最近这段时间,身边有太多朋友,不管是开发,还是非开发,都在聊一件事:想做个 AI 应用。
可能是想:加个智能客服,也可能是想写个小工具,能自动生成点代码、写点文案。这股风,比任何时候都吹得更猛烈。
但聊着聊着,大家脸上就开始出现一种心照不宣的表情:"想法是好的,但......"。这个"但",大部分时候都指向同一个问题:钱。

"起步价",到底有多高?
你可能觉得,不就是调用几个 API 吗?能贵到哪里去?但现实是,如果你真的打算动手,很快就会发现,那些强大的大模型服务,价格可不是闹着玩的。
想用 OpenAI?每次调用都要付费,调试个十几二十次,可能不知不觉就花掉不少钱。对于个人开发者或者初创团队来说,这种"未知"的成本压力,会让你在动手之前就变得畏手畏脚。更别提那些想自己部署开源模型的:光是购买、配置那些动辄几万、十几万的 GPU 服务器,就足以让绝大多数人打退堂鼓。你还没看到自己的 AI 应用跑起来呢,可能银行账户就已经空了一大半。
所以,这就像一个循环:你想尝试,但成本太高;你不敢尝试,就永远不知道自己的想法行不行。很多好点子,就这样胎死腹中!

不是"万能药",但确实是"解药"
之前也提过,亚马逊云科技推出的 Amazon Bedrock( 传送门 ) ,就显得特别有价值。Bedrock 就像是一个 "大模型超市" 。
- 你想用 Anthropic 的 Claude?------ 有。
- 想用 Meta 的 Llama?------ 有。
- 甚至 Cohere 和 自家的 Titan 系列 ------ 也能直接调用。
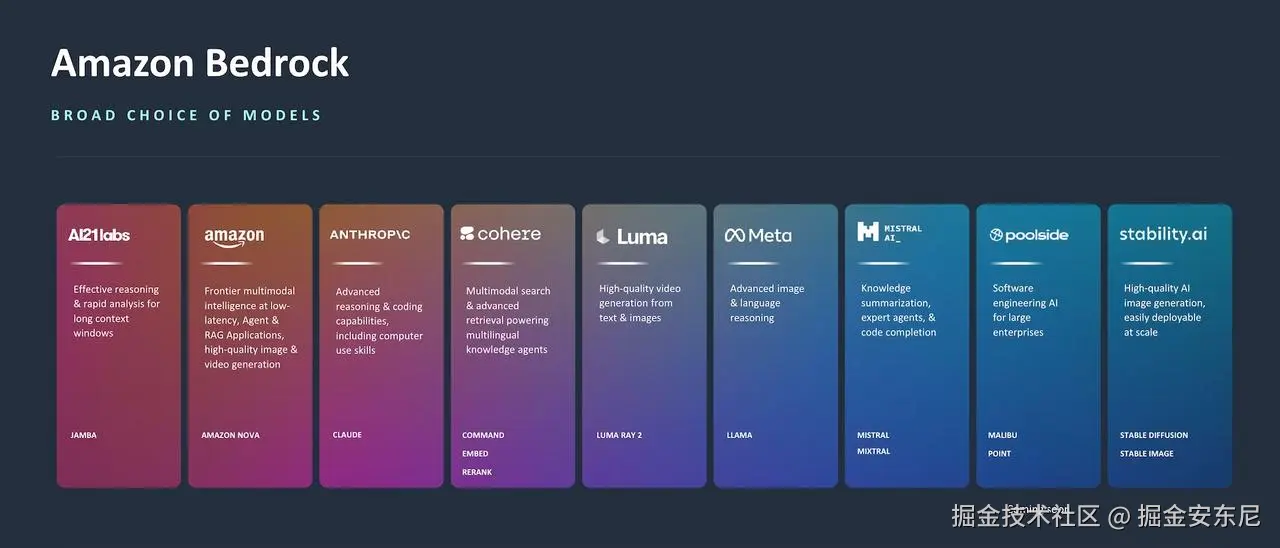
用户不用去各个平台单独注册、单独付费,更不用自己去部署那些复杂的模型。只需要一个统一的 API,就能随心所欲地调用这些模型。而且,它的核心优势在于:无服务器(Serverless) 。
翻译过来就是:你不用管那些乱七八糟的硬件和基础设施,只管写你的代码、实现你的想法就行。对于只想快速验证一个 AI 创意、做一个原型(MVP)的开发者来说,这简直是天大的福音。
如何用 Bedrock 写第一个 AI Demo?
下面我给一个最简单的 Python 例子,几行代码就能跑起来一个 Claude 模型的调用。
ini
import boto3
# 创建 Bedrock 客户端
client = boto3.client("bedrock-runtime", region_name="us-east-1")
# 调用 Claude 模型
response = client.invoke_model(
modelId="anthropic.claude-v2",
body='{"prompt": "给我写一个Python快速排序", "max_tokens_to_sample": 200}'
)
print(response['body'].read().decode())前端 Vue3 + API 调用,帮你感受一下流程结构:
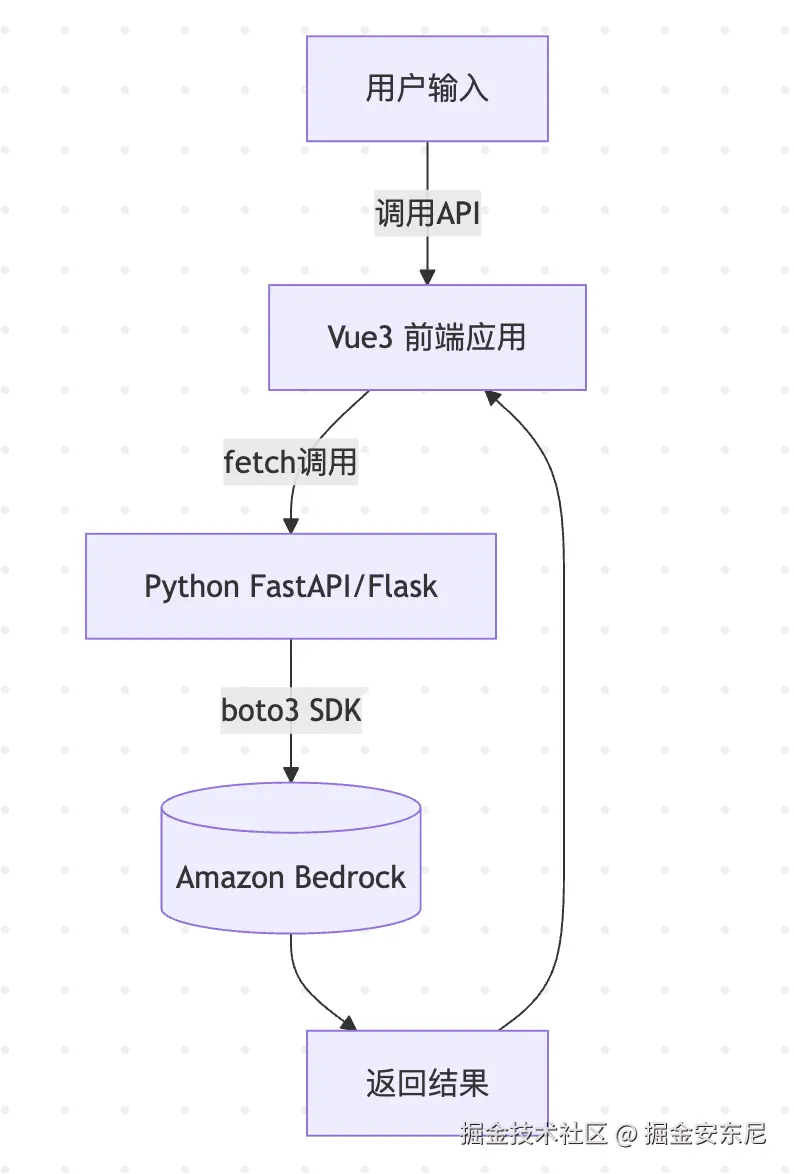
有了 Bedrock,你就能快速接上 Claude、Llama 等模型,把用户输入 → 模型推理 → 前端展示这条链路串起来。
重磅炸弹:Amazon Free Tier 2.0
尽管 Bedrock 已经很方便了,但在以前,它有一个小小的"门槛":它不在传统的免费套餐(Free Tier)的核心额度里。
直到最近,亚马逊云科技推出了 全新的 Free Tier 2.0,这玩意儿简直是给所有 AI 开发者送了一份大礼。
- 完成一些简单的"入门任务",就能拿到最高 200 美元 的 抵扣金。
- 这些任务非常实用,比如:部署一个网页应用、上传文件到 S3、用一下数据库。
- 最关键的是:Amazon Bedrock 明确在任务列表里!
换句话说:你完全可以"零风险"地去试水 Bedrock,甚至把调试成本全覆盖掉。
两个小案例
1)AI PPT 大纲生成器(Claude)
目标:输入一个主题,返回 5 页 PPT 的结构化大纲(JSON 可消费),前端可即时渲染为预览。
接口设计POST /api/ppt-outline
- 入参:
json
{ "topic": "大模型在电信行业的应用", "style": "行业报告", "lang": "zh" }- 出参(约定):
json
{
"slides": [
{ "title": "...", "bullets": ["...","..."] },
{ "title": "...", "bullets": ["...","..."] }
]
}后端增量代码(粘贴到 backend/app.py)
kotlin
from flask import request, jsonify
import os, json
@app.post("/api/ppt-outline")
def ppt_outline():
data = request.get_json(force=True) or {}
topic = (data.get("topic") or "").strip()
style = data.get("style", "产品路演")
lang = data.get("lang", "zh")
max_tokens = int(data.get("max_tokens", 800))
if not topic:
return jsonify({"error": "topic is required"}), 400
# 无 AWS 凭证时,返回 MOCK,方便前端联调
if not (os.getenv("AWS_ACCESS_KEY_ID") or os.getenv("AWS_PROFILE")):
mock = {
"slides": [
{"title": f"{topic} - 概览", "bullets": ["背景与动因","目标与范围","关键结论"]},
{"title": "现状与痛点", "bullets": ["成本压力","数据割裂","部署复杂"]},
{"title": "方案设计", "bullets": ["架构图占位","模型选择","流程编排"]},
{"title": "落地路径", "bullets": ["MVP","评估指标","风险控制"]},
{"title": "结语", "bullets": ["下一步计划","资源需求","Q&A"]}
]
}
return jsonify(mock)
client = get_bedrock_client()
sys_prompt = (
"你是演示文稿结构设计助手。"
"要求输出严格 JSON,不要多余文字。"
"字段:slides[5],每项包含 title(string)、bullets(string[3-5])。"
"语言:{lang};风格:{style}。"
).format(lang=lang, style=style)
user_prompt = f"请为主题《{topic}》生成 5 页 PPT 大纲,覆盖背景、问题、方案、路径、总结。"
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"system": sys_prompt,
"messages": [
{"role": "user", "content": [{"type": "text", "text": user_prompt}]}
]
}
resp = client.invoke_model(
modelId=os.getenv("BEDROCK_MODEL_ID", "anthropic.claude-3-5-sonnet-20240620-v1:0"),
body=json.dumps(body)
)
payload = json.loads(resp["body"].read())
text = None
if isinstance(payload.get("content"), list) and payload["content"]:
first = payload["content"][0]
if first.get("type") == "text":
text = first.get("text")
# 兜底解析
try:
data = json.loads(text) if text else {}
except Exception:
# 如果模型未严格 JSON,尝试粗解析或直接包裹
data = {"slides": [{"title": "解析失败", "bullets": [text or "无内容"]}]}
return jsonify(data)前端调用示例(追加到 App.vue 合适位置)
php
// 例:按钮事件
async function genPptOutline() {
loading.value = true
try {
const resp = await fetch('/api/ppt-outline', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({ topic: input.value, style: '行业报告', lang: 'zh' })
})
const data = await resp.json()
output.value = JSON.stringify(data, null, 2)
} finally {
loading.value = false
}
}可选扩展:
- 一键导出 Markdown/HTML;后续可用
python-pptx导出.pptx(非必须,先 MVP)。 - 增加模板选择(融资路演、产品发布、技术分享)。
2)知识库问答系统(上传文档 + Bedrock RAG)
两条路都可:A. 托管式 :用 Bedrock Knowledge Bases (更省事)。B. 自托管:本地/自建向量库(如 FAISS),用 Titan Embeddings + 简易检索。下面给 A 方案代码(最少运维);B 方案也给一个最小可用示意。
- 在 亚马逊云科技控制台创建一个 Knowledge Base(绑定 S3 数据源)。
- 前端上传文件到你的后端 → 后端推到 S3 指定前缀。
- 触发 KB 同步(或定时/自动),问答时调用
bedrock-agent-runtime.retrieve_and_generate。
接口设计
POST /api/upload:接收文件,上传到 S3(KB 绑定的桶与前缀)。POST /api/ask:入参{"question": "..."},后端调 RAG。
后端增量代码
python
import boto3, uuid
from werkzeug.utils import secure_filename
S3_BUCKET = os.getenv("S3_BUCKET", "your-kb-bucket")
S3_PREFIX = os.getenv("S3_PREFIX", "kb/raw/") # KB 绑定的数据前缀
KB_ID = os.getenv("KB_ID", "YOUR_KB_ID") # 在控制台可见
REGION = os.getenv("AWS_REGION", "us-east-1")
s3 = boto3.client("s3", region_name=REGION)
agent_rt = boto3.client("bedrock-agent-runtime", region_name=REGION)
@app.post("/api/upload")
def upload_doc():
if "file" not in request.files:
return jsonify({"error": "file is required"}), 400
f = request.files["file"]
filename = secure_filename(f.filename) or f"doc-{uuid.uuid4().hex}.txt"
key = f"{S3_PREFIX}{filename}"
s3.upload_fileobj(f, S3_BUCKET, key)
return jsonify({"ok": True, "s3_key": key})
@app.post("/api/ask")
def kb_ask():
data = request.get_json(force=True) or {}
question = (data.get("question") or "").strip()
if not question:
return jsonify({"error": "question is required"}), 400
if not (os.getenv("AWS_ACCESS_KEY_ID") or os.getenv("AWS_PROFILE")):
return jsonify({
"answer": f"[MOCK] 针对问题:{question} 的知识库答案占位",
"citations": []
})
# Bedrock KB RAG:RetrieveAndGenerate
resp = agent_rt.retrieve_and_generate(
input={"text": question},
retrieveAndGenerateConfiguration={
"knowledgeBaseConfiguration": {
"knowledgeBaseId": KB_ID,
"modelArn": f"arn:aws:bedrock:{REGION}::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
},
"type": "KNOWLEDGE_BASE"
}
)
# 解析答案与引用
out = resp.get("output", {})
answer = out.get("text") or ""
citations = []
for c in out.get("citations", []):
for ref in c.get("retrievedReferences", []):
citations.append({
"location": ref.get("location"),
"title": ref.get("content", {}).get("text", "")[:80] # 简要片段
})
return jsonify({"answer": answer, "citations": citations})前端(上传 + 提问示例)
javascript
async function uploadFile(file) {
const form = new FormData()
form.append('file', file)
const resp = await fetch('/api/upload', { method: 'POST', body: form })
return resp.json()
}
async function askKb(question) {
const resp = await fetch('/api/ask', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ question })
})
return resp.json()
}- 环境变量 :在
backend/.env增加
ini
AWS_REGION=us-east-1
BEDROCK_MODEL_ID=anthropic.claude-3-5-sonnet-20240620-v1:0
LLAMA_MODEL_ID=meta.llama3-70b-instruct-v1:0 # 以控制台为准
S3_BUCKET=your-kb-bucket
S3_PREFIX=kb/raw/
KB_ID=YOUR_KB_ID- 模型有时不守 JSON,可在后端增加「二次解析/修复」策略(如正则提取 JSON 块,或再发一次"请只输出 JSON")。
现在就可以启动!
以前我们总说"万事俱备,只欠东风"。而现在,这股"东风"已经吹来了。
Amazon Bedrock 已经把技术门槛降到了最低,而全新的 Amaozn Free Tier 2.0,则彻底把成本门槛也清零了。
👉 立即注册 Amaozn Free Tier 2.0,拿到最高 200 美元的抵扣金,把你的 AI 原型跑起来。