文章目录
前言
本节我们将学到以下内容:
- 通过proc目录查看进程信息,知道当前路径是当前进程的工作路径
- 通过ps指令查看进程信息
- 在命令行中创建的进程都是bash的子进程
- 通过系统调用fork创建子进程,fork之后父子进程的task_struct、代码和数据的关系
- 关于fork返回值的三个问题
一、查看进程
我们在上一节了解了进程相关概念后,相信大家对于到底什么是进程还是不太理解,接下来小编通过一些实践操作带大家来深入认识一下进程。
用proc目录查看进程
下面小编写一个简单的死循环程序:
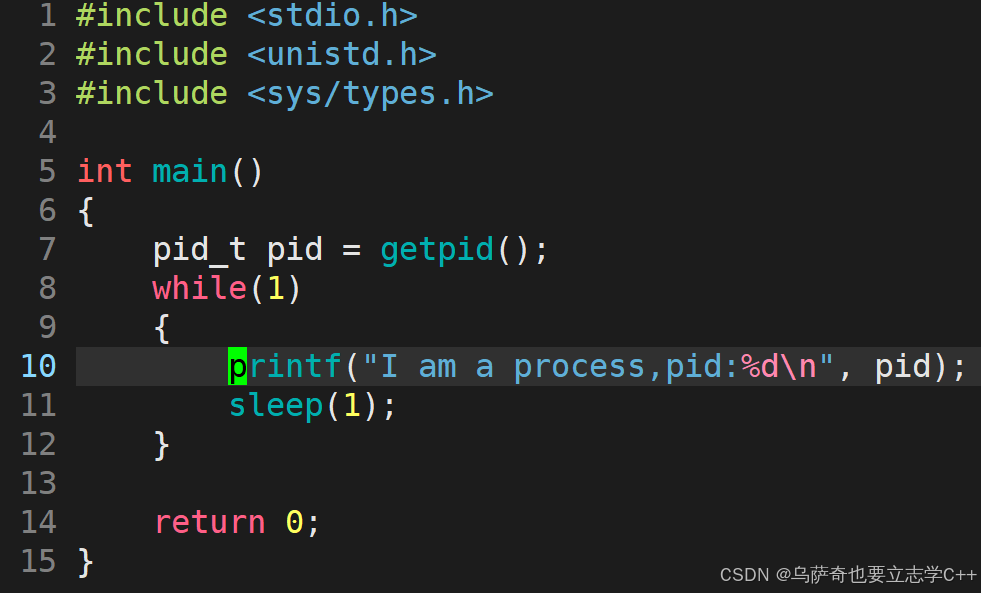
1、sleep(1)会让程序休眠1秒,使用它需要包含头文件unistd.h。
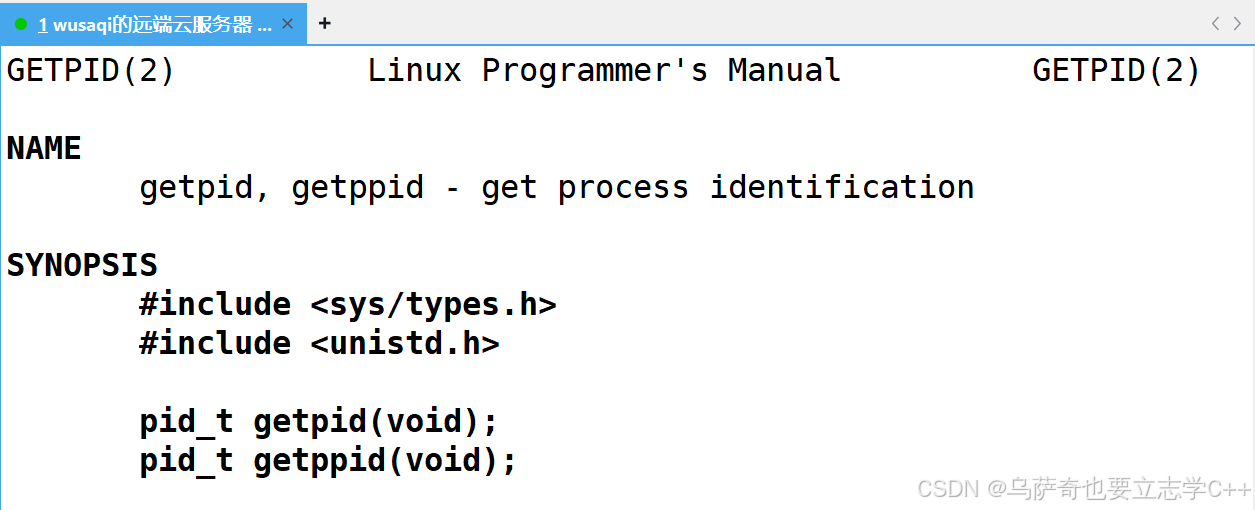
2、getpid是我们认识的第一个系统调用函数,可以获取当前进程的pid,需要包两个头文件,pid_t类型是系统定义的一个无符号整数类型,细节如下:
下面我们把这段代码编译并运行一下:

这里我们可以先下一个定义,这个用./运行起来的文件就是一个进程。
那么我们要如何查看这个pid为14158的进程呢?方法是在根目录下有一个proc目录,里面会将系统启动的所有进程信息文件化,所以我们可以通过这个目录查到启动的进程信息。
下图中的每一个蓝色数字都是一个正在运行的进程,我们的14158也在里面。
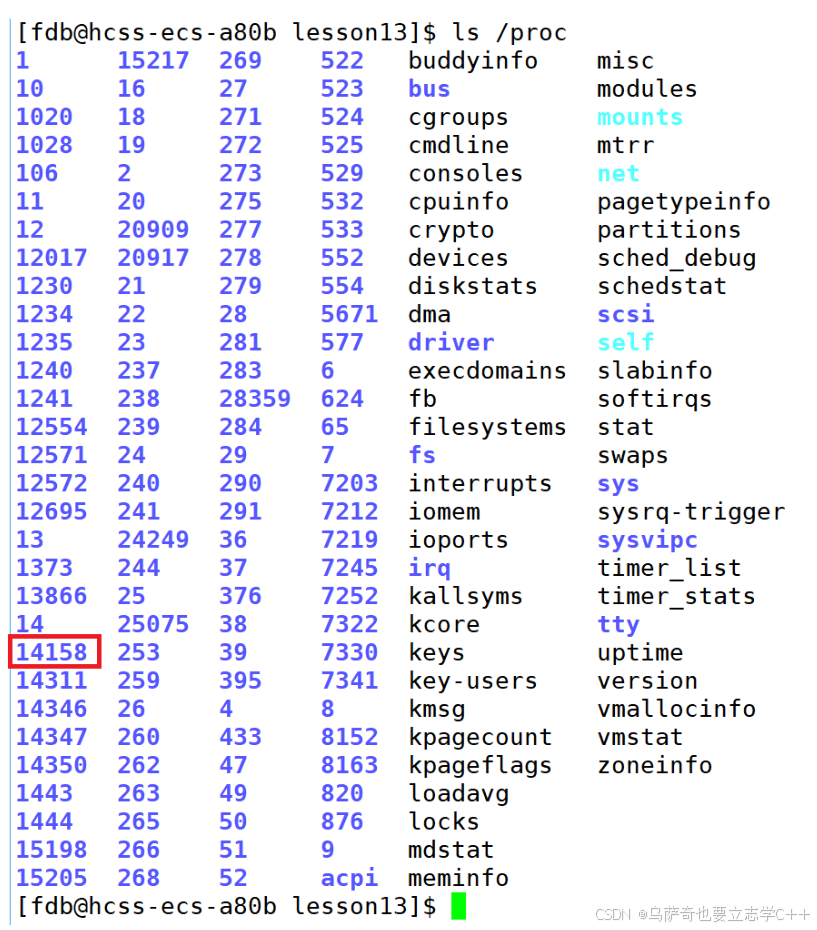
当我们使14158进程结束后,/proc目录里对应的进程文件也就消失了:

当我们重新启动该程序系统又会给启动的进程重新分配一个不一样的pid,这和我们的理解相符,小编不再多说了。
然后给大家介绍进程的两个属性,通过我们前面介绍的proc目录查看进程详细属性:
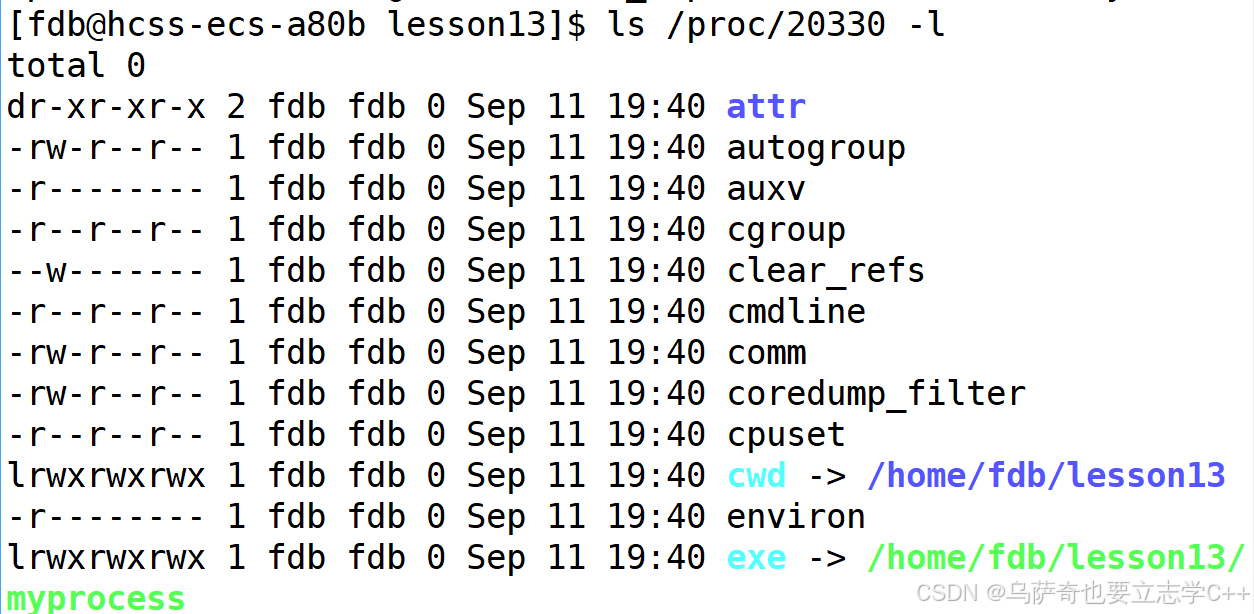
这里的exe后面的/home/fdb/lesson13/myprocess是可执行文件 myprocess 在磁盘上的存储路径,说明进程属性里会记录自己所对应磁盘二进制文件的路径,也就是说当一个进程运行的时候它会知道自己是怎么来的,加载的是磁盘里的哪一个程序。
cwd(Current Working Directory)后面跟的/home/fdb/lesson13是当前进程的工作路径。所以这里可以得出一个结论,进程启动的时候,默认工作路径就是自己可执行程序所处的路径。这个进程默认工作路径就是我们在介绍文件操作时说的当前路径。
上面示例以写的方式打开一个没有指定路径的文件例如这里的test.txt时,之前的说法是如果test.txt文件不存在的话就会在当前路径下新建一个test.txt文件,这里的当前路径就是进程的工作路径,也就是说test.txt会在该进程的工作路径中创建。
进程的默认工作路径是可以进行修改的,修改后我们新建文件就不会在进程默认工作路径下新建,而是新建在我们修改后的文件中。修改进程当前工作路径需要用到chdir指令:

这也是一个系统调用,参数是修改后的工作路径字符串,调用成功返回1,失败返回0,示例如下:
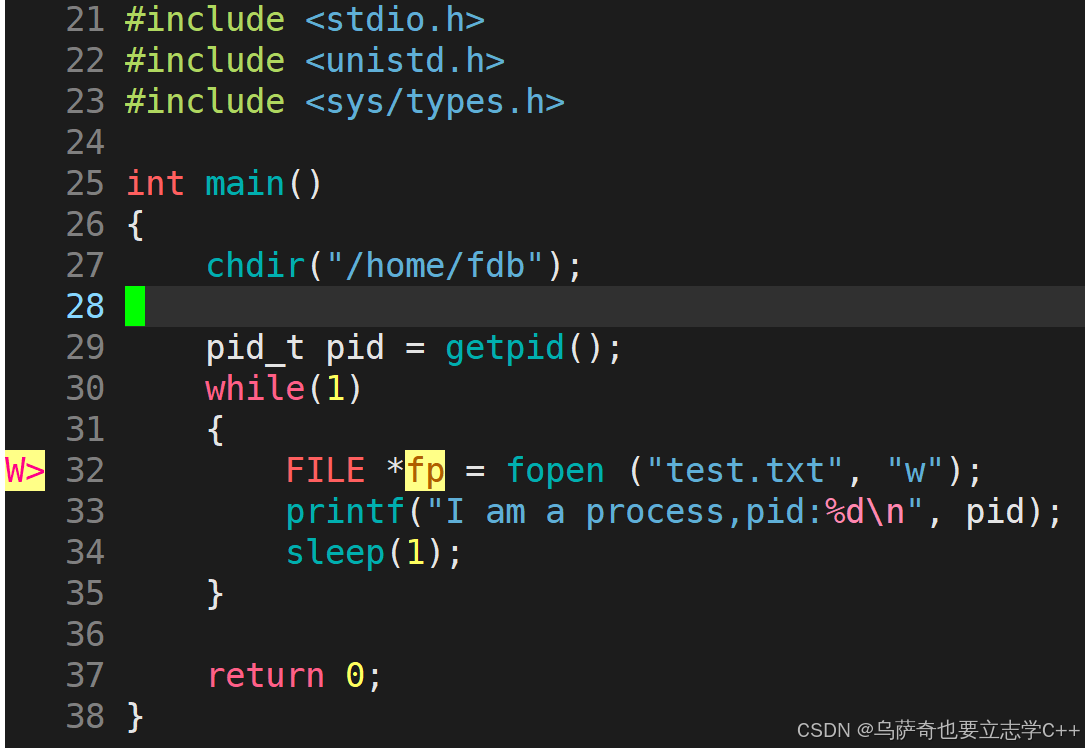
运行上面程序后我们通过proc看该进程的工作路径确实改成了我们的指定路径。
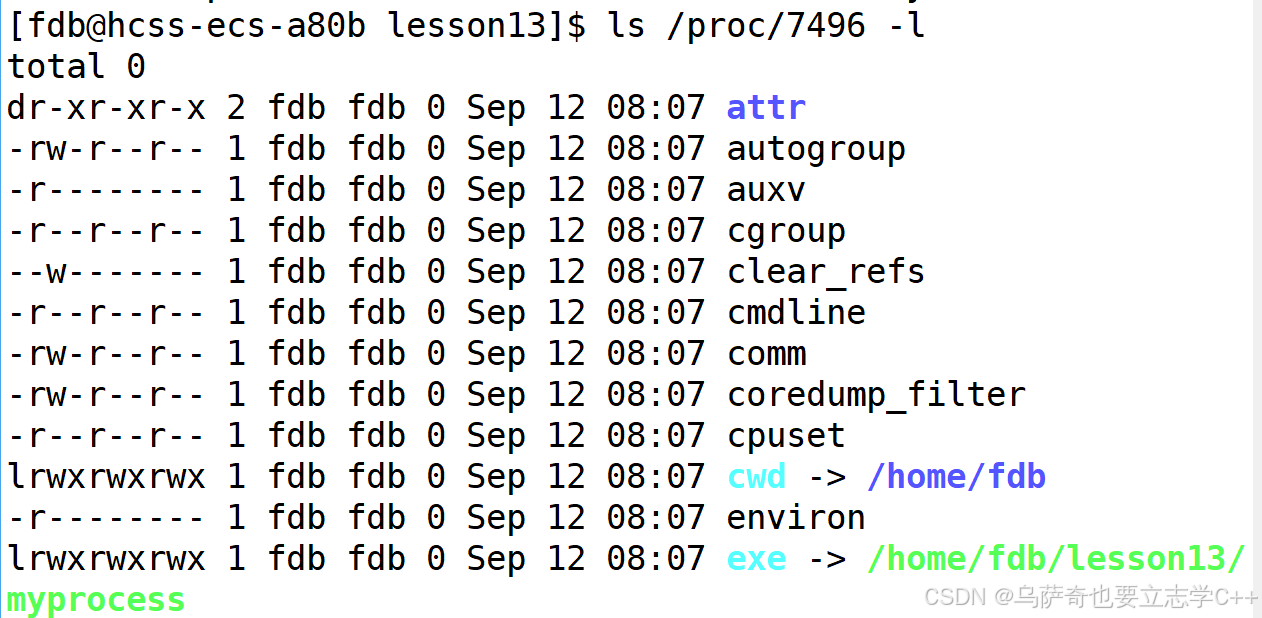
并且test.txt文件也在该路径下打开了。
用ps指令查看进程
前面用proc指令查看进程的方式并不常用,更常用的方式是用ps指令查看进程,具体指令如下,因为我们目前还有许多知识不具备,所以指令的具体细节目前小编还无法解释。(这里小编避免冲突把可执行程序文件名字由myprocess改成了myprocess.exe)
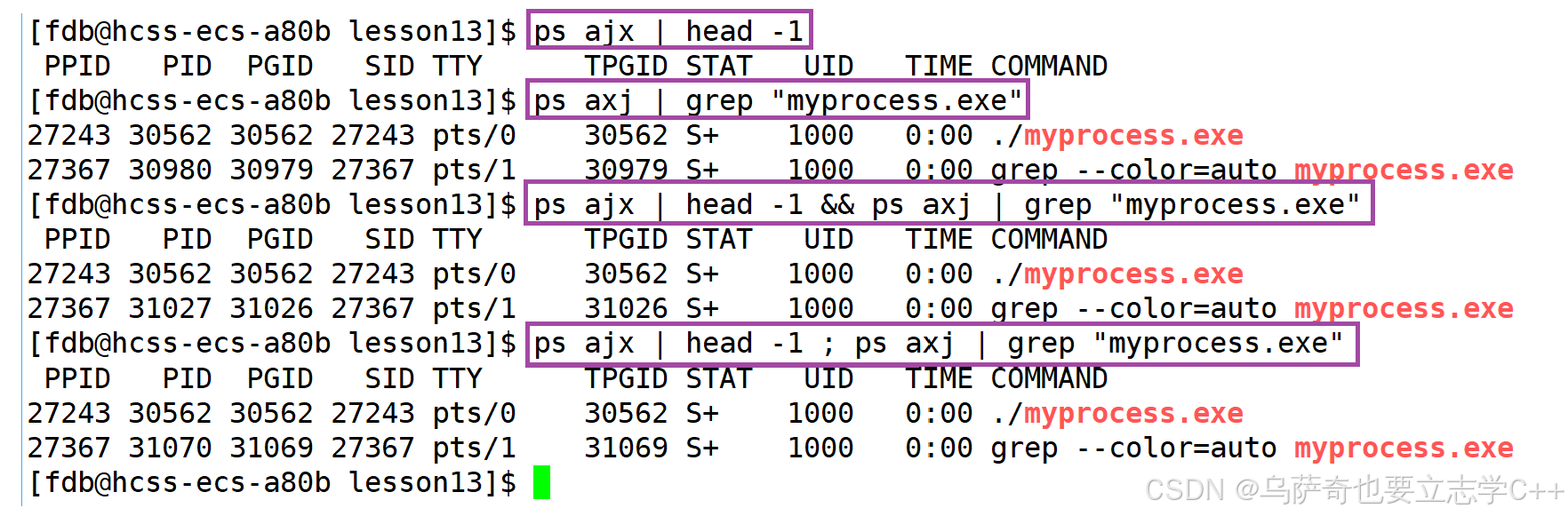
这里的axj和ajx顺序没有影响。
1、ps ajx | head -1 是打印出进程属性第一行的标题。
2、ps axj | grep "myprocess.exe" 是打印出进程的属性信息,其中ps axj会打印出当前进程的所有属性信息,如果只想查看我们自己启动的进程就需要用管道加grep过滤出包含要查看进程关键字的进程。
3、当我们想把上面含管道的指令拼在一起,先执行左边的再执行右边的就需要用&& 或 ; 将它们两个拼一起。
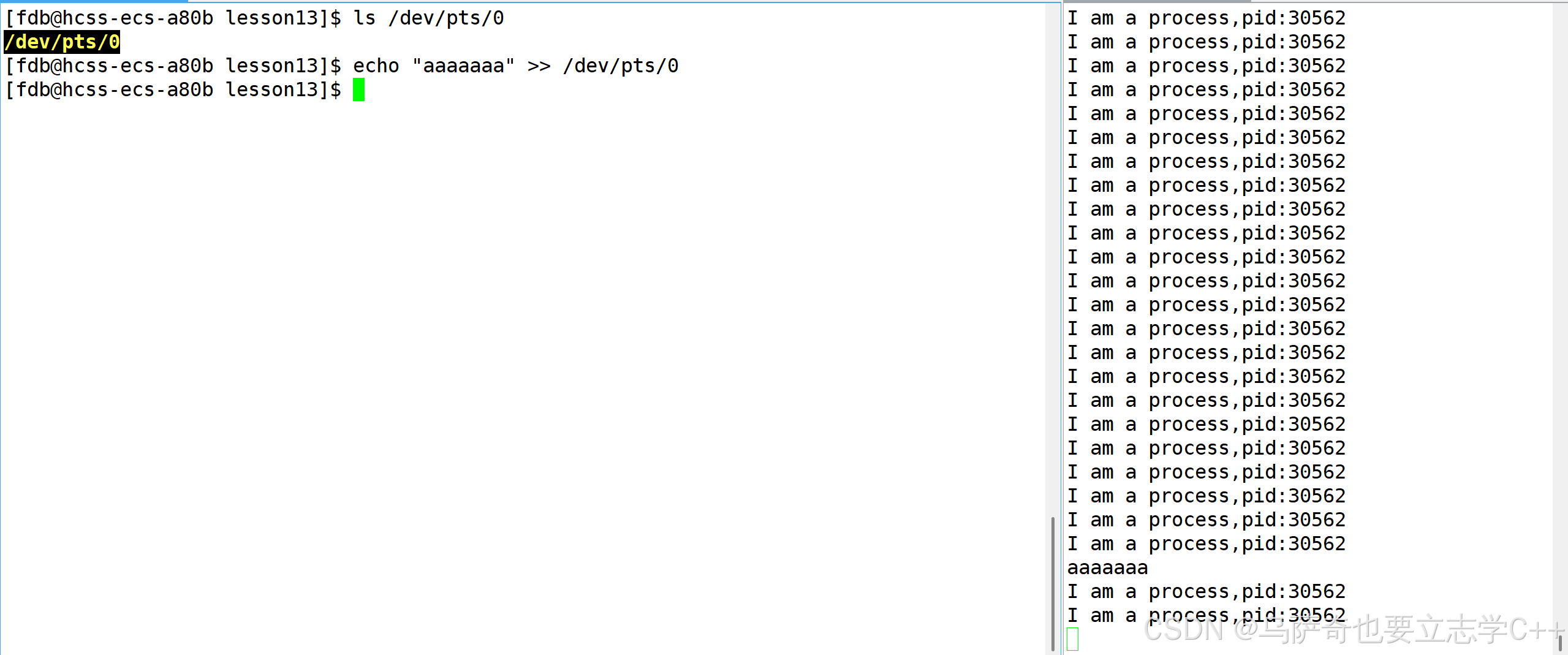
4、pts/0 和 pts/1是两个显示器文件,我们的进程启动后打印信息都是默认往这两个文件打印,这两个文件的路径如下,所以我们可以也可以往这两个显示器文件里打印信息:
PPID:
我们可以看到在进程属性中还有一栏PPID,这是当前进程的父进程pid,获取父进程pid需要用到系统调用getppid:
linux系统中的所有进程都是通过父进程创建的,所以每一个进程属性里都会保存自己父进程的pid。
cpp
#include <stdio.h>
22 #include <unistd.h>
23 #include <sys/types.h>
24
25 int main()
26 {
27 // chdir("/home/fdb");
28
29 pid_t pid = getpid();
30 pid_t ppid = getppid();
31 while(1)
32 {
33 FILE *fp = fopen ("test.txt", "w");
34 printf("I am a process,pid:%d, ppid: %d\n", pid,ppid);
35 sleep(1);
36 }
37
38 return 0;
39 }我们将上面代码运行后的结果如下所示:

上图运行结果我们可以看到子进程pid是一直在变化的,但是为什么它的父进程一直不变呢?我们通过pc指令来查看一下这个父进程的详细属性:

原来32491这个pid所对应的进程是bash,怪不得父进程一直没有变。这里我们可以推导出一个结论,所有在命令行启动的进程都是通过bash这个父进程创建的,由此可以推出所有指令对应的进程也是由bash创建的。
二、fork初识
前面我们已经学习了进程的部分属性以及通过系统调用查看一个进程及父进程的pid,接下来我们来聊聊一个进程究竟是如何创建子进程的。所有进程创建子进程都需要用到一个系统调用:
fork,包括bash创建子进程,fork信息如下:

我们先不看fork的返回值,实际上手使用一下fork,下面小编创建了一个示例:
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("我是一个进程,pid:%d, ppid:%d\n", getpid(), getppid());
fork();
sleep(1);
printf("你能看到我这条消息吗? pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}运行结果如下:

我们可以看到示例代码运行的可执行程序进程所对应的pid是19162,它的父进程bash的pid是15880,当我们使用系统调用fork函数后出现了一个由该进程创建的子进程,pid是19163,所以fork确实可以实现创建子进程的功能。
fork返回值
我们先看文档关于fork返回值的介绍:

若子进程创建成功,会把子进程pid返回给父进程,把0返回给子进程,若子进程创建失败,会把-1返回给父进程,因为子进程创建失败,会在合适的位置放置错误码。
示例代码如下:
成功创建子进程的运行结果如下:
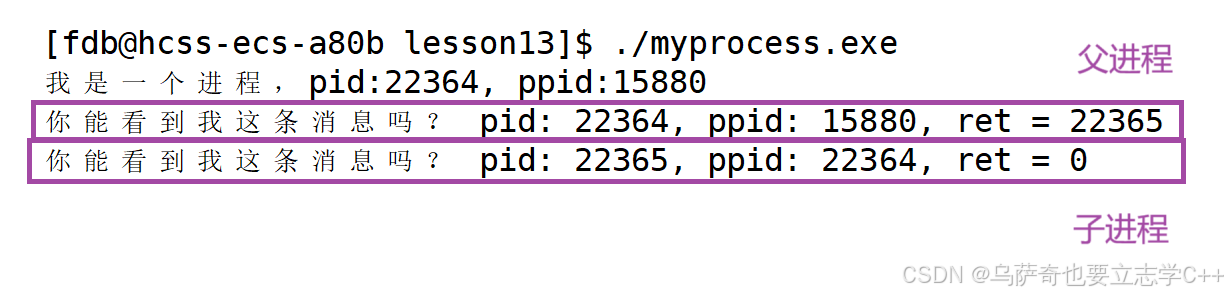
结果确实如文档所说,看到这里我相信大家心里肯定都有不少疑惑,比如:
1、fork返回值为什么是这样的?给父进程返回子进程pid,给子进程返回0. 2、一个函数怎么可能会有两个返回值?
3、一个变量怎么可能同时等于0,又大于0? 比如上面示例的22365。
前两个问题小编可以在这里解答,但是第三个问题需要我们学习了进程地址空间后才能理解,所以小编在本节不会解释第三个问题。问题一:
在linux系统中,父进程对子进程是一对多的,也就是父进程可以有多个子进程,但是子进程有且只有一个父进程,所以通过子进程找父进程很简单,但是通过父进程找子进程很麻烦,所以系统通常会在父进程里保存每一个子进程的pid,这样父进程就可以找到并控制它的每一个子进程。给子进程返回0是为了区分父子进程的身份,让代码能通过返回值区分当前执行流是子进程还是父进程,例如if (pid == 0) { /* 子进程逻辑 */ } else { /* 父进程逻辑 */ })
问题二:在解答第二个问题之前,我们先铺垫一些概念或者原理。在linux中,创建一个子进程时它的task_struct和子进程的代码和数据都需要被初始化,子进程的task_struct的初始化策略是以父进程的task_struct为模板,也就是把父进程的task_struct拷贝一份给子进程,然后修正个别子进程特有的属性。而子进程的代码和数据初始化策略和task_struct不同,我们知道父进程的代码和数据是通过磁盘加载来的,而创建子进程时系统一般不会进行二次加载,也就是说子进程创建出来时是默认没有代码和数据的,所以系统默认会让子进程和父进程共享代码和数据(共享代码可以保证,共享数据并不准确,后面会修正)。
有了上面的认识后,我们把理论用在实践,小编下面创建一个多进程的代码示例:
cpp
int main()
{
printf("我是一个进程,pid:%d, ppid:%d\n", getpid(), getppid());
pid_t ret_id = fork();
if(ret_id < 0)
{
//子进程创建失败
perror("fork");
return 1;
}
else if(ret_id == 0)
{
while(1)
{
printf("我是子进程 pid: %d, ppid: %d, ret = %d\n", getpid(), getppid(), ret_id);
sleep(1);
}
}
else
{
while(1)
{
printf("我是父进程 pid: %d, ppid: %d, ret = %d\n", getpid(), getppid(), ret_id);
sleep(2);
}
}
}运行结果如下:
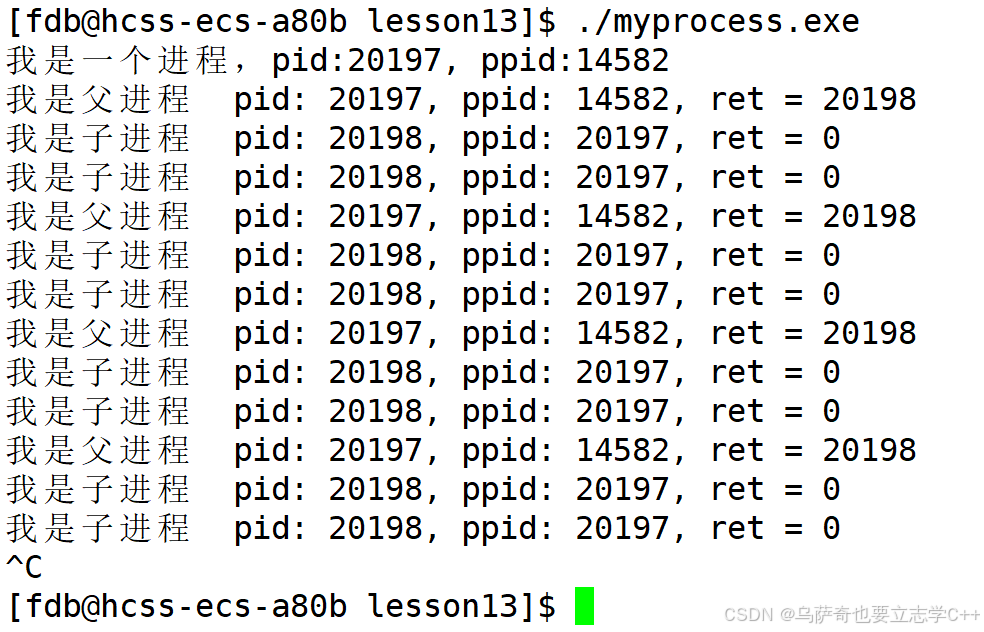
正是因为fork函数对于父子进程的返回值是不同的、fork之后父子进程共用同一段代码,所以我们可以在 fork之后通过if else语句对于fork不同返回值的处理,让父子进程执行不同的代码区域,从而让父子进程执行不同的任务。
有了上面的铺垫,接下来小编来回答第二个问题:一个函数怎么可能会有两个返回值?
首先我们知道fork函数执行之后父子进程会共享同一份代码,当我们再聚焦fork函数内部,它的函数主体功能是创建子进程,最后一句代码是return id,也就是说在fork函数完成创建子进程之后程序走到return id时已经同时存在父和子两个进程执行流了,而return id 本身也是一个语句(代码),所以父子进程会共用这个语句,父进程会执行return id,子进程也会执行return id,所以就会出现一个函数有两个返回值。
以上就是小编分享的全部内容了,如果觉得不错还请留下免费的关注和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
