在现代的数据库管理中,MySQL 作为广泛应用的关系型数据库管理系统,其性能优化显得尤为重要。随着数据量的不断增大,查询效率逐渐成为决定系统响应速度和用户体验的关键因素。MySQL 的优化不仅仅是单一的查询性能问题,更涉及到硬件配置、索引策略、数据库架构设计等多个方面。本文将从常见的 SQL 查询优化、硬件资源利用、索引使用、数据库配置调整等多个角度出发,详细探讨如何有效提升 MySQL 数据库的性能。

- 不要查询不需要的列
- 不要在多表关联返回全部的列
- 不要select *
- 不要重复查询,应当写入缓存
- 尽量使用关联查询来替代子查询。
- 尽量使用索引优化。如果不使用索引。mysql则使用临时表或者文件排序。如果不关心结果集的顺序,可以使用order by null 禁用文件排序。
- 优化分页查询,最简单的就是利用覆盖索引扫描。而不是查询所有的列
- 应尽量避免在 where 子句中使用 !=或<> 操作符,否则将引擎放弃使用索引而进行全表扫描。
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:

csharp
select * from user where name is null- 尽量不要使用前缀%
sql
select * from user where name like '%a'- 应尽量避免在 where 子句中对字段进行表达式操作
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
- 很多时候用 exists 代替 in 是一个好的选择:
btree索引
B-TREE索引适合全键值、键值范围、前缀查找。
全值匹配,是匹配所有的列进行匹配、
匹配最左前缀。比如 a=1&b=2 那么会用到a的索引
匹配列前缀。 比如 abc abcd %abc
匹配范围 比如 in(3,5)
限制
- 如果不是左前缀开始查找,无法使用索引 比如 %aa
- 不能跳过索引的列。
- 需要中,含有某个列的范围查找,后面的所有字段都不会用到索引
索引的优点
1、减少服务器扫描表的次数
2、避免排序和临时表
3、将随机io变成顺序io
高性能索引策略
- 1、使用独立的列,而不是计算的列
where num+1 =10 //bad
where num = 9 //good
- 2、使用前缀索引
- 3、多列索引,应该保证左序优先
- 4、覆盖索引
- 5、选择合适的索引顺序
不考虑排序和分组的情况。在选择性最高的列上,放索引,
- 6、使用索引扫描来排序
mysql有两种方式生成有序的结果,一种是排序操作,一种是按索引顺序扫描,如果explain处理的type列的值是index。则说明mysql使用了索引
只有当索引的列顺序和order by子句的顺序一致的时候,并且所有的顺序都一致的时候。mysql才能使用索引进行排序。
不能使用索引的情况
- 1.查询使用了两种排序方向
sql
select * from user where login_time > '2018-01-01' order by id des ,username asc #- 2.order by中含有了一个没有 索引的列
sql
select * from user where name = '11' order by age desc; //age 没有索引- 3.where 和 order by 无法形成最左前缀
- 索引列的第一列是范围条件
- 在索引列上有多个等于条件,这也是一种范围。不能使用索引
服务器层面
编辑
服务器调优,通过修改配置。提升硬件水平配置
sql
1.最大连接数,并发选项
show variables like 'max_connections';
在my.cnf配置文件中可以修改
2.innodb的缓冲池大小,innodb_buffer_pool_size
innodb的很多的元素,都会缓存到该缓冲池中
show variables like 'innodb_buffer_pool_size';
官方建议设置为物理内存的80%
3.MyISAM的索引缓存, key_buffer_size
show variables like 'key_buffer_size';部署层面
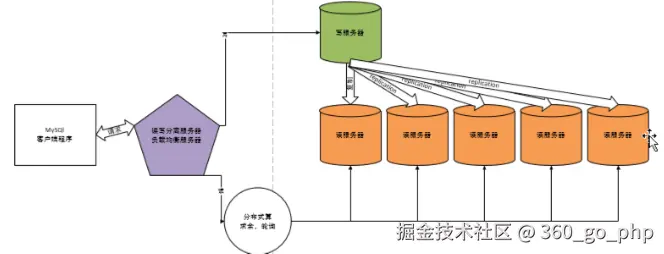
多台MySQL服务器,作用于项目读写分离
makefile
将读操作与写操作分离开。 典型的web项目,读密集型项目。
读写比:7:1到9:1
典型的情况: 少量的写服务器,大题的读服务器。最基本的架构模式:一写对多读。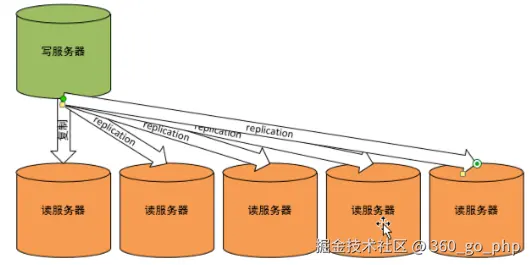
编辑
需要的技术:复制技术(replication)。
负载均衡
编辑
以上的项目:高可用
相对的:高可用概念
稳定。核心实现就是冗余
SQL层面
select * // 少用
获取需要的数据即可!limit 1 // 多用
count(*) 的处理
scss
针对innodb的引擎,一定要处理count(*)问题
增加额外的数据,记录该总的记录数
例如:
放在缓存中。memcached,每当学生数量变化,修改该缓存。
放在数据表中,新建独立的表,存储学生数量
对于MyISAM引擎 不用考虑count(*)的问题。会自动记录总的记录数order by null, 不排序
csharp
不排序的含义。
我们在使用group by的时候,数据会默认按分组字段来排序order by rand(), 随机排序 不要使用
scss
排序过程:
计算**每条记录的rand()**随机数
要想实现该业务逻辑:
在PHP程序,随机10次,生成10次主键,通过主键查询limit,大页码的处理
bash
select * from table where cond limit 1000,10;
MySQL实现逻辑:
获取复合条件的1000条记录,跳过前990条,只需要10条
select * from kang_student limit 2000000,10;
随着页码数的增加,所需要的时间被拉长
实操中:
尽可能做条件过滤
下一页操作:
第一页: 1,2,3,4,5,6
增加条件 where id>=7
第10000页:
10001,10002....10011
where id>=10011
加条件后可以不取出前面的N条数据
再优化, 过滤前面和后面的数据
where id>=10011 and id<=10021 limit 10单表查询 多表查询
sql
多表: join,subquery, union。 (业务逻辑简单化)
优势: SQL的数量少,一次性解决大量的问题
劣势: SQL执行的时间长,表锁的时间长
单表:(并发性)
优势:每条SQL执行的时间短,表锁时间短,迸发性好
劣势:执行多次慢查询日志
sql
该日志,会记录执行较慢的查询
通过配置:
1. 开启慢查询
2. 慢查询的临界时间
显示慢查询的临界时间
show variables like 'long_query%'
显示慢查询日志文件
show variables like 'slow_query%'
开启慢查询日志
set global slow_query_log = 1 -- 全局
设置慢查询临界时间
set long_query_time = 0.5 -- 当前连接(会话级)
慢查询日志一旦开启,就会在默认data目录生成日志文件
可见: 在开发阶段,将慢查询开启,优先解决时间长的SQL。
逐渐调小临界时间。
慢查询日志的查看:建议使用其它工具来完成,不是仅仅去读取日志内容。
mysql提供的:mysqldumpslow就是MySQL提供的使用perl编写的一个工具,用来查看分析慢查询日志。
使用方法:
mysqldumpslow
-s c, query 次数排序, -ac 倒序
-s t, 执行时间排序,-at 倒序
-s l, look时间排序,-al 倒序
-s r, 返回记录数排序,-ar 倒序
-t,top N,取得几行
-g "REGEXP", 正则过滤
如:mysqldumpslow -s c -t 10 -g 'left join' slow.log
分析slow.log日志中的慢查询日志,过滤到含有left join的sql,将结果依据出现次数(-s c),获取前10条。profile
sql
用于统计MySQL系统的信息。
常用于:SQL的执行时间统计。
先开启该功能,自动统计:
set profiling = 1
执行SQL,每次执行,都会自动记录
通过语法 show profiles\G 可以得到查询时间精确到亿分之1秒
反复执行SQL。取平均值才可以。
sql
该功能,还可以记录每条语句的执行流程:
show profile for query <query_id>
如:show profile for query 2; (该ID通过show profiles得到)总的来说,MySQL 性能优化是一个系统化的过程,涵盖了硬件配置、查询优化、索引设计、数据库结构调整等多个层面。通过合理的硬件资源分配、精确的索引选择、合理的查询语句优化和数据库配置调整,可以显著提升数据库的响应速度和处理能力。不断地监控和调整性能瓶颈,及时发现和解决潜在的问题,是保证数据库高效稳定运行的关键。希望本文的分析和建议,能为你在 MySQL 数据库优化过程中提供有力的支持。