引言
详解磁盘基本构造和工作原理
磁盘的基本构造
磁盘的大部分空间都是磁性材料,这些材料可以被磁化为两个不同的方向,一个方向代表1,另一个方向代表0,多个磁性单元组成一个单元用于表示1bit,也正是通过这样无数个磁性单元构成一张可以存储大量数据的磁盘:

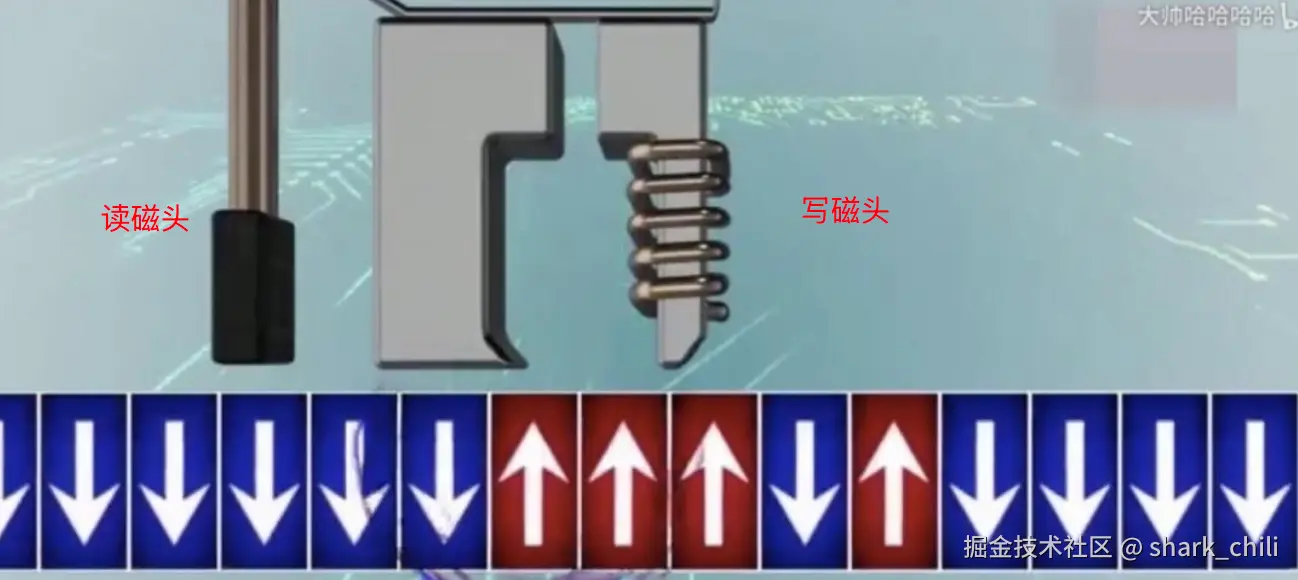
然后就是机械硬盘的另一个组成部分------磁头,当需要进行数据读写时,磁盘就会转动将目标数据对应的位置定格在磁头上(常见转速为每分钟5400转或7200转),同时为避免磁头刮坏磁盘,二者的距离设置非常小。
而磁头是由读写磁头两个部分构成,针对读时,读磁头就会通过电磁技术感知磁盘磁性单元的极性确定数值是0还是1,同理针对写时,即通过写磁针修改磁性单元的极性完成二进制数值0或1的修改。
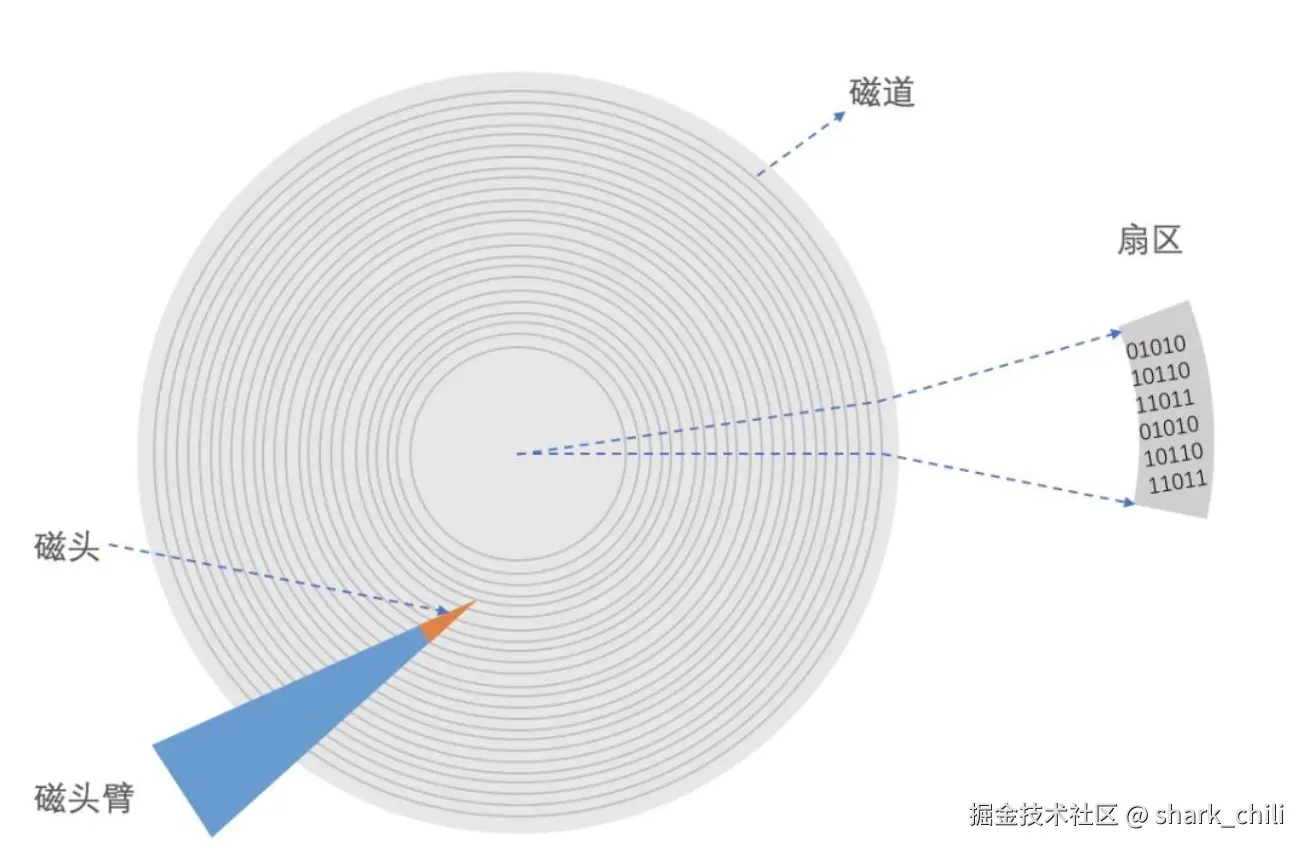
最后一个核心的部分也就是扇区,磁盘是由多个圆盘堆叠构成,每个圆盘又有无数个同心圆也就是磁道,每个磁道进行切割划分构成了扇区,传统扇区大小为512字节,现代硬盘多采用4096字节(4K)扇区。但针对外部磁道扇区密度不均衡的问题就导致了外圈扇区数据稀疏从而导致资源利用率不高,所以后续的优化就将外圈的扇区数均等切割成更多的扇区保证这些空间数据发布密集均匀:
操作系统下磁盘数据读写的工作流程
有了上述几个核心部分的了解,我们不妨串联一下这些概念梳理出磁盘的读写过程,假设我们现在要进行数据读,对应的步骤为:
- 驱动程序基于数据定制定位到盘面、磁道号、扇区编号
- 磁头移动定位到对应的磁道上,这个过程也叫寻道
- 磁盘转动定位到对应的扇区
- 完成数据读取
磁盘管理的哲学
操作系统对于数据单位的抽象
磁盘读取基本单位为扇区,传统大小为512字节,现代硬盘多为4096字节。而操作系统的计量单位则是块(block),通常为4KB大小,所以为什么说我们即使读取1字节的文件也要使用4KB的磁盘空间。这一点,我们可以通过stat -f命令查看:
css
sharkchili@DESKTOP-0F6E7K1:~$ stat -f /
# 查看文件系统信息
# File: "/" # 检查的文件系统挂载点
# ID: 1bce3e168ac7b648 # 文件系统标识符
# Namelen: 255 # 文件名最大长度
# Type: ext2/ext3 # 文件系统类型
# Block size: 4096 # 文件系统块大小为4096字节(4KB)
# Fundamental block size: 4096 # 基本块大小为4096字节(4KB)
# Blocks: Total: 263940717 # 总块数: 263,940,717个
# Free: 262373060 # 空闲块数: 262,373,060个
# Available: 248947192 # 可用块数: 248,947,192个
# Inodes: Total: 67108864 # 总Inode数: 67,108,864个
# Free: 67040061 # 空闲Inode数: 67,040,061个
File: "/"
ID: 1bce3e168ac7b648 Namelen: 255 Type: ext2/ext3
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 263940717 Free: 262373060 Available: 248947192
Inodes: Total: 67108864 Free: 67040061如何进行数据块信息的管理
上述4KB构成一个块,为了记录块的使用情况,操作系统在磁盘特定位置专门使用一块空间记录块的使用情况也就是我们常说的位图索引,1bit代表一个块,0表示空闲,1表示已使用,一般情况下这个块位图位于文件系统的特定区域:
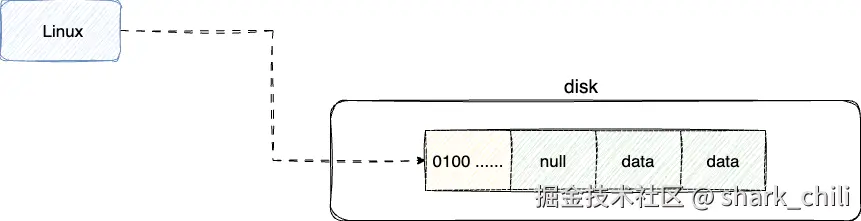
但是硬盘空间非常庞大,所以定位某个单位块若采用扫描这种方式是非常低效的,所以我们就需要记录对应数据的元信息,于是就考虑使用一个名为inode的数据结构记录文件的物理元信息,而每个inode大小因文件系统而异,常见大小为128或256字节,存储的元信息包含:
- 数据占用物理空间
- 块起始号
- 数据块数量
- 权限
- 时间

我们可以通过Linux的stat指令查看inode文件的详情,例如我们在tmp文件夹下有一个file文件,内部包含数据hello world,我们就可以执行stat指令查看,此时我们就可以看到:
- 文件大小12字节
- 占用8个磁盘块
- inode起始编号为6744
- 访问权限0664
- 修改时间、创建时间等信息
css
sharkchili@DESKTOP-0F6E7K1:/tmp$ stat file
File: file
Size: 12 Blocks: 8 IO Block: 4096 regular file
Device: 8,48 Inode: 6744 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/sharkchili) Gid: ( 1000/sharkchili)
Access: 2025-09-13 17:07:21.291934846 +0800
Modify: 2025-09-13 17:08:12.992226483 +0800
Change: 2025-09-13 17:08:12.992226483 +0800
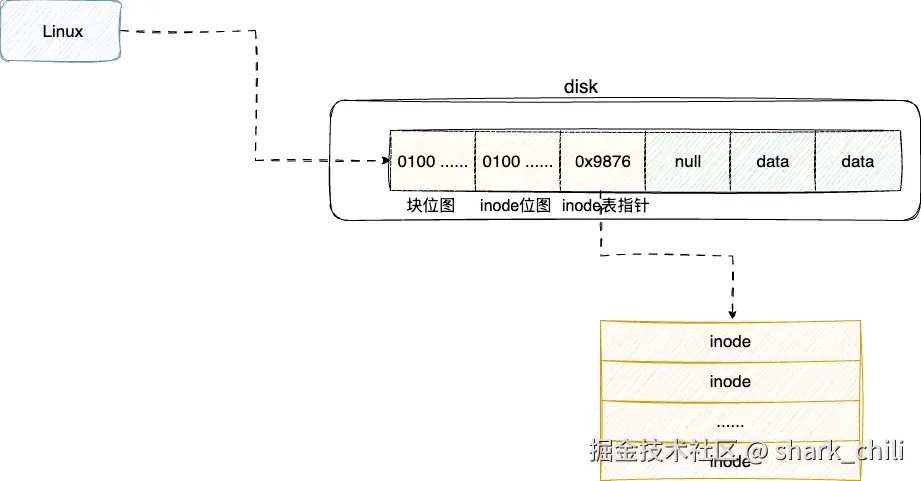
Birth: 2025-09-13 17:07:21.291934846 +0800由此无数个文件就基于这些inode构成一张inode表,同时考虑到inode块定位的效率,在块位图之后又补充了一个inode块位图,同时也将inode表追加在inode块位图后面:
大文件空间管理
通过上述一系列数据结构我们可以很好管理磁盘空间并保证读写效率,但由此也衍生了两个问题:
- 磁盘空间分配
- 大文件元信息存储
我们先来说说问题1,针对文件的磁盘空间分配整体方向就是两个,连续分配和非连续分配,前者对于文件数据读取友好但是存在磁盘碎片问题,试想这样一种情况,经过连续分配我们的磁盘空间存在两个非连续的磁盘块,此时我们需要存储一个文件大小为4097字节的文件,因为磁盘块每个大小都是4096字节,按照连续分配法,我们就必须要有一个连续两个磁盘块的磁盘空间,所以这种文件分配策略下,文件就无法存储到磁盘,这两个非连续的空闲空间就无法被使用,变成空洞块,导致磁盘碎片:
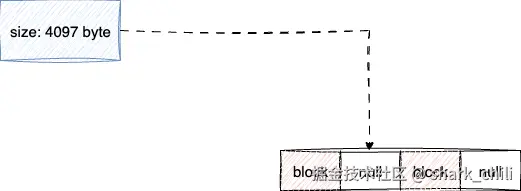
所以设计者们为了最大化利用磁盘空间,采用非连续分配,由此就有了问题2的探讨------如何维护大文件信息。大文件元信息维护,要知道现在的大文件动不动就是几个G,所以一个inode只有128或256字节,如果直接记录磁盘块信息,最多只能记录少量磁盘块,无法完整维护一份大文件的元信息,所以inode在原有基础上抽象出指针指向全新的数据块,即通过间接索引指向的空间继续存储其他磁盘块的信息以保证记录大文件:
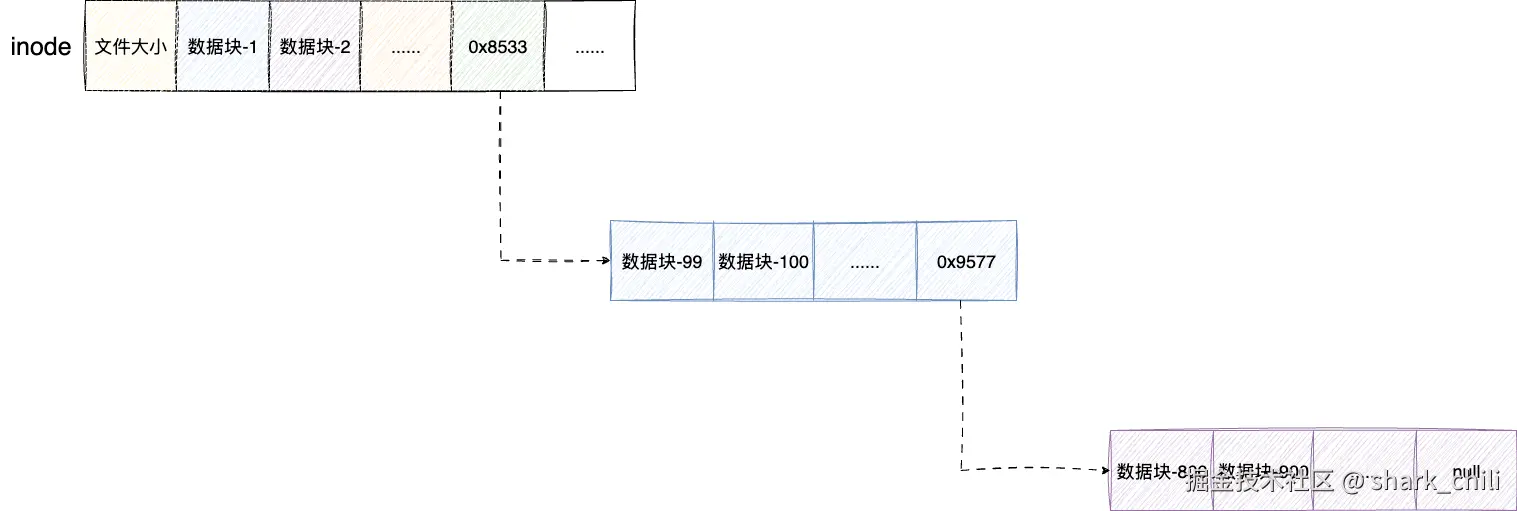
文件索引
自此我们解决了文件存储和文件元信息维护问题,接下来我们再说说文件的索引,对于文件的定位从使用者的角度来看,自然是希望基于文件名的方式定位而非inode号,所以我们针对文件名和inode(如果是大文件就和第一个inode建立映射)建立映射,于是我们就有了一张记录文件名和对应inode映射,这就是操作系统中目录的概念:

基于这个思路我们再继续分析,要知道操作系统中的文件可能有数亿个,所以为了提升检索效率,我们打算将目录分层,即根目录下挂着目录项或者又一个子目录,如此一级一级层次下推构成一个树结构的目录,通过根目录我们就可以定位到对应的文件名的inode:
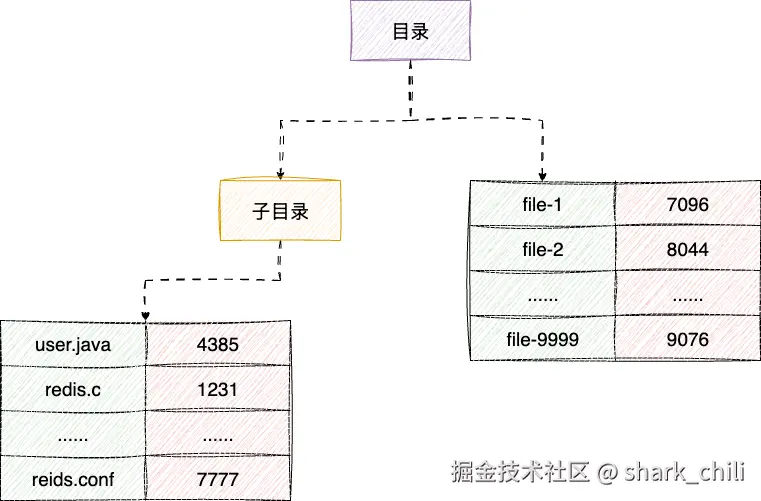
最后再把这个根目录对应的文件维护到inode表的开头位置,后续就可以顺着这个目录进行文件映射inode读写操作了。
操作系统下不同分区管理的哲学
最后一个问题,如何构建一张检索高效且可以记录整个磁盘数据对应inode信息的inode表,之所以这么问,是因为一个磁盘块4KB,而一个inode项大小为128或256字节,对应4096/128=32或4096/256=16这意味着单个块只能维护16或32个inode。所以我们就需要多个块才能构建出一个大的inode表。于是我们在原有基础上添加一个块专门记录inode表使用的数据块,这就是我们常说的inode表块指针:

基于这个问题,我们也联想到块位图,一个块位图对应4KB,假设1个bit代表一个磁盘块,对应4096*8也就是32768个磁盘块,对应128M,这很明显也不够的。于是文件系统就考虑到将磁盘空间的块进行划分,把一组相关的块当作一个块组,这些块组交由组描述符进行统一管理,如下图,多个块构成块组,包括块位图、inode块位图、inode表等,原本描述全局的inode表项的描述符变为组描述符统一管理这个块组。
与之对应操作系统若想知道块组的使用情况,于是在第一个块组中添加一个超级块记录整个文件系统的元信息,而其他块组则是拷贝这份信息作为冗余:
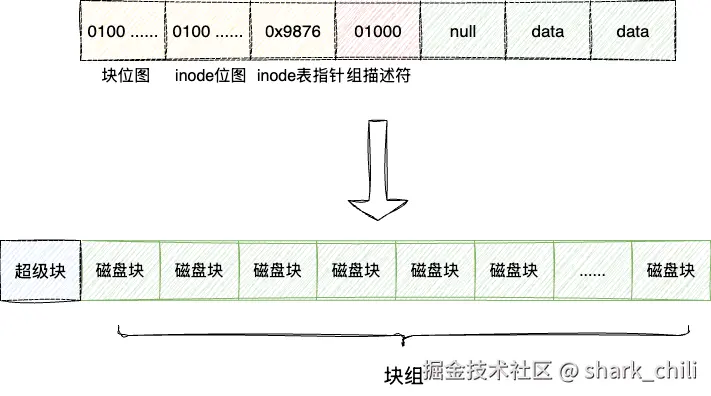
最后操作系统存在多分区,所以:
- 每个分区对应多个块组
- 每个分区对应一个启动扇区(boot sector),作为安装操作系统时写入引导程序的位置
汇总上述信息,以操作系统分区3为例,对应的逻辑结构如下,即一个分区对应引导块和块组,每个块组由组描述符统一维护各种元信息:
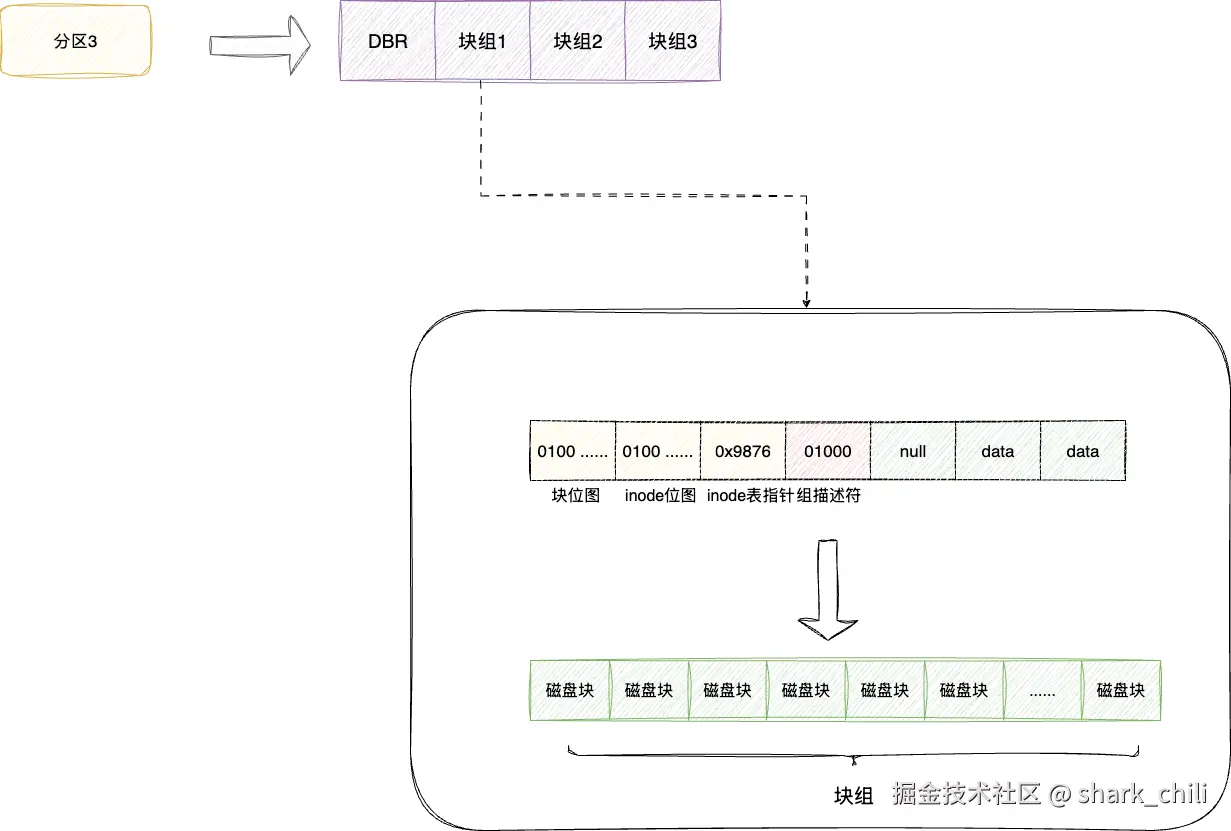
最后为了维护各个分区的元信息,在硬盘的第一个扇区作为MBR(Master Boot Record),引导系统启动加载和管理这些分区。

现代存储设备的发展
固态硬盘(SSD)
随着技术的发展,固态硬盘(SSD)逐渐成为主流存储设备之一。与传统机械硬盘(HDD)不同,SSD使用闪存芯片存储数据,具有以下特点:
- 无机械运动部件,读写速度快
- 功耗低,噪音小
- 随机访问性能优异
- 但存在写入寿命限制和写入放大问题
日志结构文件系统
现代文件系统如日志文件系统(Journaling File System)通过引入日志机制来提高文件系统的可靠性,当系统崩溃时可以通过日志恢复数据一致性。
小结
最后我们再来自底向上的总结一下本文知识点:
- 磁盘通过磁性材料维护数据、通过磁头寻址读写,磁盘由多个圆盘构成,每个圆盘对应磁道,磁道划分为扇区进行管理,传统扇区大小为512字节,现代硬盘多为4096字节
- 操作系统以磁盘块为单位管理磁盘扇区,每个磁盘块通常为4096字节
- 操作系统通过块位图统一管理磁盘块空闲空间
- 每个文件可能用到多个磁盘块,所以通过inode信息维护文件使用的磁盘块和元信息
- 操作系统通过inode表统一管理维护inode信息
- 为方便用户检索文件,通过目录维护文件名和inode映射,同时为了管理更多的文件,引出目录和子目录的层次结构
- 为方便统一管理磁盘空间,将磁盘块分为多个块组独立管理,这样就缩小了inode、块位图、inode位图的管辖范围
- 操作系统分为多分区,所以每个分区划分几个块组,并添加一个引导扇区作为操作系统安装引导程序的数据块
- 操作系统通过MBR作为引导块统一管理多分区
- 现代存储技术如SSD和日志文件系统进一步提升了存储性能和可靠性
参考
《趣话计算机底层技术》
Linux的i节点(inode) 和 数据块(Block)相关操作详解:blog.csdn.net/lianghudrea...
本文使用 markdown.com.cn 排版