今天咱们继续聊聊 spring-ai-hunyuan 这个项目。上次我们兼容了 spring-ai 的 1.0.0 正式版本之后,就暂时放了一阵子,没怎么动。最近倒是收到不少小伙伴反馈,说混元的思考链功能为什么不返回结果。其实,混元官方那边提供的兼容 OpenAI 的方案,本质上就是帮大家能快速接入,方便快捷,但也难免会有一些高级特性或者参数没办法支持。就算官方给了参数,也未必能直接用上。
所以最近我就抽时间重新开发了一下,专门把思考链的集成做了进来。同时顺带把 ASR(语音识别)和 TTS(语音合成)功能也加进去了,这样一来,基本上跟文字生成相关的场景都给覆盖了,功能更加完整了。
项目的源码开源在这儿,感兴趣的小伙伴可以直接去看看: github.com/StudiousXia...
目前我还没写出详细的实战案例教程,不过今天先给大家简单介绍一下,方便大家能快速上手。所有的案例源码也已经全部开源了,大家可以直接 clone 到本地跑起来试试: github.com/StudiousXia...
项目集成
首先,咱们需要在 pom.xml 文件中集成相应的依赖。只需要将以下依赖添加到你的 pom.xml 中就可以了:
xml
<dependency>
<groupId>io.github.studiousxiaoyu</groupId>
<artifactId>spring-ai-starter-model-hunyuan</artifactId>
<version>${spring-ai-hunyuan.version}</version>
</dependency>好的,这样就搞定了,挺简单的。现在我们已经开发到1.0.0.2版本了,除了混元生文功能外,还加入了思考链、文本转语音、语音转文本等功能。接下来,我们需要在配置文件里加上你腾讯云的秘钥信息,具体内容如下:
properties
spring.ai.hunyuan.secret-id=${HUNYUAN_SECRET_ID}
spring.ai.hunyuan.secret-key=${HUNYUAN_SECRET_KEY}申请地址如下:console.cloud.tencent.com/cam/capi
你直接新建秘钥即可。
场景演示
没错,经过这些步骤后,我们就具备了所有必要的条件,可以直接用 SpringAI 混元框架来对接混元,进行企业级开发了。这样一来,开发流程会更加顺畅,功能也能更好地满足企业需求,效率会大大提升。
模型注入
首先,我们需要将本章节需要用到的所有模型先注入进来。这里简单介绍下。
java
private final ChatClient chatClient;
private final HunYuanAudioTranscriptionModel audioTranscriptionModel;
private final HunYuanAudioTextToVoiceModel textToVoiceModel;
public ChatClientExample(ChatModel chatModel, HunYuanAudioTranscriptionModel audioTranscriptionModel, HunYuanAudioTextToVoiceModel textToVoiceModel) {
this.chatClient = ChatClient.builder(chatModel).defaultAdvisors(new SimpleLoggerAdvisor()).build();
this.audioTranscriptionModel = audioTranscriptionModel;
this.textToVoiceModel = textToVoiceModel;
}这里使用的聊天模型默认是hunyuan-pro,语音转文本则用的是一句话识别接口,具体使用的模型是16k_zh-PY(支持中英粤三种语言)。需要注意的是,这个接口有一些限制,比如音频时长不能超过60秒,文件大小不能超过3MB。之所以选择这个接口,是因为目前语音转文本技术主要集中在日常对话类应用,像大数据分析这种场景还没有广泛涉及,所以暂时是采用这个接口。如果你有疑问,可以参考一下官方文档链接:点击查看文档。
至于文本转语音,我们用的是101001(情感女声),你可以查看音色列表来了解更多:点击查看音色列表,如果需要更多信息,也可以参考这里:点击查看详细文档。
如果你想调整模型的参数,完全可以在配置文件中做修改。我已经把参数配置开放出来,常见的参数如下:
properties
#聊天模型切换
spring.ai.hunyuan.chat.options.model=
#语音转文本模型切换
spring.ai.hunyuan.audio.transcription.options.engSerViceType=
#文本转语音模型切换
spring.ai.hunyuan.audio.tts.options.voiceType=这只是其中的一个小例子,实际上官方提供的所有请求参数都被封装在每个模型配置的 option 里面。如果你想了解更详细的内容,可以直接去看看官方文档,或者你也可以查看我写的源码,都会有很清楚的说明。
基础聊天
先来看下最基础的生文操作,直接使用spring ai的官方示例即可。
对话
这里直接看下阻塞问答和流式问答,代码如下:
java
@PostMapping("/chat")
public String chat(@RequestParam("userInput") String userInput) {
String content = this.chatClient.prompt()
.user(userInput)
.call()
.content();
log.info("content: {}", content);
return content;
}
@GetMapping("/chat-stream")
public Flux<ServerSentEvent<String>> chatStream(@RequestParam("userInput") String userInput) {
return chatClient.prompt()
.user(userInput)
.stream()
.content() // 获取原始Flux<String>
.map(content -> ServerSentEvent.<String>builder() // 封装为SSE事件
.data(content)
.build());
}因为我们采用了流式问答的方式,通常最喜欢用前端通过SSE(Server-Sent Events)来实现。所以在这个地方,我也直接返回了ServerSentEvent,这样方便前端对接。这里虽然没有展示具体的页面,但示例项目中已经集成了Swagger文档,你可以简单浏览一下,看看效果如何。

结构化对象
另外一个要说的点是结构化对象的兼容性,简单来说就是系统能不能返回 Java 对象的信息。接下来我们看一下具体的代码:
java
@GetMapping("/ai-Entity")
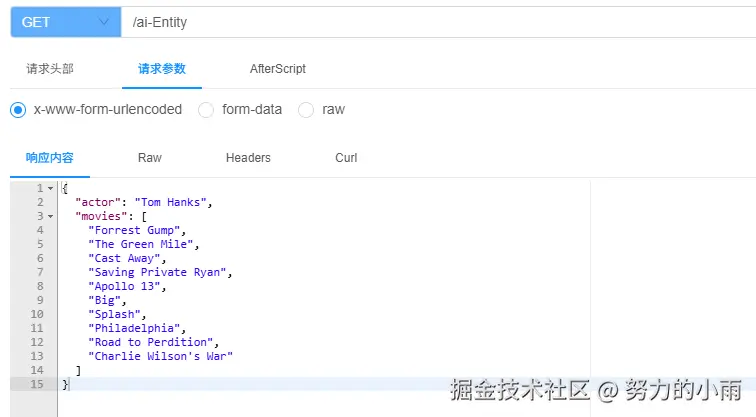
public ActorFilms aiEntity() {
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);
return actorFilms;
}
/**
*当前用户输入后,返回列表实体类型的回答,ParameterizedTypeReference是一个泛型,用于指定返回的类型。
* @return List<ActorFilms>
*/
@GetMapping("/ai-EntityList")
List<ActorFilms> generationByEntityList() {
List<ActorFilms> actorFilms = chatClient.prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {
});
return actorFilms;
}
public record ActorFilms(String actor, List<String> movies) {
}这个例子里,我们用了两种不同的情况:一种是普通的单一类型,另外一种是数组类型。当然,其实其他类型的Map结构也是支持的。不过,能不能正常运行,最终还是取决于模型的能力,看它是否支持这些结构。
目前我用的hunyuan-pro模型还没有报错。从返回的结果来看,大体上是没问题的,具体效果可以参考下面的截图:
函数调用
另外,关于函数调用的部分,我们会提前准备好一些写好的方法,并且把这些方法的参数暴露出来,供大模型调用。先让我们看看代码是怎么写的吧。
java
@PostMapping("/ai-function")
String functionGenerationByText(@RequestParam("userInput") String userInput) {
HunYuanChatOptions options = new HunYuanChatOptions();
options.setModel("hunyuan-functioncall");
String content = this.chatClient
.prompt()
.options(options)
.user(userInput)
.tools(new DateTimeTools())
.call()
.content();
log.info("content: {}", content);
return content;
}
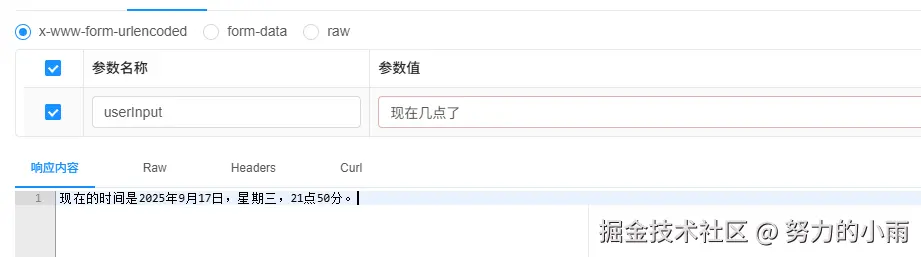
public class DateTimeTools {
@Tool(description = "Get the current date and time in the user's timezone")
String getCurrentDateTime() {
String currentDateTime = LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();
log.info("getCurrentDateTime:{}",currentDateTime);
return currentDateTime;
}
}我这里简单展示了一下如何获取当前日期的工具,代码没有加入任何输入参数,主要就是看看它能否正常工作。顺便提一下,我在代码里指定了当前使用的模型。之前的配置是换全局模型,但在这里,你只需要替换当前对话中使用的模型就行了。因为我们需要切换到一个支持函数调用的大模型。
最后演示如下,如图所示:
思考链
新集成的思考链来了,简单来说,就是通过检查大模型返回的数据,看里面有没有包含'思考'的内容。不过要注意,并不是所有的大模型都有这个功能,只有部分模型才会有类似的思考内容。代码如下:
java
@PostMapping("/chat-think")
public String think(@RequestParam("userInput") String userInput) {
HunYuanChatOptions options = new HunYuanChatOptions();
options.setModel("hunyuan-a13b");
options.setEnableThinking(true);
ChatResponse chatResponse = this.chatClient.prompt()
.user(userInput)
.options(options)
.call().chatResponse();
HunYuanAssistantMessage output = (HunYuanAssistantMessage) chatResponse.getResult().getOutput();
String think = output.getReasoningContent();
String text = output.getText();
log.info("think: {}", think);
log.info("text: {}", text);
return text;
}
@PostMapping("/stream-think")
public Flux<ServerSentEvent<String>> streamThink (@RequestParam("userInput") String userInput){
HunYuanChatOptions options = new HunYuanChatOptions();
options.setModel("hunyuan-a13b");
options.setEnableThinking(true);
Flux<ServerSentEvent<String>> chatResponse = this.chatClient.prompt()
.user(userInput)
.options(options)
.stream()
.chatResponse()
.map(content -> (HunYuanAssistantMessage) content.getResult().getOutput())
.map(content -> {
String think = content.getReasoningContent();
String text = content.getText();
StreamResponse streamResponse;
if (think != null && !think.isEmpty()) {
streamResponse = new StreamResponse("thinking", think);
} else {
streamResponse = new StreamResponse("answer", text);
}
return ServerSentEvent.<String>builder()
.data(JSONUtil.toJsonStr(streamResponse))
.build();
});
return chatResponse;
}
@Data
@NoArgsConstructor
public class StreamResponse {
@JsonProperty("type")
private String type;
@JsonProperty("content")
private String content;
public StreamResponse(String type, String content) {
this.type = type;
this.content = content;
}
}同样的,我这边也写了两种方案,一个是阻塞式的,另一个是流式返回内容的。因为目前Spring AI还没有统一的思考链返回字段,所以如果你想要获取思考链的内容,得先把返回的信息类转换成我自己定义的信息类,才能提取出这些数据。而且还需要注意的是,你得设置enableThinking的值才行。
接下来我们来看一下效果,像图上展示的那样。
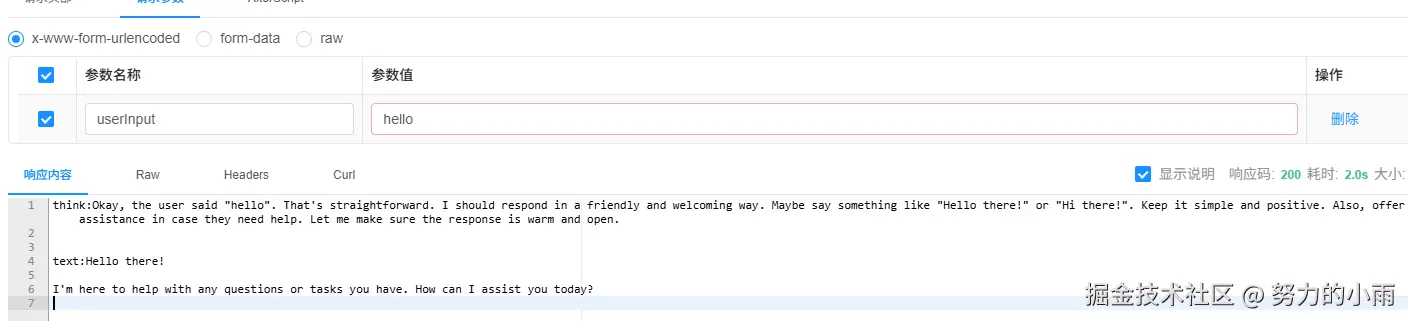
因为我只能返回到固定的字段里,所以如果你需要以流式的方式获取思考链的话,你得先定义一个格式,方便前端去截取数据。我这边已经帮你定义好了,当前的返回样式就是这样的,如图所示。

通过type值,前端就可以方便的定义标签里的值了。
图片理解
目前大模型已经可以支持图片理解了,但它暂时不能直接通过文字生成图片,这其实是另外一个功能,需要单独进行对接。目前这个部分还没有对接完成。以下是相关的代码:
java
@PostMapping("/chatWithPic")
public String chatWithPic(@RequestParam("userInput") String userInput) {
var imageData = new ClassPathResource("/img.png");
var userMessage = UserMessage.builder()
.text(userInput)
.media(List.of(new Media(MimeTypeUtils.IMAGE_PNG, imageData)))
.build();
var hunyuanChatOptions = HunYuanChatOptions.builder().model("hunyuan-turbos-vision").build();
String content = this.chatClient.prompt(new Prompt(userMessage, hunyuanChatOptions))
.call()
.content();
log.info("content: {}", content);
return content;
}
//https://cloudcache.tencent-cloud.com/qcloud/ui/portal-set/build/About/images/bg-product-series_87d.png
@PostMapping("/chatWithPicUrl")
public String chatWithPicUrl(@RequestParam("url") String url,@RequestParam("userInput") String userInput) throws MalformedURLException {
var imageData = new UrlResource(url);
var userMessage = UserMessage.builder()
.text(userInput)
.media(List.of(Media.builder()
.mimeType(MimeTypeUtils.IMAGE_PNG)
.data(url)
.build()
))
.build();
var hunyuanChatOptions = HunYuanChatOptions.builder().model("hunyuan-t1-vision").build();
String content = this.chatClient.prompt(new Prompt(userMessage, hunyuanChatOptions))
.call()
.content();
log.info("content: {}", content);
return content;
}目前我们支持两种方式来上传图片,一种是直接使用本地图片,另一种是通过在线的 URL 图片都可以。不过呢,这样的话,我们需要先构建一些用户信息,不能再像以前那样只传个简单的文本就能搞定了。咱们先看看效果如何吧。
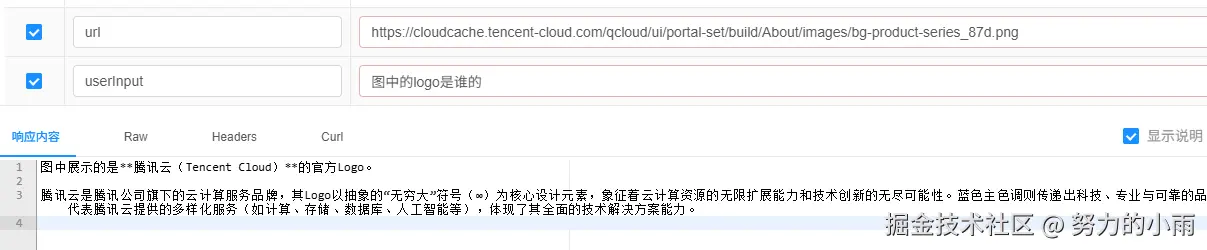
本地文件我也放在了案例项目中,你可以直接查看,和这个url的图片是一致的。
语音转文本
具体的注意事项前面已经说了,我们这里直接使用即可。代码如下:
java
//https://output.lemonfox.ai/wikipedia_ai.mp3
@PostMapping("/audio2textByUrl")
public String audio2textByUrl(@RequestParam("url") String url) throws MalformedURLException {
Resource resource = new UrlResource(url);
String call = audioTranscriptionModel.call(resource);
log.info("text: {}", call);
return call;
}
@PostMapping("/audio2textByPath")
public String audio2textByPath(){
Resource resource = new ClassPathResource("/speech/speech1.mp3");
String call = audioTranscriptionModel.call(resource);
log.info("text: {}", call);
return call;
}好的,这里有两种方式可以选择,一种是用本地文件,另一种是用在线 URL。官方推荐使用腾讯云 COS 来存储音频并生成 URL 后提交请求,这样做有几个好处:首先,它会走内网来下载音频,能显著减少请求的延迟;其次,使用这种方式不会产生外网流量费用,也能帮助节省成本。
当然,最后还是看你个人的需求和实际情况啦。效果如图所示:
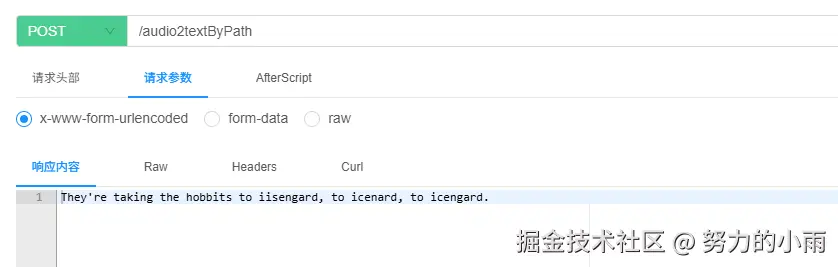
文本转语音
这部分也是已经集成完毕,直接一行代码即可完成调用,所有配置变动都可以写到配置中,代码如下:
java
@PostMapping("/text2audio")
public byte[] text2audio(@RequestParam("userInput") String userInput) throws MalformedURLException {
byte[] call = textToVoiceModel.call(userInput);
FileUtil.writeBytes(call, "D:/output.mp3");
return call;
}前端其实可以直接读取音频流,然后用一个 <audio> 标签来播放。我这边后台是直接生成的 MP3 文件,主要是为了测试文件是否能正常播放。经过测试,结果一切正常,播放效果也没问题。
小结
这次更新的 spring-ai-hunyuan 项目在功能上做了不少增强,特别是在思考链、语音识别(ASR)和语音合成(TTS)方面。之前由于兼容性问题,一些高级功能可能无法完全支持,而现在这些问题已经得到解决。新的版本 1.0.0.2 增加了这些功能,增强了项目的整体能力,特别是在与文本生成相关的场景中,用户可以更加顺畅地进行开发。
首先,项目源码已经开源,大家可以直接从 GitHub 上查看,甚至根据提供的案例源码快速上手。集成方面,也提供了简单易用的依赖配置和腾讯云秘钥设置,帮助开发者迅速搭建起开发环境。
在实际功能上,这个版本加入了思考链、文本转语音、语音转文本等模块,能够让开发者更加方便地调用大模型进行文本和语音的处理。对于语音识别和合成,使用腾讯云的接口能更好地处理音频文件(如语音转文字和文字转语音)。另外,思考链功能的加入,更是让模型能在生成回答的同时,带上思考过程,提升了交互的自然度。
具体到代码实现上,项目的集成和配置都非常直观,基本只需在 pom.xml 添加依赖、配置好秘钥,并调整一些参数设置,就能实现各种功能。最基本的功能包括基于用户输入的聊天对话,支持流式和阻塞式问答。而在结构化对象的处理上,项目支持将聊天内容转换成 Java 对象格式返回,非常适合数据驱动的应用场景。
对于前端开发者来说,流式问答(SSE)可以非常方便地实现实时聊天功能,而思考链的集成则让聊天更具智能化和逻辑性。虽然目前图片生成还未完全对接,但语音转文本和文本转语音的功能已非常完善,提供了两种方式(本地文件和 URL)来处理音频数据。