前言
程序抛出Read timed out 这个问题已经出现过一年多了,之前因为这个问题导致定时任务运行一段时间就停止、报名重复等一系列问题,这个问题的本质就是:程序向数据库发送了commit指令之后,一直得不到响应,就超时报错,AOP自动回滚也失败。然后一系列的问题就产生了。
之前的临时解决方案,就是延长了Read timed out时间,从原来的默认10s延长到40s。当然这个也只临时的解决方案!
🔈环境是信创环境:云服务器、数据库这些都是用的国产的;数据库采用的是主从架构
今天就来分享一下我的定位思路🚀
报错详细日志
程序直接的报错如下:
js
2025-09-11 09:00:45.384 [QuartzScheduler_MyScheduler-cdszgh-szhpt-41757490208098_ClusterManager] ERROR druid.sql.Statement - [statementLogError,148] - {conn-10013, pstmt-21177} execute error. UPDATE QRTZ_SCHEDULER_STATE SET LAST_CHECKIN_TIME = ? WHERE SCHED_NAME = 'MyScheduler' AND INSTANCE_NAME = ?
com.kingbase8.util.KSQLException: An I/O error occurred while sending to the backend.
at com.kingbase8.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:428)
at com.kingbase8.jdbc.KbStatement.executeInternal_(KbStatement.java:784)
...................
com.alibaba.druid.filter.FilterChainImpl.preparedStatement_executeUpdate(FilterChainImpl.java:3236)
.................
org.quartz.impl.jdbcjobstore.StdJDBCDelegate.updateSchedulerState(StdJDBCDelegate.java:2975)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.clusterCheckIn(JobStoreSupport.java:3477)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.doCheckin(JobStoreSupport.java:3330)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.manage(JobStoreSupport.java:3935)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.run(JobStoreSupport.java:3972)
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
....................
2025-09-11 09:00:45.386 [QuartzScheduler_MyScheduler-cdszgh-szhpt-41757490208098_ClusterManager] ERROR o.s.s.q.LocalDataSourceJobStore - [rollbackConnection,3729] - Couldn't rollback jdbc connection. This _connection has been closed.
com.kingbase8.util.KSQLException: This _connection has been closed.
at com.kingbase8.jdbc.KbConnection.checkIsClosed(KbConnection.java:1401)
at com.kingbase8.jdbc.KbConnection.rollback(KbConnection.java:1414)
at com.alibaba.druid.filter.FilterChainImpl.connection_rollback(FilterChainImpl.java:675)
at com.alibaba.druid.filter.FilterAdapter.connection_rollback(FilterAdapter.java:952)
at com.alibaba.druid.filter.logging.LogFilter.connection_rollback(LogFilter.java:437)
at com.alibaba.druid.filter.FilterChainImpl.connection_rollback(FilterChainImpl.java:670)
at com.alibaba.druid.filter.stat.StatFilter.connection_rollback(StatFilter.java:289)
------
ClusterManager: Error managing cluster: Couldn't commit jdbc connection. An I/O error occurred while sending to the backend.
org.quartz.JobPersistenceException: Couldn't commit jdbc connection. An I/O error occurred while sending to the backend.
at org.quartz.impl.jdbcjobstore.JobStoreSupport.commitConnection(JobStoreSupport.java:3749)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.doCheckin(JobStoreSupport.java:3331)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.manage(JobStoreSupport.java:3935)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.run(JobStoreSupport.java:3972)
Caused by: com.kingbase8.util.KSQLException: An I/O error occurred while sending to the backend.
at com.kingbase8.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:428)
at com.kingbase8.jdbc.KbConnection.executeTransactionCommand(KbConnection.java:1350)
at com.kingbase8.jdbc.KbConnection.commit(KbConnection.java:1387)
........................
at com.sun.proxy.$Proxy540.commit(Unknown Source)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.commitConnection(JobStoreSupport.java:3747)
... 3 common frames omitted
Caused by: java.net.SocketTimeoutException: Read timed out
... 19 common frames omitted🔈 前言也说了之前的默认socket time-out 是10s 改成 40s 就很少出现这个问题了,说明 程序的commit 确实是发出去了,只是等到 数据库收到命令-\>处理完毕响应 回来的时间太长了. 目前是不清楚具体是哪个阶段出的问题:
-
应用服务器发出命令------------>数据库接受命令(网络问题)
-
数据库收到命令---------------->处理命令并响应(数据库本身问题)
排查过程
解决过程中肯定是要把AI利用起来,首先确认造成响应超时的可能有哪些
- ❌应用层问题:排除了慢SQL、以及连接时间默认的已经是10s完全够了(因为Quartz在维护任务状态的时候,表就一两条数据也会出现断开连接的情况)
- 数据库性能问题:之前出现过数据性能的问题,CPU直接被打满这个情况也出现过。(不大相信是这个问题)
- ✔数据库环境问题:是否和主从架构、网络有关系(我是比较怀疑这个原因引起)
主从同步是否存在问题(排除)
首先我们要了解主从架构下面,提交事务到事务执行成功的流程:
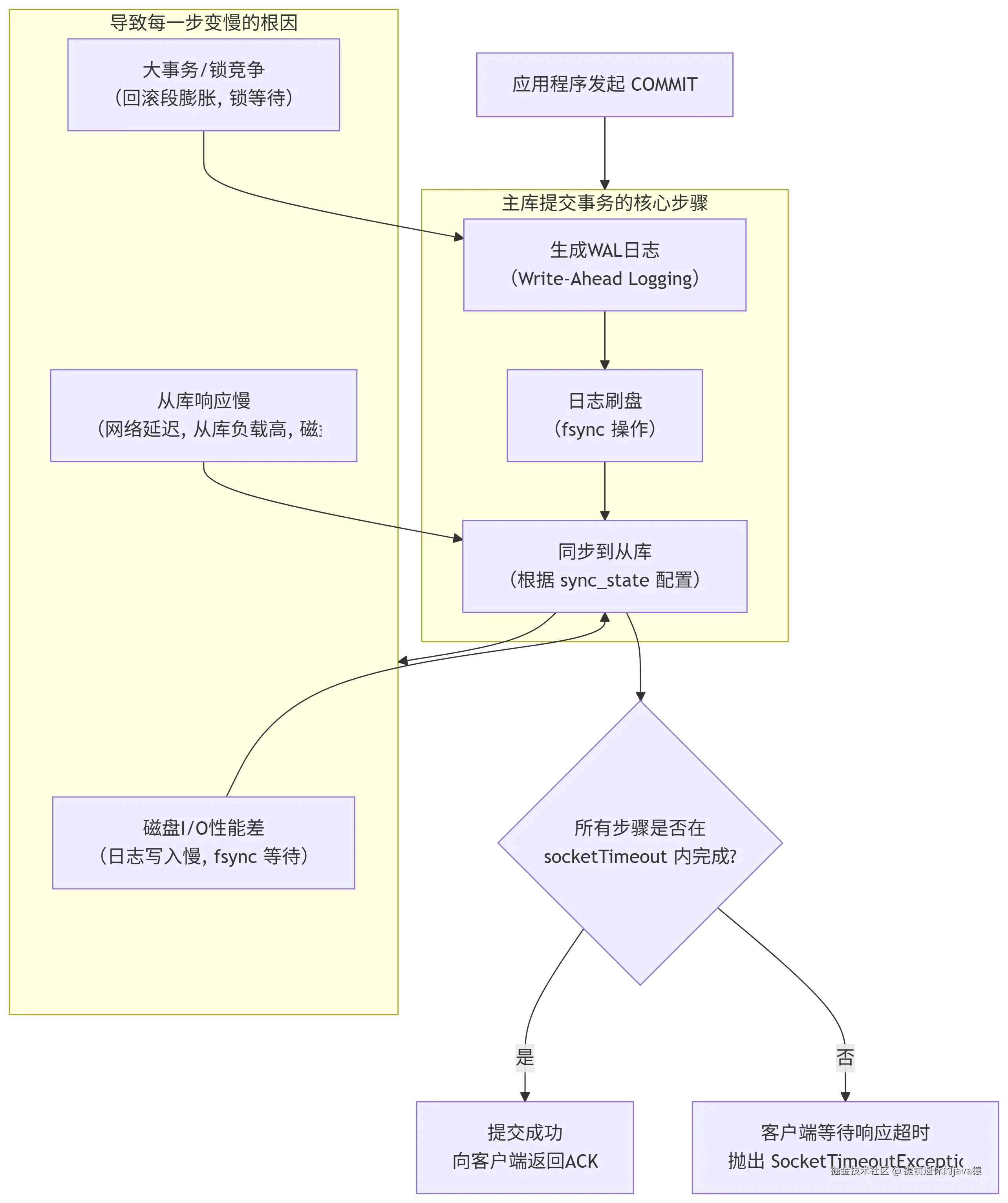
如果同步从库出现问题,那么确实会阻塞我们的事务响应。 如何排除主从同步是否异常呢❓
1.查询当前主从复制情况(执行多次观察):
SQL
SELECT
usename AS application_user,
application_name,
client_addr AS client_address,
--复制状态。最常见也是最重要的状态是 streaming,表示流复制正在进行中,状态正常。backup(正在备份)
state,
-- **同步模式**。表示从库的同步级别:
-- async:异步复制。主库提交无需等待从库。
-- sync:同步复制。主库提交需等待此从库确认。
-- quorum`:法定人数同步。主库提交需等待多个从库中的一部分确认。**您之前的配置**
sync_state,
-- 写入延迟。主库生成的 WAL 日志到达从库服务器后,写入到从库操作系统缓存所花费的时间。
-- 这反映了网络传输 + 从库 OS 写入的延迟。
write_lag::TEXT AS write_lag_str,
-- 刷盘延迟。WAL 日志从从库的操作系统缓存持久化刷入从库磁盘所花费的时间。
flush_lag::TEXT AS flush_lag_str,
-- 重放延迟(最关键的指标!)*。WAL 日志在从库上被磁盘刷入后,被 SQL 进程应用到从库数据库所花费的时间。
-- 这个时间直接反映了你的从库数据比主库"旧"了多久。是业务层面能感知到的延迟。
replay_lag::TEXT AS replay_lag_str,
-- 各种积压的字节数。这些计算字段直观地显示了在主库当前日志位置下,从库还有多少字节的数据没收到(`send`)、没写入(`write`)、没刷盘(`flush`)、没应用(`replay`)。数字越大,延迟越严重。
pg_current_wal_lsn() - sent_lsn AS pending_send_bytes,
pg_current_wal_lsn() - write_lsn AS pending_write_bytes,
pg_current_wal_lsn() - flush_lsn AS pending_flush_bytes,
pg_current_wal_lsn() - replay_lsn AS pending_replay_bytes
FROM pg_stat_replication;
✔从同步状态、以及同步时间、堆积数据上来看也没发现什么问题。至少正常情况下是没有发现主从同步问题的
当然这个是查看当前快照的状态,本身发生
read timed out也不是必现的。估计要排查这个问题,还得看发生问题时候,数据库的状态。
✔后面搞了个新的测试项目,没有配置主从架构,还是出现Read timed out 问题
数据库日志
js
2025-09-11 09:00:57.068 CST [3136949] LOG: unexpected EOF on client connection with an open transaction
2025-09-11 09:00:57.069 CST [3138912] LOG: unexpected EOF on client connection with an open transaction
2025-09-11 09:00:57.078 CST [3138329] LOG: unexpected EOF on client connection with an open transaction
2025-09-11 09:00:57.078 CST [3140068] LOG: unexpected EOF on client connection with an open transaction
..................抓取了数据库日志,确实也存在断开连接的问题,上面是部分日志,数据库中有三种类型的日志如下:
1. unexpected EOF on client connection with an open transaction
客户端连接异常中断,且中断时存在未完成的事务
-
发生场景:
- 应用程序(客户端)在事务进行中(例如执行了
BEGIN和INSERT后,还未执行COMMIT或ROLLBACK)时发生了崩溃、进程被强制杀死(kill -9)、服务器重启或网络设备突然断电。 - 客户端程序编写有缺陷,没有进行正确的异常处理,在事务中发生错误时直接退出,而没有发送回滚指令。
- 应用程序(客户端)在事务进行中(例如执行了
🕘 表明数据库没有收到
commit和rollback指令
2. could not receive data from client: Connection timed out
建立连接等待客户端发送数据超时,在操作系统设定的TCP超时时间内没有收到任何响应
-
发生场景:
- 网络问题:客户端和服务器之间的网络路由上存在防火墙、负载均衡器或中间路由器,这些设备配置了空闲连接超时时间(例如为了节省资源)。一旦连接空闲超过这个时间,它们会默默地丢弃TCP包,导致两端连接状态不一致。
- 客户端消失:客户端主机崩溃、网络线缆被拔出或Wi-Fi断开。
🕘 长时间没有收到客户端指令
3. could not receive data from client: Connection reset by peer
数据库服务器收到了来自客户端的 TCP RST (Reset) 包。这是一个明确的信号,表示客户端主动拒绝或终止了这个连接。
-
发生场景:
- 客户端应用程序主动调用了类似
close(socket)或terminate的方法,但可能没有优雅地等待数据库响应。 - 客户端的操作系统在套接字关闭后仍然收到数据,于是发送了RST包(例如,应用程序崩溃后重启,之前连接的端口被用于新的连接)。
- 防火墙或安全软件(如杀毒软件)主动阻断了连接。
- 客户端应用程序主动调用了类似
客户端在socket通信异常之后,就close了连接
✅ 通过日志来看确实90%都是网络问题引起的
网络问题排查
应用服务器-----> 数据库服务器:
执行命令:ping -c 1000 ip
执行结果: 基本上是在0-3ms,小部分是几十毫秒,很少一部分是 100ms以上
js
64 bytes from 17x.xx..: icmp_seq=850 ttl=128 time=126 ms
64 bytes from 17x.xx..: icmp_seq=998 ttl=128 time=0.394 ms执行好几次,有一次存在 0.1%的丢包率
总结
今天分享当发生Read time out时候,排除了SQL问题之后,我们如何去排查这个问题。首先是查看数据库的性能是否存在阻塞的问题,是否主从架构存在同步问题,再到通过分析数据库日志,查看发生事故时候的报错日志,最后就是对网络进行排查,监控。目前暂时得出得结论就是网络问题引起的。
😭因为本人也没有数据库服务器的权限,也不想去申请这个权限,目前网络的问题已经反馈了。后面会一直跟进这个网络问题。有结论之后也再次次更新这篇文章🙆♂️
知识扩展
今天还是借这个机会,分享一下一些查询数据库状态的基本操作吧👏
数据库事务、性能问题排查(排除)
因为发生问题的频率经常是隔一个小时,两个小时就会出现,并且晚上0晨也有同样的情况。晚上也根本没有人我们的系统。所以能排除是并发高,数据库性能瓶颈了。这儿也分享一下如何排查数据库性能问题吧:
📖实际上互联网企业,都有一套完整的监控措施,比如数据库的慢SQL,数据库服务器内存、以及CPU这些指标都是被监控的。比如我们运用阿里云的数据库,其提供了更加丰富的监控指标。
在传统行业监控这一套就属于可有可无了,在没有完善监控服务的情况下。我们通过SQL去实时查询数据库的状态
- 查询活跃的事务:可以看到事务开始时间判断是否存在长事务
SQL
SELECT
pid AS 进程ID,
usename AS 用户名,
datname AS 数据库名,
client_addr AS 客户端IP,
application_name AS 应用名称,
state AS 连接状态,
xact_start AS 事务开始时间,
now() - xact_start AS 事务持续时间,
query AS 当前执行的SQL
FROM pg_stat_activity
WHERE
xact_start IS NOT NULL -- 存在活跃事务(未提交/未回滚)
AND state != 'idle' -- 排除空闲连接(仅保留正在活动的连接)
ORDER BY 事务持续时间 DESC; -- 按事务持续时间倒序,优先看长事务- 查看整体的连接数据:判断是否连接快被撑满了
SQL
-- 总连接数、活跃连接数、空闲连接数统计
SELECT
COUNT(*) AS 总连接数,
SUM(CASE WHEN state = 'active' THEN 1 ELSE 0 END) AS 活跃连接数,
SUM(CASE WHEN state = 'idle' THEN 1 ELSE 0 END) AS 空闲连接数
FROM sys_stat_activity;
-- 查看连接数上限配置
SHOW max_connections;-
检查死锁:查询
sys_locks视图,可以关注sys_locks视图中的几个关键字段:
SQL
--强制终止会话
SELECT sys_terminate_backend(阻塞进程的PID);