 随着ChatGPT、Midjourney等通用人工智能系统的普及,我们越来越多地将生活、学习、工作交给AI助手。然而,AI真的"理解"我们了吗?我们又是否真的"理解"AI在想什么?
随着ChatGPT、Midjourney等通用人工智能系统的普及,我们越来越多地将生活、学习、工作交给AI助手。然而,AI真的"理解"我们了吗?我们又是否真的"理解"AI在想什么?
最近,一篇由密歇根大学、卡内基梅隆大学、斯坦福大学和谷歌研究人员联合发布的论文《Towards Bidirectional Human-AI Alignment》提出了一个颠覆性的观点:人机对齐(Human-AI Alignment)不应该只是"单向"的,而应该是"双向"的。
什么是"人机对齐"?
传统上,人机对齐指的是"让AI听话"------即确保AI系统的行为、决策与人类的目标和价值观一致。比如,让AI不歧视、不骗人、不给出危险建议。
这种思路强调的是"AI要像人一样思考",但作者指出:这种想法过于理想化,也过于片面。
为什么要"双向对齐"?
作者从400多篇近五年人机对齐相关论文中发现,大部分研究都集中在"如何训练AI更好地对齐人类目标",却忽视了另一个重要问题:
在AI日益融入生活的今天,人类也在悄然发生变化------我们正在适应、接受甚至依赖AI。
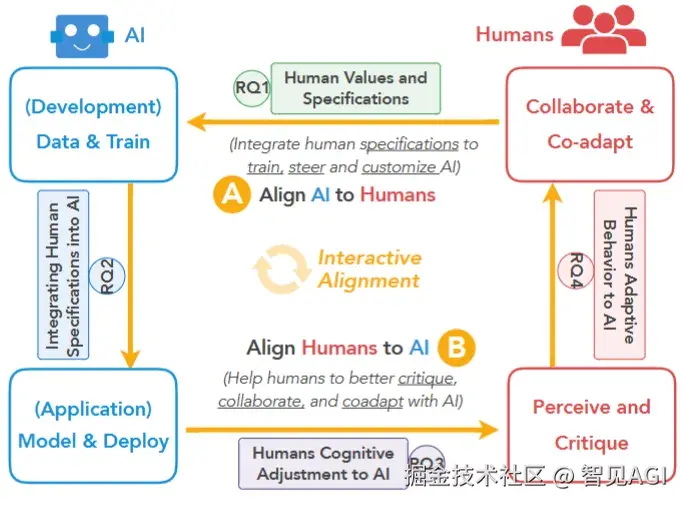
因此,他们提出了一个"双向对齐框架"(Bidirectional Alignment Framework):
-
AI对齐人类(Align AI to Humans):继续优化模型,使其理解人类价值、偏好和指令。
-
人类对齐AI(Align Humans to AI):引导人类提升AI素养,学会质疑和合作,适应与AI共处的新范式。
我们该如何"对齐"彼此?
论文给出了一个四问框架:
RQ1:哪些人类价值值得被AI学习?
-
不仅是效率、准确性,也包括公平、包容、环保、同理心等软价值。
-
作者列出69种人类核心价值,其中很多在当前AI训练中被忽视。
RQ2:如何将这些人类价值融入AI?
-
包括用户打分、自然语言反馈、模拟用户行为、定制化微调等方式。
-
倡导"人类参与训练"而非全自动黑箱式AI。
RQ3:人类如何理解和质疑AI?
- 不是盲目信任,而是需要提升AI素养,如AI解释性、用户培训、批判性思维。
RQ4:人类如何调整行为与AI共存?
- 包括在人机协同写作、教育、医疗等场景中,逐步建立有效沟通与信任。
论文的关键观点总结
✅ 价值多样性很重要:AI不应只对齐"技术人员"的理性目标,也应考虑普通用户、弱势群体的感受和需求。
✅ 交互是核心场景:很多AI风险(如偏见、误导)并不是训练阶段出现的,而是在实际使用中暴露的。
✅ AI不是工具那么简单:它正在悄悄重塑人类的思维习惯、社会规则,甚至价值观。
AI发展不只是技术问题,更是人类社会的问题。我们不能只想着"如何让AI更懂我",也要思考"我是否真的准备好拥抱AI时代"。
如果你是AI开发者,思考如何更好地引入用户反馈。
如果你是普通用户,也可以从今天开始,学习如何与AI"健康相处"。
毕竟,未来的世界,不是人类控制AI,也不是AI控制人类,而是我们共同适应、共同进化。
深入理解"人机对齐"的内涵
所谓人机对齐(Human-AI Alignment),并不只是简单地让AI"听话",更重要的是让AI的目标、决策机制、以及最终输出结果,在复杂、多元的现实世界中,真正体现人类社会的伦理标准与价值体系。
过去,AI研究者们更多地关注"外在对齐",即AI是否能够输出符合人类预期的结果,是否能避免明显的偏差或误导;而较少涉及"内在对齐"------即AI在决策过程中是否真正"理解"了人类的价值逻辑,是否存在潜在的奖励黑客(reward hacking)等行为。
这就像一位考试机器虽然每次答题正确,但未必真的理解题意。这种表面上的"对齐",如果被用于招聘、医疗、司法等敏感领域,很容易导致不可控的社会风险。
双向对齐的必要性:不仅AI要懂人,人也要懂AI
文章提出,"双向对齐"意味着人和AI需要在交互中共同演化。比如:
-
当我们使用写作AI辅助生成内容时,AI可能影响我们的表达风格,甚至改变我们原本的写作意图。
-
当AI根据用户历史行为推荐新闻,它也在塑造我们的认知偏好,甚至影响我们的价值判断。
这些例子说明:人类不是AI发展的旁观者,而是被卷入其中的"合作者"。因此,我们不能只关注如何让AI符合人类意图,还要关注如何让人类在长期互动中形成对AI的理解力、批判力与适应力。
研究方法与关键发现
本研究基于PRISMA系统综述方法,从2019年至2024年初,共审阅了411篇跨领域的论文,涵盖人机交互(HCI)、自然语言处理(NLP)、机器学习(ML)等方向。
研究团队提出了一个"人机双向对齐"框架(Bidirectional Human-AI Alignment Framework),并围绕以下四个核心问题构建理论基础与研究拓扑结构:
-
人类的价值观如何分类、建模并输入到AI中(RQ1)
-
如何在AI的训练、推理、评估和部署过程中整合这些价值观(RQ2)
-
人类如何提升AI素养,理解并批判AI输出的过程(RQ3)
-
人类如何在长期与AI互动中调整行为和策略,实现协同进化(RQ4)
人类价值的系统分类:不仅是"效率"
研究团队基于Schwartz人类基本价值理论,结合AI领域实证研究成果,构建了一个囊括69种具体价值的分类表(详见原文Table 2),并划分为五大类:开放性(如创新、好奇)、自我提升(如能力、成功)、保守性(如安全、传统)、自我超越(如公平、利他)以及工具性(如可解释性、透明度)。
这张图谱告诉我们一个核心观点:AI不仅要懂"对错",更要懂"人性"------即那些影响人类行为选择、社会规则和群体合作的深层动因。
未来研究的三大方向
在结尾部分,研究团队为人机双向对齐未来的发展指出了三条值得探索的路径:
-
多模态对齐:不仅用文字,还包括语音、图像、动作等更多人类表达方式,来增强AI对价值的理解能力。
-
可扩展监督机制:研究如何降低人类监督AI的成本,提高评估、反馈的效率与准确性。
-
长期共进:不把AI视为工具,而视为"合作者",从而推进跨学科、跨文化的人机关系研究。
双向人机对齐框架的两大支柱
1️⃣ 人工智能对齐人类(Align AI to Humans)
这一部分强调如何将人类的价值观、意图和行为目标融入AI系统的开发与运行中,作者提出了以下几个关键方法和步骤:
• 明确价值目标(Articulating Values)
-
借助文献综述、公众参与、专家访谈等方式,梳理出AI系统应优先对齐的"价值类别",如公平性、透明度、可解释性、安全性等。
-
作者整合出一张囊括69种人类价值的全景图谱,并按心理学标准分成五类,为AI开发提供"道德坐标系"。
• 将价值转化为模型目标(Operationalizing Values)
- 用人类反馈(如RLHF)、偏好建模、行为数据模拟等方式,把抽象的价值具体化为模型可学习的目标函数。
• 多阶段注入价值观(Embedding Values into Pipelines)
- 在模型训练(如数据清洗、微调)、部署(如人机界面设计)和评估阶段(如偏差检测)都注入人类价值的考量,而不是集中在训练阶段。
• 使用多元指标进行评估(Evaluating Alignment)
- 不再单纯依赖accuracy、loss等传统指标,而是用问卷调查、用户测试、对抗性prompt等"多模态""多角色"的方式来综合评估对齐效果。
2️⃣ 人类对齐人工智能(Align Humans to AI)
这一部分更具前瞻性,作者强调了三个关键主题:
• 理解与信任(Understanding & Trust)
-
当前用户面对强大的AI模型时,可能会"过度依赖"或"完全不信任"。
-
作者建议提升用户的"AI素养",如通过界面透明性、解释系统、预测置信度展示等手段,帮助用户判断AI的边界与可靠性。
• 学习与协同(Learning & Co-Adaptation)
-
人类需要逐步适应与AI共事的方式,例如在自动写作、辅助决策、机器人合作等场景中,主动调整策略以提高效率。
-
同时,设计"适应性界面"可以动态学习用户习惯,实现协同优化。
• 价值反思与反馈(Value Reflection & Critique)
-
人类用户不仅要反馈模型表现,更要主动识别哪些"假设价值"可能在交互中被强化、误导或扭曲。
-
例如:一个推荐系统不断强化消费主义倾向时,用户应有能力识别这种"隐性价值引导"。
阅读原文(英文):
项目资源库: