <EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS> \
as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
<EXPERT_SUGGESTIONS>
{reflection}
</EXPERT_SUGGESTIONS>
Please take into account the expert suggestions when editing the translation. Edit the translation by ensuring:
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules and ensuring there are no unnecessary repetitions), \
(iii) style (by ensuring the translations reflect the style of the source text)
(iv) terminology (inappropriate for context, inconsistent use), or
(v) other errors.
Output only the new translation and nothing else."""
messages = [
(
"system",
system_message,
),
("human", improve_prompt),
]
return {"messages": [llm.invoke(messages)]}
workflow = StateGraph(State)
workflow.add_node("initial_translation", initial_translation)
workflow.add_node("reflect_on_translation", reflect_on_translation)
workflow.add_node("improve_translation", improve_translation)
# 定义 DAG
workflow.set_entry_point("initial_translation")
workflow.add_edge("initial_translation", "reflect_on_translation")
workflow.add_edge("reflect_on_translation", "improve_translation")
workflow.add_edge("improve_translation", END)
#workflow.add_edge("chat", "__end__")
#workflow.set_finish_point("chat")
graph = workflow.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
"""
静夜思\n
床前明月光,疑是地上霜。\n
举头望明月,低头思故乡。\n
"""
user_input = input("输入中翻英内容: ")
events = graph.stream(
{"messages": [("user", user_input)]}, stream_mode="values"
)
for event in events:
event["messages"][-1].pretty_print()
# for event in graph.stream({"messages": ("user", user_input)}):
# for value in event.values():
# print("Assistant:", value["messages"][-1].content)
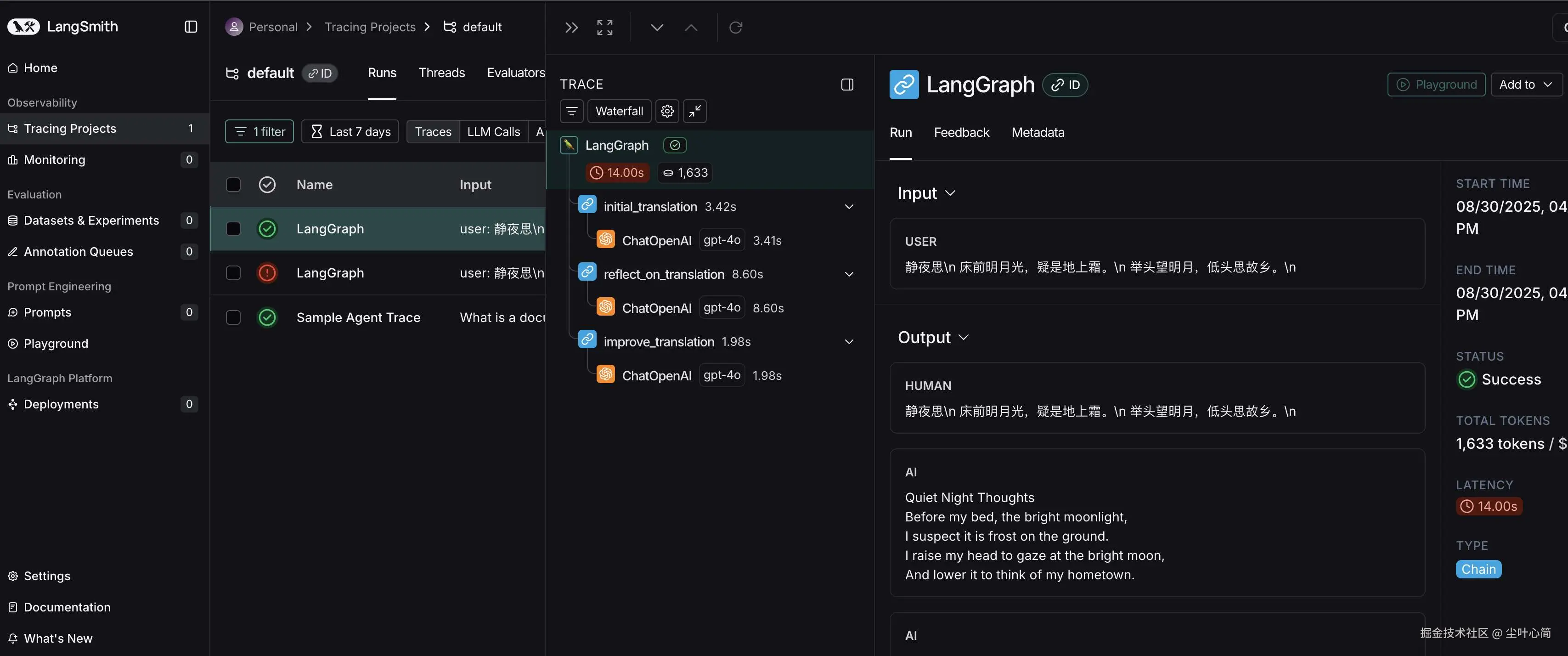
然后我们回到LangSmith上面查看一下,他可以展示出我们的调用逻辑节点。
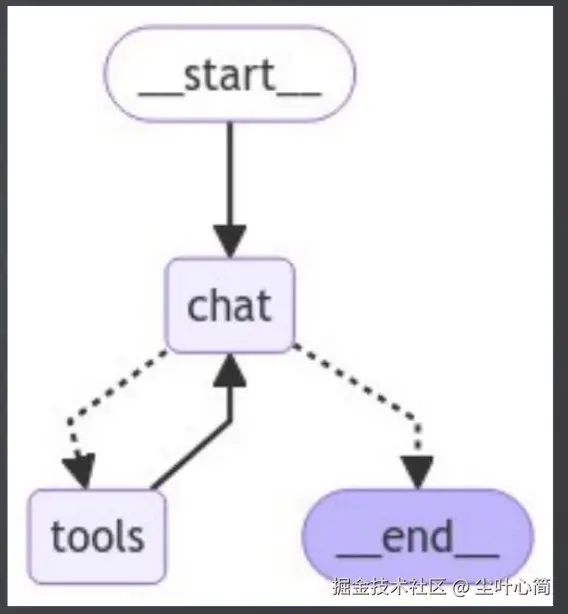
借助LangGraph实现ReActAgent
ReAcTAgent:根据用户输入进行思考,循环调用工具,直到有足够的信息来解决用户输入。
python
# 安装相关包
! pip install -U langgraph langchain-openaiUser:帮我修改payment的工作负载,镜像为
nginx:v1.0。 Assistant:要修改payment工作负载,首先要获取payment deploymentAssistant:先调用tools:get_deployment获取工作负载 Assistant:获取成功,再调用tools:patch_deployment修改工作负载 Assistant:修改成功
如何控制循环结束?
借助
add_conditional_edges实现动态控制,当条件函数返回tools字符串,则继续调 用tools节点,当返回__end__字符串,则退出 条件函数should_continue的条件逻辑是检查AI消息是否需要继续调用工具
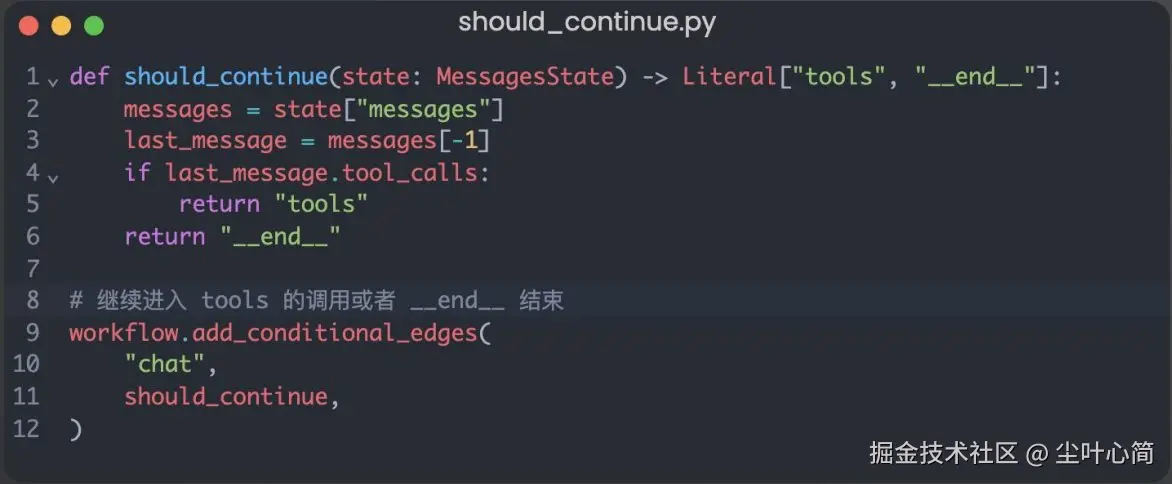
核心代码
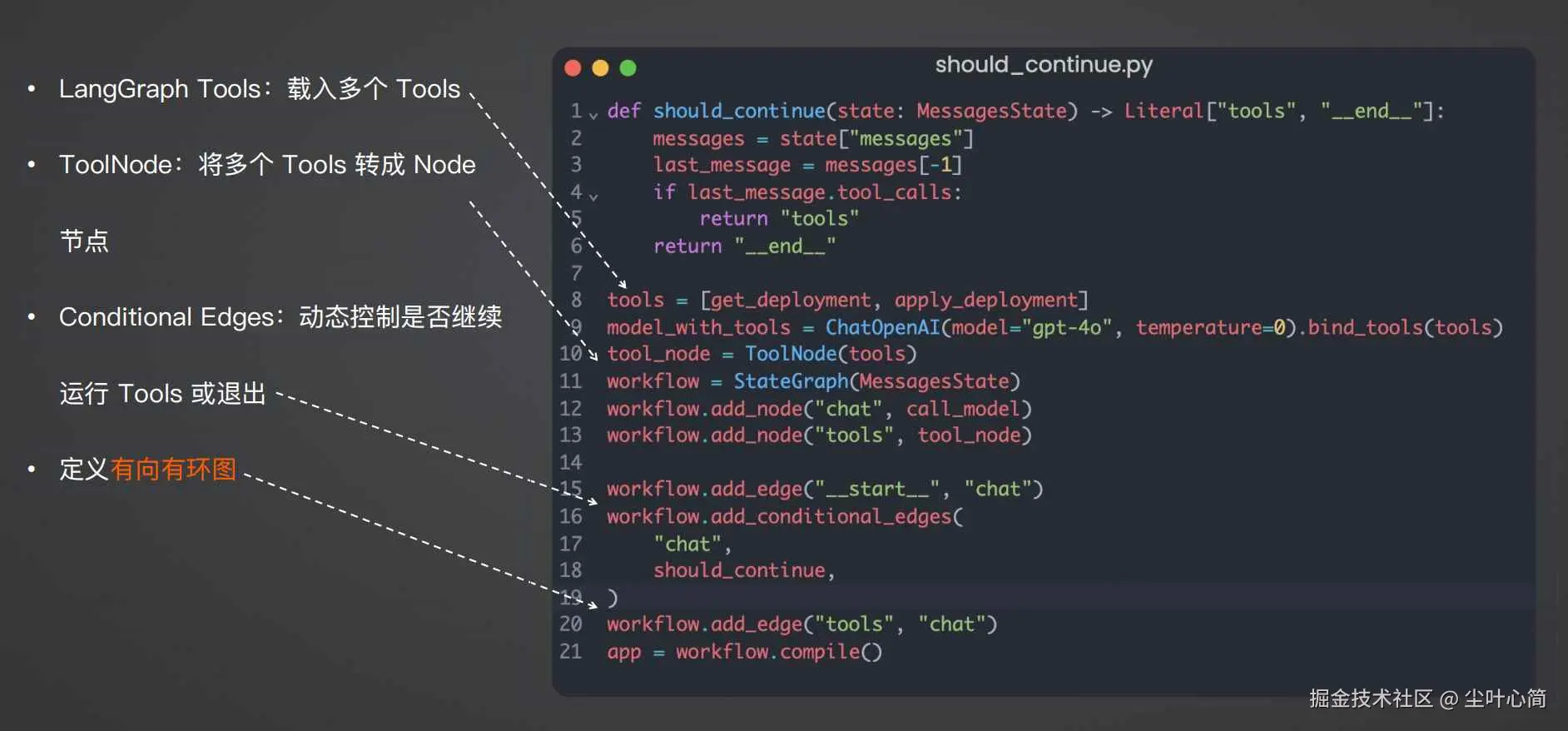
完整示例代码如下:
python
import os
from langchain_openai import ChatOpenAI
from typing import Literal
from langchain_core.tools import tool
from IPython.display import Image, display
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, MessagesState
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "你的申请的smith API Key"
# LangSmith 项目名称,默认 default
os.environ["LANGCHAIN_PROJECT"] = "default"
@tool
def get_deployment(deplyment_name: str):
"""Use this to get deployment YAML."""
print("get deployment: ", deplyment_name)
return """
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment
spec:
selector:
matchLabels:
app: payment
template:
metadata:
labels:
app: payment
spec:
containers:
- name: payment
image: nginx
ports:
- containerPort: 80
"""
@tool
def apply_deployment(patch_json: str):
"""Edit the deployment YAML."""
print("apply deployment: ", patch_json)
# 这里在后续的课程里会讲解调用 k8s API 来真正部署 patch_json
return "deployment applied"
def call_model(state: MessagesState):
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
def should_continue(state: MessagesState) -> Literal["tools", "__end__"]:
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return "__end__"
tools = [get_deployment, apply_deployment]
model_with_tools = ChatOpenAI(model="gpt-4o", temperature=0,
api_key="你的API Key"
).bind_tools(tools)
tool_node = ToolNode(tools)
workflow = StateGraph(MessagesState)
workflow.add_node("chat", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge("__start__", "chat")
workflow.add_conditional_edges(
"chat",
should_continue,
)
workflow.add_edge("tools", "chat")
app = workflow.compile()
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
pass
for chunk in app.stream(
{"messages": [("human", "帮我修改 payment 的工作负载,镜像为 nginx:v1.0")]}, stream_mode="values"
):
chunk["messages"][-1].pretty_print()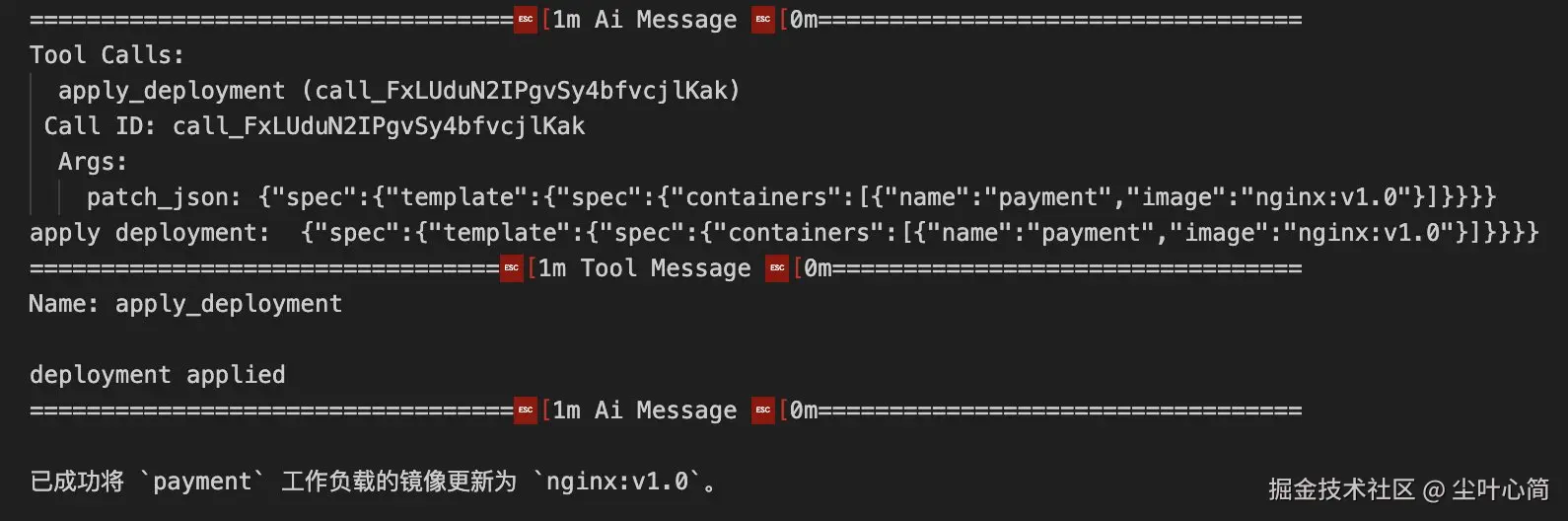
深入LangGraph并行(Super-step)
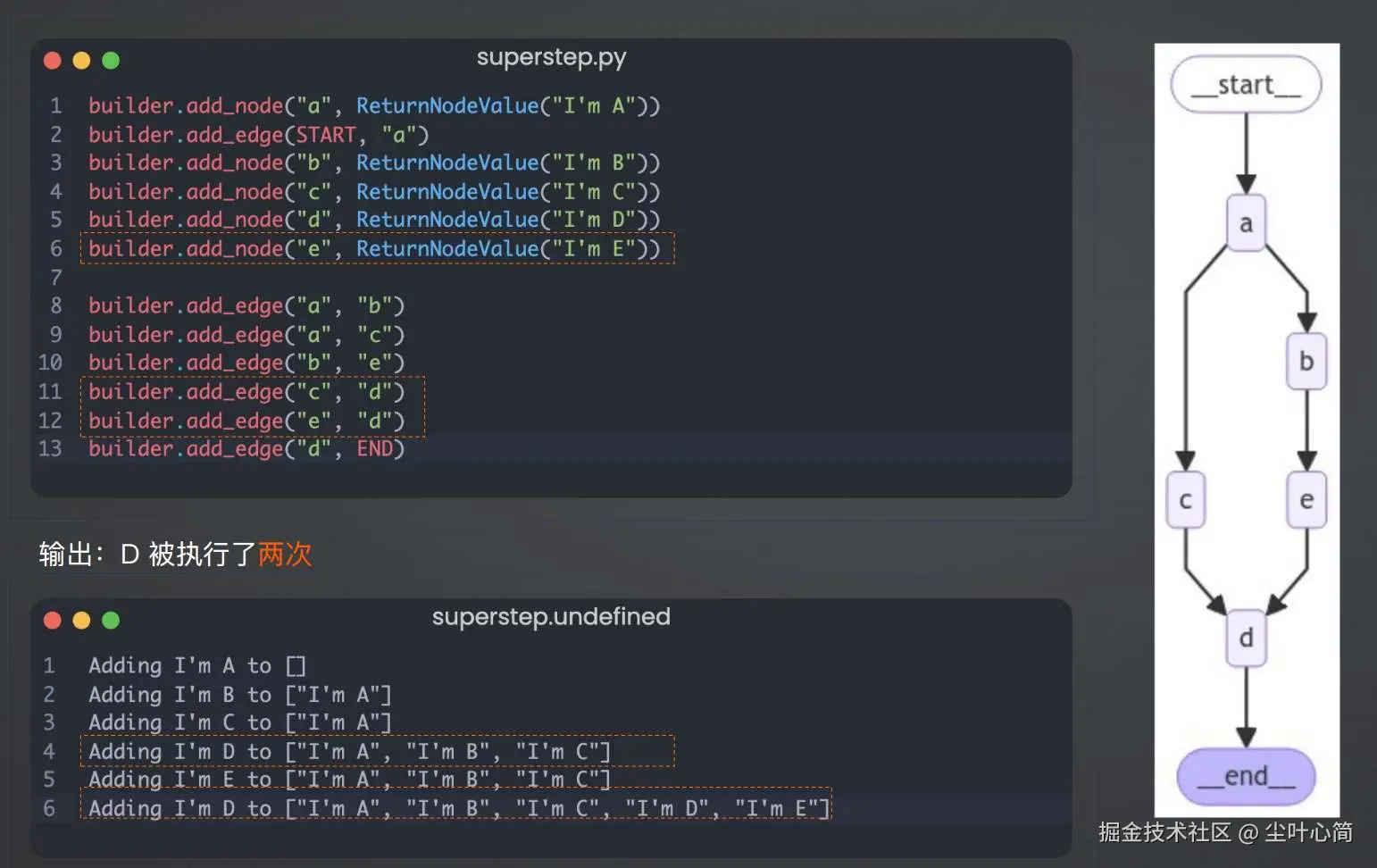
根据下面的代码可以实现LangGraph进行并行处理,这里我们可以看到并行处理了b和c,并且d只执行了一次。

但是当并行的节点数量不一致时,最终的D节点是会输出两次的,如下图所示:
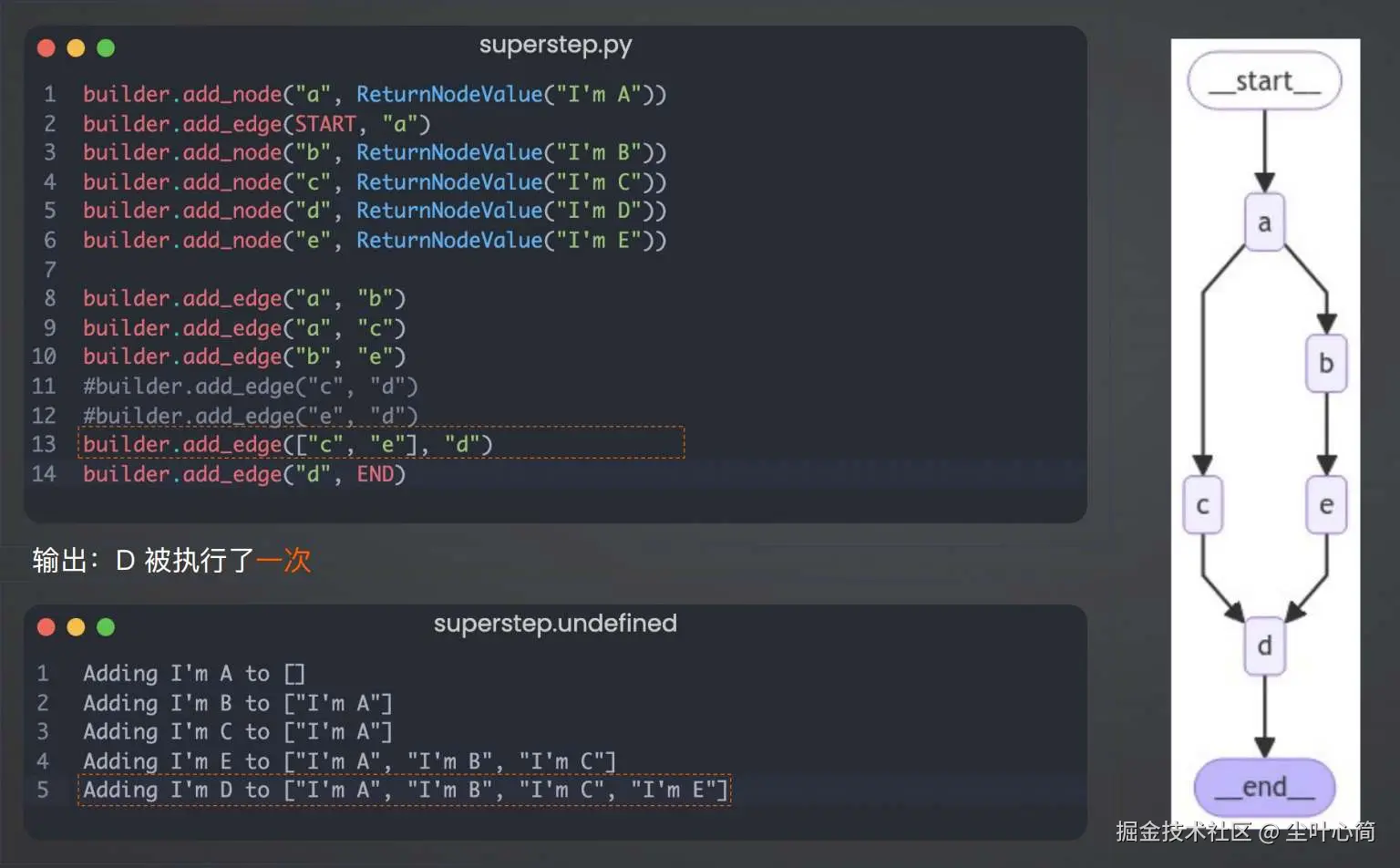
如果我希望执行完成c点和e点后,只执行一次d点我们可以这样写。
从零开发个人运维知识库Agent
三种落地方式
1.无需代码开发,自托管部署:QAnything、RAGFlow、OpenWebUI 2.SaaS服务:Coze、Dify 3.二次开发,深度接入公司业务流程:LangChain、LangGraph 3.1. 创建工单 3.2. 读取内部运维数据 3.3打通IM工具 3.4. 根因分析
Coze个人运维知识库
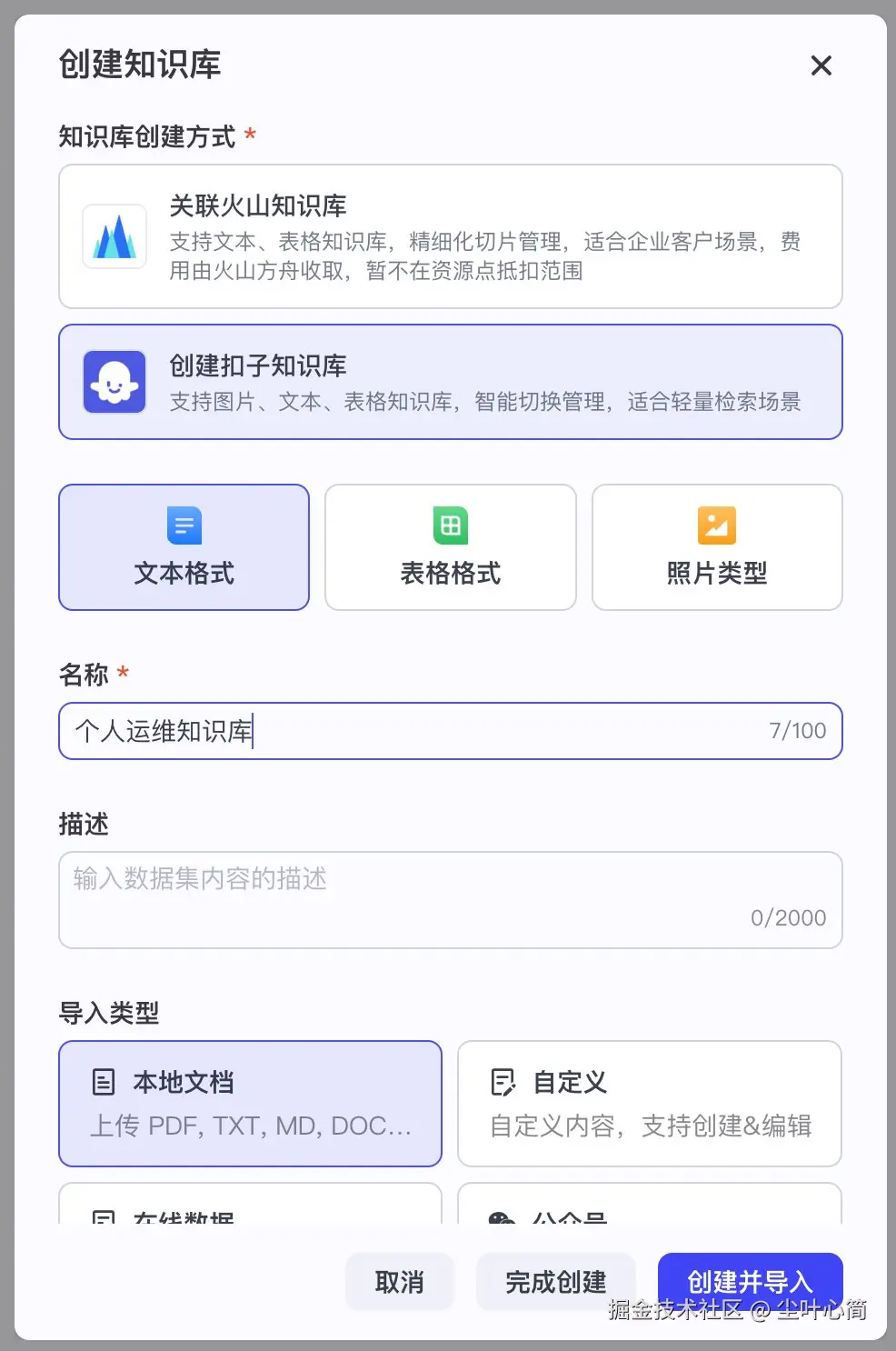
注册www.coze.com/ 打开工作空间->点击资源库->资源->知识库->创建扣子知识库->创建扣子知识库。

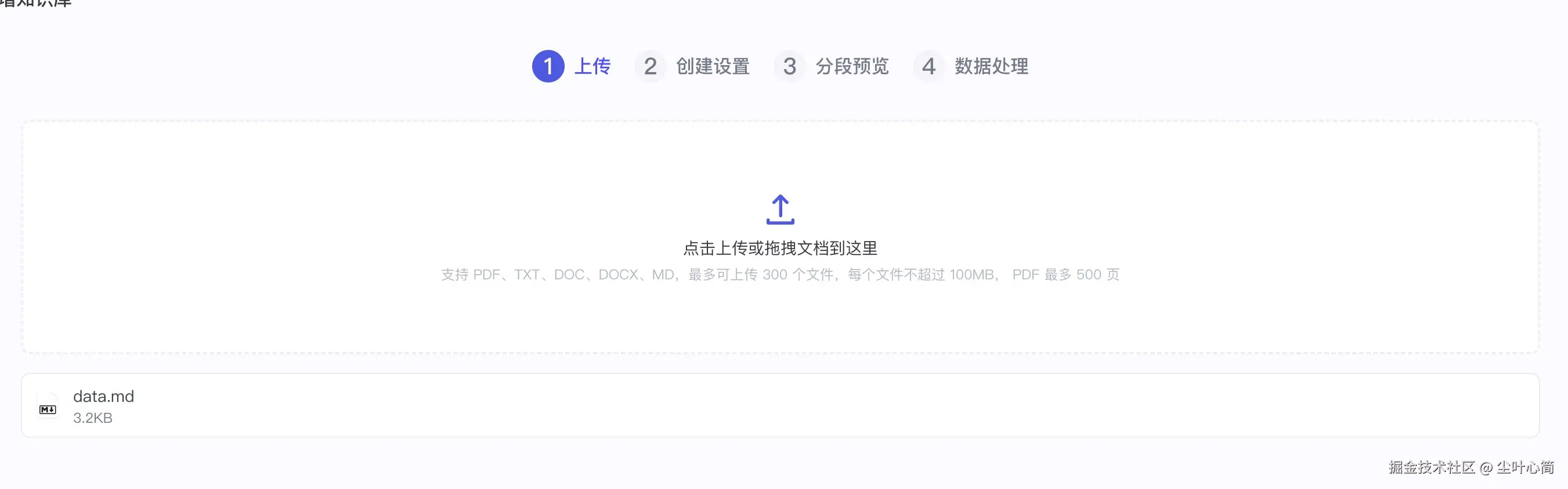
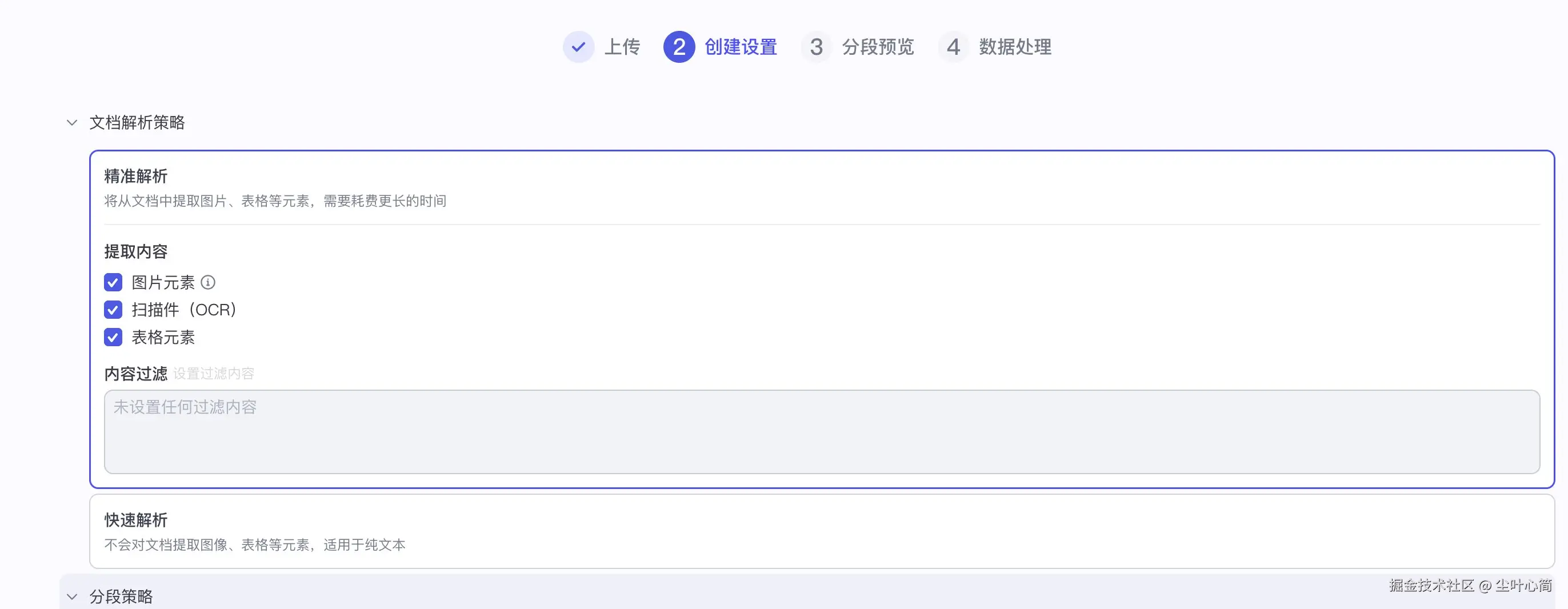
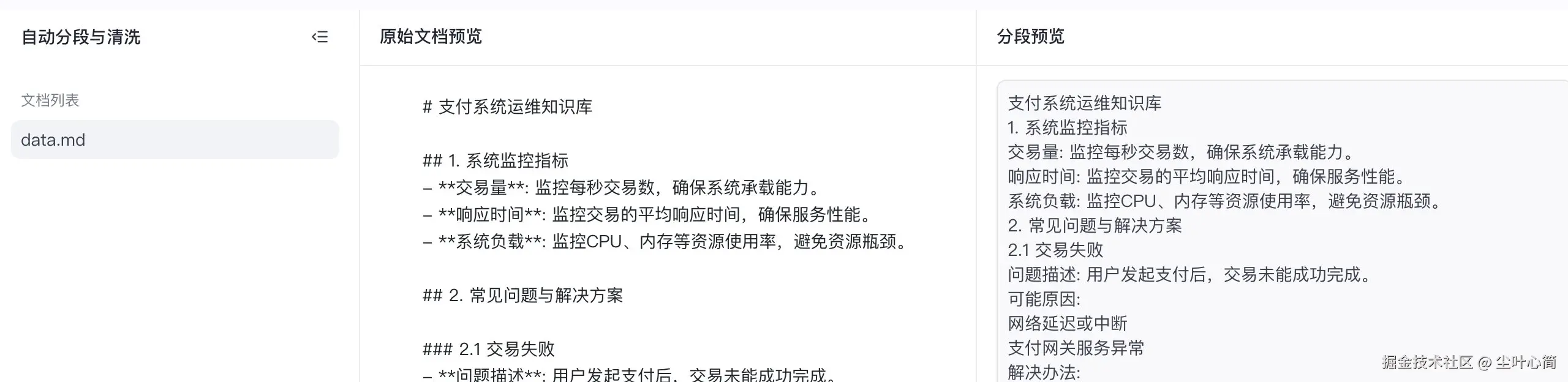
起名为个人运维知识库,创建并导入,然后上传我们的文件
data.md,然后点击下一步,下一步直到完成。

接下来我来通过点击旁边的+好来创建智能体。
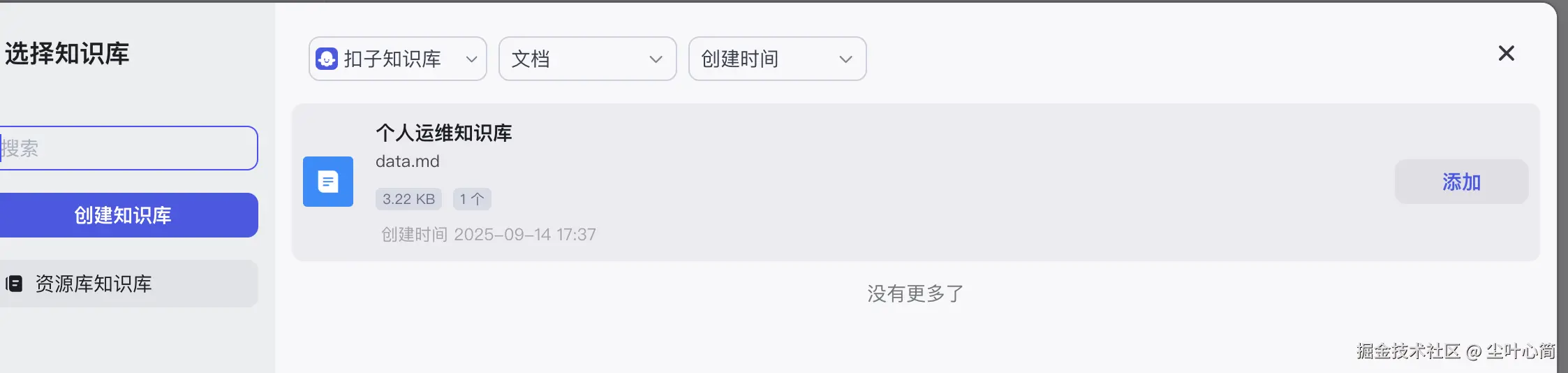
在知识->点一下文本再下点击+,添加刚才创建的知识库
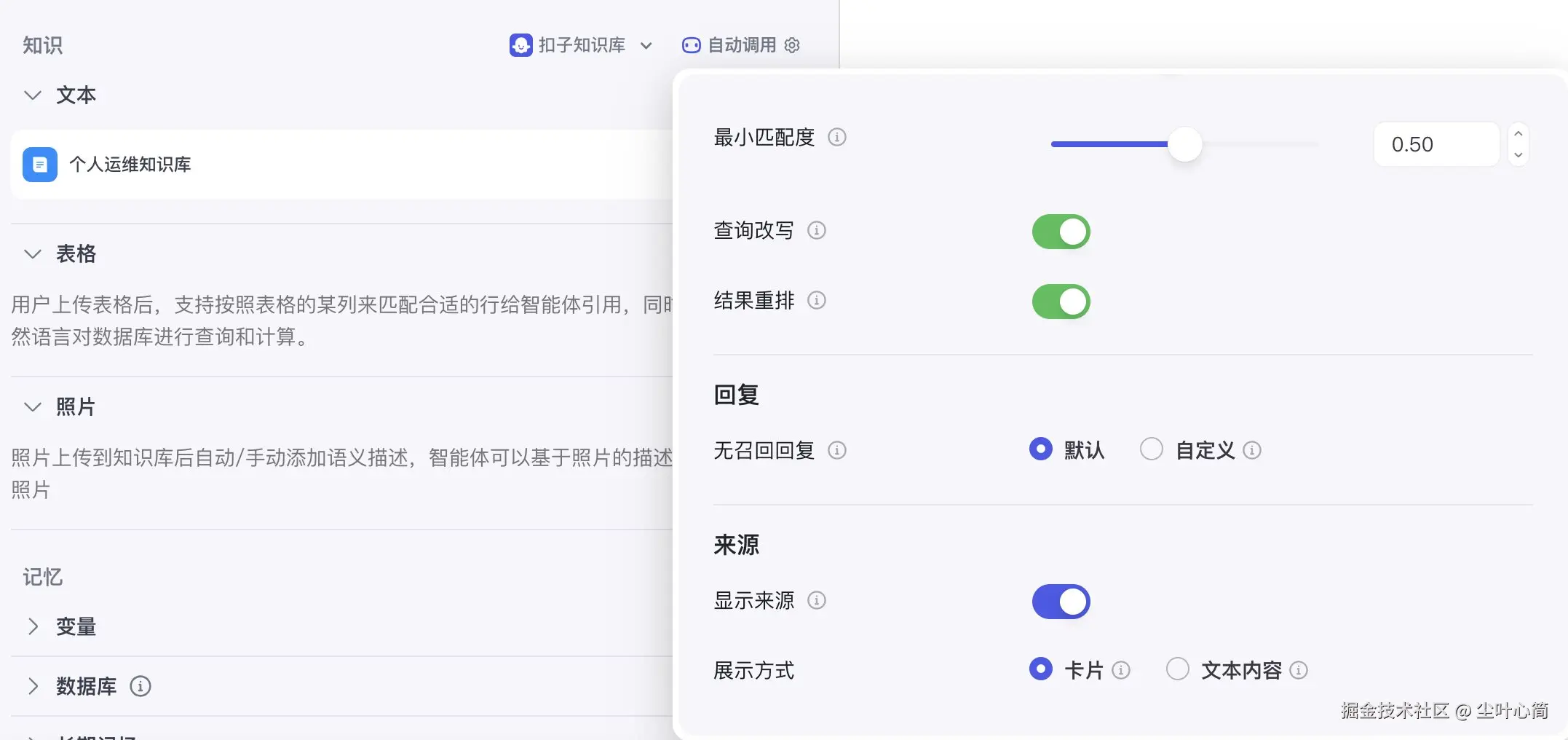
然后我们点击自动调用,在来源显示来源进行开启它。
在右侧开始调试,提问:你知道payment服务是谁维护吗?
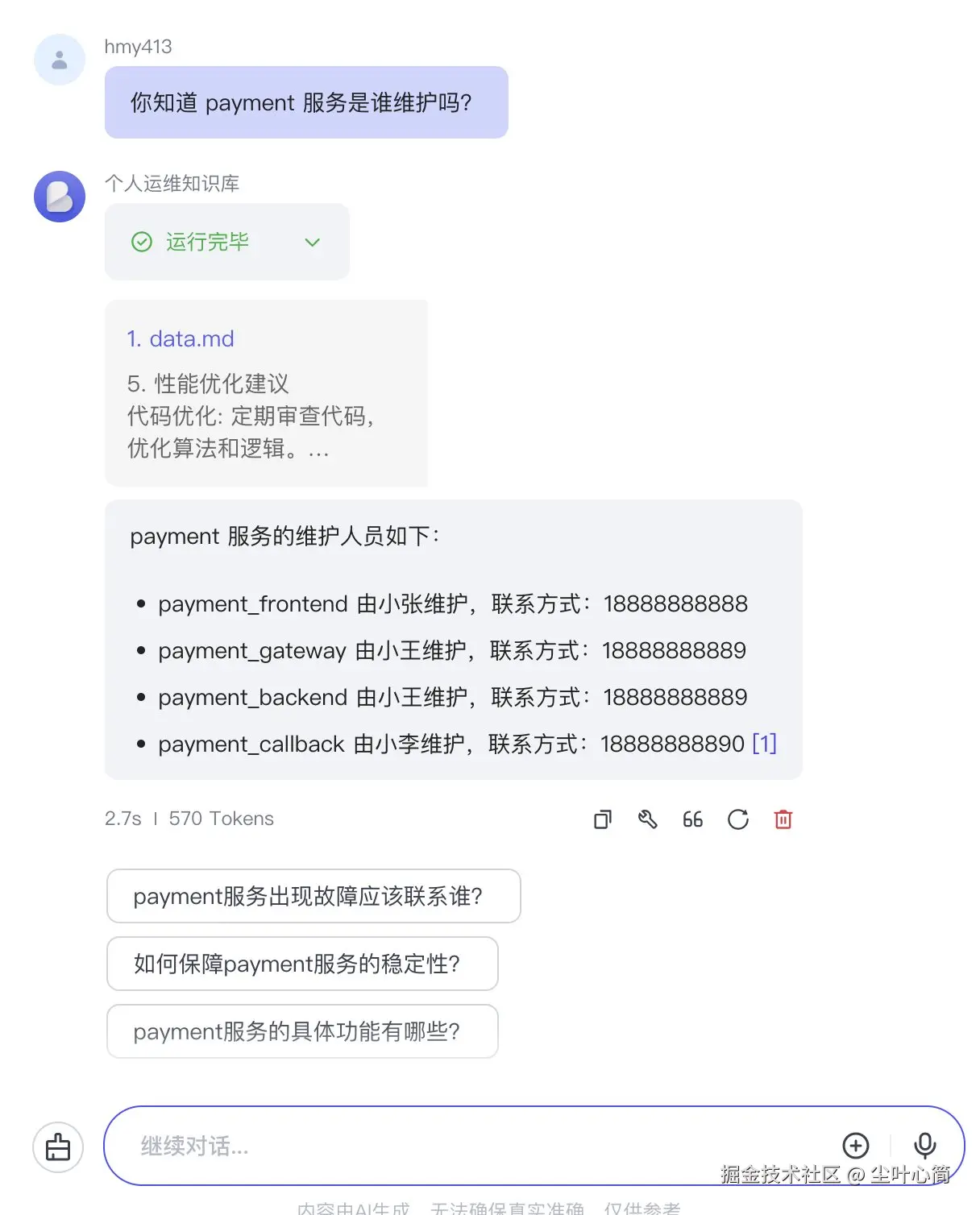
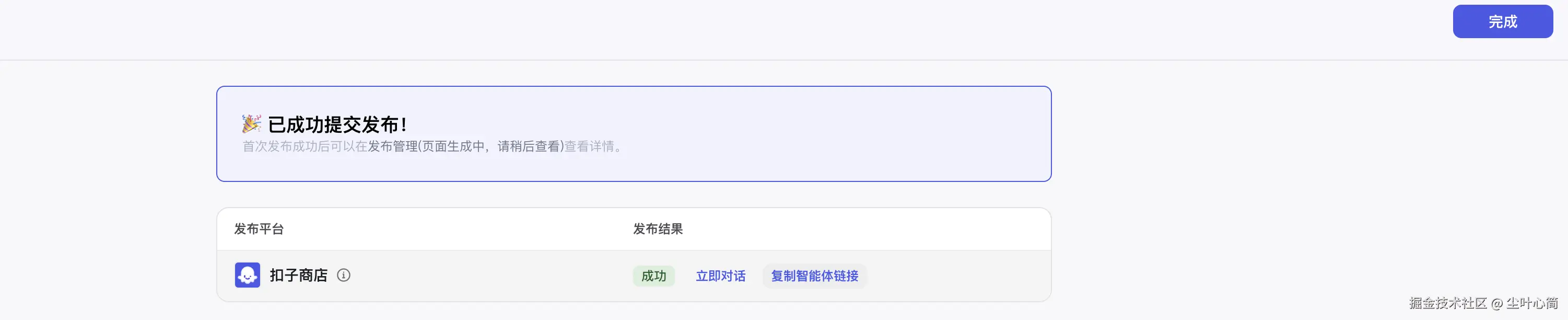
发布Bot,获得一个公网访问链接,例如:www.coze.cn/store/agent...
Coze参数配置
就是刚刚在文本添加那儿自动调用展开的列表配置。
