9 月 17 日,DeepSeek-R1 的相关研究成果登上 Nature 封面,这一消息迅速在全球学术领域引发热烈讨论。其实相关研究成果已经于今年 1 月以预印本的形式发表于 arXiv,但本次公开于 Nature 的意义在于其通过这一权威期刊接受了同行评审, 换言之,外部专家并非只接收单向信息,而是能够在独立第三方(编辑)的监督和管理下,通过一个协作过程提出问题并向作者团队要求更多信息,实属业内首次。
更加重要的是,不同于 1 月公开的预印本论文已经概述了研究方法以及 DeepSeek-R1 在一系列评测基准上的表现,这一正式见刊的论文中补充披露了该模型的训练成本。据 Nature News 的报道显示,DeepSeek-R1 训练成本仅相当于 29.4 万美元, 尽管 DeepSeek 已经为 R1 模型所依托的基础 LLM 投入了约 600 万美元,但成本总额仍远低于业内普遍认为的头部模型训练所需的数千万美元。
- 预印版论文地址:

DeepSeek-R1 训练成本
DeepSeek 表示,在训练 DeepSeek-R1-Zero 时,共使用了 648 张 H800 GPU,整个过程大约耗时 198 小时。 此外,在训练 DeepSeek-R1 的过程中,其同样使用了 648 张 H800 GPU,训练约 4 天,约合 80 小时。 为了构建 SFT 数据集,还消耗了约 5,000 GPU Hours。具体成本如上图所示。
大规模强化学习提升推理能力
大模型推理能力的重要意义无需赘述,已经成为业内的重点研究方向,但在预训练阶段获得推理能力往往需要巨大的计算资源支撑。对此,有研究表明可以通过 CoT(Chain-of-Thought,思维链)prompting 有效增强 LLM 的能力,或是在后训练阶段学习高质量的多步推理轨迹,也能进一步提升性能。尽管这些方法行之有效,但仍存在明显局限,例如依赖人工标注的推理过程,降低了扩展性并引入了认知偏差。 此外,由于限制模型去模仿人类的思维方式,其性能本质上受制于人类提供的示例,无法探索更优的、超越人类思维模式的推理路径。
针对于此,DeepSeek 公司基于 DeepSeek-V3 Base8,采用 Group Relative Policy Optimization(GRPO)作为 RL 框架,并在 RL 训练前跳过了传统的监督微调(SFT)阶段。这一设计选择源于团队的假设:人为定义的推理模式可能会限制模型的探索,而不受限制的 RL 训练更能促进 LLM 中新推理能力的涌现。
基于此,团队开发了 DeepSeek-R1-Zero,展现出了多样而复杂的推理行为。为了解决推理问题,该模型倾向于生成更长的回答,在每个回答中融入验证、反思以及对不同解法的探索。尽管团队没有显式教授模型如何进行推理,但它依然通过 RL 成功习得了更优的推理策略。 研究团队采用了群组相对策略优化(GRPO),该算法最初被提出是为了简化训练流程,并减少 Proximal Policy Optimization (PPO)的资源消耗,不需要使用与策略模型同样大小的评估模型,而是直接从群组分数中估算基线。
此外,团队采用基于规则的奖励系统来计算准确率和格式奖励。随后在 GRPO 和奖励设计的基础上,团队设计了一个模板,要求 DeepSeek-R1-Zero 先产生一个推理过程,再产生最终答案,并在训练过程中,用具体的推理问题代替 prompt。
学会使用拟人化的基调来重新思考
具体而言,接收用户提问后,模型首先在「Think」标签中输出推理过程,再在「Answer」标签中给出最终答案,以便能够在强化学习中自主探索有效的推理路径。同时,研究团队采用了基于规则的奖励系统来评估 DeepSeek-R1-Zero 在实验中所提供的答案,从而保证训练过程的稳定性与可扩展性。
评测结果显示,DeepSeek-R1-Zero 在 AIME 2024 数学竞赛上的 pass@1 分数从初始的 15.6% 显著提升至 77.9%;若采用自洽解码策略,准确率则进一步提升至 86.7%,超过了人类选手的平均水平。
除了数学任务,模型在编程竞赛以及研究生层次的生物、物理和化学问题中同样表现出众,充分验证了强化学习在提升大语言模型推理能力方面的有效性。
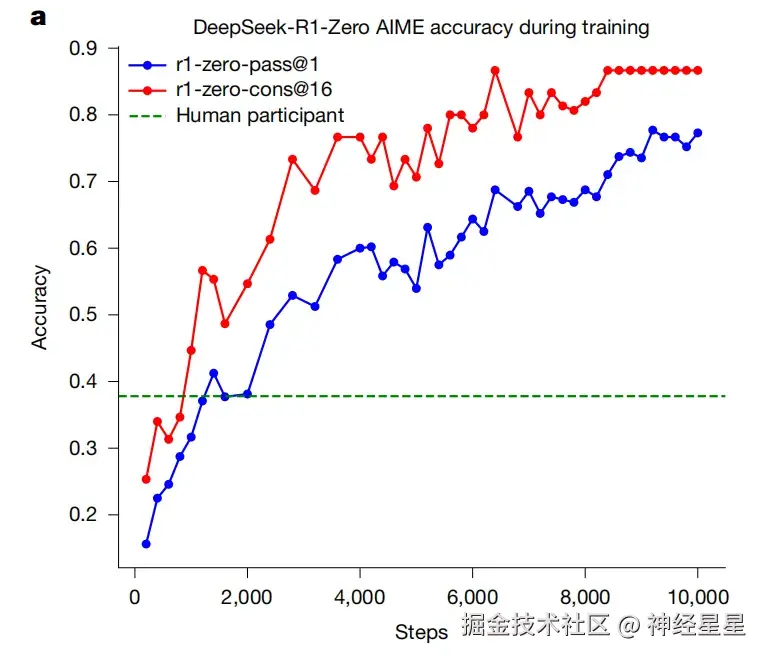
DeepSeek-R1-Zero 在训练过程中的 AIME 准确率与人类选手平均表现(绿色基线)对比
此外,在强化学习过程中,DeepSeek-R1-Zero 不仅展现出随训练逐步增强的推理能力,而且伴随明显的自我进化特征。实验数据显示,模型由内在适应驱动时,其平均推理长度在训练中持续增长并不断修正推理路径,能在推理过程中主动暂停、检视并修正已有推理步骤,实现了反思性推理和对替代解决方案的系统性探索。

强化学习过程中 DeepSeek-R1-Zero 在训练集上的平均响应长度
更进一步地,为了解决可读性差和语言混合等挑战,针对 DeepSeek-R1-Zero 可读性差、语言混乱的问题,研究团队开发了 DeepSeek-R1,其工作流程如下:
- 基于 DeepSeek-V3 收集对话式、与人类思维一致的冷启动数据,输入 DeepSeek-R1 Dev1;
- DeepSeek-R1 Dev1 基于数据进行强化学习和采样,DeepSeek-R1 Dev2 将推理和非推理数据集纳入 SFT 流程;
- DeepSeek-R1 Dev3 推动进入第二个强化学习阶段,以增强模型的有用性和无害性最后输出答案至 DeepSeek-R1。
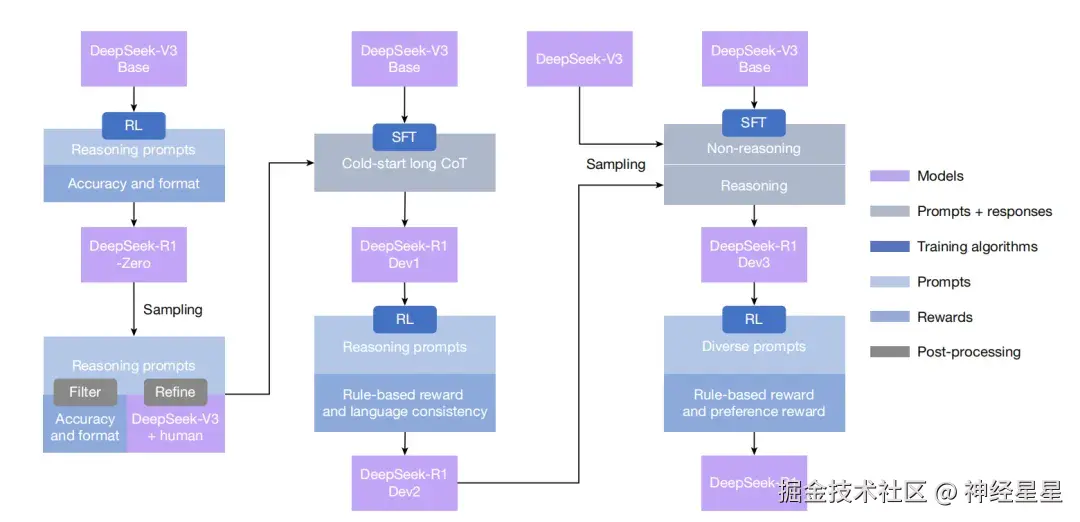
DeepSeek-R1 的多阶段 pipeline
从实验结果来看,对比 DeepSeek-R1-Zero 和 DeepSeek-R1 Dev1,DeepSeek-R1 在各个开发阶段的指令执行表现有显著提升,在 IF-Eval 和 Arena-Hard 基准测试中得分更高。
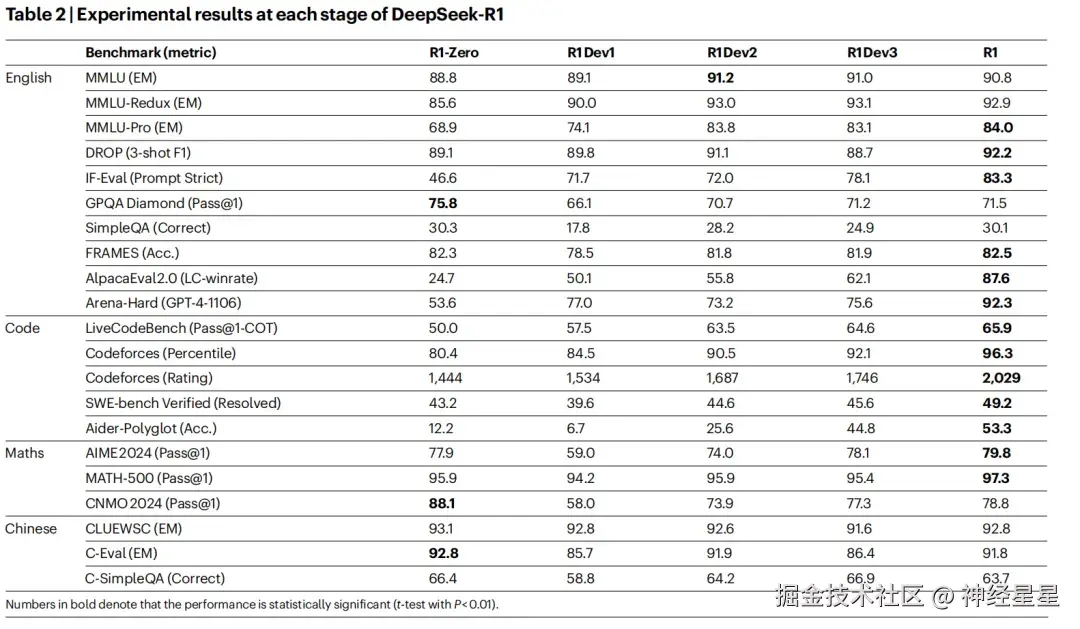
DeepSeek-R1 各阶段实验结果
首个通过权威期刊同行评审的大模型
作为首个接受同行评审的 LLM 模型,DeepSeek- R1 的研究论文一经发表就登上了 Nature 的封面。Nature 在「Bring us Your LLms:why peer review is good for AI models」一文中表示,同样评审是应对 AI 行业营销炒作的有效方式。几乎所有主流的大规模人工智能模型都尚未经过独立的同行评审,而这一空白「终于被 DeepSeek 填补了」。
对此,曾任 AAAI 主席的亚利桑那州大学研究员 Subbarao Kanbhampati 表示,他参与了此次同行评审,并认为这是一个良好的趋势,希望看到更多前沿模型开发人员跟随他们的脚步,分享 AI 模型同行评审的技术细节。

美国科技媒体 Wind Info 报道表示,与1月份发布的初始版本相比,该论文揭示了关于模型训练过程的更多细节,并直接解决了早期的蒸馏问题。可以说,DeepSeek- R1 为未来更透明、更规范的 AI 研究实践提供了范例。
参考资料: