背景
Pulsar 作为下一代云原生分布式消息与流处理平台,凭借其高吞吐、低延迟、强一致性和高度可扩展 的架构设计,已在全球范围内被众多头部企业广泛采用为关键基础设施。自成为 Apache 顶级项目以来,Pulsar 经历了大规模生产环境的充分验证,尤其适用于云原生部署环境,支持多租户、弹性扩缩容和无缝容器化集成。然而,其精密而先进的架构在带来强大功能的同时,也增加了系统操作与问题定位的复杂性。
谙流科技自 Pulsar 项目早期阶段便深度参与其生态建设,核心团队在 Apache Pulsar 和 Apache BookKeeper 的研发、运维与优化方面积累了丰富的实战经验。凭借对 Pulsar 底层机制的深刻理解,团队积累了深厚的实践经验,能够高效应对各类复杂场景下的技术挑战。
问题诊断
问题:Consumer 消息拉取故障、机架感知 Bookies 节点数不足;集群网络连接超时,导致集群严重无法使用。
诊断 :跨区域(下文简称为跨AZ)的 Pulsar 集群网络问题的根本原因是防火墙较短的探活周期断开了 Pulsar 和 BookKeeper 的 TCP 连接。
TCP 保活(TCP keepalive)
TCP 双方建立连接后,如果长时间无数据交互,且不主动释放连接,或出现掉电等意外情况时,连接的另一方将始终维护这些无效的连接。长期积累,会导致大量半连接出现。这给对端系统造成了大量资源浪费。通常会在传输层使用 TCP 保活机制来解决这个问题。
防火墙超时灭活
防火墙等中间设备会维持连接信息表,并设有超时删除机制。如果有连接在定时器探活期间发现无数据保活交互,则会将连接从中删除。
删除后的表现为,应用认为仍然连接着服务(实际连着防火墙),防火墙并未断连,只是删除了自行维护的链接信息表。当应用再有新的报文发来时,防火墙会直接丢弃该报文,从而导致应用出现 RST 等异常网络表现。
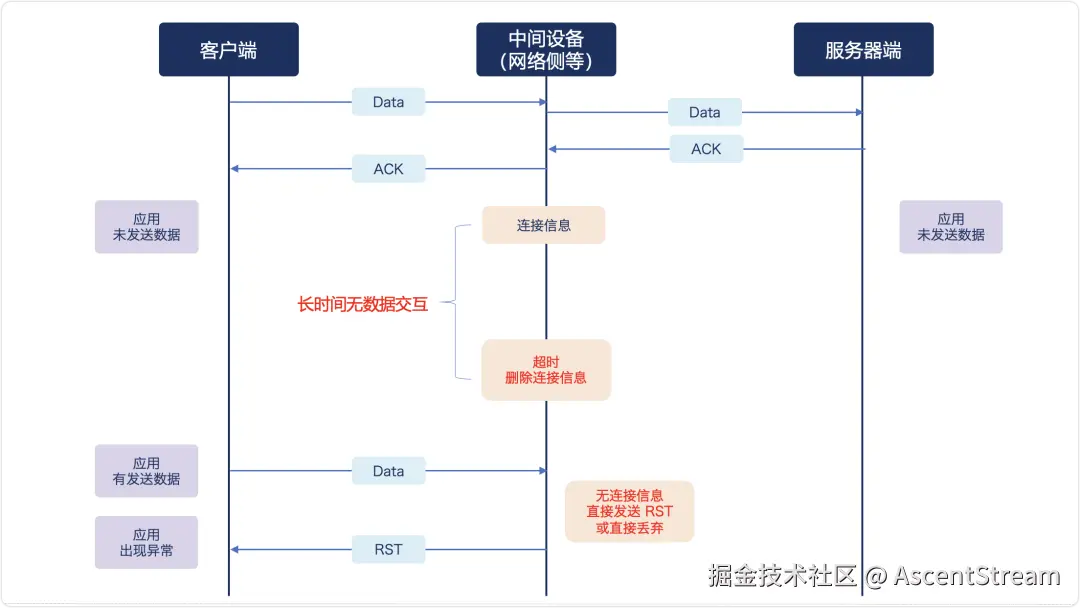
防火墙的"超时灭活"机制,会给需要长连接,但可能长时间无数据交互的应用(如数据库和消息队列)带来极大影响。
Pulsar 作为底层核心消息队列,通常处于没有防火墙的内网环境中。因此相关报错处理,外界的经验会相对较少。同时,Pulsar 的消息处理场景,典型场景为高吞吐、低延时的核心消息处理,其长连接通常处于数据满载的状态。因此,长时间维持连接但无数据交互的罕见场景也触及了 Pulsar 应用的边界,这块经验也相对较少,同样会给问题定位带来麻烦。
Pulsar 的保活机制
Pulsar 的 TCP 连接主要分为两类:
-
PulsarBroker 和 PulsarClient 的客户端侧连接,采用主动 Ping-Pong 保活机制,默认 30 秒。
-
PulsarBroker 和 Bookie 的内部连接,如果没有特别设置,默认值通常是操作系统的默认值(例如,在 Linux 上通常是 7200 秒,即 2 小时)。
当 Pulsar 集群有大量连接、但较多连接长时间无数据交互的情况下,且默认保活时间小于防火墙的保活时间,则比如会被防火墙的保活机制给灭端连接,造成网络 Reset 和超时等问题。大量的网络问题会引发集群内部未知的其他问题。
在用户实际的网络中,Broker-Bookie 间采用操作系统级别的 TCP 连接保活机制,默认 2 小时探活一次,而跨 AZ 的防火墙探活检测为 20 分钟,因此触发网络异常问题。
耗时的应用
用户有些应用处理非常耗时,对于单条消息的处理,通常保持在 8~9 分钟。在未改版之前,应用逻辑为每条消息对应一个消费者处理,使用多个 Consumer 通过 Shared 订阅来提升处理性能。
多个 Consumer 隶属于一个客户端,每个客户端会和 Pulsar 集群建立一个 TCP 连接。代码中消费结束后并未发现主动close 掉客户端的动作。这些都将导致,随着并发处理数据消息量的增加和时间的累积,集群中的连接数量会过多(有小集群,保留有 7000 多客户端连接)。
这些应用的过慢处理,也会快速占满网络侧资源,同时也会加剧"防火墙灭活"机制的影响。
排查过程
问题暴露后
第 3 个工作日
远程协助集中排查问题。问题为跨 AZ 网络环境下集群连接出现各类报错,包括 Connection reset by peer 和 connection timed out 。网络抓包发现大量半连接满问题。建议调整 TCP 内核参数,重点将 net.core.somaxconn 从默认 128 调整到 1024 并复测。
第 4 个工作日
不间断远程支持。反馈调参复测后问题得到缓解,但仍有网络连接报错,且伴随大量其他报错。大量报错干扰排查,让问题追踪陷入困境,谙流要求保持单 AZ 环境排查,一直等待实施中。由于当日问题仍未解决,升级响应,希望有专家入场排查。
第 5 个工作日
谙流支持入场并会同远程排查。经反复测试,确定问题为跨 AZ 网段的网络"保活问题",现象为单 AZ 集群各类测试无误,跨 AZ 抓包发现大量 FIN 包丢失,即 Pulsar 连接被防火墙"架空",防火墙默认断开超过 20 分钟无保活连接。而 Pulsar-Bookie 默认采用 OS 保活机制(默认 2 小时),因此出现网络连接问题,怀疑此为根因。谙流人员出场,建议次日用户陪同防火墙专家复测。
第 6 个工作日
远程不间断支持。用户复测抓包确认防火墙关闭了 Broker-Bookie 的连接,确认了防火墙保活超时关闭机制。谙流确认 Pulsar-Bookie 依赖 OS 保活策略,基本确认根因,等待用户修改保活配置,复测确认根因。
第 9 日
远程不间断支持。用户修改保活参数,发现起"反向"作用,且由于影响应用测试,又回退保活配置,确认测试陷入僵局。谙流要求搭建自测多 AZ 集群(应用前期不参与测试)。同时期,审核代码,并应用调整代码实现,使用缓存方式,去除一个消息新建一个客户端的实现。
第 10 日
远程不间断支持。用户通过降低 Broker-Bookie 的保活为 15 分钟,在自测多 AZ 集群复测,无报错,邀请应用复测,无报错。确定根因。
根因分析
通常 Pulsar 会部署在没有防火墙的内部网络中,因此常规用户感知不到 TCP Keepalive的影响。用户跨 AZ 的网络架构中,防火墙是其中必不可缺是一环,而这给也给 Pulsar 的建设引入了额外的复杂性。
本次的 Pulsar 网络问题中,大量爆发网络相关 WARN,常见的如 Connection reset by peer 等,表现为应用大概率可以正常消费数据,但是连接极为不稳定,集群充斥大量 WARN 和异常。
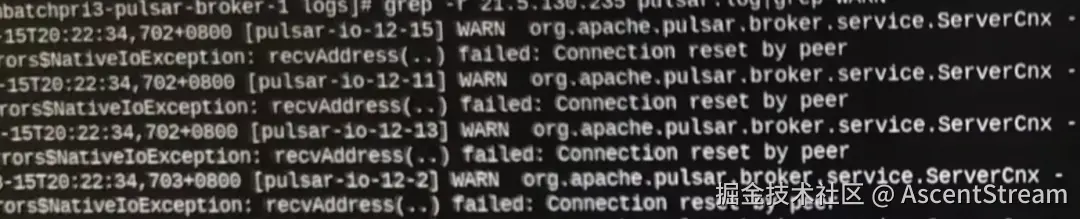
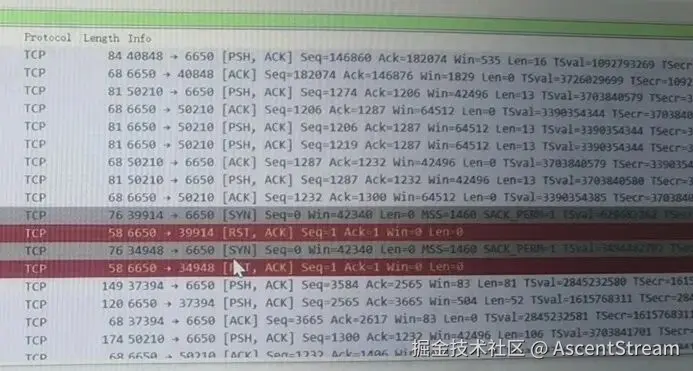
通过对应用到集群和集群组件之间的网络抓包,也会发现大量的 RST 报文。
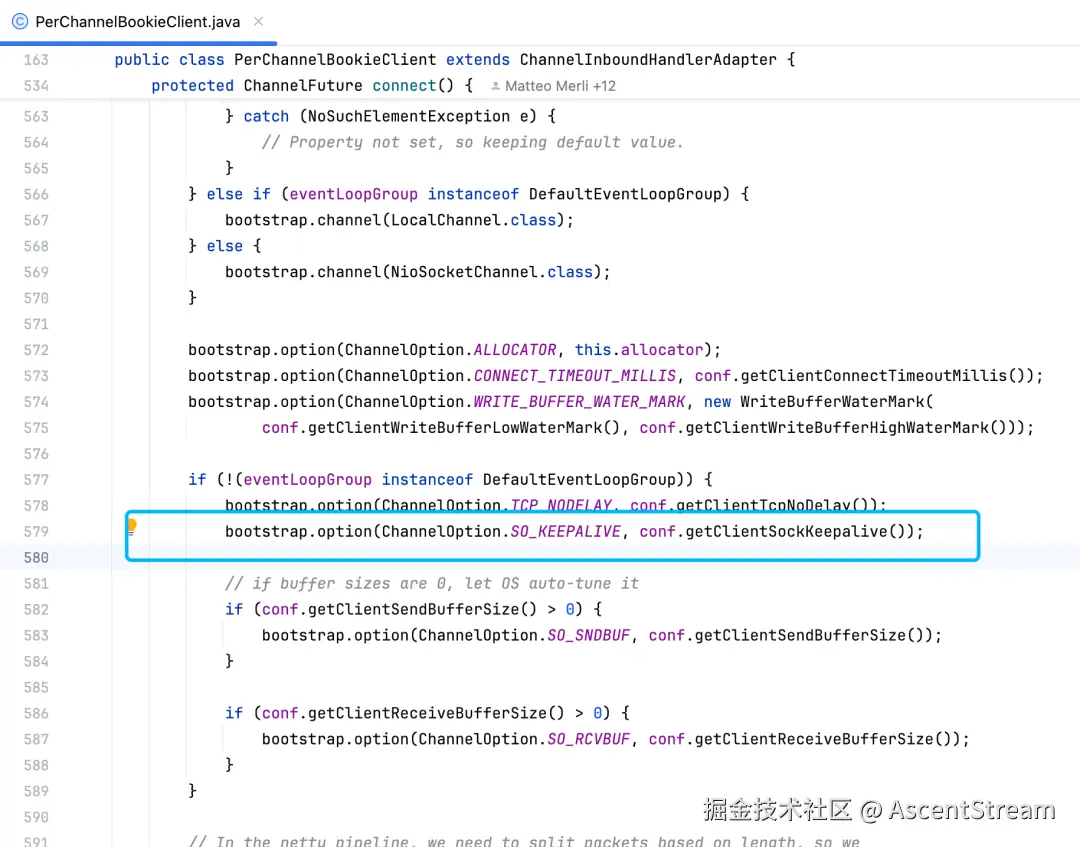
复核 Pulsar←→Bookie 的保活机制,确定走常规的依赖操作系统的 Keepalive机制。
证伪测试:
- 在单 AZ 环境,无防火墙,不做任何配置修改,集群无网络问题,应用正常。
- 在跨 AZ,防火墙灭活环境中,降低集群 Pod 内 OS的保活为 15 分钟(防火墙灭活为 20 分钟定时),集群无网络问题,应用正常。
因此根因确认为防火墙的保活机制问题。
处置建议
-
降低 Pulsar 集群 Pod 内 OS 的保活时间,例如设置为防火墙灭活周期的一半。
-
建议调整应用代码实现,例如可使用 Java 层面的异步队列来接收消息并使用多线程做后续处理,以加速 Pulsar Consumer 对消息的处理频率。同时做好生产者、消费者和客户端的示例回收(close)。
-
建议补全 Pulsar 的集群监控、端到端监控,做好每个集群的基础性能测试、压测和流控等运维工作。
-
建议问题定位能尽量减少变量,保持主线,增加问题解决效率。
同时,由于应用等级较高,Pulsar 的保障难度较大;欢迎联系我们,第一时间获取保障和支持。
附录1:保活问题测试和抓包
本地 Keepalived 抓包测试
本地测试代码,JDK11:
java
import java.io.IOException;import java.net.InetSocketAddress;import java.net.Socket;import jdk.net.ExtendedSocketOptions;
publicclassTcpClient { publicstaticvoidmain(String[] args) throws IOException, InterruptedException { Socket s = new Socket(); s.setKeepAlive(true); // 标记空闲后,每10秒发送一次keepalive s.setOption(ExtendedSocketOptions.TCP_KEEPINTERVAL, 10); // 5秒内没有流量,就标记空闲 s.setOption(ExtendedSocketOptions.TCP_KEEPIDLE, 5); s.connect(new InetSocketAddress("localhost", 13370)); Thread.sleep(30 * 1000); }}可修改内核的参数 tcp_keepalive_time:7200 -> 300,然后再观察,可参考下图。
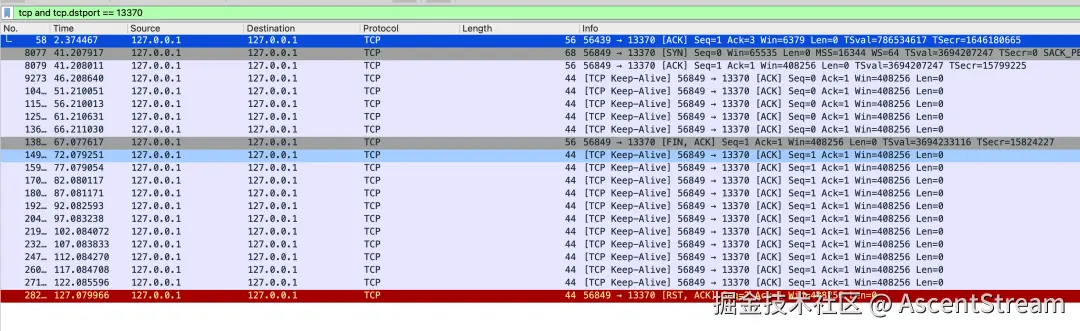
Pulsar Wireshark 协议工具
如遇到类似场景,可以联系我们获取工具包
附录2:Consumer消息拉取问题排查和建议
当前应用 Consumer 收到消息后业务处理比较耗时,线上使用多个 Consumer 通过 Shared 订阅来提高消息处理的效率,但是业务处理非常耗时,因此需要考虑消息必须打散在全部 Consumer 上,能够有效的提高效率。
环境:
- client 2.10.3
- broekr 2.10.6
难点:
配置 receiverQueueSize为 1(假定),消息数量等于 Consumer 数量,发现部分 Consumer 空闲。正常情况下所有 Consumer 都应该在处理数据。
Consumer 预拉取机制
Pulsar 消息推送采用推拉结合的方式:
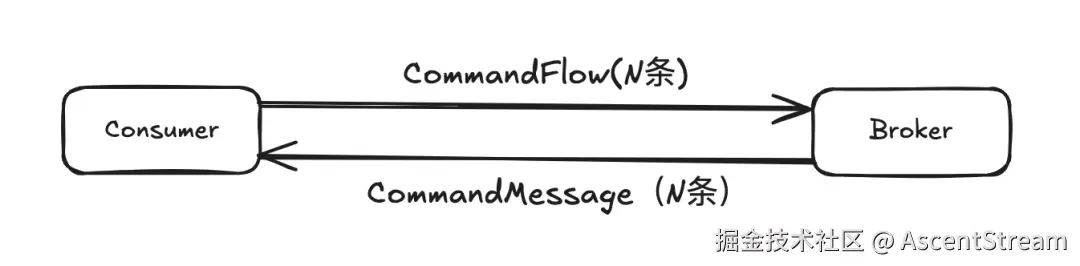
- Consumer 向 Broker 发送 CommandFlow 请求,通知 Broker 它能够接收并处理最多 N 条消息。这样,Broker 就能根据这个信号来控制向 Consumer 推送消息的数量。
- Broker 根据 Consumer 之前的 CommandFlow 请求,读取 BK,然后将消息通过 CommandMessage 请求推送给 Consumer。
Consumer 在内存默认可以预存储 1000 条消息,此机制由 client.newConsumer().receiverQueueSize(1000) 决定。
CommandFlow 触发条件
当调用 consumer.receive() 时会从 receiverQueue 中取出1条,若当前receiverQueue空闲大小大于等于receiverQueueSize/2时,则发送 CommandFlow 命令。
Consumer 最大预拉取的消息数量
- 非分区Topic:最大预拉取的消息数量等于 receiverQueueSize。
例如:Consumer receiverQueueSize: 10
Client 使用 ConsumerImp 对象,第一次 Consumer 会发送 CommandFlow 命令,Broker 会推送 10 条消息到 Consumer,当使用 consumer.receive() 方法接收 5 条消息后,此时receiverQueue空闲大小大于等于 receiverQueueSize/2 时,此时 Consumer 会再次预拉取 5 条消息。
- 分区Topic:最大预拉取的消息数量等于 receiverQueueSize * (分区数 + 1)。
例如:Consumer receiverQueueSize: 10
Topic 分区数:3
对于多分区 Topic,Client使用 MultiTopicsConsumerImpl 对象(父 Consumer),该对象会根据分区数创建相同数量的 ConsumerImp(子 Consumer),然后拉取逻辑与非分区 Topic 的逻辑一致。
3 分区 Topic 创建 3 个子 Consumer,每个子 Consumer 各自发送 CommandFlow 命令拉取 10 条消息,此时子 Consumer 预拉取消息总和为 30 条(分区数*receiverQueueSize),父 Consumer 从子 Consumer 中拉取 10 条(receiverQueueSize)到自身,当父 Consumer 拉取的消息数量大于等于 receiverQueueSize,不再拉取子 Consumer 的消息,注意第一个子 Consumer 的 receiverQueue 空闲大小大于等于 receiverQueueSize/2 时,子 Consumer 会再次预拉取 10 条消息,总计预拉取 40((分区数+1)*receiverQueueSize)条消息。当调用 父 consumer.receive() 方法接收 5 条消息后,父 Consumer 再次从子 Consumer 中拉取消息到自身。
Consumer 消息处理场景
Shared 模式 -- 非分区 Topic(等价 1 分区 Topic)
- 消息量小于预拉取的数量
当消息量小于预拉取的数据量时,在多 Consumer 的情况下,只有一个 Consumer 处理消息,其他的 Consumer 会处于空闲状态。
- 消息量大于预拉取的数量
当消息量大于预拉取的数据量时,在多 Consumer 的情况下,全部的 Consumer 都能够得到有效的利用。
Shared 模式 -- 多分区 Topic
多分区 Topic 等于非分区Topic * 分区数,一个父 Consumer 会创建多个子 Consumer(等于分区数),每个子 Consumer 拥有独立的 ReceiverQueue,逻辑与非分区 Topic一致。
问题分析
由于当前正在使用分区 Topic,同时分区数大于 1,假定场景如下:
| Topic | Consumer |
|---|---|
| 分区数:3消息数量:3 | 订阅模式:Shared数量:3ReceverQueue: 1 |
预期效果
每个 Consumer 都能够收到 1 条消息,此时所有 Consumer 都能够得到有效利用。
实际效果
根据 Consumer 最大预拉取的消息数量计算方法可知,其中 1 个 Consumer 一次性可以接收到 12((3+1)*3) 条消息,由于总消息数量等于 3 条,另外 2 个 Consumer 将会空闲,得不到有效的利用。
已验证的版本
-
broker: 2.10.6、3.0.5
-
client:2.10.3、2.10.6、3.0.5
最佳实践
根据根据上述情况,做出以下建议:
Topic
分区 Topic
- 分区数:1
如果未来需要扩容分区,这是非常容易的。
- receiverQueueSize:1
可以根据数据情况来配置,例如该值等于 CPU 核数,收到消息后可以丢给线程池并行处理
scss
String topic = "test-topic-1";
Consumer<byte[]> consumer = client.newConsumer()
.topic(TopicName.get(topic).getPartition(0).toString()) // 关键步骤1 - 必须这样写
.subscriptionName("test-sub")
.receiverQueueSize(1)
.subscriptionType(SubscriptionType.Shared)
.isAckReceiptEnabled(true)
// TODO .....
.subscribe(); 注意:当使用分区Topic时会使用,Pulsar Client创建org.apache.pulsar.client.impl.MultiTopicsConsumerImpl对象:github.com/apache/puls... receiverQueue 最小值为 2,无法配置为 1,因此"关键步骤1"必须使用完整的分区名称,可以避免使用该对象,此时相当于使用非分区的 Topic。
非分区 Topic
- receiverQueueSize:1
可以根据数据情况来配置,例如该值等于 CPU 核数,收到消息后可以丢给线程池并行处理
scss
String topic = "test-topic-2";
Consumer<byte[]> consumer = client.newConsumer()
.topic(topic)
.subscriptionName("test-sub")
.receiverQueueSize(1)
.subscriptionType(SubscriptionType.Shared)
.isAckReceiptEnabled(true)
// TODO .....
.subscribe();请根据业务场景选择合适的 Topic。
Producer
- 禁用批量处理:newProducer().topic(topic).enableBatching(false)
Producer 默认启用批量消息,当启用时,多个消息会打包成一个 Entry 数据包,Broker 在推送消息时不会对该 Entry 进行拆包,而是直接推送到 Consumer,然后 Consumer 进行拆包处理,此时没有办法在 Broker 上打散消息。