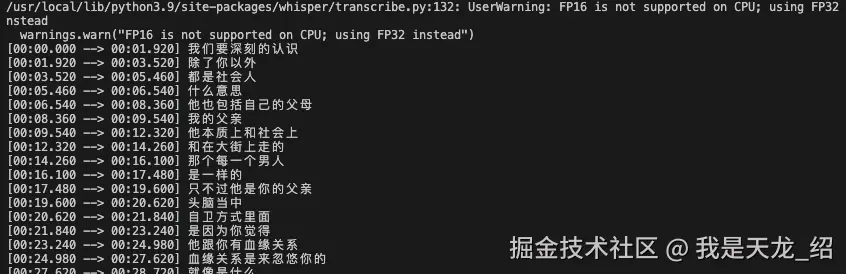
像剪映和一些软件一样,识别字幕,输出文本,用Whisper。
Whisper是openai推出的,一种开源语音识别模型,能够识别很多种语言,然后将音频转成文字。
用python实现。
不懂代码的,用图形界面buzz和const-me/whisper
python记住一定要安装3.9 - 3.11 之间,我用到3.9.9
命令是这样:whisper --language Chinese --model large audio.mp3
就可以输出了。
也可以写代码:
代码如下:
py
import os.path
import whisper
model = whisper.load_model("turbo")
# load audio and pad/trim it to fit 30 seconds
audio_path = os.path.join(os.path.dirname(__file__), "1.mp3")
audio = whisper.load_audio(audio_path)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}") # 检测是哪国语言
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text) # 输出结果