一、RocketMQ 核心架构图
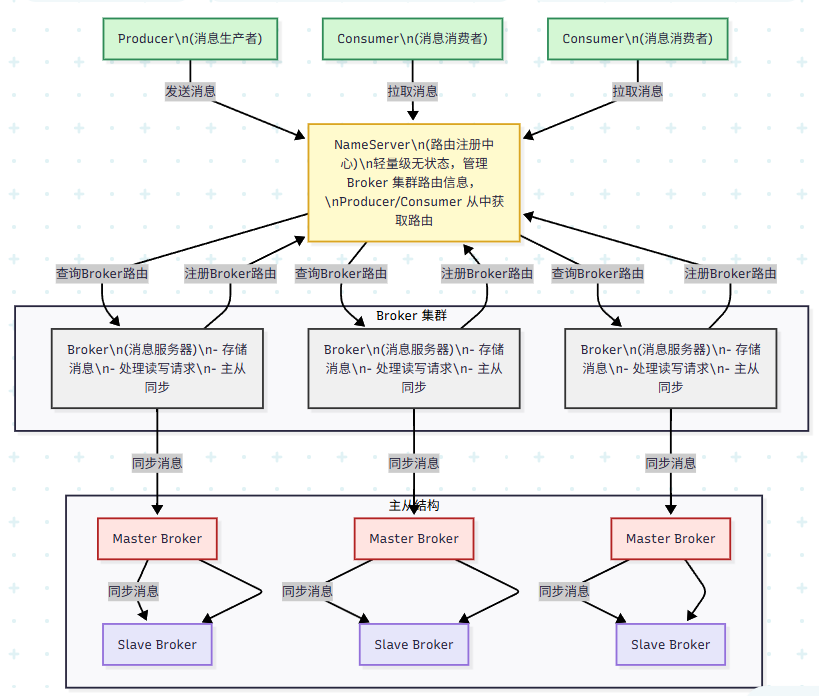
架构特点:
完全无单点:NameServer 集群无状态,Broker 主从高可用。
水平扩展:Broker 可无限横向扩展,Topic 可跨多个 Broker。
Pull 模型:Consumer 主动拉取,可控消费速度,避免压垮消费者。
二、四大核心组件详解
1. Producer(生产者)------ 消息的"发件人"
职责:
- 创建并发送消息到指定 Topic。
- 支持同步、异步、单向发送模式。
- 自动从 NameServer 获取 Topic 路由信息(Broker 地址列表)。
- 支持消息重试、事务消息、顺序消息、延迟消息。
关键概念:
** Producer Group:**生产者组,用于标识一类 Producer(事务消息回查用)。
Tag: 消息标签,用于 Consumer 端过滤(如 TagA || TagB)。
** Key:**消息业务唯一键,用于精确查询和去重。
java
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroup1");
producer.setNamesrvAddr("localhost:9876");
producer.start();
Message msg = new Message("OrderTopic", "CreateOrder", "orderId_123", "Hello RocketMQ".getBytes());
SendResult result = producer.send(msg); // 同步发送
System.out.println("Send Status: " + result.getSendStatus());2. Consumer(消费者)------ 消息的"收件人"
职责:
- 从 Broker 拉取消息并处理。
- 支持集群消费(Clustering)和广播消费(Broadcasting)。
- 自动从 NameServer 获取路由,负载均衡分配 Queue。
- 支持消费重试、死信队列、消费位点(Offset)持久化。
关键概念:
** Consumer Group:**消费者组,同一组内负载均衡消费(每条消息只被组内一个 Consumer 消费)。
MessageListener: 消息监听器,实现 consumeMessage() 方法处理业务逻辑。
** Offset:**消费位点,记录 Consumer 已消费到的位置(存储在 Broker 或本地)。
java
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("ConsumerGroup1");
consumer.setNamesrvAddr("localhost:9876");
consumer.subscribe("OrderTopic", "*"); // 订阅所有 Tag
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
System.out.println("Received: " + new String(msg.getBody()));
// 处理业务逻辑
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 消费成功
});
consumer.start();3. Broker(消息服务器)------ 消息的"邮局 + 仓库"
职责:
- 接收 Producer 发送的消息,存储到 CommitLog(顺序写磁盘)。
- 响应 Consumer 的拉取请求,从 ConsumeQueue + IndexFile 快速检索。
- 管理 Topic、Queue、Consumer Offset、权限控制等。
- 主从同步:Master Broker 接收读写,Slave Broker 只读 + 同步数据(高可用)。
核心存储结构:
** CommitLog:**所有 Topic 消息混合顺序写入(高性能关键)。
** ConsumeQueue:**每个 Queue 一个文件,存储消息在 CommitLog 的 offset、size、tag hash(供 Consumer 快速定位)。
** IndexFile:**基于 Key 的哈希索引,支持按 Key 查询消息。
高可用模式:
异步复制:Master 写成功即返回,异步同步给 Slave(高性能,可能丢少量数据)。
同步双写:Master + Slave 都写成功才返回(强一致,性能略低)。
4. NameServer(路由注册中心)------ 消息的"DNS 服务器"
职责:
- 无状态、轻量级:多个 NameServer 之间无通信,数据最终一致。
- 路由管理:Broker 启动时向所有 NameServer 注册 Topic 路由信息(含 Master/Slave 地址)。
- 路由发现:Producer/Consumer 定时(默认 30s)从 NameServer 拉取最新路由表。
- 心跳检测:NameServer 每 10s 检测 Broker 心跳,超时(120s)则剔除路由。
为什么不用 ZooKeeper?
RocketMQ 追求极致性能与简单性,NameServer 无选举、无 Watch,比 ZK 更轻量、更稳定。
部署建议:
至少部署 2 个 NameServer,Producer/Consumer 配置多个地址(逗号分隔)。
NameServer 不存储消息,宕机不影响已建立连接的读写(路由缓存有效期内)。
三、核心概念:Topic、Queue、Group、Tag
| 概念 | 说明 | 类比 |
|---|---|---|
| Topic | 消息主题,一类消息的逻辑分类(如 OrderTopic, LogTopic) |
邮箱的"收件箱分类" |
| Queue | Topic 的分区,一个 Topic 可分多个 Queue,分布在不同 Broker 上(并行消费) | 邮箱的"分拣格子" |
| Producer Group | 一类 Producer 的标识,用于事务消息回查 | 发件人"部门" |
| Consumer Group | 一类 Consumer 的标识,组内负载均衡消费 | 收件人"工作组" |
| Tag | 消息标签,用于 Consumer 端二次过滤(如 TagA, TagB) |
邮件"标签/优先级" |
| Key | 消息业务唯一键,用于查询、去重(如订单ID) | 邮件"追踪号" |
最佳实践:
- Topic 按业务域划分(如
Order,Payment,User)。 - Queue 数量 = 消费并发度上限(建议 8~32 个,根据业务调整)。
- 同一业务用同一个 Consumer Group,避免重复消费。
四、消息全流程:从发送到消费
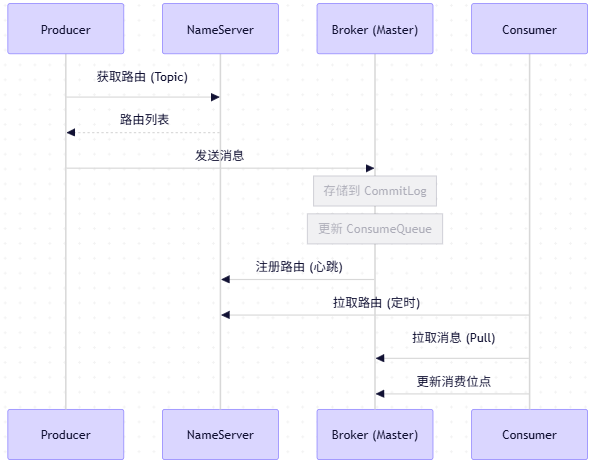
关键点:
- Producer/Consumer 与 NameServer 是"查询关系",非强依赖。
- Broker 是消息存储与转发的核心,需保证高可用。
- Consumer 主动 Pull,可控制消费速度(背压机制)。
五、高级特性与生产实践
1. 顺序消息(Orderly Message)
保证同一业务 ID(如订单ID)的消息按发送顺序消费。
实现:Producer 按 shardingKey 选择固定 Queue,Consumer 单线程消费该 Queue。
场景:订单创建 → 付款 → 发货 → 完成。
2. 事务消息(Transactional Message)
实现"本地事务 + 消息发送"的最终一致性。
流程:发送 Half 消息 → 执行本地事务 → Commit/Rollback → Broker 回查(若超时)。
场景:扣库存 + 发订单消息。
3. 延迟消息(Delay Message)
消息发送后,延迟指定时间才对 Consumer 可见。
级别:支持 18 个固定延迟级别(1s ~ 2h)。
场景:订单超时未支付自动取消。
4. 死信队列(DLQ - Dead Letter Queue)
消费失败超过最大重试次数(默认 16 次)的消息,进入死信队列。
Topic :
%DLQ% + ConsumerGroupName处理:人工干预或定时任务补偿。