RELIABLE AND DIVERSE EVALUATION OF LLM MEDICAL KNOWLEDGE MASTERY

该文章于2025年发表在ICLR(CCF A),早在2024年9月发布在arxiv。
文章地址:Reliable and Diverse Evaluation of LLM Medical Knowledge Mastery
arXiv:[2409.14302 Reliable and diverse evaluation of LLM medical knowledge mastery](https://arxiv.org/abs/2409.14302)
openreview打分: 6 8 8 6
一、概述
本文提出了一个新颖的LLMs医疗知识评估的框架,利用谓词等价转换来给给定的医学知识点生成一系列变体,然后将这些变体转换成文本语言,从而产生一系列可靠和多样化的测试样本,通过统计LLMs对这些样本的正误判断结果,来衡量LLMs对医学知识的掌握能力。
二、研究的核心问题及背景
核心问题: 如何设计一个动态生成测试样本且样本不会过时的大模型评估框架
背景: 近年来,大型语言模型(LLM)发展迅速,在各个领域都显示出巨大的潜力。一些基准如MedQA,长期以来一直是评估LLM医疗能力的有效工具,然而他们可能面临过时或被泄露给LLM的挑战。此外,医学数据库如UMLS定期更新,并包含广泛的医学知识,现在还没有统一框架,充分利用这些知识来评估LLM掌握的医学知识。
通过医学知识库评估LLM需要从结构化知识中生成文本测试样本,如果直接用LLM生成会导致两个缺点:①.真实性不足。②.结构多样性不足。
三、现有方法面临的挑战
大模型医疗评估
1.分类两大类:①.从医疗文献、测试或网络资料收集得到的QA数据集,来评估大模型的全面的医疗能力。②.利用数据集来测试大模型对医疗知识的掌握。
2.他们都面对相同的问题,也就是过时或可能泄露给LLMs等问题,虽然构建新的数据集、基准可以解决这些问题,但随着时间推移,它们也会过时
动态评估范式
1.一些工作利用算法动态生成特定任务的训练样本,例如在数学、SQL执行器。另一些工作通过对现有的基准进行释义来生成测试样本(对已有的数据集里的题目,换一种说法,改写成不同的表述)。现在还没有从定期更新的医学知识库中动态生成测试样本的方法。
四、针对挑战,解决思路
1.针对数据集、基准过时、泄露问题,提出动态生成测试样本
2.针对利用LLM直接生成测试样本真实性不足和结构多样性不足问题,提出谓词等价变换。先将知识点用谓词表达式表示,生成多个谓词表达式变体,然后映射到对应的原型样本(文本变体),最后用LLM进行重述,得到测试样本。
五、模型框架与具体实现

评估范式
1.给定一个知识点P,直接使用LLM生成测试样本可能会缺乏多样性和可靠性。相比之下,本文先将知识点P投影成谓词表达式q,然后进行谓词等价变换,得到一系列变体V_1-V_m。谓词等价变换保证了这些变体的可靠性,前提是原始表达式q为真。

2.随后,将每个变体转换成文本测试样本S_i进行评估,因为这些样本具有不同结构,因此可以在保持可靠性的同时表现出多样性。

评估框架
谓词变体生成
1.在三元组知识库中,谓词可以从关系r中导出。

2.接下来,该框架采用了在实际医学应用中广泛使用的三类等价变换:逆向表达(Inversion)、实例化(Instantiation)和双重否定(Double Negation)。
3.这三种类型还可以进一步组合,产生基于谓词等价变换的传递性质的附加表达式,一共生成m个变体。


文本样例生成
1.最后,将谓词变体转换回文本样式以供LLM评估。一种方法是提示LLM直接生成,这种方法可能会引入事实错误(LLM可能不完全理解谓词形式)。本文设计了一种基于原型的样本生成方法,构造一个原型池(映射表),谓词变体从原型池中检索对应原型样本。随后,使用LLM(llama3-70B)对得到的原型样本进行改写,得到最终的一系列测试样本。
评估方法
1.每一条测试样本都有真实标签∈True or False。要求所评估的LLM判断给定的语句是真还是假。
2.对于评价指标有两种,一种是平均准确率,统计LLM在所有样本的所有变体的准确率。一种是联合准确率,在一个知识点的所有变体样本都回答正确,才算LLM掌握该知识。


六、实验
数据集:MedLAMA、DiseK
基线:LLM直接测试(Direct),用LLM生成的测试样本(LLLEval)测试LLM,用本文的框架(PretexEval)测试LLM。
1.主实验

与原始数据集相比,评估的LLM在PretexEval生成的数据集上的性能要低得多。这表明,为每个知识点动态生成多个样本可以显著提高评估的全面性。 此外,与LLM直接生成的数据集(LLMEval)相比,几乎所有LLM在PretexEval创建的数据集上的性能都要低,一些模型(例如Llama 2 - 7 B和Llama 2 - 70 B)经历了超过50%的降解。这些发现表明PretexEval能够生成比LLM直接生成的测试样本更多样化的测试样本。
在所有评估的LLM中,GPT-4 o在几乎所有数据集和评估方法上都优于其他LLM,实现了性能提升(相对于随机猜测(50%))的31.7和26.7由PretexEval评估。在开源的LLM,与具有类似参数尺度的LLM相比,Llama 3 - 70 B和Llama 3 -8B在PretexEval生成的数据集上表现最好。这些结果表明,Llama 3模型系列比其他评估的LLM编码了更多的医学知识。 此外,尽管一些医学专用LLM(ClinicalCamel,Med 42)的性能与其骨干模型相似(Llama 2 - 70 B)在原始数据集上,他们在PretexEval上的表现明显优于后者约7%,这表明,医学语料库的培训可以显着提高医学知识掌握的深度。
2.生成样例数量的研究
当使用单个样本进行评估时,LLMEval和PretexEval的结果非常接近。然而,随着测试样本数量的增加,两种方法的结果之间的差异明显变大。这种现象表明,与LLM直接生成的样本相比,当前LLM在面对由我们的方法生成的结构多样的测试样本时通常表现出显著较低的一致性。

3.消融实验
对于框架组件的消融实验:观察到,删除这两个模块会导致更高的评估性能,特别是当谓词等价转换模块被移除时(在Llama 3 - 70 B上约为7%)。这些结果表明,谓词等价转换对所提出的框架中的评估多样性贡献最大。
谓词转换类型的有效性实验:随着更多谓词转换类型的添加,LLM性能不断下降,表明它们的有效性。此外,包含双重否定(+DN)会导致更显著的性能下降(约5%)这表明,**与实例化相比,当前的LLM在理解否定表达式方面表现出相对较低的熟练度。**和医学知识的颠倒陈述。

4.对可靠性和多样性的人工分析
我们观察到,在改写过程之前 ,PretexEval生成的原型样本表现出较高的结构多样性和可靠性,但与其他方法相比,词汇多样性较低。尽管LLMEval有较高的词汇多样性,但是可靠性和结构多样化很低。在改写之后 ,PretexEval框架在词汇多样性也有较大的提高。

5.案例研究

6.跨评估任务的可伸缩性
为了验证PretexEval对于不同类型评估任务的可伸缩性,还对多项选择题(这是广泛采用的当前基准)使用PretexEval进行评估。实验结果(图7)显示了与声明验证评估中观察到的趋势相似的趋势,证明PretexEval可以与各种任务类型相结合,以准确评估LLM的医学知识掌握程度。

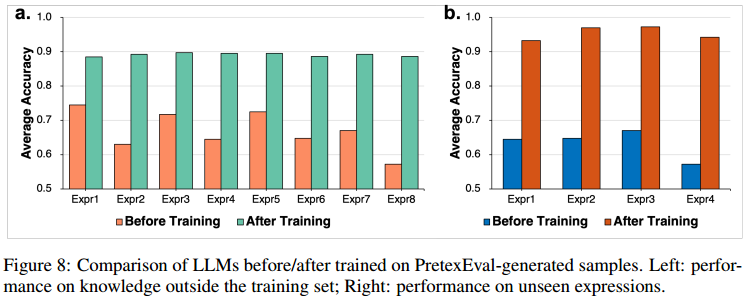
7.模型训练适应性研究
主要关注两个研究问题:RQ 1:PretexEval生成的样本训练能否提高LLM对训练集外知识的理解?RQ 2:在几种类型的PretexEval生成的样本上进行训练是否可以提高LLM对其他看不见的表达式的理解? 对于RQ 1,选择了200个知识三元组作为训练集,另外200个三元组作为测试集。我们使用所有来自训练集的PretexEval生成的样本对Llama 3 -8B进行微调,图8a中的实验结果表明,在PretexEval生成的样本上进行训练可以显著提高模型在所有类型的表达式上的性能(约20%),这些表达式来自训练集之外的知识。
对于RQ 2,我们从8种PretexEval生成的表达式中随机选择4种进行训练,并将其余4种类型用于评估。图8b表明,在几种PretexEval生成的样本上进行训练可以大大提高LLM在所有未见过的表达式上的性能(约30%)。这些结果表明,使用PretexEval生成的样本进行训练可能会有所帮助